1、Map集合常用的方法

Map.Entry

练习
package map;import java.util.Collection;import java.util.HashMap;import java.util.Map;/*java.util.Map 中常用的方法1、Map和Collection没有继承关系*/public class Demo01 {public static void main(String[] args) {// 创建一个map对象Map<Integer,String> map = new HashMap<>();// 向map集合中添加键值对map.put(1,"zhangsan");map.put(2,"lisi");map.put(3,"wangwu");// 通过key获取valueString value = map.get(1);System.out.println(value);// 获取键值对的数量System.out.println("键值对的数量: " + map.size());// 通过key删除keymap.remove(1);System.out.println("键值对的数量:" + map.size());// 包含key和valueSystem.out.println(map.containsKey(7));// falseSystem.out.println(map.containsValue("lisi")); // true// map集合是否为空System.out.println(map.isEmpty());Collection<String> values = map.values();for (String element:values) {System.out.println(element);}}}
2、Map集合的遍历
- 获取所有的key,遍历key获取value ```java package map;
import java.util.HashMap; import java.util.Iterator; import java.util.Map; import java.util.Set;
public class Demo02 {
public static void main(String[] args) {
Map
map.put(1,"zhangsan");map.put(2,"lisi");map.put(3,"wangwu");Set<Integer> keys = map.keySet();// 方式一:foreach循环for(Integer key: keys){System.out.println(map.get(key));}// 方式二:迭代器遍历Iterator<Integer> it = keys.iterator();while(it.hasNext()){Integer key = it.next();System.out.println(map.get(key));}}
}
<a name="ig5Zi"></a>#### 2、适用大数量的情况,效率高```java// 方式:效率高Map.Entry,值和value都是从node对象中获取Set<Map.Entry<Integer,String>> set = map.entrySet();Iterator<Map.Entry<Integer,String>> it2 = set.iterator();while(it2.hasNext()){Map.Entry<Integer,String> node = it2.next();Integer key = node.getKey();String value = node.getValue();System.out.println(key + "=" + value);}for(Map.Entry<Integer,String> node: set){System.out.println(node.getKey() + "=" + node.getValue());}
3、哈希表数据结构

3.1 概念
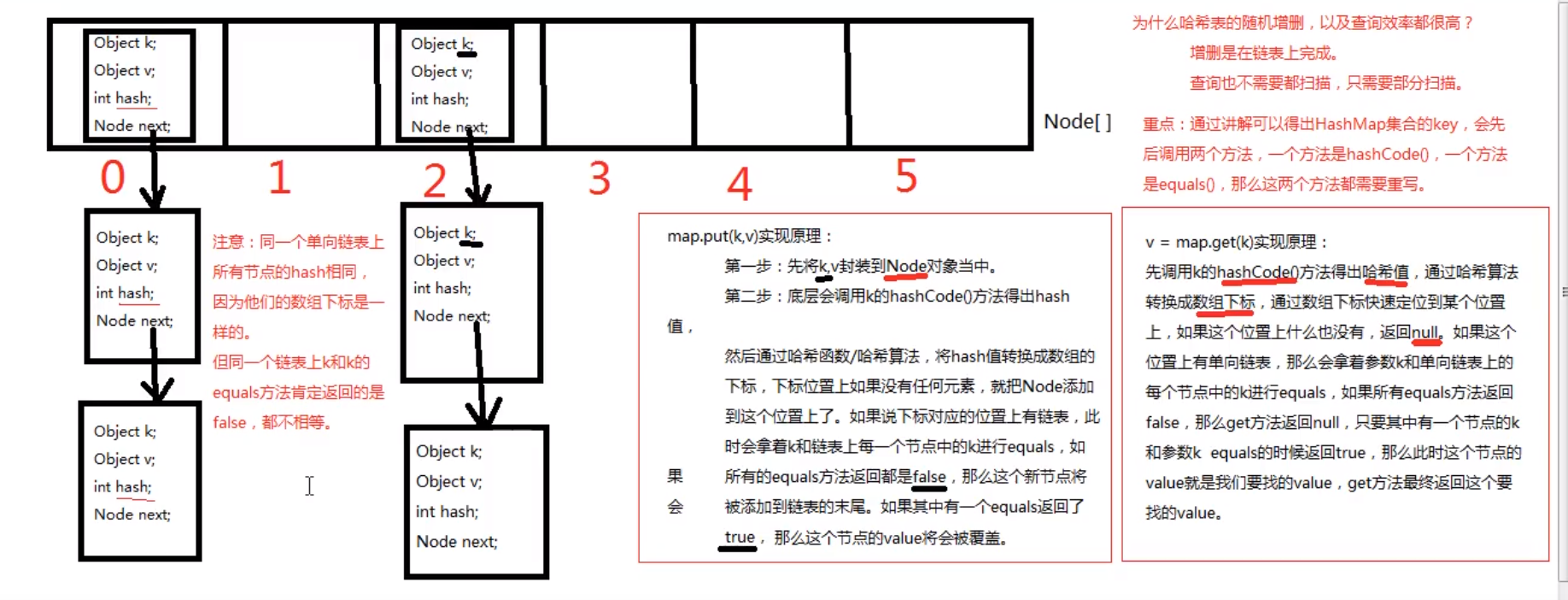
package map;import java.util.HashMap;import java.util.Map;/*HashMap集合1、HashMap集合底层是哈希表/散列表的数据结构2、哈希表是一个怎么的数据结构哈希表是一个数组和单向列表的结合体数组:在查询方面效率很高,随机增删效率很低单向链表:在随机增删方面效率很高,在查询方面效率很低哈希表将以上两种数据结构结合在一起,充分发挥它们的优点3、hashMap 底层源代码4、Hash表/散列表:一维数组,这个数组一个元素是一个单向链表(数组和链表的结合体)5、最主要掌握的是map.put(k,v)实现原理1、将k,v封装到node对象中2、底层通过调用k得到HashCode的哈希值然后通过Hash函数或Hash算法,将Hash值转变为数组的下标,下标位置上如果没有任何元素,就把Node添加到这个位置上如果下标对应的位置有链表,会拿着k和链表上每一个节点中的key进行equals,如果equals方法返回都是false,那么新节点将被添加到链表的末尾如果其中一个equals返回了true,那么这个节点的value将被覆盖v = map.get(k)1、调用k的HashCode 方法得到哈希值,通过Hash算法转换成数组下标2、并通过下标快速定位到某个位置,如果这个位置什么也没有返回null如果这个位置有单向链表,那么会拿着参数k和单向链表中的每个节点的k进行equals,如果有其中一个节点的k和参数k equals的时候返回true,那么此时这个节点的value就是我们要找的valueget方法最终返回要找的这个value6、HashMap集合中的key会先后调用两个方法HashCode和equals,那么这两个方法都需要被重写7、同一个单向链表上所有节点的HashCode相同,因为它们的数组下标一样但同一个链表上的key和key的equals方法肯定返回的都是false8、以上两个方法的实现原理必须掌握9、为什么Hash表的随机增删和查询效率都很高增删在链表上完成,没有纯链表增删效率高查询不是全局扫描,只是局部扫描,没有纯数组查询率高10、为什么放在HashMap集合key部分的元素要重写equals方法equals比较的是两个对象间的内存地址我们应该比较内容11、HashMap集合key部分特点无序,不可重复为什么无序?因为不一定挂载到哪一个单向链表上不可重复怎么保证?Equals方法保证集合的key不可重复如果key重复了,value会被覆盖放在HashMap集合中的key其实放到HashSet集合所以HashSet集合中的元素同时重写HashCode和equals方法112、hashCode方法需要重写,在重写时返回一个固定值可以吗?会出现什么问题?哈希表使用不当时无法发挥性能a)如果hashCode方法需要重写,在重写时返回一个固定值导致哈希表变成纯单向链表,这种情况我们称为散列分布不均匀b) 所有hashCode方法返回值都设定为不一样的值,可以吗,会导致什么问题?导致哈希表变成一维数组,也是散列分布不均匀*/public class Demo03 {public static void main(String[] args) {Map<Integer,String> map = new HashMap<>();}}

若有收获,就点个赞吧
0 人点赞
