数据页的物理存储
学习索引的物理存储之前,需要清楚数据页的物理存储结构。
指针存储的是相邻数据页在磁盘文件里的position或者offset。
数据页之间组成双向链表;数据页内的数据行组成单向链表。

每个数据页都有包含一个页目录指针,里面根据数据行的主键存放了一个目录。
数据行被分散到不同的槽位,每个数据页的目录,存放的是这个页里,主键和槽位的映射关系。
根据主键查数据:
通过二分查找在目录里迅速定位到主键对应的数据行在哪个槽位里,然后到那个槽位里去,遍历槽位里每一行数据,就能快速找到那个主键对应的数据了。每个操作里都有一组数据行,你就是在里面遍历查找就可以了。
根据非主键查找数据:
无法像使用主键那样,根据页目录进行二分查找,只能进入到数据行构成的单向链表,遍历查找数据。
如果有很多数据页,只能逐个把数据页加载到内存,然后遍历数据页里的数据行,俗称“全表扫描”。
页分裂
在动态插入数据时,会在数据页间移动数据行,保证下一个数据页里的主键比上一个数据页的主键值大。
主键索引
针对主键的索引实际上就是主键目录,这个主键目录就是把每个数据页的页号,还有数据页里最小的主键值放在一起,组成一个索引的目录
B+ 树索引结构
表里的数据可能很多很多,比如有几百万、几千万,甚至单表几亿条数据都是有可能的。
有大量的数据页,然后你的主键目录就要存储大量的数据页和最小主键值,实际上是把索引数据存储在数据页。
如果索引页的数据太多了,就会分裂!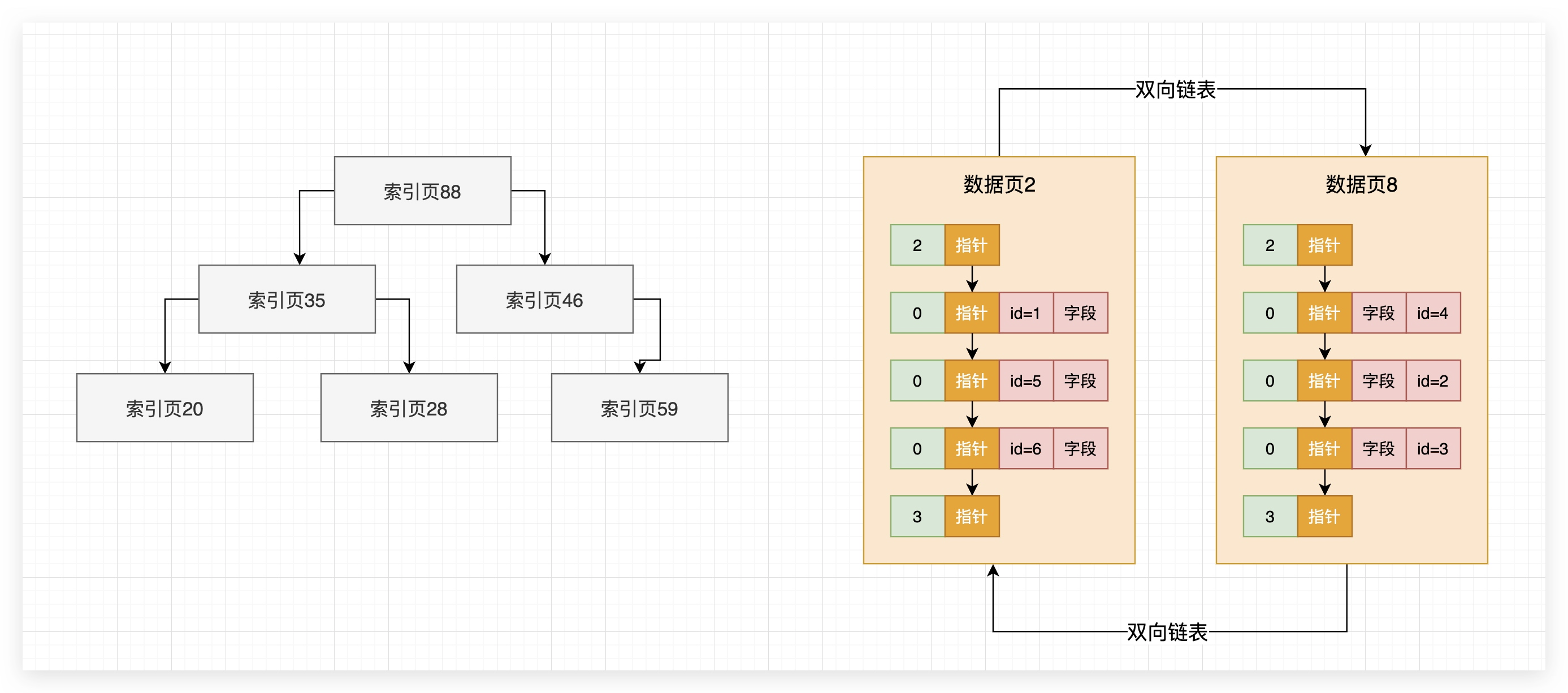
以主键索引为例,为一个表的主键建立索引之后,其实主键索引就是一颗B+树。
根据主键来查数据时,从B+树的顶层开始二分查找,一层一层往下定位,最终定位到一个数据页里,在数据页内部的目录里二分查找,找到那条数据。
聚簇索引
聚簇索引是InnoDB存储引擎默认创建的基于主键的索引结构。
而且表里的数据就是直接放在聚簇索引里的,作为叶子节点的数据页。
如果一颗大的B+树索引数据结构里,叶子节点是数据页,此时称这颗B+树索引为聚簇索引。
索引页+数据页组成的B+树就是聚簇索引。核心:
1 最下层索引页,有指针引用数据页
2 索引页之间组成双向链表
聚簇索引的维护
在InnoDB存储引擎里,对数据增删改时,就是直接把你数据页放在聚簇索引里的,数据就在聚簇索引里,聚簇索引就包含了数据,比如插入数据,那么就是在数据页里插入数据。
如果数据页开始进行页分裂了,会调整各个数据页内部的行数据,保证数据页内、页间的主键值都是有顺序的。同时在页分裂的时候,会维护上层索引数据结构,在上层索引页里维护索引条目(不同的数据页和最小主键值)。
如果数据页越来越多,一个索引页放不下了,此时就会生成新的索引页,同时更新上层的索引页。上层索引页里维护索引条目(下层索引页页号和最下主键值)。
按照这个顺序,以此类推,数据量越大,此时可能就会多出更多的索引页层级来。
一般索引页里可以放很多索引页条目。即使对于亿级的大表,建的索引的层级也就三四层而已。
聚簇索引默认按照主键来组织的。
在增删改数据的时候,一方面会更新数据页,一方面会自动维护(B+树结构的)聚簇索引。
二级索引
假设要针对其他字段建立索引,比如name字段,也是一样的原理。在插入数据的时候:
一方面,把数据插入到聚簇索引的叶子节点的数据页里去,并且维护好聚簇索引; 另一方面,会为该字段维护一棵 B+ 树索引
该字段的B+树索引会构建多层级的索引页。索引页存放的是下一层的页号和最小name字段值,以及最小字段name值对应的主键值,因为有可能多个索引页指向的name字段相同。
该B+树索引的叶子节点也是数据页,但是这个数据页里仅仅放主键字段和name字段。
该B+树索引的数据页(叶子节点)页间和页内的 name 值都是按照大小排序的。
查询过程:
如果要根据name字段来搜索数据,会先从 name字段的索引B+树的根节点开始找,一层一层往下找,一直找到叶子节点的数据页里,定位到name字段值对应的主键值。
针对select from table where name = ‘xx’这样的语句,先根据name字段值在name字段的索引B+树里找,*找到叶子节点也就可以找到对应的主键值,而找不到这行数据完整的所有字段。
此时还需要进行“回表”。需要根据主键值,再到聚簇索引里从根节点开始,找到叶子节点的数据页,定位到主键对应完整数据行,此时才能把select *要的全部字段值都拿出来。
一般把name字段这种普通字段的索引称之为二级索引,一级索引就是聚簇索引。
联合索引
联合索引只不过是建立一颗独立的B+树。
叶子节点的数据页里放了id+name+age,数据页页间、页内默认按照name排序,name一样就按照age排序。
索引页存放的是下层节点的页号和最小的name和age的值。
根据name+age搜索的时候,就会走name+age联合索引的这颗B+树了,搜索到主键,再根据主键到聚簇索引里去搜索。
索引的优缺点
索引的本质是空间换查询时间。
添加索引也会导致增删改操作耗时更长,因为要维护每棵B+树索引的有序性。
总结
建立一个索引的本质就是建立对应字段的B+树,根据B+树一层一层二分查找。
增删改的时候,一方面在数据页里更新数据,一方面就是维护B+树的索引。

若有收获,就点个赞吧
0 人点赞
