业务发展到哪个阶段需要考虑分库分表?
业务增长的同时,数据量变得非常大,给数据库带来了性能和可用性的问题。
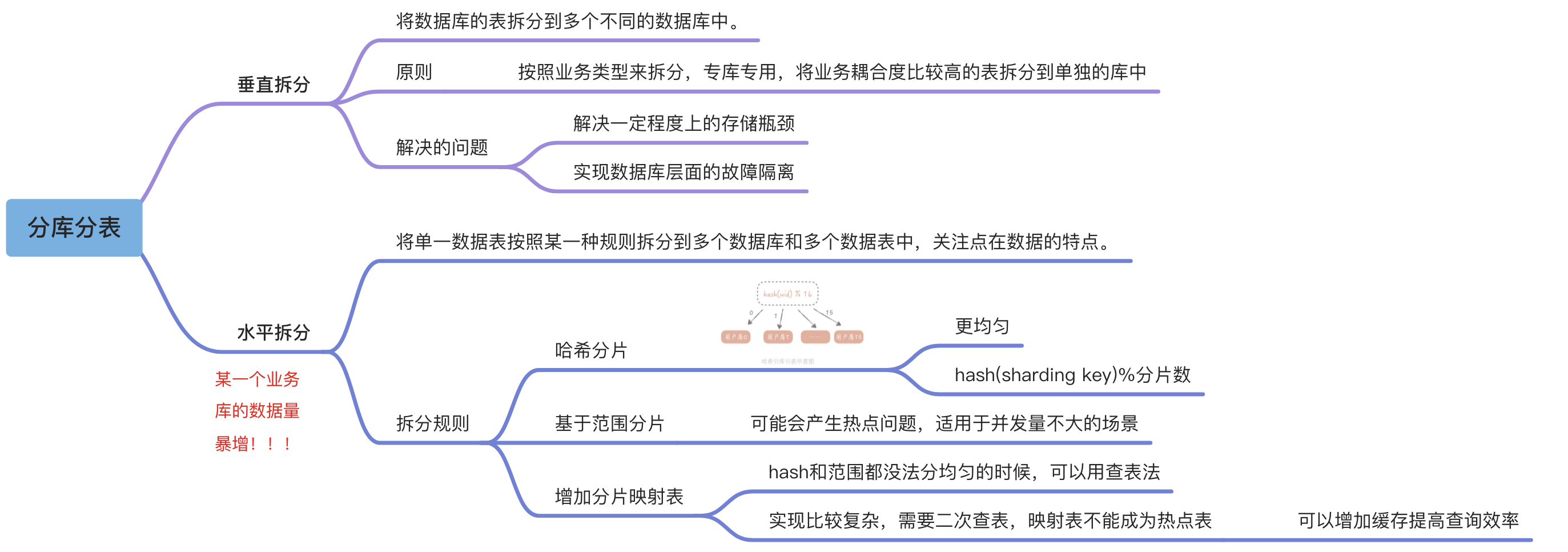
什么是分库分表?
| 方案 | 解决的问题 |
|---|---|
| 分库 | 数据库读写QPS过高,数据库连接数不足 |
| 分表 | 单表数据量过大,数据库存储遇到瓶颈 |
| 分库分表 | 连接数不足+数据量过大引起的存储性能瓶颈 |
分库分表引入的问题
多表join,不在一个库直接join不可行,但可以使用一些折中的方案,完成join等复杂查询。
1、设计全局表
所谓全局表,就是有可能系统中所有模块都可能会依赖到的一些表。比较类似我们理解的“数据字典”。为了避免跨库join查询,我们可以将这类表在其他每个数据库中均保存一份。同时,这类数据通常也很少发生修改(甚至几乎不会),所以也不用太担心“一致性”问题。
2、数据同步
假如A库中的tab_a表和B库中tbl_b有关联,可以定时将指定的表做同步。当然,同步本来会对数据库带来一定的影响,需要性能影响和数据时效性中取得一个平衡。这样来避免复杂的跨库查询。有很多优秀的数据同步的中间件可以选择,开发中复杂度不算高,开发中使用也较多。
或者干脆就不要在SQL中进行复杂的关联查询了,直接单表查询在系统层面去组装,同样很流行,而且写起来很爽。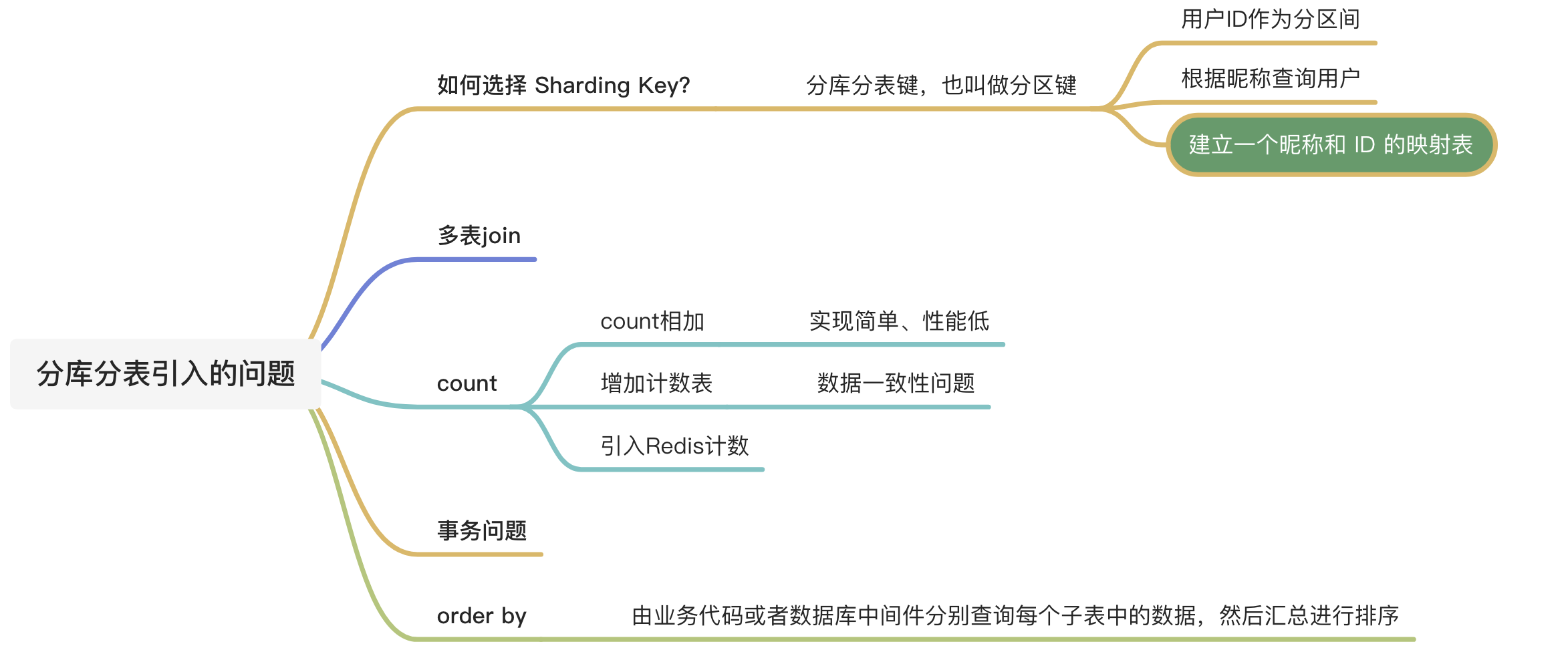
原则
非必要,不分表
1.做硬件优化,例如从机械硬盘改成使用固态硬盘,当然固态硬盘不适合服务器使用,只是举个例子
2.先做数据库服务器的调优操作,例如增加索引,oracle有很多的参数调整;
3.引入缓存技术,例如Redis,减少数据库压力
4.程序与数据库表优化,重构,例如根据业务逻辑对程序逻辑做优化,减少不必要的查询;
5.在这些操作都不能大幅度优化性能的情况下,不能满足将来的发展,再考虑分库分表,也要有预估性
分表后的ID怎么保证唯一性的呢?
- 设定步长,比如1-1024张表我们设定1024的基础步长,这样主键落到不同的表就不会冲突了。
- 分布式ID,自己实现一套分布式ID生成算法或者使用开源的比如雪花算法这种
分表后不使用主键作为查询依据,而是每张表单独新增一个字段作为唯一主键使用,比如订单表订单号是唯一的,不管最终落在哪张表都基于订单号作为查询依据,更新也一样。
分表后,
非sharding_key的查询怎么处理呢?可以做一个mapping表,比如这时候商家要查询订单列表怎么办呢?不带user_id查询的话你总不能扫全表吧?所以我们可以做一个映射关系表,保存商家和用户的关系,查询的时候先通过商家查询到用户列表,再通过user_id去查询。
- 打宽表,一般而言,商户端对数据实时性要求并不是很高,比如查询订单列表,可以把订单表同步到离线(实时)数仓,再基于数仓去做成一张宽表,再基于其他如es提供查询服务。
- 数据量不是很大的话,比如后台的一些查询之类的,也可以通过多线程扫表,然后再聚合结果的方式来做。或者异步的形式也是可以的。

若有收获,就点个赞吧
0 人点赞
