课程介绍
课程背景
涉及海量数据处理的企业,就一定要用到分库分表。如何进行海量数据的分库分表设计和迁移,有效存储和访问海量业务数据?
课程目的
基于 ShardingSphere 框架,介绍主流的分库分表解决方案和工程实践。
课程结构
1 在业务中使用ss
2 ss核心功能
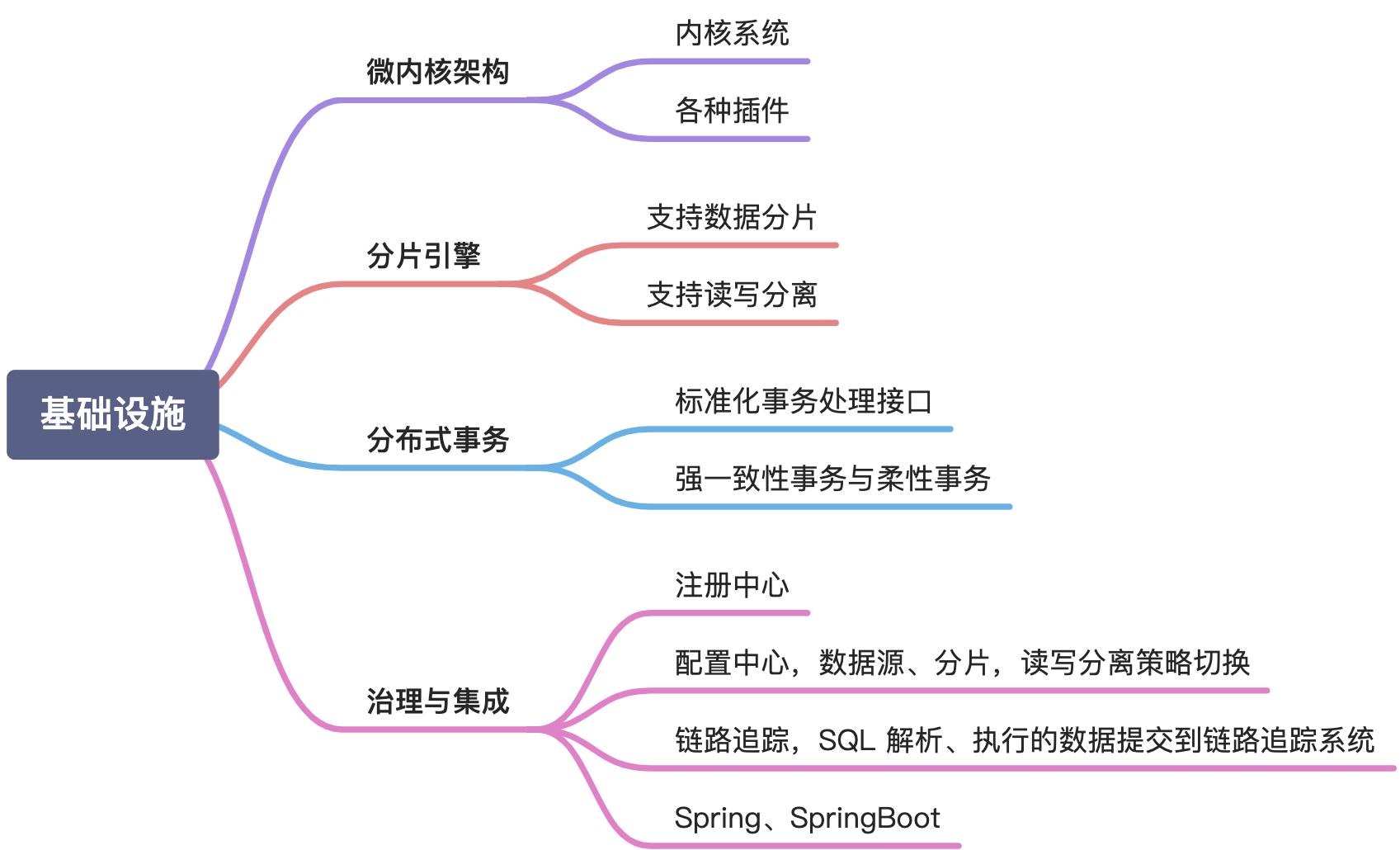
3 ss内核架构 基础设施、分片引擎、分布式事务、治理与集成
技术体系相通
ss的技术体系与 Dubbo、Spring Cloud 等主流开发框架相通
比如 zk 的动态监听机制、配置信息管理。
基于 SPI 机制的微内核架构、基于雪花算法的分布式主键、
基于 Apollo 的配置中心、基于 Nacos 的注册中心、
基于 Seata 的柔性事务、基于 OpenTracing 规范的链路跟踪等。
学习总结
解析引擎部分的鸡汤:
https://kaiwu.lagou.com/course/courseInfo.htm?courseId=257#/detail/pc?id=3575
学习源码
版本:4.0.1
设计模式的应用(如外观模式、工厂模式、策略模式、模板方法等)、
微内核架构等架构模式、
组件设计和类层结构划分的思想和实现策略、
常见缓存的应用以及自定义缓存机制的实现、
Spring 家族框架的集成和整合等开发技巧
业务中引入ShardingSphere
分库分表
分库分表解决单表数据量过大而导致的数据库性能降低的问题。
MySQL 单表容量在百万级别比较合适。关系型数据库又比NoSQL 稳定,成熟;支持事务。
因此采用分库分表的方案来解决单库表的瓶颈问题
种类:水平拆分;垂直拆分;分库;分表
垂直分表: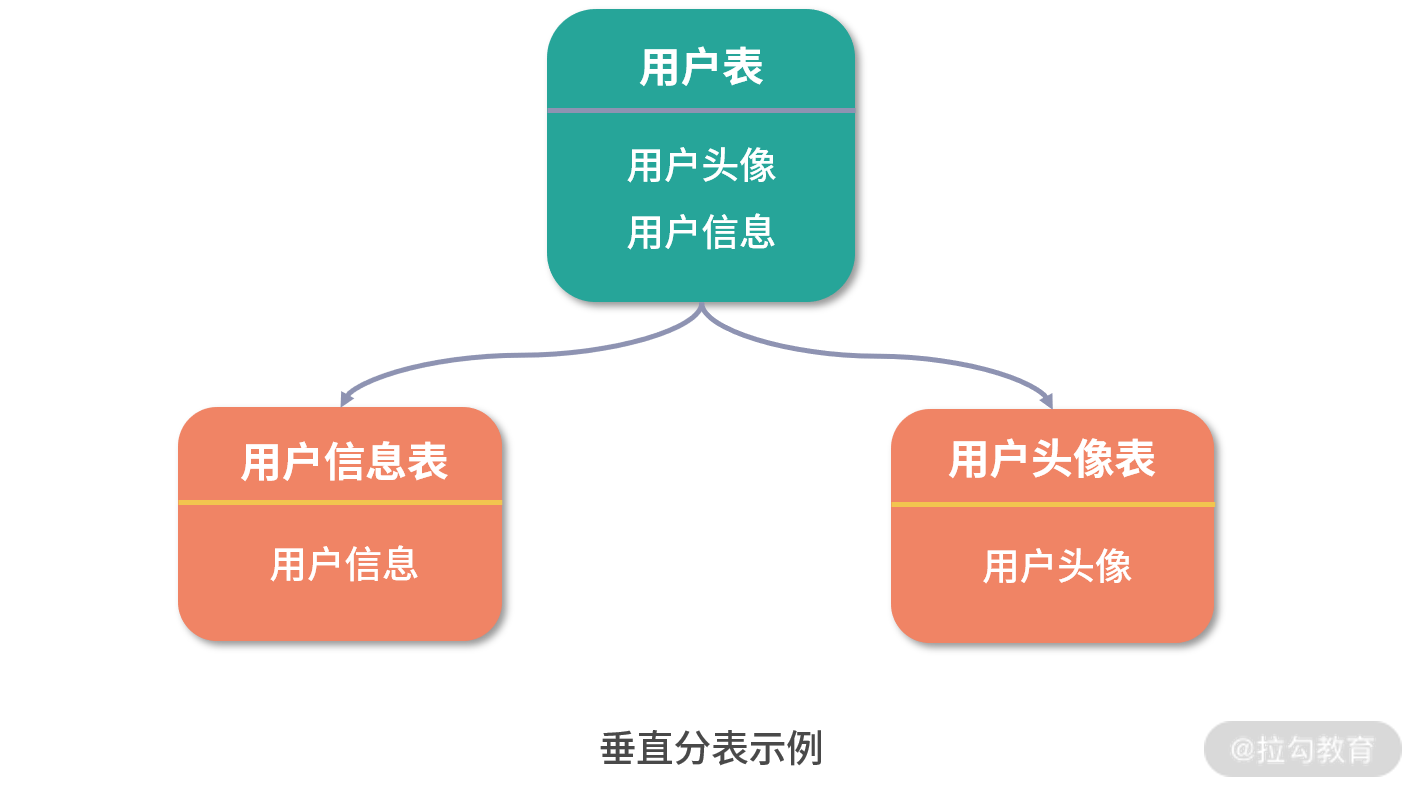
垂直分库:
但并不能解决单表数据量过大这一核心问题,往往需要在垂直拆分的基础上添加水平拆分机制。
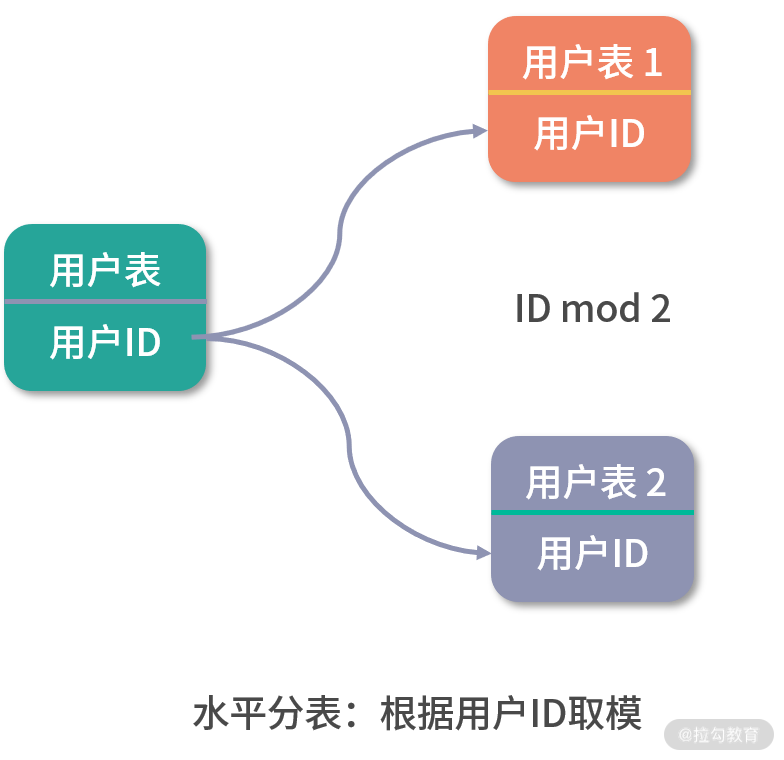
水平分库分表的取模算法。
读写分离
MySQL 数据库提供了完善的主从架构,能够确保主数据库与从数据库之间的数据同步。基于主从架构,就可以按照操作要求对读操作和写操作进行分离,从而提升访问效率。
在互联网系统中,数据库读操作的频率要远远高于写操作,所以瓶颈往往出现在读操作上。通过读写分离,就可以把读操作分离出来,在独立的从库上进行。
现实中的主从架构,主库和从库的数量,尤其从库的数量都是可以根据数据量的大小进行扩充的。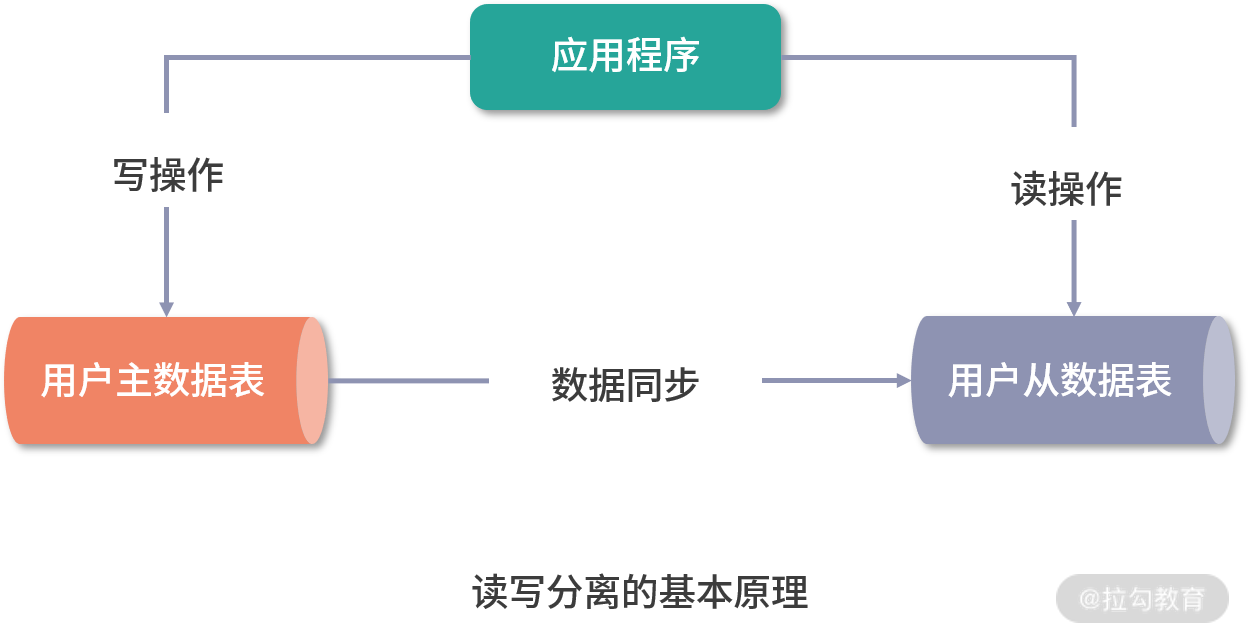
具体的数据同步细节可以见面1分库分表
分库分表+读写分离

分库分表解决方案
无论是分库还是分表,都是把数据划分成不同的数据片,并存储在不同的目标对象中。
客户端分片:
数据库的客户端实现了分片规则,决定 SQL 执行所对应的目标数据库和数据表。业务代码引入包含分片处理逻辑的公共 JAR 包即可。
重写JDBC协议实现分片操作和业务解耦。
eg:ShardingSphere 重写 JDBC 规范实现客户端分片。
代理服务器分片:
业务逻辑与分片解耦;代理机制影响网络传输性能。

eg:Sharding-Proxy 模块来实现代理服务器分片;Mycat;Cobar
分布式数据库:
数据分片及分布式事务是分布式数据库内置的基础功能。
RD 只需要使用框架对外提供的 JDBC 接口
ShardingSphere 结构
ShardingSphere 由 Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar 这三款相互独立的产品组成,其中前两款已经正式发布。
Sharding-JDBC
JDBC 是一种开发规范,指定了 DataSource、Connection、Statement、PreparedStatement、ResultSet 等一系列接口。而各大数据库供应商通过实现这些接口提供了自身对 JDBC 规范的支持。
Sharding-JDBC 对外暴露的一套分片操作接口与 JDBC 规范中所提供的接口完全一致。优点:
01 使用简单
开发人员只需要了解 JDBC,就可以使用 Sharding-JDBC 来实现分库分表,Sharding-JDBC 内部屏蔽了分片规则和处理逻辑的复杂性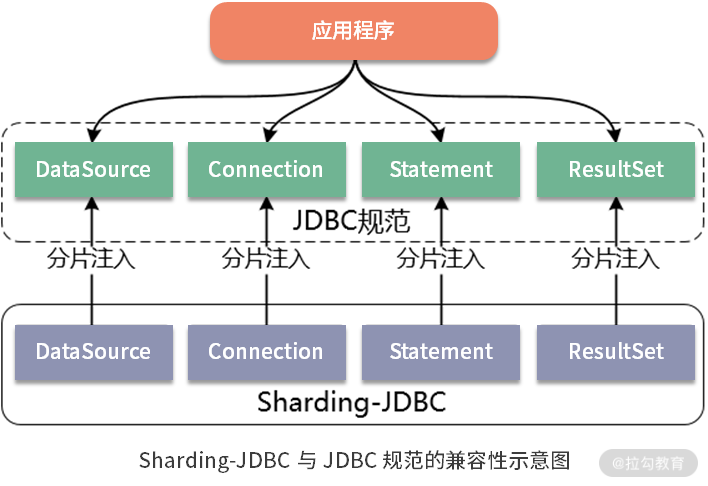
02 无缝集成多种组件和框架
用于提供数据库连接的 DBCP、C3P0 等数据库连接池组件,以及用于提供对象-关系映射的 Hibernate、MyBatis 等 ORM 框架
Sharding-JDBC 以 JAR 包的形式提供服务。开发人员可以使用这个 JAR 包直连数据库,无需额外的部署和依赖管理。
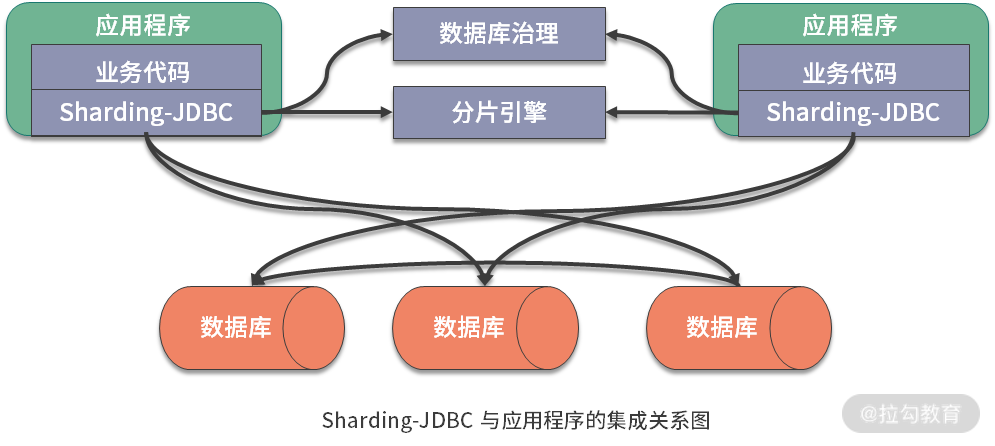
Sharding-Proxy
Sharding-Proxy 可以视为一个数据库,用来代理后面分库分表的多个数据库,它屏蔽了后端多个数据库的复杂性。
Sharding-Proxy 提供静态入口以及异构语言的支持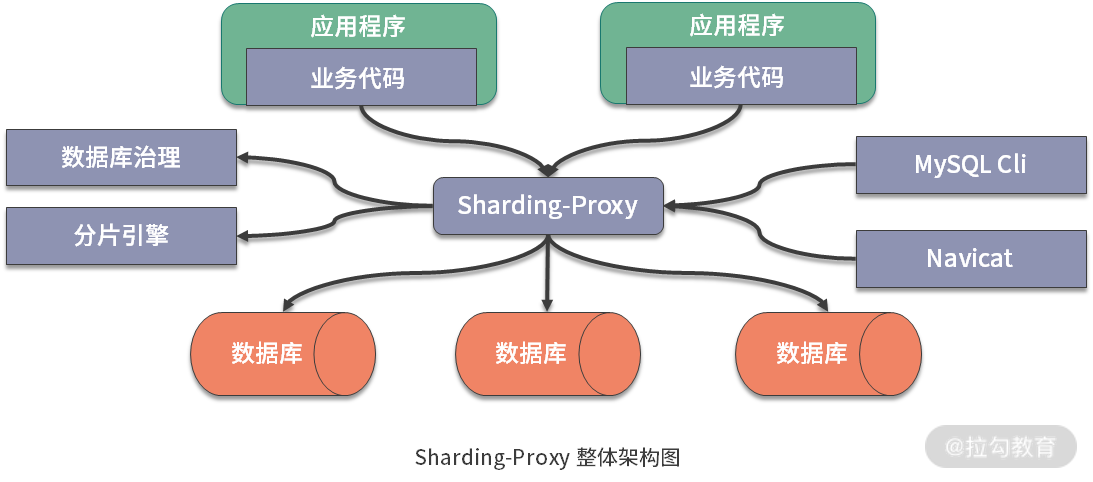
Sharding-Proxy 的运行同样需要依赖于完成分片操作的分片引擎以及用于管理数据库的治理组件。
基于底层共通的分片引擎,以及数据库治理功能,可以混合使用 Sharding-JDBC 和 Sharding-Proxy,以便应对不同的应用场景和不同的开发人员
整体功能
ShardingSphere 与 JDBC 的关系
理解 JDBC 规范以及 ShardingSphere 对 JDBC 规范的重写方式,是正确使用 ShardingSphere 实现数据分片的前提。
JDBC(Java Database Connectivity)的设计初衷是提供一套用于各种数据库的统一标准
DataSource 是官方定义的获取 Connection 的基础接口,
ConnectionPoolDataSource 是从连接池 ConnectionPool 中获取的 Connection 接口,
XADataSource 则用来实现在分布式事务环境下获取 Connection。
ShardingSphere 的集成
ShardingSphere 的配置
ShardingSphere 的主要工作在于根据业务需求完成各种分片操作相关配置项的设置。
掌握了 ShardingSphere 的核心配置项,就相当于掌握了这个框架的使用方法。
ShardingSphere 用 行表达式 简化和统一配置信息的一种工具
以分片引擎为例,核心配置项:
TableRuleConfiguration:分库分表配置
ShardingStrategyConfiguration:
配置体系的作用本质上就是用来初始化 DataSource 等 JDBC 对象。
例如,ShardingDataSourceFactory 就是基于传入的数据源 Map、ShardingRuleConfiguration 以及 Properties 来创建一个 ShardingDataSource 对象
配置方式
Java 代码配置
Yaml 配置
Spring 命名空间配置
Spring Boot配置
无论采用哪种配置方式,所有的配置项都是在这些核心配置类的基础之上进行封装和转换。
外部的 Yaml 文件中获取了一个 ShardingRuleConfiguration 对象,然后使用 ShardingDataSourceFactory 工厂类完成目标 DataSource 的创建过程。
如何设计和实现开源框架!!!
底层工具
开源框架所依赖的第三方工具。这种底层工具往往不是框架本身可以控制和管理的,框架的作用只是在它上面添加一个应用层,用于封装对这些底层工具的使用方式。
基础规范
考虑开发人员目前在使用的基础规范。例如设计一个与链路跟踪相关的开源框架,一般都需要兼容 OpenTracing 这一开放式分布式追踪规范。
开发框架
比如SpringBoot、Spring
领域框架
所谓领域框架,是指与所设计的开源框架属于同一专业领域的开发框架。
对于ShardingSphere 而言,领域框架指的是 MyBatis、Hibernate 等常见的 ORM 框架。ShardingSphere 对领域框架提供了无缝集成的实现方案
ShardingSphere 治理
框架本身并不负责如何采集、存储以及展示应用性能监控的相关数据,而是将整个数据分片引擎中最核心的 SQL 解析与 SQL 执行相关信息发送至应用性能监控系统,并交由其处理。
ShardingSphere 仅负责产生具有价值的数据,并通过标准协议递交至第三方系统,而不对这些数据做二次处理。
ShardingSphere 核心功能
ShardingSphere 分片引擎
解析、路由、改写、执行、归并
解析:根据输入的 SQL 语句生成一个 SQLStatement 对象
路由:基于 SQLStatement 和上下文信息,获取匹配数据库和表的分片策略,生成路由结果。
解析引擎的核心对象
要想完成分片操作,首先需要引入 SQL 解析引擎。
输入:一条 SQL 语句
内部:解析 SQL 语句
输出:SQLStatement 对象,供后续的 ShardingRouter 等路由引擎进行使用。
SQLParseEngine 是整个链路的最底层对象。
一方面,在 DataSource 的创建过程中,最终初始化了 SQLParseEngine;
另一方面,ShardingRouter 依赖于 SQLParseEngine。
SQLParseEngine 是 ShardingSphere 中负责 SQL 解析过程的入口。
从解析引擎到解析内核
存在一批以“Engine”结尾的引擎类。从架构思想上看,这些类在设计和实现上普遍采用了外观模式。
外观模式为子系统中的一组接口定义了一个高层接口,这个接口使得这一子系统对客户端透明,更加容易使用。
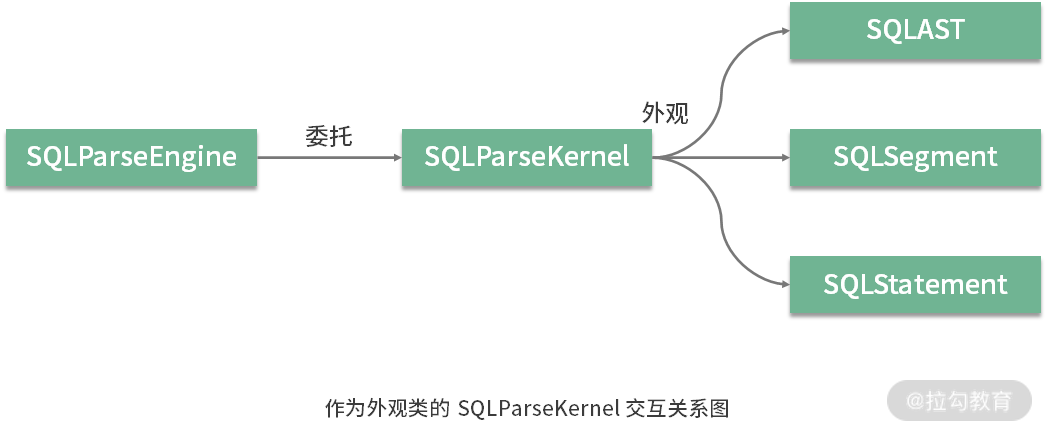
01 SQLParseEngine的创建
去阅读源码
RuntimeContext 在 ShardingSphere 中充当一种运行时上下文,保存着与运行时环境下相关的分片规则、分片属性、数据库类型、执行引擎以及 SQL 解析引擎。
AbstractRuntimeContex 在其构造函数中,通过工厂类 SQLParseEngineFactory 完成对 SQLParseEngine 的构建
02 解析引擎的三大阶段:解析、提取和填充
核心类通过简单的调用方式组合在一起完成业务链路:
通过 SQLParserEngine 生成 SQL 抽象语法树。
通过 SQLSegmentsExtractorEngine 提取 SQLSegment
通过 SQLStatementFiller 填充 SQLStatement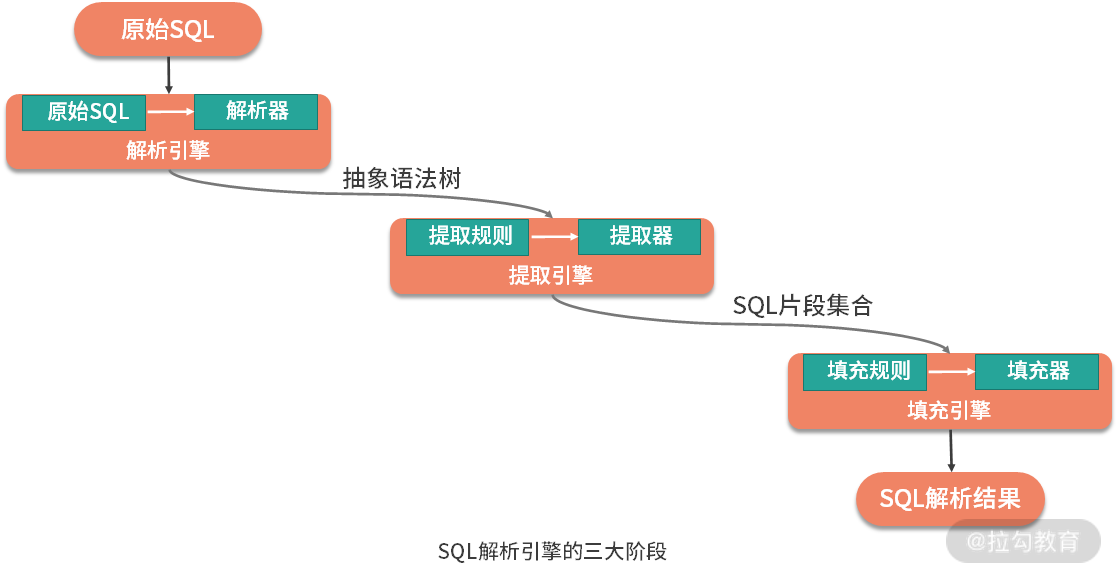
step 01:
ANTLR4 的 AST 生成机制。
step 02:
针对某一条 SQL,遍历 SQLStatementRule 中所配置的提取器,然后从 Context 中提取对应类型的 SQLSegment,并最终存放在一个集合对象中进行返回。
ShardingSphere 中内置了一大批通用的 SQLSegment,包括查询选择项(SelectItems)、表信息(Table)、排序信息(OrderBy)、分组信息(GroupBy)以及分页信息(Limit)等。
针对各种数据库,ShardingSphere 提供了相应的 SQLSegment 的提取器定义。以 Mysql 为例,在其代码工程的 META-INF/parsing-rule-definition/mysql 目录下,存在一个 extractor-rule-definition.xml 配置文件,专门用来定义针对 Mysql 的各种 SQLSegmentExtractor,
step 03:
通过填充器 SQLSegmentFiller 为 SQLStatement 注入具体 SQLSegment 的过程。
SQLSegmentFiller、SQLSegment 和 SQLStatement 三者的关系:
去阅读源码
采用了回调机制来完成对象的注入
根据数据库类型和SQLSegment找到对应的SQLSegmentFiller,并为SQLStatement填充SQLSegment
路由引擎
分层架构

若有收获,就点个赞吧
0 人点赞
