事务的概念
逻辑架构与物理架构
逻辑模式是数据的概念模型。在关系数据库中,它通常是与平台无关的 - 即逻辑模式原则上可以在任何SQL数据库上实现。逻辑模式主要涉及理解业务实体,它们的属性和它们的关系。
物理架构将逻辑架构转换为适用于特定数据库平台的实现。将正确的数据类型应用于属性,但它也可能涉及性能优化,例如非规范化,特定于平台的功能(如触发器)和大小/性能决策(如物理磁盘分发)。
例如:逻辑结构我们定义字段ProductID,表示商品的代码,存储的时候需要16个字节,格式为yyyyMMdd_xxxxxx_yyyy,与销售单等发生1:n的关联;而在物理设计的时候,应该反映成 ProductID CHAR(16) NOT NULL,进行索引,建立外键,但是不再关心其中的内容是什么,更不去关心其中的格式了。
开源数据库
- MongoDB
- 基于分布式文件存储的数据库
- 介于关系数据库和非关系数据库,是非关系数据库当中功能最丰富,最像关系数据库
- 支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引
- HBase - Hadoop Database
- 分布式的、面向列的开源数据库。
- 不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
- 基于列的而不是基于行的模式。
- redis - Remote Dictionary Server
- 内连接(等值连接)
格式:
A,B where 条件 或
A inner join B on 条件
需求分析:
- 查询的列
- 涉及的表
- 条件
- 外连接
左外连接格式:
A left [outer] join B on 条件
查询A的所有信息以及符合条件的B的信息
右外连接格式:
A right [outer] join B on 条件
查询B的所有信息以及符合条件的A的信息
- 自连接
多表关联查询
查询语句中嵌套了查询语句,即将一条查询语句的结果作为另一条查询语句的查询条件
格式:
A where 列名 [not] in ( 列名 from B [where 条件] )
MySQL数据库时区设置
spring:datasource:url: jdbc:mysql://ip:port/dbname?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTC
三大范式
- 第一范式:1NF 原子性,列或者字段不能再分,要求属性具有原子性,不可再拆分
- 第二范式:2NF 唯一性,一张表只能描述一件事,是对记录的唯一性约束,要求记录有唯一标识
- 第三范式:3NF 直接性,数据不能存在传递关系,即每个属性都跟主键有直接关系,而不是间接关系
MySQL覆盖索引与回表
两大类索引
聚簇索引
- 如果表设置了主键,则主键就是聚簇索引
- 如果表没有主键,则会默认第一个NOT NULL,且唯一(UNIQUE)的列作为聚簇索引
- 以上都没有,则会默认创建一个隐藏的row_id作为聚簇索引
InnoDB的聚簇索引的叶子节点存储的是行记录(其实是页结构,一个页包含多行数据),InnoDB必须要有至少一个聚簇索引。 由此可见,使用聚簇索引查询会很快,因为可以直接定位到行记录
普通索引
普通索引也叫二级索引,除聚簇索引外的索引,即非聚簇索引。 InnoDB的普通索引叶子节点存储的是主键(聚簇索引)的值,而MyISAM的普通索引存储的是记录指针。
示例
建表
mysql> create table user(-> id int(10) auto_increment,-> name varchar(30),-> age tinyint(4),-> primary key (id),-> index idx_age (age)-> )engine=innodb charset=utf8mb4;
填充数据
insert into user(name,age) values('张三',30);insert into user(name,age) values('李四',20);insert into user(name,age) values('王五',40);insert into user(name,age) values('刘八',10);mysql> select * from user;+----+--------+------+| id | name | age |+----+--------+------+| 1 | 张三 | 30 || 2 | 李四 | 20 || 3 | 王五 | 40 || 4 | 刘八 | 10 |+----+--------+------+
索引存储结构
id 是主键,所以是聚簇索引,其叶子节点存储的是对应行记录的数据
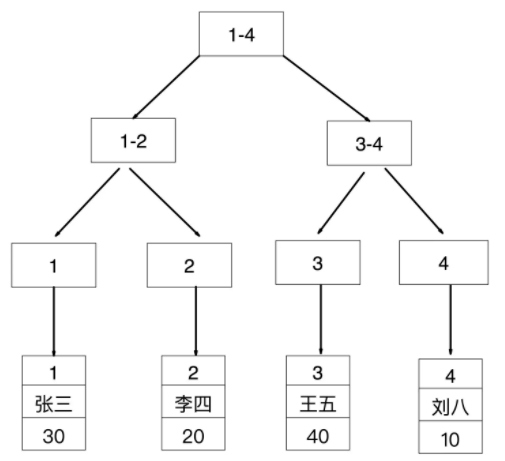
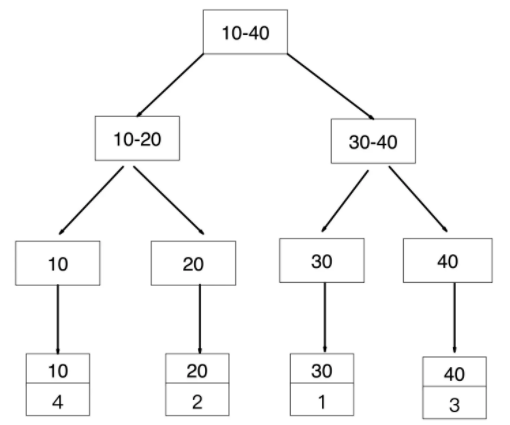
age 是普通索引(二级索引),非聚簇索引,其叶子节点存储的是聚簇索引的的值
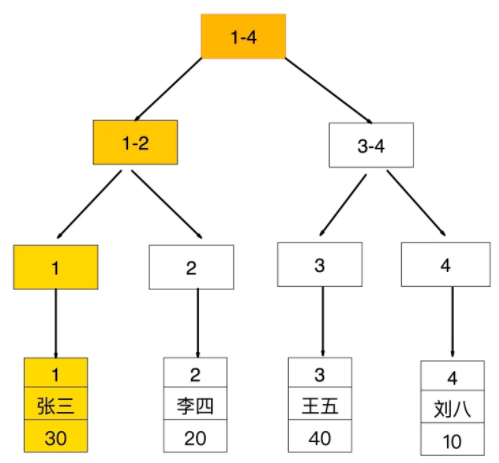
如果查询条件为主键(聚簇索引),则只需扫描一次B+树即可通过聚簇索引定位到要查找的行记录数据。 如:select * from user where id = 1;
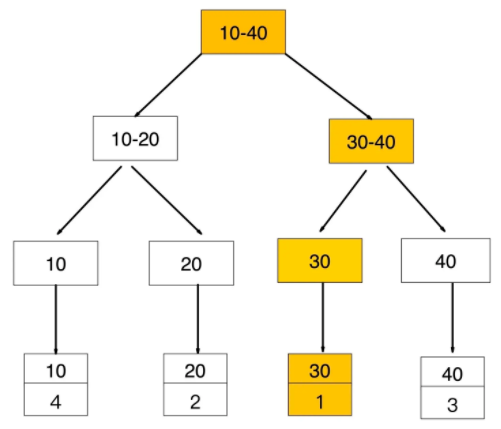
如果查询条件为普通索引(非聚簇索引),需要扫描两次B+树,第一次扫描通过普通索引定位到聚簇索引的值,然后第二次扫描通过聚簇索引的值定位到要查找的行记录数据。 如:select * from user where age = 30;
- 先通过普通索引 age=30 定位到主键值 id=1
- 再通过聚集索引 id=1 定位到行记录数据

若有收获,就点个赞吧
0 人点赞
