要想让机器人变得聪明,也得教会它响应的内容,但凭一己之力终究教的内容是有限的,那么就联网从网上获取相应的内容吧。而联网就需要一种接口来来连接机器人和网络,这种接口有一个名字叫做应用程序接口(Application Programming Interface),简称API,因为网络上的有用的信息都是别人做好的,我们要想调用的话一般就需要注册他们对应平台的账号,然后付费使用api,
当然也有一些免费开放的api供开发测试。
现在我们就联网查询一下天气信息而不是我们自己手写的天气内容,这里就用到了天气API。
http://wthrcdn.etouch.cn/weather_mini?city=北京
把上面城市名称可以换成自己所在城市
url = "http://wthrcdn.etouch.cn/weather_mini?city=郑州"
要从网络上获取url地址的内容的话,需要pip install requests安装这样一个库,然后调用该库的get方法,get到整个网址里面的所有内容,而我们只需要里面text的内容,所以再取其text就行:
import requestsurl = "http://wthrcdn.etouch.cn/weather_mini?city=郑州"res = requests.get(url)txt = res.textprint(txt)
如此我们就拿到了郑州近一周的天气情况,该天气格式为json。
然后就可以再取出具体的内容通过语音合成播放出来了。
或者使用百度天气的API:
http://api.map.baidu.com/telematics/v3/weather?location={城市名}&output={返回格式}&ak={百度AppKey}
而偶然发现的一个apihttps://sp0.baidu.com/5a1Fazu8AA54nxGko9WTAnF6hhy/su?wd=关键词f&json=1,可以把在对话中要问的问题给进行进一步联想从而逼疯提问者,可以一直跟你打太极,只需要适时替换关键词。
除了天气之外,如果想要让改机器人更加聪明,比如能讲笑话、能背古诗、能回答一些百科知识,就需要特定的API接口了,那么有没有更加方便的呢?也就是智能聊天机器人的API,这里推荐使用有图灵机器人、小i机器人和青云客提供的在线机器人接口。其中图灵机器人的效果应该是最为出色的,但是要花钱包月,而小i机器人的连接也时断时续,所以我们挑选了青云客提供的在线机器人。不用注册账户直接使用。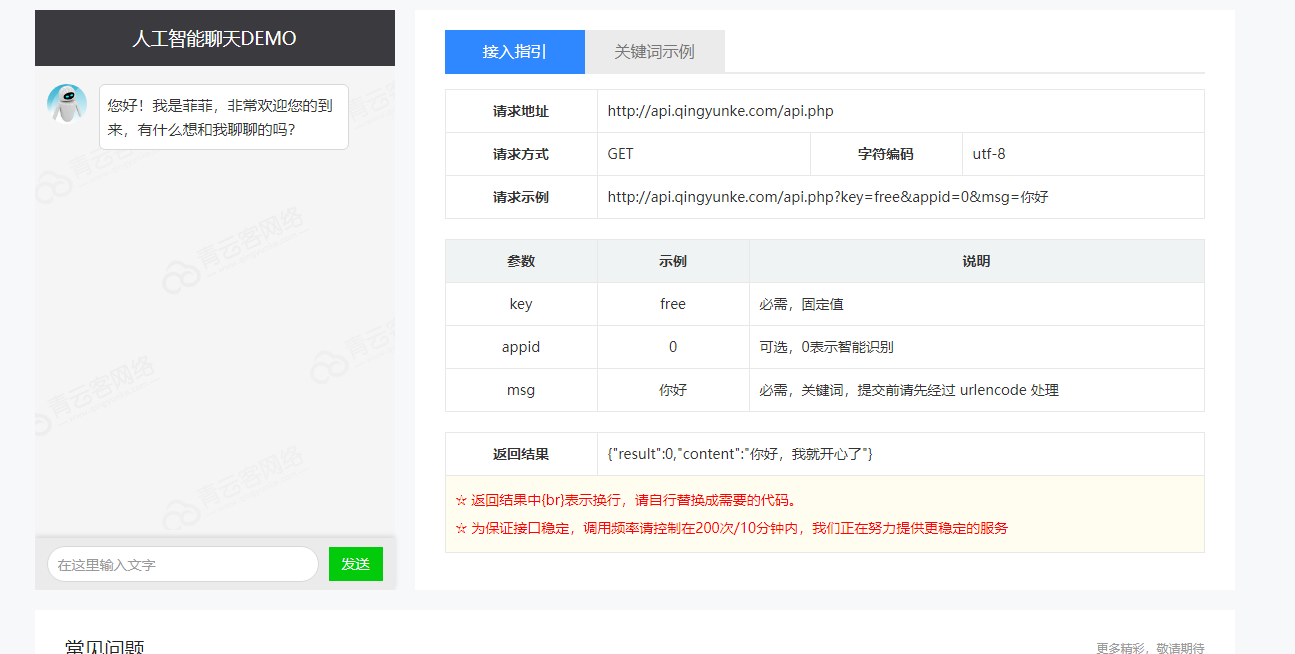
import requestsurl = "http://api.qingyunke.com/api.php?key=free&appid=0&msg=郑州天气"res = requests.get(url)txt = res.textprint(txt)
返回结果如下:
import requestsurl = "http://api.qingyunke.com/api.php?key=free&appid=0&msg=讲个笑话"res = requests.get(url)txt = res.textprint(txt)
返回结果如下:
也就是只需要用存储我们讲话的变量替换掉url里面最后的关键词即可:
import requestscontent = "讲个笑话"url = "http://api.qingyunke.com/api.php?key=free&appid=0&msg="+contentres = requests.get(url)txt = res.textprint(txt)
现在再把之前写的能够语音对答的程序拿过来:
import jsonfrom aip import AipSpeechimport pyaudioimport waveinput_filename = "input.wav" # 麦克风采集的语音输入input_filepath = "../src/" # 输入文件的pathin_path = input_filepath + input_filenamedef get_audio(filepath):CHUNK = 256FORMAT = pyaudio.paInt16CHANNELS = 1 # 声道数RATE = 11025 # 采样率RECORD_SECONDS = 5WAVE_OUTPUT_FILENAME = filepathp = pyaudio.PyAudio()stream = p.open(format=FORMAT,channels=CHANNELS,rate=RATE,input=True,frames_per_buffer=CHUNK)print("*"*10, "开始录音:请在5秒内输入语音")frames = []for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):data = stream.read(CHUNK)frames.append(data)print("*"*10, "录音结束\n")stream.stop_stream()stream.close()p.terminate()wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')wf.setnchannels(CHANNELS)wf.setsampwidth(p.get_sample_size(FORMAT))wf.setframerate(RATE)wf.writeframes(b''.join(frames))wf.close()#申请百度语音识别APP_ID = '16835749'API_KEY = 'UnZlBOVhwYu8m5eNqwOPHt99'SECRET_KEY = '6jhCitggsR0Ew91fdC47oMa1qtibTrsK'client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)# 读取文件def get_file_content(filePath):with open(filePath, 'rb') as fp:return fp.read()def result_word():# 识别本地文件# path='/Users/alice/Documents/Blog/AI/语音识别/speechrecognition/audiofiles'get_audio(in_path)test1 = client.asr(get_file_content(in_path), 'pcm', 16000, {'dev_pid': 1536, })# print(test1["result"])if test1["err_no"]==3307:test1["result"]=["请讲话"]return test1["result"][0]print(result_word())from playsound import playsounddef playAudio(txt):resultAudio = client.synthesis(txt, 'zh', 1, { 'vol': 2,'per':4 })if not isinstance(resultAudio, dict):with open('audio.mp3', 'wb') as f:f.write(resultAudio)playsound("audio.mp3")import osos.remove("audio.mp3")with open("语料库.txt","r",encoding="utf-8") as lib:lists = lib.readlines()# print(lists)# print(len(lists))while True:print("请开始对话:")ask = result_word()a = 0b = 0while a==0:for i in range(0,len(lists),2):if lists[i].find(ask)!=-1:print(lists[i+1][2:])playAudio(lists[i+1][2:])b =1breaka = 1if b==0:print("你问的问题太深奥,我还没学会呢,换个问题吧")playAudio("你问的问题太深奥,我还没学会呢,换个问题吧")print("请开始对话:")ask = result_word()a = 0
然后进行修改替换如下:就是把whlie循环里面的内容替换掉:
import jsonfrom aip import AipSpeechimport pyaudioimport waveinput_filename = "input.wav" # 麦克风采集的语音输入input_filepath = "../src/" # 输入文件的pathin_path = input_filepath + input_filenamedef get_audio(filepath):CHUNK = 256FORMAT = pyaudio.paInt16CHANNELS = 1 # 声道数RATE = 11025 # 采样率RECORD_SECONDS = 5WAVE_OUTPUT_FILENAME = filepathp = pyaudio.PyAudio()stream = p.open(format=FORMAT,channels=CHANNELS,rate=RATE,input=True,frames_per_buffer=CHUNK)print("*"*10, "开始录音:请在5秒内输入语音")frames = []for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):data = stream.read(CHUNK)frames.append(data)print("*"*10, "录音结束\n")stream.stop_stream()stream.close()p.terminate()wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')wf.setnchannels(CHANNELS)wf.setsampwidth(p.get_sample_size(FORMAT))wf.setframerate(RATE)wf.writeframes(b''.join(frames))wf.close()#申请百度语音识别APP_ID = '16835749'API_KEY = 'UnZlBOVhwYu8m5eNqwOPHt99'SECRET_KEY = '6jhCitggsR0Ew91fdC47oMa1qtibTrsK'client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)# 读取文件def get_file_content(filePath):with open(filePath, 'rb') as fp:return fp.read()def result_word():# 识别本地文件# path='/Users/alice/Documents/Blog/AI/语音识别/speechrecognition/audiofiles'get_audio(in_path)test1 = client.asr(get_file_content(in_path), 'pcm', 16000, {'dev_pid': 1536, })# print(test1["result"])if test1["err_no"]==3307:test1["result"]=["请讲话"]return test1["result"][0]print(result_word())from playsound import playsounddef playAudio(txt):resultAudio = client.synthesis(txt, 'zh', 1, { 'vol': 2,'per':4 })if not isinstance(resultAudio, dict):with open('audio.mp3', 'wb') as f:f.write(resultAudio)playsound("audio.mp3")import osos.remove("audio.mp3")import requestswhile True:content_word=result_word()url="http://api.qingyunke.com/api.php?key=free&appid=0&msg="+content_wordres = requests.get(url)txt = json.loads(res.text)txt=txt["content"]playAudio(txt)
现在就可智能对话了,只不过还有一些问题,首先就是第一句话是识别不到的,然后是返回的内容里面还有一些其他字符像换行符{br}也会读出来,而影响对话体验。还有就是程序启动之后一直傻啦吧唧的捕捉外部声音,捕捉不到就一直循环播放“因为人家笨嘛”,一点都不聪明。那么如何改进程序呢,如下添加判断语句:
import osimport requestsimport waveimport jsonimport pyaudiofrom aip import AipSpeechfrom playsound import playsound#申请百度语音识别APP_ID = '16835749'API_KEY = 'UnZlBOVhwYu8m5eNqwOPHt99'SECRET_KEY = '6jhCitggsR0Ew91fdC47oMa1qtibTrsK'client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)input_filename = "input.wav" # 麦克风采集的语音输入input_filepath = "../src/" # 输入文件的pathin_path = input_filepath + input_filenamedef get_audio(filepath):CHUNK = 256FORMAT = pyaudio.paInt16CHANNELS = 1 # 声道数RATE = 11025 # 采样率RECORD_SECONDS = 5WAVE_OUTPUT_FILENAME = filepathp = pyaudio.PyAudio()stream = p.open(format=FORMAT,channels=CHANNELS,rate=RATE,input=True,frames_per_buffer=CHUNK)print("*"*10, "开始录音:请在5秒内输入语音")frames = []for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):data = stream.read(CHUNK)frames.append(data)print("*"*10, "录音结束\n")stream.stop_stream()stream.close()p.terminate()wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')wf.setnchannels(CHANNELS)wf.setsampwidth(p.get_sample_size(FORMAT))wf.setframerate(RATE)wf.writeframes(b''.join(frames))wf.close()# 读取文件def get_file_content(filePath):with open(filePath, 'rb') as fp:return fp.read()def result_word():# 识别本地文件# path='/Users/alice/Documents/Blog/AI/语音识别/speechrecognition/audiofiles'test1 = client.asr(get_file_content(in_path), 'pcm', 16000, {'dev_pid': 1536, })# print(test1["result"])if test1["err_no"]==3307:test1["result"]=["请讲话"]return test1["result"][0]print(result_word())def playAudio(txt):resultAudio = client.synthesis(txt, 'zh', 1, { 'vol': 2,'per':4 })if not isinstance(resultAudio, dict):with open('audio.mp3', 'wb') as f:f.write(resultAudio)playsound("audio.mp3")os.remove("audio.mp3")a = 0while True:get_audio(in_path)content_word=result_word()if content_word=="请讲话":if a == 0:playAudio("你是不是没有讲话")a=1else:url="http://api.qingyunke.com/api.php?key=free&appid=0&msg="+content_wordres = requests.get(url)txt = json.loads(res.text)txt=txt["content"].replace("br","")print(txt)playAudio(txt)a=0

若有收获,就点个赞吧
0 人点赞
