一、什么是读写分离?
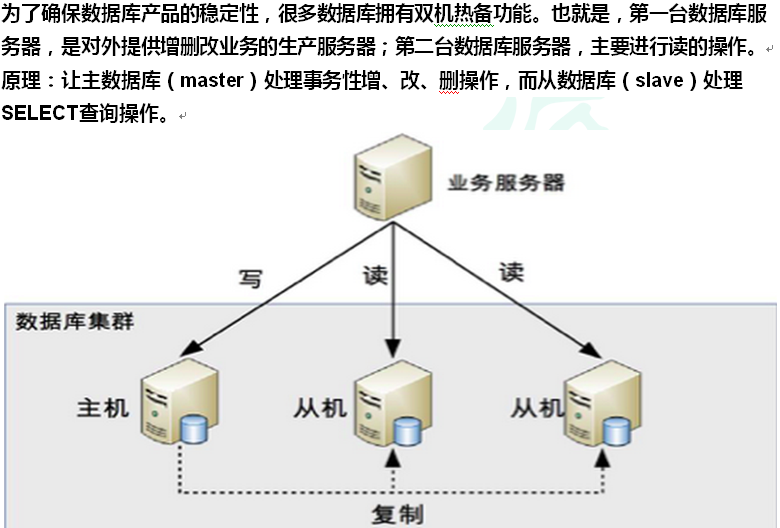
读写分离原理:MySQL开启binlog日志(记录增删改操作),实时监控binlog日志,读取日志从中提取SQL执行
,ShardingSphere-JDBC并不含有数据同步的功能。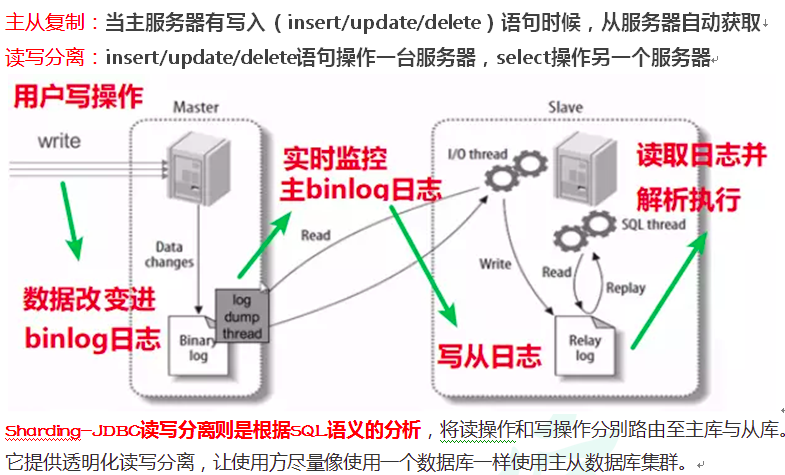
二、MySQL配置读写分离
1)在两台服务器安装MySQL并启动
2)修改主从服务器的配置文件

3)重启两台服务器的MySQL
4)创建用于主从复制的账号
4-1)在主服务器上
mysql -uroot -p123456
create user ‘back’@’172.16.235.5’ identified by ‘back123456’;
grant replication slave on . to back@172.16.235.5;
FLUSH PRIVILEGES;
SHOW master status; 确认位点,并记录下文件名以及位点
4-2)在从服务器上
先停止同步 stop SLAVE;
然后设置master
CHANGE MASTER TOmaster_host = '172.16.235.3',master_user = 'back',master_password = 'back123456',master_log_file = 'mysql-bin.000002', #这个对应filemaster_log_pos = 156; #这个对应截图的position
再启动master: start SLAVE;
查看 同步状态:show slave status;
我标注的两个地方状态必须都是YES,才能说明配置成功 4-2-1)如果Slave_IO_Runing是Connecting,说明是防火墙、账号密码等等错误,
4-2-1)如果Slave_IO_Runing是Connecting,说明是防火墙、账号密码等等错误,
4-2-3)如果Slave_IO_Runing是NO,可能是因为你的MySQL是用Docker安装或者直接克隆的虚拟机造成的,但是要先看错误日志来断定:vi /var/log/mysqld.log,
我的报错信息如下:Fatal error: The slave I/O thread stopsbecause master and slave have equal MySQL server UUIDs; these UUIDs must bedifferent for replication to work.”
这就是因为UUID是一样的,所以我们删除 /var/lib/mysql/auto.cnf 再重启mysql就能解决
4-2-3)如果Slave_IO_Runing是NO,我的解决方法如下:
stop slave;
SET GLOBAL SQL_SLAVE_SKIP_COUNTER=1;
start slave;
就行了
。。。。。具体情况看日志
4-3)注意事项:
4-3-1)查看Slave_IO_Runing和Slave_SQL_Runing字段值都为Yes,表示同步配置成功。如果不为Yes,请检查日志排查相关异常。
4-3-1)如果之前这数据库已经有主库指向, 需要执行下面的命令进行晴空
STOP SLAVE IO_THREAD FRO CHANNEL ‘’;
RESET slave all;
4-4)测试:
在从库修改一条数据
从库如果也修改了,那么说明配置成功
三、shardingSphere-JDBC具体实现步骤
1、修改配置文件
#分片策略配置
#配置数据源名称, 水平分库,需要配置两个数据源
spring.shardingsphere.datasource.names=db1,db2,master0,slave0
#配置第一个数据源
spring.shardingsphere.datasource.db1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.db1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.db1.url=jdbc:mysql://172.16.245.3:3306/course_db_1?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.db1.username=root
spring.shardingsphere.datasource.db1.password=123456
#配置第二个个数据源
spring.shardingsphere.datasource.db2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.db2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.db2.url=jdbc:mysql://172.16.245.3:3306/course_db_2?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.db2.username=root
spring.shardingsphere.datasource.db2.password=123456
#配置主数据库 数据源
spring.shardingsphere.datasource.master0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.master0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.master0.url=jdbc:mysql://172.16.245.3:3306/user_db?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.master0.username=root
spring.shardingsphere.datasource.master0.password=123456
#配置从数据库 数据源
spring.shardingsphere.datasource.slave0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.slave0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.slave0.url=jdbc:mysql://172.16.245.4:3306/user_db?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.slave0.username=root
spring.shardingsphere.datasource.slave0.password=123456
# 主库从库逻辑数据源定义 ds0 为 user_db
spring.shardingsphere.sharding.master-slave-rules.ds0.master-data-source-name=master0
spring.shardingsphere.sharding.master-slave-rules.ds0.slave-data-source-names=slave0
# 配置 user_db 数据库里面 t_user 专库专表
#spring.shardingsphere.sharding.tables.t_user.actual-data-nodes=m$->{0}.t_user
# t_user 分表策略,固定分配至 ds0 的 t_user 真实表
spring.shardingsphere.sharding.tables.t_user.actual-data-nodes=ds0.t_user
spring.shardingsphere.sharding.tables.t_user.key-generator.column=user_id
spring.shardingsphere.sharding.tables.t_user.key-generator.type=SNOWFLAKE
spring.shardingsphere.sharding.tables.t_user.database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.t_user.database-strategy.inline.algorithm-expression=t_user
#配置公共表
spring.shardingsphere.sharding.binding-tables=t_pub
spring.shardingsphere.sharding.tables.t_pub.key-generator.column=pub_id
spring.shardingsphere.sharding.tables.t_pub.key-generator.type=SNOWFLAKE
# 配置 数据库和数据表的 分库分表规则
# 现在有两个库,分别是course_db_1和course_db_2 ,每个库里面有两个表,分别是 course_1,course_2
#1、设置分库分表规则 -------------------------------------------------------------------------------------
spring.shardingsphere.sharding.tables.course.actual-data-nodes=db$->{1..2}.course_$->{1..2}
#2、指定数据库分片策略 -------------------------------------------------------------------------------------
# userId为偶数放在course_db_1数据库中,奇数放在course_db_2数据库中
#spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=user_id
#spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=course_db$->{user_id % 2 + 1}
# 这个default是指默认全部的表的数据,都按照这个规则分片,如果只想指定特定的表(如course表),可以像下面这样做
spring.shardingsphere.sharding.tables.course.database-strategy.inline.sharding-column=user_id
spring.shardingsphere.sharding.tables.course.database-strategy.inline.algorithm-expression=db$->{user_id % 2 + 1}
#3、设置表 分片策略 -------------------------------------------------------------------------------------
# 表 主键 和 生成策略
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
# 表 SNOWFLAKE(雪花算法)/UUID
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
#指定表分片策略
#cid为偶数放在course1表中,奇数放在course2中
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{cid % 2 + 1}
#打开SQL日志输出
spring.shardingsphere.props.sql.show=true
#一个实体类对应两张表的覆盖的参数
spring.main.allow-bean-definition-overriding=true
2、编写测试代码
就用之前的添加用户的代码就行了
YES!

若有收获,就点个赞吧
0 人点赞
