现在开始Debug过程,首先在识别的程序里添加if判断语句,以防止录音为空的时候中断程序,并进行一个提示,这里也是找到识别结果的json格式数据中有err_on标识的那个标志错误码,我们用这个来进行判断是否识别出错。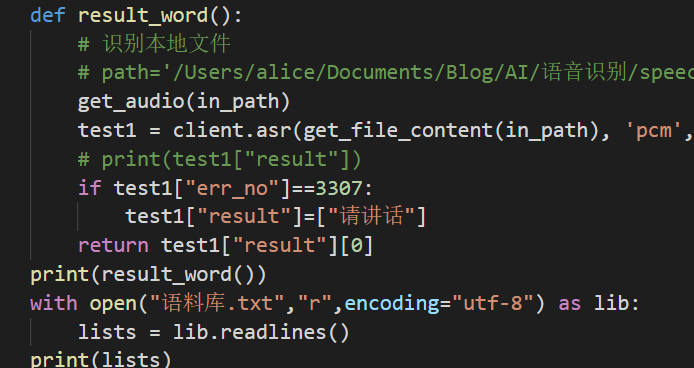
修改完之后,我们把语音合成的也放进来:
import jsonfrom aip import AipSpeechimport pyaudioimport waveinput_filename = "input.wav" # 麦克风采集的语音输入input_filepath = "../src/" # 输入文件的pathin_path = input_filepath + input_filenamedef get_audio(filepath):CHUNK = 256FORMAT = pyaudio.paInt16CHANNELS = 1 # 声道数RATE = 11025 # 采样率RECORD_SECONDS = 5WAVE_OUTPUT_FILENAME = filepathp = pyaudio.PyAudio()stream = p.open(format=FORMAT,channels=CHANNELS,rate=RATE,input=True,frames_per_buffer=CHUNK)print("*"*10, "开始录音:请在5秒内输入语音")frames = []for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):data = stream.read(CHUNK)frames.append(data)print("*"*10, "录音结束\n")stream.stop_stream()stream.close()p.terminate()wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')wf.setnchannels(CHANNELS)wf.setsampwidth(p.get_sample_size(FORMAT))wf.setframerate(RATE)wf.writeframes(b''.join(frames))wf.close()#申请百度语音识别APP_ID = '16835749'API_KEY = 'UnZlBOVhwYu8m5eNqwOPHt99'SECRET_KEY = '6jhCitggsR0Ew91fdC47oMa1qtibTrsK'client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)# 读取文件def get_file_content(filePath):with open(filePath, 'rb') as fp:return fp.read()def result_word():# 识别本地文件# path='/Users/alice/Documents/Blog/AI/语音识别/speechrecognition/audiofiles'get_audio(in_path)test1 = client.asr(get_file_content(in_path), 'pcm', 16000, {'dev_pid': 1536, })# print(test1["result"])if test1["err_no"]==3307:test1["result"]=["请讲话"]return test1["result"][0]print(result_word())from playsound import playsounddef playAudio(txt):resultAudio = client.synthesis(txt, 'zh', 1, { 'vol': 2,'per':4 })if not isinstance(resultAudio, dict):with open('audio.mp3', 'wb') as f:f.write(resultAudio)playsound("audio.mp3")with open("语料库.txt","r",encoding="utf-8") as lib:lists = lib.readlines()print(lists)print(len(lists))while True:print("请开始对话:")ask = result_word()a = 0b = 0while a==0:for i in range(0,len(lists),2):if lists[i].find(ask)!=-1:print(lists[i+1])playAudio(lists[i+1])b =1breaka = 1if b==0:print("你问的问题太深奥,我还没学会呢,换个问题吧")playAudio("你问的问题太深奥,我还没学会呢,换个问题吧")print("请开始对话:")ask = result_word()a = 0
以上程序基本能简单实现想要的功能了,但是运行起来发现,语音合成的时候,会把语料库里面的回答内容整个合成出来,包括Q,A这些无用的提示字母,这里我们使用一种方法进行剔除:
a="1234567"print(a[2:])#就是从第三位开始输出

还有别的字符串操作方法:
使用.pop()方法。输入参数,即为要删除的索引。
string = '公众号:土堆碎念'list_str = list(string)list_str.pop(1)list_str = ''.join(list_str)print(list_str)#结果就是剔除了第二位“众”
这个是剔除特定字符。
上述程序在语音合成时候,只能合成一次,除非重启程序,否则就会提示权限不够,无法重新合成播放audio.mp3文件,这是因为playsound()这个方法在程序运行开始第一次使用后会一直占用audio.mp3,所以在接下来的播放就会提示无法打开该文件。但因为该playsound()不再维护,所以只能自己修改其方法了,这里有两个解决方法,一个是合成播放完之后直接删除该文件:
import osos.remove("audio.mp3")
另一个解决方法就是找到安装路径下的playsound()库文件,在python安装目录下的~\Python36\Lib\site-packages找到playsound.py
打开该文件,找到以下代码位置: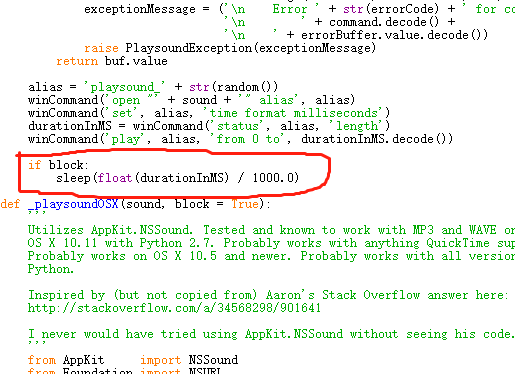
在红圈位置,添加 winCommand(‘close’, alias),即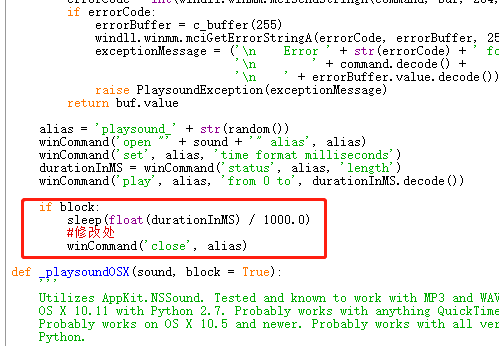
然后保存就可以了。但是该方法只适用于windows系统下的python环境。
修改过的程序如下:
import jsonfrom aip import AipSpeechimport pyaudioimport waveinput_filename = "input.wav" # 麦克风采集的语音输入input_filepath = "../src/" # 输入文件的pathin_path = input_filepath + input_filenamedef get_audio(filepath):CHUNK = 256FORMAT = pyaudio.paInt16CHANNELS = 1 # 声道数RATE = 11025 # 采样率RECORD_SECONDS = 5WAVE_OUTPUT_FILENAME = filepathp = pyaudio.PyAudio()stream = p.open(format=FORMAT,channels=CHANNELS,rate=RATE,input=True,frames_per_buffer=CHUNK)print("*"*10, "开始录音:请在5秒内输入语音")frames = []for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):data = stream.read(CHUNK)frames.append(data)print("*"*10, "录音结束\n")stream.stop_stream()stream.close()p.terminate()wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')wf.setnchannels(CHANNELS)wf.setsampwidth(p.get_sample_size(FORMAT))wf.setframerate(RATE)wf.writeframes(b''.join(frames))wf.close()#申请百度语音识别APP_ID = '16835749'API_KEY = 'UnZlBOVhwYu8m5eNqwOPHt99'SECRET_KEY = '6jhCitggsR0Ew91fdC47oMa1qtibTrsK'client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)# 读取文件def get_file_content(filePath):with open(filePath, 'rb') as fp:return fp.read()def result_word():# 识别本地文件# path='/Users/alice/Documents/Blog/AI/语音识别/speechrecognition/audiofiles'get_audio(in_path)test1 = client.asr(get_file_content(in_path), 'pcm', 16000, {'dev_pid': 1536, })# print(test1["result"])if test1["err_no"]==3307:test1["result"]=["请讲话"]return test1["result"][0]print(result_word())from playsound import playsounddef playAudio(txt):resultAudio = client.synthesis(txt, 'zh', 1, { 'vol': 2,'per':4 })if not isinstance(resultAudio, dict):with open('audio.mp3', 'wb') as f:f.write(resultAudio)playsound("audio.mp3")import osos.remove("audio.mp3")with open("语料库.txt","r",encoding="utf-8") as lib:lists = lib.readlines()# print(lists)# print(len(lists))while True:print("请开始对话:")ask = result_word()a = 0b = 0while a==0:for i in range(0,len(lists),2):if lists[i].find(ask)!=-1:print(lists[i+1][2:])playAudio(lists[i+1][2:])b =1breaka = 1if b==0:print("你问的问题太深奥,我还没学会呢,换个问题吧")playAudio("你问的问题太深奥,我还没学会呢,换个问题吧")print("请开始对话:")ask = result_word()a = 0
当然可能还存在一些问题,比如程序启动后就会一直监听我们的讲话,并进行语音反馈,如果只是想要再需要的时候机器人才会进行回答,或者只有捕捉识别到有效信息才进行回答响应,其他时间都保持休眠静默状态,注意这里休眠是指程序还在运行状态,这也是现在语音助手为啥都要有一个唤醒词的原因。
JSON
上述问题,在接下让我们的机器人联网之后再继续优化解决,现在要做的的是了解json的文件格式,因为联网之后,从网络上获取到的内容多是以json的格式传回来的,JSON是一种简单的数据交换格式。能够在服务器之间交换数据,关于json的特点这里简单介绍几个:
1、JSON是纯文本;
2、JSON具有良好的自我描述性,便于阅读;
3、JSON具有层级结构(值中存在值);
4、 数据格式比较简单, 易于读写, 格式都是压缩的, 占用带宽小;
Q:你叫什么名字
A:你好,我是瓦力,我是一个机器人
Q:你几岁了
A:我5岁了~
Q:你是男生还是女生
A:我当然是男生了,伊娃才是女生呢
Q:最近天气怎么样
A:你想问哪里天气
Q:你不会定位吗
A:你还没给我添加自动定位的功能
Q:郑州天气怎么样
A:你想问郑州哪一天的天气
Q:你不会自己看时间吗,当然是明天啦
A:郑州明天天气,阴,有短时雷暴,空气质量良。
重点看后面跟天气有关的几句,如果前面几句可以随机提问对交互体验影响不大的话,那么后面个天气有关的问答,就最好按顺序提问了,要不然就真的顺序错乱了。那么我们呢能不能把跟某一主题有关的放在一个类别里面呢?当然可以。
我们可以用python直接读取txt文件,把前6行放进一个列表里,后面几行放进另一个列表里。那能不能在新建语料库的时候就很直观。这样既方便后期自己看,也方便程序读取呢?所以我们需要另一种文件格式,也是在程序中流行的一种文件格式,json。新建“语料库.json”:
{"question":{"person":{"name":"你叫什么名字","age":"你几岁了","sex":"你是男生还是女生"},"weather":{"city":"最近天气怎么样","location":"你不会定位吗","date":"郑州天气怎么样","data":"你不会自己看时间吗,当然是明天啦"}},"answer":{"person":{"name":"你好,我是瓦力,我是一个机器人","age":"我5岁了","sex":"我当然是男生了,伊娃才是女生呢"},"weather":{"city":"你想问哪里天气","location":"你还没给我添加自动定位的功能","date":"你想问郑州哪一天的天气","data":"郑州明天天气,阴,有短时雷暴,空气质量良。"}}}
用python读取json文件程序如下:
import jsonwith open("语料库.json","r",encoding="utf-8") as lib:lists = json.load(lib)print(lists["question"]["person"]["name"])#输出结果就是能立刻找到“你叫什么名字”这句话

若有收获,就点个赞吧
0 人点赞
