索引基础
索引
索引是加快查询的一种数据结构,原理是插入时对记录排序,缺点是影响插入/更新的性能;
MySQL 当前支持 B+树索引、全文索引、R 树索引;
B+树索引的结构
B+ 树索引由根节点(root node)、中间节点(non leaf node)、叶子节点(leaf node)组成。叶子节点存放所有排序后的记录。根节点和中间节点存放索引键对, 索引键是用于排序的列、值是指针,指向下一层的地址。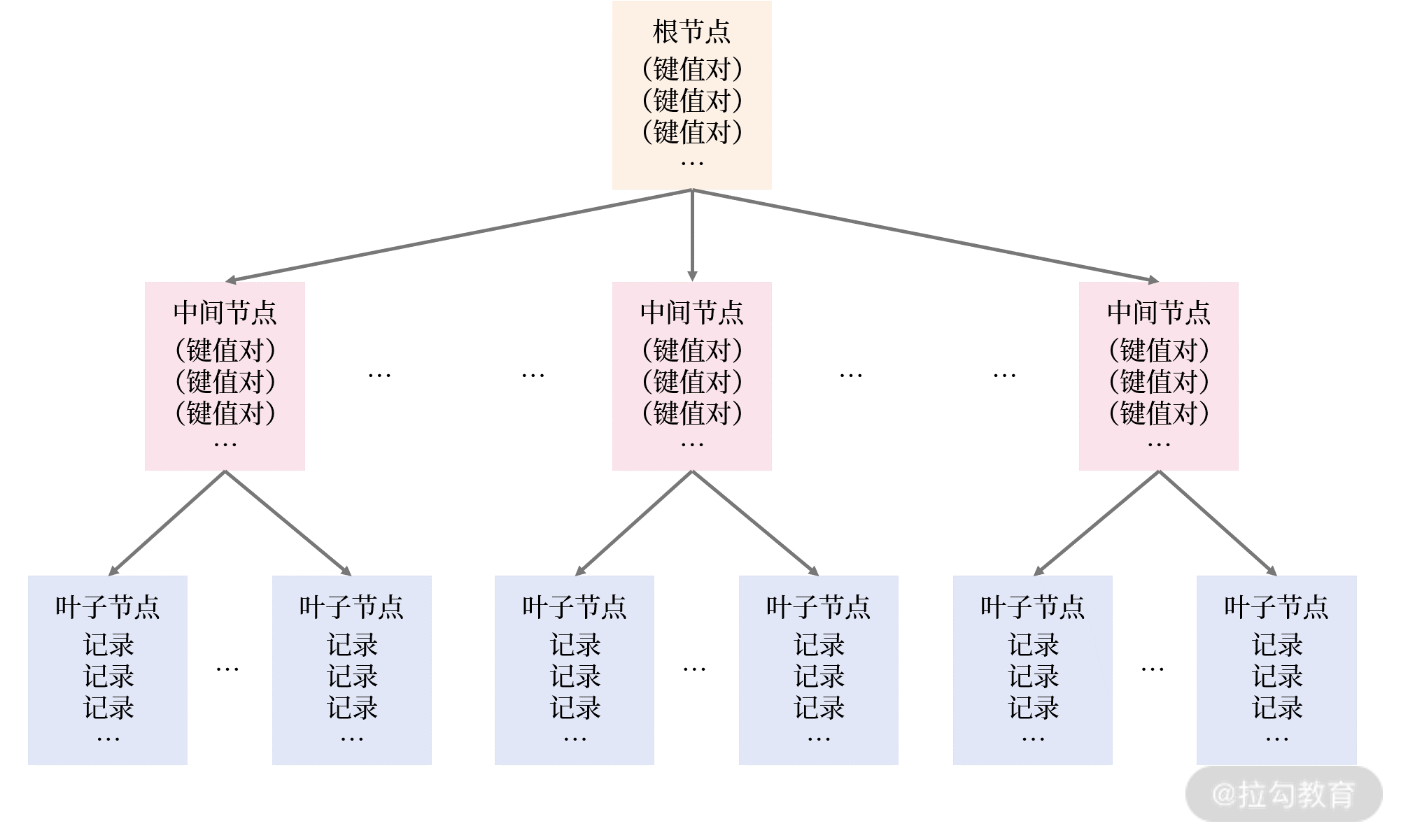
(B+ 树)索引是对记录进行排序。叶子节点间,节点内的数据都是有序的。
根据 B+ 树索引 查询记录,只用进行二分查找,就能快速定位数据。
B+树高度与记录数
B+ 树索引的高度通常为 3~4 层,高度为 4 的 B+ 树能存放 54 亿左右的数据。
3层:800万 ~ 19660660
4层:54亿 ~ 19660660*660
B+ 树的高度不高,因此查询效率极高,54 亿的数据也只需要 4 次 I/O,大概仅需 0.004 秒。如果这些查询的页已经被缓存在内存缓冲池中,查询性能会更快。
根据高度计算存放记录数:
索引键值对,索引 BIGINT 是 8 字节; innoDB 引擎的指针是 6 字节,一个页的大小为 16K。
根节点能最多存放以下多个键值对 = 16K / 键值对大小(8+6) ≈ 1100
假设每条记录的大小为 500 字节:
叶子节点能存放的最多记录为 = 16K / 每条记录大小 ≈ 32
树高度为 2 的 B+ 树索引,最多能存放的记录数为:
总记录数 = 1100 * 32 = 35,200
树高度为 3 的 B+ 树索引,最多能存放的记录数为:
总记录数 = 1100(根节点) 1100(中间节点) 32 = 38,720,000
真实环境中,每个页存在一些碎片,假设每个页的使用率为60%
根节点/非叶节点存放键值对数:11000.6=660
叶子节点存放记录数:320.6=19
B+树索引的维护
所有 B+ 树都是从高度为 1 的树开始,然后根据数据的插入,慢慢增加树的高度。
插入 B+ 树索引的记录变多,1个页(16K)无法存放这么多数据,所以会发生 B+ 树的分裂,B+ 树的高度变为 2。当 B+ 树的高度大于等于 2 时,根节点和中间节点存放的是索引键值对。
插入性能优化
插入性能优化,本质就是在插入数据时,降低维护 B+ 树索引的成本。
两种数据插入情况:顺序/逆序插入、无序插入:
有序:索引的维护代价非常小,叶子节点都是从左往右进行插入。
比较典型的是自增 ID 的插入、时间的插入(若在自增 ID 上创建索引,时间列上创建索引,则 B+ 树插入比较快的)。
无序:B+ 树为了维护排序,需要对页进行分裂、旋转等开销较大的操作;
另外,对于固态硬盘,随机写的性能也不如顺序写,所以磁盘性能也会受到较大影响。
比较典型的是用户昵称,每个用户注册时,昵称是随意取的,若在昵称上创建索引,插入是无序的,索引维护需要的开销会比较大。
B+ 树索引的使用规范
01 保证主键的索引有序
比如使用自增,或使用函数 UUID_TO_BIN 排序的 UUID,而不用无序值做主键。
02 索引数量
MySQL 单表的索引没有个数限制,若业务查询有具体需要,创建对应的索引即可。
但注意优化器并不会使用低效的索引。无效索引占用了空间,又影响了插入的性能。
B+ 树索引的管理
查询表 mysql.innodb_index_stats 查看每个索引的大致情况。
查询表 sys.schema_unused_indexes,查看有哪些索引一直未被使用过,可以被废弃
MySQL 8.0 版本推出了索引不可见(Invisible)功能。
在删除废弃索引前,可将索引设置为对优化器不可见,然后观察业务是否有影响。
InnoDB 存储引擎的索引
索引组织表是核心。本质就是 MySQL 如何存储数据和索引对象的。
目标就是降低维护索引的成本。
索引组织表
数据存储有堆表和索引组织表两种方式。
堆表:堆表中的数据是无序的,索引的叶子节点存放了数据在堆表中的地址。
堆表中的数据发生改变,且位置发生了变更,所有索引中的地址都要更新,十分影响性能,特别是对于 OLTP 业务。
索引组织表:
数据根据主键排序存放在索引中,主键索引也叫聚集索引(Clustered Index)。
在索引组织表中,万物皆索引,索引就是数据,数据就是索引。
二级索引
除了主键索引外,其他的索引都称之为二级索引(Secondeary Index)
二级索引也是一颗 B+ 树索引,和主键索引不同的是叶子节点存放的是索引键值、主键值。
通过二级索引 idx_name 只能定位主键值,需要额外再通过主键索引进行查询,才能得到最终的记录。这种“二级索引通过主键索引进行再一次查询”的操作叫作“回表”。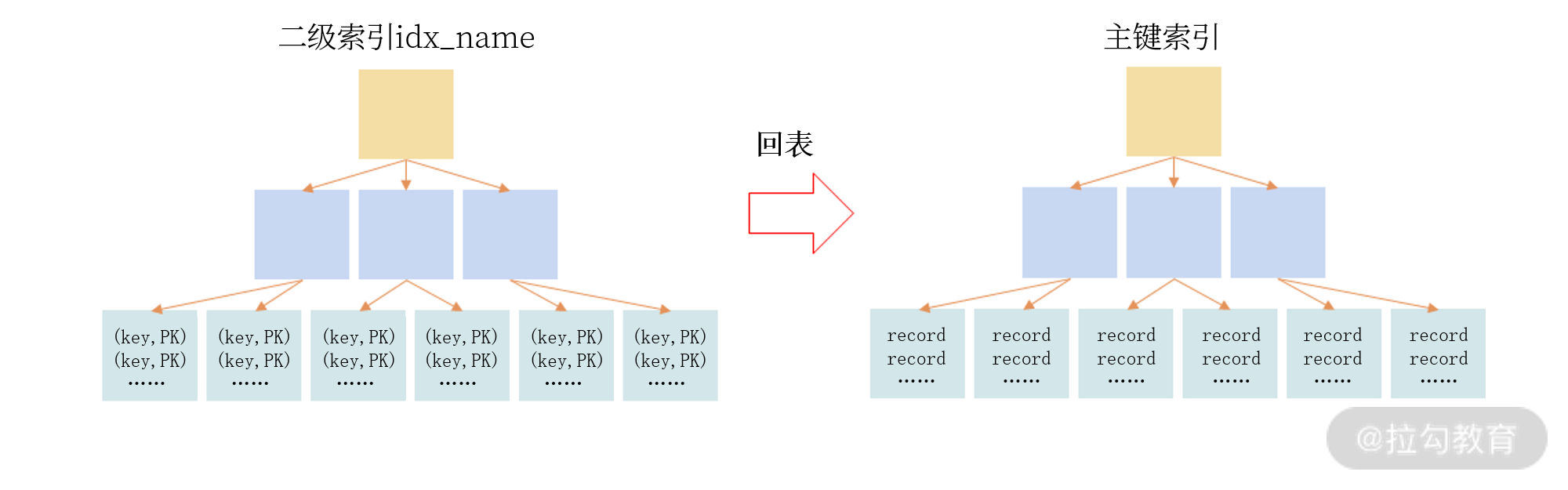
可以将二级索引按照一张表来进行理解
根据 二级索引 name 进行查询/插入的 SQL 可以理解为拆分成了两个步骤。
//查询数据时SELECT id FROM idx_name WHERE name = ?SELECT * FROM User WHERE id = _id; -- 回表//插入数据时START TRANSATION;INSERT INTO User VALUES (...) -- 主键索引INSERT INTO idx_name VALUES (...) -- 二级索引COMMIT;
唯一索引
对于索引,还可以加入唯一的约束,具有唯一约束的索引称之为唯一索引,也是二级索引。
具有唯一约束的索引:
CREATE TABLE User (id BIGINT AUTO_INCREMENT,name VARCHAR(128) NOT NULL,sex CHAR(6) NOT NULL,registerDate DATETIME NOT NULL,...PRIMARY KEY(id), -- 主键索引UNIQUE KEY idx_name(name) -- 二级索引)
可以理解为:
CREATE TABLE idx_name (name VARCHAR(128) NOT NULL,id BIGINT NOT NULL,PRIAMRY KEY(name,id)) -- 二级索引CREATE TABLE check_idx_name (name VARCHAR(128),PRIMARY KEY(name),) -- 唯一约束

若有收获,就点个赞吧
0 人点赞
