join的几种类型:
inner join:内连接
最后返回的数据行数是在inner join前后两张表中同时存在的数据行数。任何一条只存在于某一张表中的数据,都不会返回,
left join:左连接
又称为left outer join,我们平时都把outer省略。简写为left join
left左边的表为主表,left右边的表为从表。返回结果行数以left左边的表的行数为最后的数据行,对于左表中有些数据行在右表中找不到它所匹配的数据行记录时候,返回结果的时候这些行后面通常会以null来填充。
right join:右连接
又称为right outer join,我们平时都把outer省略。简写为right join
right右边的表为主表,right坐标的表为从表。返回结果行数以right右边的表的行数为左后的数据行,对于主表中有些数据行在从表中找不到它所匹配的数据行记录时候,返回结果的时候这些行后面通常会以null来填充。
full join:全连接
最后返回的数据行数是full join前后两张表的数行数的笛卡尔积。但是MySQL中没有这种写法,它直接使用select * from A,B;这样的写法就可以实现全连接。Oracle中有full join这种写法。
straight_join
straight_join的含义和上面的inner join有些类似,它也是对两个表进行inner join的操作,但是它属于一种特殊的inner join。
在关联查询的时候,inner join会根据两个关联的表的大小自动的选择哪一个表作为驱动表,哪一个表作为被驱动表。这个由MySQL内部的优化器自己去选择的。但是MySQL的优化器也不是100%靠谱,有时候由于我们对表频繁的CURD操作,表的统计信息也可能不够准确,所以它也会选择错误的优化方案。比如选择了错误的表作为驱动表,这样将导致我们的查询效率变得很低。
对于上述的这种情况,我们可以手动的去指定让MySQL去选择哪个作为驱动表哪个作为被驱动表吗?答案是肯定的,此时的straight_join就上场了。
它的功能是可以指定在straight_join前面的表作为驱动表,在straight_joion后面的表作为被驱动表。这样我们就可以指定让MySQL选择哪个表作为驱动表哪个表作为被驱动表了。
MySQL官网给straight_join的解释是下面这样的:
STRAIGHT_JOIN is similar to JOIN, except that the left table is always read before the right table. This can be used for those (few) cases for which the join optimizer processes the tables in a suboptimal order.
straight_join使用示例
select * from A as a straight_join B as b on a.id = b.id;
什么是驱动表? 什么是被驱动表?
驱动表在SQL语句执行的过程中,总是先读取。而被驱动表在SQL语句执行的过程中,总是后读取。
在驱动表数据读取后,放入到join_buffer后,再去读取被驱动表中的数据,来和驱动表中的数据进行匹配。如果匹配上则作为结果集返回,否则丢弃。
如何区分驱动表和被驱动表?
我们对于一个已有的SQL语句,我们应该怎么判断这个SQL语句中哪个表示驱动表?哪个表示被驱动表呢?
可以使用explain命令查看一下SQL语句的执行计划。在输出的执行计划中,排在第一行的表是驱动表,排在第二行的表是被驱动表。
left join
下面的SQL中,A是驱动表,B是被驱动表。left join的左表示驱动表,右表示被驱动表。
select from A as a left join B as b on a.id = b.id;
right join
下面的SQL中,A是被驱动表,B是驱动表。right join的右表示驱动表,左表示被驱动表。
select from A as a right join B as b on a.id = b.id;
inner join
对于inner join而言,MySQL会选择小表作为驱动表,大表作为被驱动表。
如何区分join语句中表的大小?
两个表在进行关联查询的时候,是根据真正参与关联查询的数据行和列所占用的空间大小来确认谁作为驱动表谁作为被驱动表的
对于大小的判断,是指真正参与关联查询的数据量所占用的join_buffer的大小来区分的,而不是根据表中所有的数据行数来判断的。
join buffer的概念
join查询的时候,会把驱动表中的数据全部查询出来放入到内存中,而这个内存就是我们现在要说的:join buffer,它的大小是有参数join_buffer_size大小来决定的,默认值为262144字节,即为:256KB。
这个值不建议设计的特别大,因为MySQL会为每一个join查询语句都分配一个当前配置的join_buffer_size大小的join buffer,所以如果这个值配置过大,那么当查询并发量大的时候,可能导致内存被吃掉的很多。比较好的建议是保持全局的设置为一个较小的值,然后当我们执行一个比较大的join查询的时候,设置session级别的join_buffer_size比较大,只对当前会话级别的查询生效。
join查询过程
Index Nested-Loop Join:索引嵌套循环连接
简称 NLJ
“可以使用被驱动表的索引”。
驱动表是走全表扫描,而被驱动表是走树搜索。
被驱动表的行数是 M,驱动表的行数是 N。整个执行过程,近似复杂度是 N + N2log2M。N 对扫描行数的影响更大,因此应该让小表来做驱动表。
Simple Nested-Loop Join:简单嵌套循环连接
MySQL 也没有使用这个 Simple Nested-Loop Join 算法
Block Nexted-Loop Join:基于块的嵌套循环连接
简称 BNL.
被驱动表上没有可用的索引,算法的流程:
- 把表 t1 的数据读入线程内存 join_buffer 中,由于我们这个语句中写的是 select *,因此是把整个表 t1 放入了内存;
- 扫描表 t2,把表 t2 中的每一行取出来,跟 join_buffer 中的数据做对比,满足 join 条件的,作为结果集的一部分返回。
Block Nested-Loop Join 算法的这 10 万次判断是内存操作,速度上会快很多,性能也更好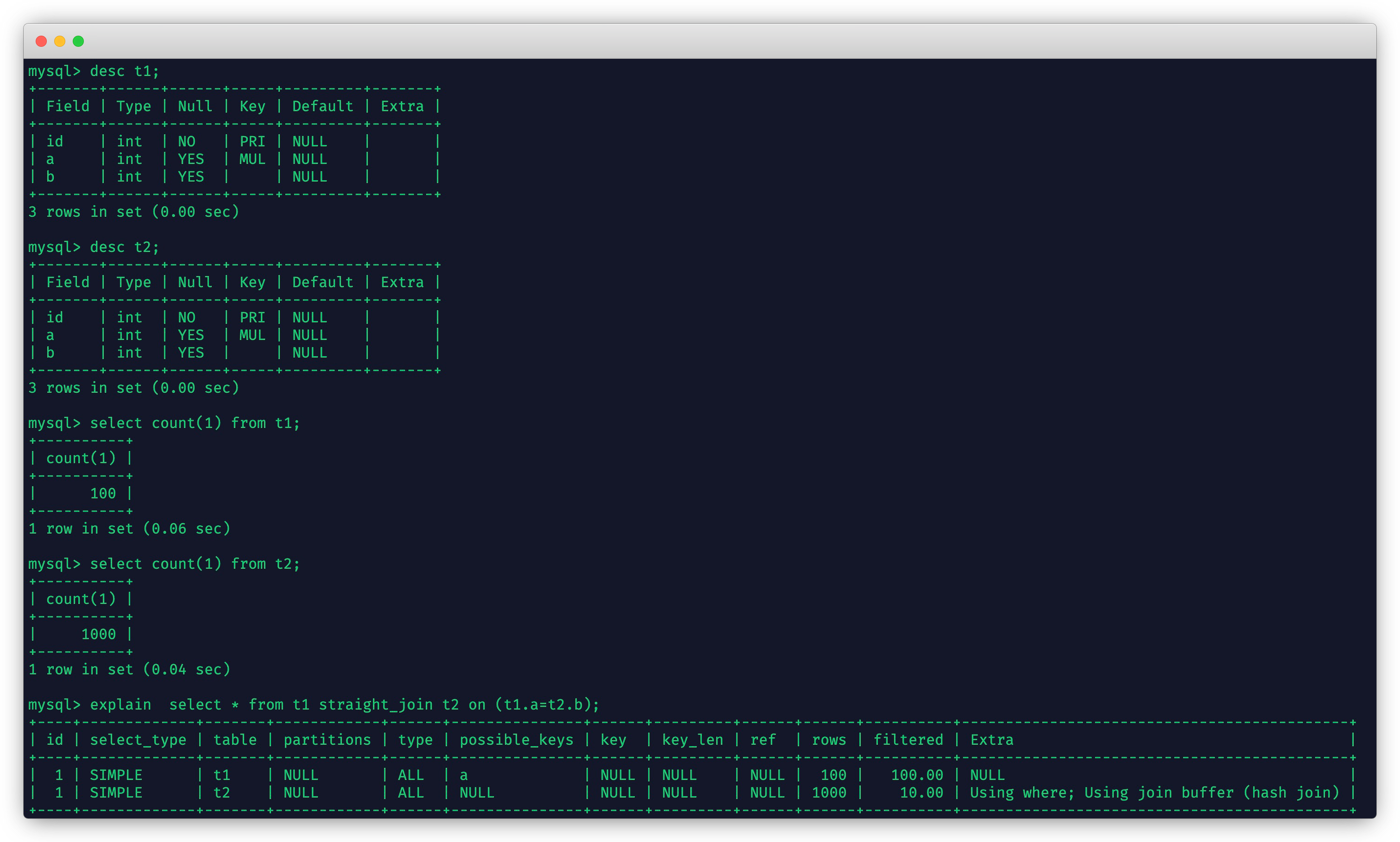
这个例子里表 t1 才 100 行,要是表 t1 是一个大表,join_buffer 放不下怎么办呢?
join_buffer 的大小是由参数 join_buffer_size 设定的,默认值是 256k。如果放不下驱动表的所有数据话,策略很简单,就是分段放。
假设,驱动表的数据行数是 N,需要分 K 段才能完成算法流程,被驱动表的数据行数是 M。这里的 K 不是常数,N 越大 K 就会越大,因此把 K 表示为λ*N,显然λ的取值范围是 (0,1)。
join_buffer_size 越大,一次可以放入的行越多,分成的段数也就越少,对被驱动表的全表扫描次数就越少。
如果你的 join 语句很慢,就把 join_buffer_size 改大。
问题
- 能不能使用 join 语句?
如果可以使用 Index Nested-Loop Join 算法,也就是说可以用上被驱动表上的索引,其实是没问题的;
如果使用 Block Nested-Loop Join 算法,扫描行数就会过多。尤其是在大表上的 join 操作,这样可能要扫描被驱动表很多次,会占用大量的系统资源。所以这种 join 尽量不要用。
在判断要不要使用 join 语句时,就是看 explain 结果里面,Extra 字段里面有没有出现“Block Nested Loop”字样。
- 如果要使用 join,应该选择大表做驱动表还是选择小表做驱动表?
如果是 Index Nested-Loop Join 算法,应该选择小表做驱动表;如果是 Block Nested-Loop Join 算法:在 join_buffer_size 足够大的时候,是一样的;在 join_buffer_size 不够大的时候(这种情况更常见),应该选择小表做驱动表。所以,这个问题的结论就是,总是应该使用小表做驱动表。
- 如果被驱动表是一个大表,并且是一个冷数据表,除了查询过程中可能会导致 IO 压力大以外,你觉得对这个 MySQL 服务还有什么更严重的影响吗?
如果被驱动表是一个大表(因为不论用BNL还是ILJ算法) 都是优先让被参与join的总的字段量较大的一张表作为一个被驱动表。 但是由于关联的时候被驱动表的数据会频繁被走索引树, 所以根据MYSQL 的LRU算法 其实冷数据也会被提到链表的前部 ,造成冷数据的前移,其余业务数据被淘汰。 造成内存命中率降低。 请求响应变慢,业务可能造成阻塞。
Multi-Range Read 优化 (MRR)
这个优化的主要目的是尽量使用顺序读盘。
因为大多数的数据都是按照主键递增顺序插入得到的,所以我们可以认为,如果按照主键的递增顺序查询的话,对磁盘的读比较接近顺序读,能够提升读性能。这,就是 MRR 优化的设计思路。
语句的执行流程变成了这样:
- 根据索引 a,定位到满足条件的记录,将 id 值放入 read_rnd_buffer 中 ;
- 将 read_rnd_buffer 中的 id 进行递增排序;
- 排序后的 id 数组,依次到主键 id 索引中查记录,并作为结果返回。
这里,read_rnd_buffer 的大小是由 read_rnd_buffer_size 参数控制的。如果步骤 1 中,read_rnd_buffer 放满了,就会先执行完步骤 2 和 3,然后清空 read_rnd_buffer。之后继续找索引 a 的下个记录,并继续循环。
join优化
NLJ 算法的优化
Multi-Range Read 优化
Batched Key Access优化
理解了 MRR 性能提升的原理,我们就能理解 MySQL 在 5.6 版本后开始引入的 Batched Key Access(BKA) 算法了。这个 BKA 算法,其实就是对 NLJ 算法的优化。
NLJ 算法执行的逻辑是:从驱动表 t1,一行行地取出 a 的值,再到被驱动表 t2 去做 join。也就是说,对于表 t2 来说,每次都是匹配一个值。这时,MRR 的优势就用不上了。
join_buffer 在 BNL 算法里的作用,是暂存驱动表的数据。但是在 NLJ 算法里并没有用。那么,我们刚好就可以复用 join_buffer 到 BKA 算法中。
使用 BKA 优化算法的话,你需要在执行 SQL 语句之前,先设置set optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';前两个参数的作用是要启用 MRR。这么做的原因是,BKA 算法的优化要依赖于 MRR。
BNL算法优化
LRU算法
InnoDB 的 LRU 算法的时候提到,由于 InnoDB 对 Bufffer Pool 的 LRU 算法做了优化,即:第一次从磁盘读入内存的数据页,会先放在 old 区域。如果 1 秒之后这个数据页不再被访问了,就不会被移动到 LRU 链表头部,这样对 Buffer Pool 的命中率影响就不大。
BNL 算法对系统的影响主要包括三个方面:
- 可能会多次扫描被驱动表,占用磁盘 IO 资源;
- 判断 join 条件需要执行 M*N 次对比(M、N 分别是两张表的行数),如果是大表就会占用非常多的 CPU 资源;
可能会导致 Buffer Pool 的热数据被淘汰,影响内存命中率。
优化方式
优化的常见做法是,给被驱动表的 join 字段加上索引,把 BNL 算法转成 BKA 算法。
对于可以加索引的被驱动表,加索引即可。
- 对于不适合加索引的被驱动表,例如驱动表很多,查询操作又很低频。考虑使用临时表
不论是在原表上加索引,还是用有索引的临时表,我们的思路都是让 join 语句能够用上被驱动表上的索引,来触发 BKA 算法,提升查询性能。
扩展 -hash join
MySQL 的优化器和执行器一直被诟病的一个原因:不支持哈希 join
这个优化思路,我们可以自己实现在业务端。
- select * from t1;取得表 t1 的全部 1000 行数据,在业务端存入一个 hash 结构,比如 C++ 里的 set、PHP 的数组这样的数据结构。
- select * from t2 where b>=1 and b<=2000; 获取表 t2 中满足条件的 2000 行数据。
- 把这 2000 行数据,一行一行地取到业务端,到 hash 结构的数据表中寻找匹配的数据。满足匹配的条件的这行数据,就作为结果集的一行。
注t2是个大的被驱动表

若有收获,就点个赞吧
0 人点赞
