

面试题

问题 1 分库分表的逻辑
阶段1: mysql 单表百万记录、2k qps。
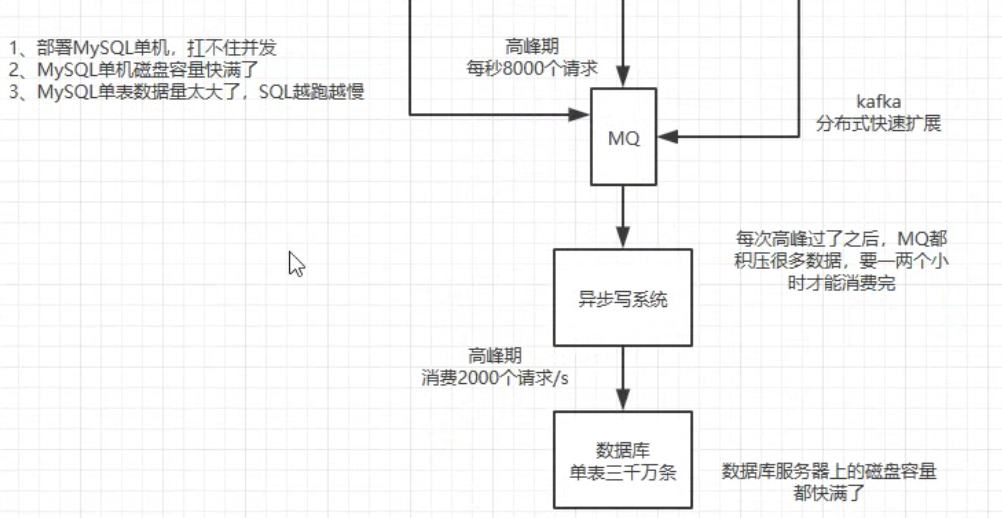
阶段2: partition 分区 + mysql 分库分表
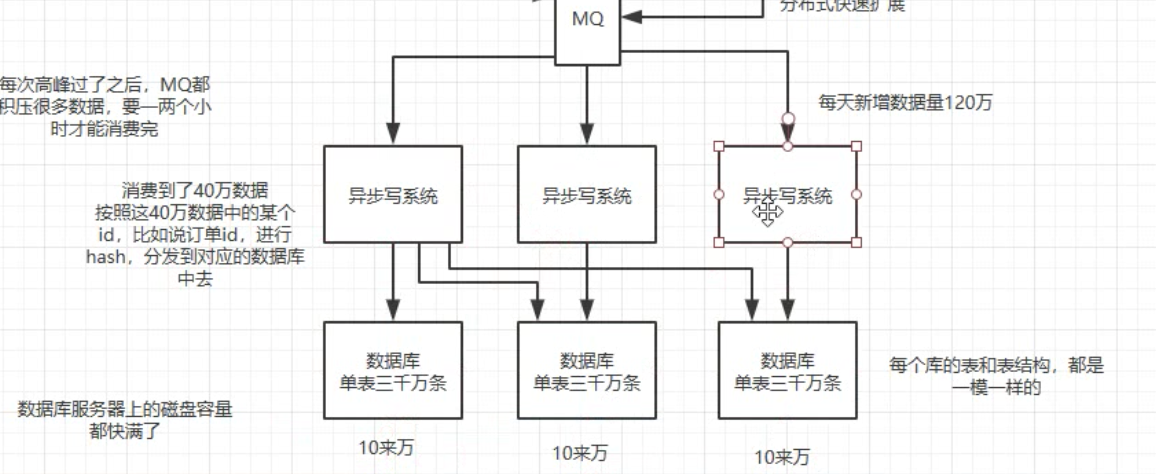

引入分库分表中间件
中间件分几种类型:
一种是jar包,在client端;一种是独立部署的,proxy层。
sharding-jdbc 是client端,性能高,耦合依赖,适合中小企业。
proxy层,部署维护需要运维团队,适合大厂。
如何拆分
垂直拆分:字段分成经常访问,不经常访问的字段。
水平拆分:600w行,拆到三台机器,每台200w行。
水平拆分和垂直拆分可以组合使用。
但是其实垂直拆分在数据库设计时就应该做了。
实际做法01:按照哈希分!!!
用id分别取mod。先分到m个库、再分到库里的n个表。
实际做法02:按照range分!!!
按照时间范围,就是按照range分。
对比:
range分,除非是访问最新的数据。
hash分,可以均摊请求,但是扩容比较麻烦。
问题 2 未分库分表平滑迁移到分库分表
方案1 停机
pre:先看mycat、sharding-jdbc的入门例子
阶段1:停止外部访问,进行数据迁移
阶段2:修改系统设置,将数据写到数据库中间件
方案2 不停机双写方案
双写,既写单库单表,也写数据库中间件;
同时,单库单表的数据也要通过数据迁移工具同步到数据库中间件。

还有别的方案
问题3 分库分表之后全局 id 如何生成
方案1 新增一个生成主键的库。
存在单点问题
方案2 UUID
UUID不适合当主键,因为长度太长。
适合做文件名。
方案3 获取系统当前时间。
方案4 snowflake算法
全局唯一id的作用?
如何使用?
作为单个服务,接受请求,生成唯一全局id。
snowflake源代码!!!
使用的注意事项:
一毫秒 4096个id
机房 id 限制 32,单个机房限制 32 台机器。

问题4 分库分表的扩容方案
写并发太高了可以扩容
数据库磁盘容量满了可以扩容
最佳方案是,只用修改数据库服务器地址。
好处是:直接迁移 db,DBA有简单、快捷的方案。
orderId/库
orderId/表
最开始设置4台服务器,每台8个库,每个库32个表。
可以扩展到32个数据库服务器,每个服务器一个库,32个表。
sharding jdbc demo
问题5 读写分离
常规的数据库服务器,一般读写qps 2k。
加一个缓存,5k qps 4k 走缓存。
主从复制的原理
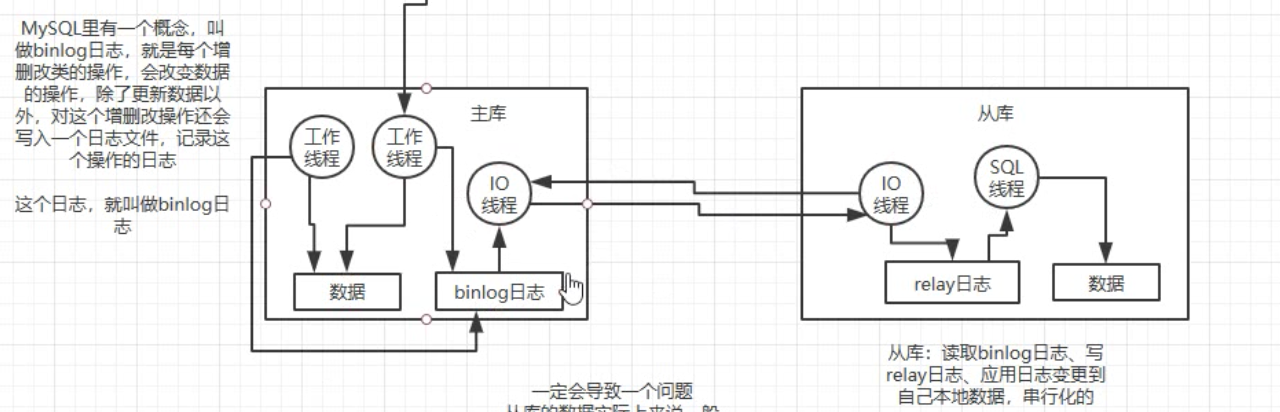
主从复制延迟

半同步复制——主库数据丢失问题
写成功的标志。
并行复制——主从同步问题
多个 IO 线程写 relay 日志
并发重放 relay 日志。
主从同步延时的生产问题(精华)

若有收获,就点个赞吧
0 人点赞
