一、概述
定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。它使⽤客⼾端直连数据库,以 jar 包形式
提供服务,⽆需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
• 适⽤于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接
使⽤ JDBC。
• ⽀持任何第三⽅的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP 等。
• ⽀持任意实现 JDBC 规范的数据库,⽬前⽀持 MySQL,Oracle,SQLServer,PostgreSQL 以及任何
遵循 SQL92 标准的数据库。
二、主要作用
简化对分库分表之后的数据相关操作。
他并不是做分库分表,他只操作分库分表之后的数据,主要做两个任务:数据分片和读写分离
三、代码演示
水平分表
1)IDEA 新建一个SpringBoot工程
1-1):修改springboot版本为2.2.1.RELEASE
1-2)引入依赖:
SpringBoot 2.2.1+ MyBatisPlus + Sharding-JDBC + Druid 连接池
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId></dependency><dependency><groupId>com.alibaba</groupId><artifactId>druid-spring-boot-starter</artifactId><version>1.1.20</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId></dependency><dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-jdbc-spring-boot-starter</artifactId><version>4.0.0-RC1</version></dependency><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.0.5</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency></dependencies>
2)安装水平分库的方式,创建数据库和表
1)创建课程数据库 :course_db;
2)创建两张表(课程1、课程2):course_1、course_2;
3)确定分表规则:如果id是偶数,添加数据到course_1,如果是奇数:那么添加数据到course_2。
3)编写代码,对数据库进行操作
3-1)实体类
3-2)dao层接口
然后在启动扫描dao层接口
因为只是测试,所以不再编写controller和service了,直接再SpringBoot Test中测试。
4)配置ShardingSphere-JDBC的分片策略
官网地址:https://shardingsphere.apache.org/document/current/cn/user-manual/shardingsphere-jdbc/usage/sharding/spring-boot-starter/
配置规则:
# 配置真实数据源
spring.shardingsphere.datasource.names=ds0,ds1
# 配置第 1 个数据源
spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql://localhost:3306/ds0
spring.shardingsphere.datasource.ds0.username=root
spring.shardingsphere.datasource.ds0.password=
# 配置第 2 个数据源
spring.shardingsphere.datasource.ds1.type=com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds1.jdbc-url=jdbc:mysql://localhost:3306/ds1
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=
# 配置 t_order 表规则
spring.shardingsphere.rules.sharding.tables.t_order.actual-data-nodes=ds$->{0..1}.t_order$->{0..1}
# 配置分库策略
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-column=user_id
spring.shardingsphere.rules.sharding.tables.t_order.database-strategy.standard.sharding-algorithm-name=database_inline
# 配置分表策略
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-column=order_id
spring.shardingsphere.rules.sharding.tables.t_order.table-strategy.standard.sharding-algorithm-name=table_inline
# 省略配置 t_order_item 表规则...
# ...
# 配置 分片算法
spring.shardingsphere.rules.sharding.sharding-algorithms.database_inline.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.database_inline.props.algorithm-expression=ds_${user_id % 2}
spring.shardingsphere.rules.sharding.sharding-algorithms.table_inline.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.table_inline.props.algorithm-expression=t_order_${order_id % 2}
#上面是官网的5.x版本
# ----------------------------------------------------分割线---------------------------------------------------------
#下面是我的(4.x版本)
#分片策略配置
#配置数据源名称
spring.shardingsphere.datasource.names=course1
#配置第一个数据源
spring.shardingsphere.datasource.course1.type=com.alibaba.druid.pool.DruidDataSource
#mysql8的驱动多一个cj
spring.shardingsphere.datasource.course1.driver-class-name=com.mysql.cj.jdbc.Driver
#mysql8需要加上时区
spring.shardingsphere.datasource.course1.url=jdbc:mysql://172.16.235.3:3306/course_db?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.course1.username=root
spring.shardingsphere.datasource.course1.password=123456
# 配置 course 表规则 指定表在什么位置 分布情况
#spring.shardingsphere.sharding.tables.可变的规则名称.actual-data-nodes=数据库名称.表达式{1..2} 因为我有 course1,course2两张表
#行表达式标识符可以使用${...}或$->{...},但前者与Spring本身的属性文件占位符冲突,因此在Spring环境中使用行表达式标识符建议使用$->{...}。
spring.shardingsphere.sharding.tables.course.actual-data-nodes=course1.course_$->{1..2}
# 主键 和 生成策略
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
# SNOWFLAKE(雪花算法)/UUID
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
#指定分片策略
#cid为偶数放在course1表中,奇数放在course2中
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{cid % 2 + 1}
#打开SQL日志输出
spring.shardingsphere.props.sql.show=true
更多详见官网。。。
5)在测试启动类中编写代码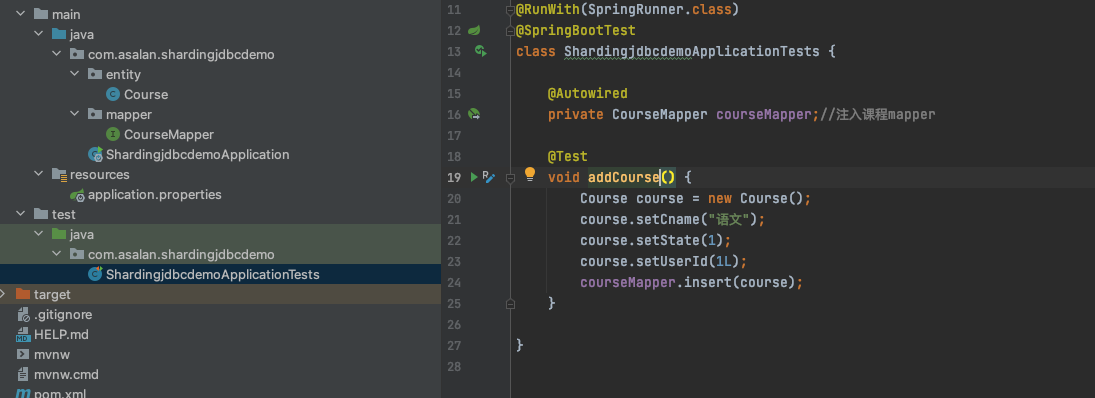
然后启动测试,你会发现,这个时候会报错
报错信息如下:
Caused by: org.springframework.beans.factory.support.BeanDefinitionOverrideException: Invalid bean definition
with name 'dataSource' defined in class path resource
[org/apache/shardingsphere/shardingjdbc/spring/boot/SpringBootConfiguration.class]: Cannot register bean definition [Root bean: class [null]; scope=;
abstract=false; lazyInit=null; autowireMode=3; dependencyCheck=0; autowireCandidate=true; primary=false;
factoryBeanName=org.apache.shardingsphere.shardingjdbc.spring.boot.SpringBootConfiguration; factoryMethodName=dataSource;
initMethodName=null; destroyMethodName=(inferred); defined in class path resource
[org/apache/shardingsphere/shardingjdbc/spring/boot/SpringBootConfiguration.class]] for bean 'dataSource':
There is already [Root bean: class [null]; scope=; abstract=false; lazyInit=null; autowireMode=3;
dependencyCheck=0; autowireCandidate=true; primary=false;
factoryBeanName=com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceAutoConfigure;
factoryMethodName=dataSource; initMethodName=init; destroyMethodName=(inferred);
defined in class path resource [com/alibaba/druid/spring/boot/autoconfigure/DruidDataSourceAutoConfigure.class]] bound.
解决方法其实已经打印出控制台最上方了
Description:
The bean 'dataSource', defined in class path resource [org/apache/shardingsphere/shardingjdbc/spring/boot/SpringBootConfiguration.class], could not be registered. A bean with that name has already been defined in class path resource [com/alibaba/druid/spring/boot/autoconfigure/DruidDataSourceAutoConfigure.class] and overriding is disabled.
Action:
Consider renaming one of the beans or enabling overriding by setting spring.main.allow-bean-definition-overriding=true
所以我们只需要将“spring.main.allow-bean-definition-overriding=true” 这个配置添加到配置文件中即可
然后再运行就不回报错了
控制台打印的SQL语句为:
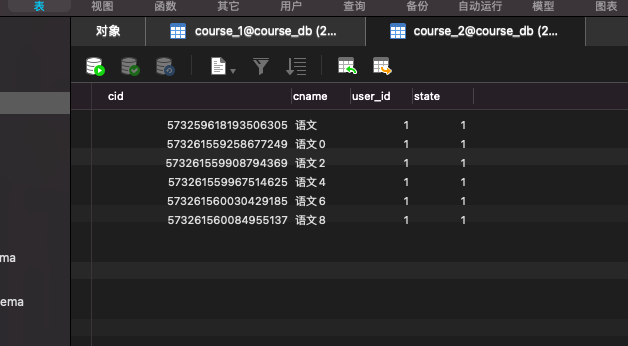
Actual SQL: course1 ::: INSERT INTO course_2 (cname, user_id, state, cid) VALUES (?, ?, ?, ?) ::: [语文, 1, 1, 573259618193506305]
可以看出 这条数据因为cid是奇数 所以插入到了course2中
为了更好的测试看看他是否会根据id来插入不同的表,所以我们批量插入10条看看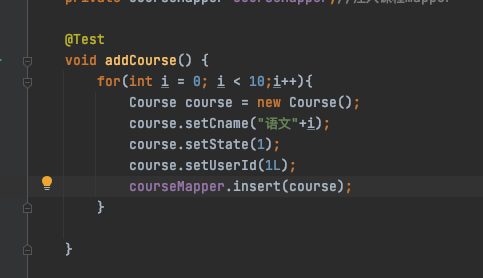
运行之后发现,成功根据id分别插入不同的表中。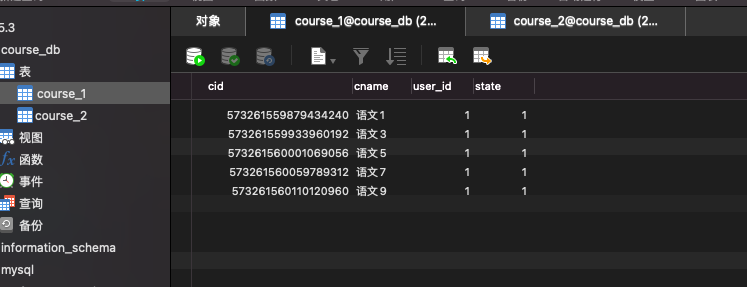
我们再来根据ID,我们就选课程名称为《语文》的ID看一下查询试一下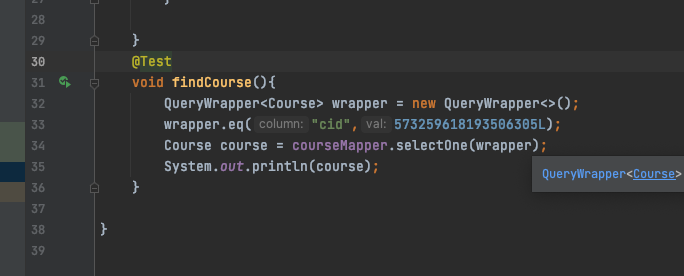

水平分库
创建两个库:course_db1,course_db2,里面也是有course_1 和course_2 两张表
定义规则:userId为偶数添加到db1中,如果为奇数,那么就添加到db2中
两么现在就有两种规则了:
一是分库的规则,二是分表的规则
一、创建库和表
二、修改配置文件**
#分片策略配置
#配置数据源名称, 水平分库,需要配置两个数据源
spring.shardingsphere.datasource.names=db1,db2
#配置第一个数据源
spring.shardingsphere.datasource.db1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.db1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.db1.url=jdbc:mysql://172.16.235.3:3306/course_db_1?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.db1.username=root
spring.shardingsphere.datasource.db1.password=123456
#配置第二个个数据源
spring.shardingsphere.datasource.db2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.db2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.db2.url=jdbc:mysql://172.16.235.3:3306/course_db_2?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.db2.username=root
spring.shardingsphere.datasource.db2.password=123456
# 配置 数据库和数据表的 分库分表规则
# 现在有两个库,分别是course_db_1和course_db_2 ,每个库里面有两个表,分别是 course_1,course_2
#1、设置分库分表规则 -------------------------------------------------------------------------------------
spring.shardingsphere.sharding.tables.course.actual-data-nodes=db$->{1..2}.course_$->{1..2}
#2、指定数据库分片策略 -------------------------------------------------------------------------------------
# userId为偶数放在course_db_1数据库中,奇数放在course_db_2数据库中
#spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=user_id
#spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=course_db$->{user_id % 2 + 1}
# 这个default是指默认全部的表的数据,都按照这个规则分片,如果只想指定特定的表(如course表),可以像下面这样做
spring.shardingsphere.sharding.tables.course.database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.course.database-strategy.inline.algorithm-expression=db$->{user_id % 2 + 1}
#3、设置表 分片策略 -------------------------------------------------------------------------------------
# 表 主键 和 生成策略
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
# 表 SNOWFLAKE(雪花算法)/UUID
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
#指定表分片策略
#cid为偶数放在course1表中,奇数放在course2中
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{cid % 2 + 1}
#打开SQL日志输出
spring.shardingsphere.props.sql.show=true
#一个实体类对应两张表的覆盖的参数
spring.main.allow-bean-definition-overriding=true
三、编写业务代码
可以看到我这里将userId设为偶数,那么肯定是添加到db1中,然后我们再看SQL语句
cid为奇数,那么位置就在 db1的course_2表中!
和水平分表一样,为了更好的测试不同情况,我们循环插入20条试试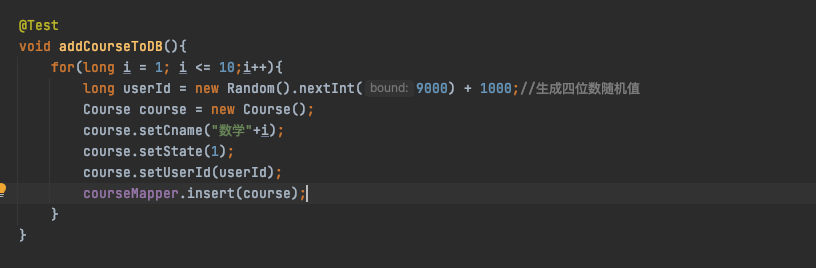
可以从数据库看到已经插入到了四张表中
然后我们测试一下用ID拿数据会不会拿到
 也是拿到了,但是好像发现了一个规律,他是分别去两张表中去拿的
也是拿到了,但是好像发现了一个规律,他是分别去两张表中去拿的
在通过“数学”模糊查询,看会不会都查询到

他好像也是从四张表(两个库)中去查询的

若有收获,就点个赞吧
0 人点赞
