
InnoDB体系架构
后台线程
Master Thread
作用:负责将缓冲池中的数据异步刷新到磁盘,保证数据的一致性,包括脏页的刷新、合并插入缓冲(Insert Buffer)、Undo页的回收等。
IO Thread
InnoBD存储引擎大量使用了AIO(Async IO) 来处理写IO请求,这样可以极大提高数据库的性能。IO Thread的作用是处理IO请求的回调。
| innodb_read_io_threads | 4 |
|---|---|
| innodb_write_io_threads | 4 |
show engine innodb status
mysql> show engine innodb status\G*************************** 1. row ***************************Type: InnoDBName:Status:=====================================2021-10-24 01:35:53 0x70000c2e6000 INNODB MONITOR OUTPUT=====================================Per second averages calculated from the last 19 seconds-----------------BACKGROUND THREAD-----------------srv_master_thread loops: 51 srv_active, 0 srv_shutdown, 26104 srv_idlesrv_master_thread log flush and writes: 0----------SEMAPHORES----------OS WAIT ARRAY INFO: reservation count 18OS WAIT ARRAY INFO: signal count 70RW-shared spins 0, rounds 0, OS waits 0RW-excl spins 0, rounds 0, OS waits 0RW-sx spins 0, rounds 0, OS waits 0Spin rounds per wait: 0.00 RW-shared, 0.00 RW-excl, 0.00 RW-sx------------TRANSACTIONS------------Trx id counter 2172Purge done for trx's n:o < 2172 undo n:o < 0 state: running but idleHistory list length 0LIST OF TRANSACTIONS FOR EACH SESSION:---TRANSACTION 421986640383904, not started0 lock struct(s), heap size 1128, 0 row lock(s)---TRANSACTION 421986640383112, not started0 lock struct(s), heap size 1128, 0 row lock(s)---TRANSACTION 421986640382320, not started0 lock struct(s), heap size 1128, 0 row lock(s)---TRANSACTION 421986640381528, not started0 lock struct(s), heap size 1128, 0 row lock(s)--------FILE I/O--------I/O thread 0 state: waiting for i/o request (insert buffer thread)I/O thread 1 state: waiting for i/o request (log thread)I/O thread 2 state: waiting for i/o request (read thread)I/O thread 3 state: waiting for i/o request (read thread)I/O thread 4 state: waiting for i/o request (read thread)I/O thread 5 state: waiting for i/o request (read thread)I/O thread 6 state: waiting for i/o request (write thread)I/O thread 7 state: waiting for i/o request (write thread)I/O thread 8 state: waiting for i/o request (write thread)I/O thread 9 state: waiting for i/o request (write thread)Pending normal aio reads: [0, 0, 0, 0] , aio writes: [0, 0, 0, 0] ,ibuf aio reads:, log i/o's:, sync i/o's:Pending flushes (fsync) log: 0; buffer pool: 01591 OS file reads, 181772 OS file writes, 56933 OS fsyncs0.00 reads/s, 0 avg bytes/read, 0.00 writes/s, 0.00 fsyncs/s-------------------------------------INSERT BUFFER AND ADAPTIVE HASH INDEX-------------------------------------Ibuf: size 1, free list len 0, seg size 2, 0 mergesmerged operations:insert 0, delete mark 0, delete 0discarded operations:insert 0, delete mark 0, delete 0Hash table size 34679, node heap has 0 buffer(s)Hash table size 34679, node heap has 1 buffer(s)Hash table size 34679, node heap has 1 buffer(s)Hash table size 34679, node heap has 0 buffer(s)Hash table size 34679, node heap has 325 buffer(s)Hash table size 34679, node heap has 1 buffer(s)Hash table size 34679, node heap has 1 buffer(s)Hash table size 34679, node heap has 1 buffer(s)0.00 hash searches/s, 0.00 non-hash searches/s---LOG---Log sequence number 317541200Log buffer assigned up to 317541200Log buffer completed up to 317541200Log written up to 317541200Log flushed up to 317541200Added dirty pages up to 317541200Pages flushed up to 317541200Last checkpoint at 317541200166766 log i/o's done, 0.00 log i/o's/second----------------------BUFFER POOL AND MEMORY----------------------Total large memory allocated 0Dictionary memory allocated 513248Buffer pool size 8191Free buffers 961Database pages 6900Old database pages 2530Modified db pages 0Pending reads 0Pending writes: LRU 0, flush list 0, single page 0Pages made young 2499, not young 28706890.00 youngs/s, 0.00 non-youngs/sPages read 1566, created 9669, written 116540.00 reads/s, 0.00 creates/s, 0.00 writes/sNo buffer pool page gets since the last printoutPages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/sLRU len: 6900, unzip_LRU len: 0I/O sum[0]:cur[0], unzip sum[0]:cur[0]--------------ROW OPERATIONS--------------0 queries inside InnoDB, 0 queries in queue0 read views open inside InnoDBProcess ID=42847, Main thread ID=0x70000b11b000 , state=sleepingNumber of rows inserted 3935407, updated 0, deleted 0, read 107560.00 inserts/s, 0.00 updates/s, 0.00 deletes/s, 0.00 reads/sNumber of system rows inserted 318, updated 869, deleted 143, read 1067150.00 inserts/s, 0.00 updates/s, 0.00 deletes/s, 0.00 reads/s----------------------------END OF INNODB MONITOR OUTPUT============================1 row in set (0.00 sec)
Purge Thread
事务提交后,回收不再使用的undo log 页。
启用独立的Purge Thread:设置参数innodb_purge_threads > 1,默认值是4。InnoDB支持多个Purge Thread,目的是加快undo页的回收。
Page Cleaner Thread
InnoDB 1.2.x版本引入的,作用是刷新脏页,之前是在Master Thread中进行刷新脏页,独立出来是为了减轻Master Thread的工作,减少对用户线程的阻塞,提高性能。
InnoDB存储引擎内存池
由于CPU和磁盘速度之间的鸿沟,基于磁盘的数据库通常使用缓冲池技术来提高数据库的整体性能。
缓冲池就是一块内存区域。
读取:在数据库中读取页,首先将从磁盘读取到的页放入缓冲池中,下一次再读相同的页时,首先判断该页是否在缓冲池中,若在,直接读取页,否则,读取磁盘。
修改:对于数据库中页的修改操作,首先修改在缓冲池中的页,然后再以一定的频率刷新到磁盘上。刷新机制是Checkpoint,checkpoint也是为了提高数据库的整体性能。
缓冲池大小
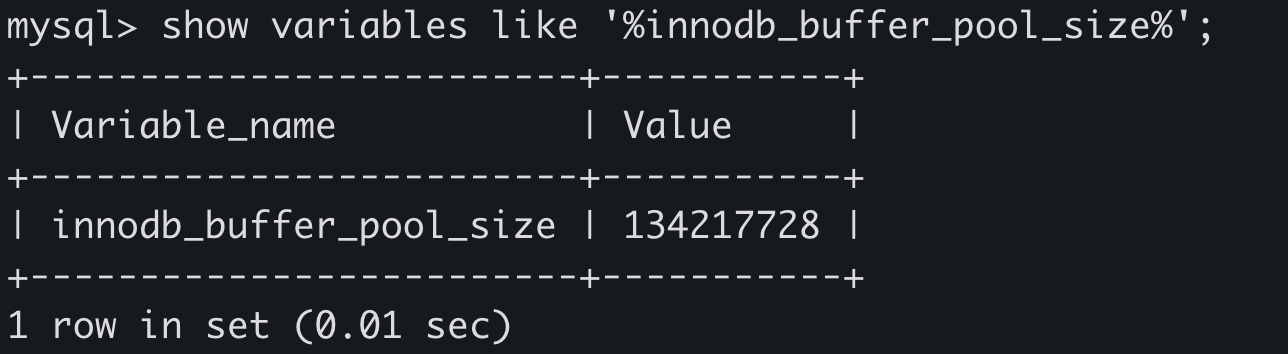
innodb_buffer_pool_size,默认是128M。
缓冲池中缓存的数据页的类型有:索引页、数据页、undo页、插入缓冲(insert buffer)、自适应哈希索引(adaptive hash index)、InnoDB存储的锁信息(lock info)、数据字典信息(data dictionary)等。
缓冲池个数
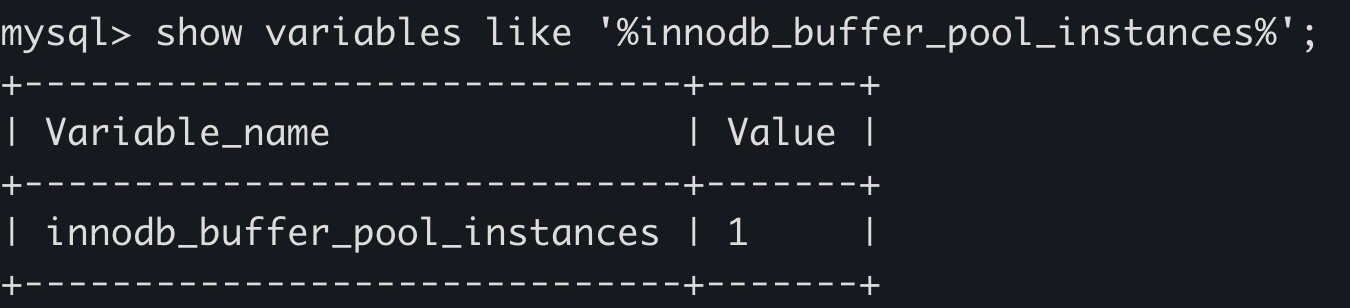
InnoDB允许有多个缓冲池实例,通过innodb_buffer_pool_instances参数指定。
LRU list/Free list/Flush list
LRU list用来管理已经读取的页,Free list管理空闲页,Flush list中的页是脏页,表示缓冲池中的页和磁盘中的页的数据产生了不一致。
redo log buffer重做日志缓冲
InnoDB首先将redo log放入到这个缓冲区,然后按照一定的频率将其刷新到重做日志文件。重做日志缓存的大小通过参数innodb_log_buffer_size控制。不需要设置很大,因为一般情况下会每一秒钟将其刷新到redo log文件中。
checkpoint技术
解决的问题:
- 缩短数据库的恢复时间
- 缓冲池不够用时,将脏页刷新到磁盘
- 重做日志不可用时,刷新脏页
write ahead log策略
为了避免发生数据丢失的问题,事务型数据库一般都采用WAL策略,事务提交时,先写redo log,再修改页。当由于发生宕机二导致数据丢失时,通过redo log完成数据的恢复。这也是ACID中D的要求。
InnoDB的关键特性
- 插入缓存insert buffer
- 两次写 double write
- 自适应哈希索引 adaptive hash index
- 异步IO async io
- 刷新邻接页 flush neighbor page
MRR
MRR,全称「Multi-Range Read Optimization」。
简单说:MRR 通过把「随机磁盘读」,转化为「顺序磁盘读」,从而提高了索引查询的性能。
开启MRR
mysql > set optimizer_switch='mrr=on';
# 开启了 MRR,重新执行 sql 语句,发现 Extra 里多了一个「Using MRR」。
MySQL 的查询过程会变成这样: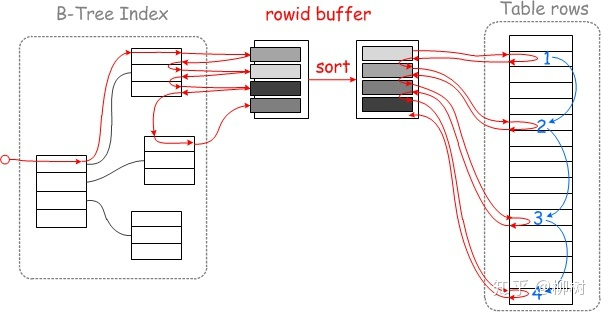
对于 Myisam,在去磁盘获取完整数据之前,会先按照 rowid 排好序,再去顺序的读取磁盘。
对于 Innodb,则会按照聚簇索引键值排好序,再顺序的读取聚簇索引。
顺序读带来了几个好处:
1、磁盘和磁头不再需要来回做机械运动;
2、可以充分利用磁盘预读
比如在客户端请求一页的数据时,可以把后面几页的数据也一起返回,放到数据缓冲池中,这样如果下次刚好需要下一页的数据,就不再需要到磁盘读取。这样做的理论依据是计算机科学中著名的局部性原理:
当一个数据被用到时,其附近的数据也通常会马上被使用。
3、在一次查询中,每一页的数据只会从磁盘读取一次
MySQL 从磁盘读取页的数据后,会把数据放到数据缓冲池,下次如果还用到这个页,就不需要去磁盘读取,直接从内存读。
但是如果不排序,可能你在读取了第 1 页的数据后,会去读取第2、3、4页数据,接着你又要去读取第 1 页的数据,这时你发现第 1 页的数据,已经从缓存中被剔除了,于是又得再去磁盘读取第 1 页的数据。
而转化为顺序读后,你会连续的使用第 1 页的数据,这时候按照 MySQL 的缓存剔除机制,这一页的缓存是不会失效的,直到你利用完这一页的数据,由于是顺序读,在这次查询的余下过程中,你确信不会再用到这一页的数据,可以和这一页数据说告辞了。
顺序读就是通过这三个方面,最大的优化了索引的读取。
索引本身就是为了减少磁盘 IO,加快查询,而 MRR,则是把索引减少磁盘 IO 的作用,进一步放大。
�

若有收获,就点个赞吧
0 人点赞
