在说这个几个指标之前有一个非常重要的东西叫做混淆矩阵:
我们把上述提到的这个表格称作为混淆矩阵,那么一般使用混淆矩阵干嘛呢?计算召回率、计算准确率、计算精准率。接下来分别介绍这三个指标。
TP:实际是正样本预测也是正样本;TN:预测是负样本实际也是负样本;FN:实际上是正样本预测为负样本;FP:实际上是负样本预测为正样本
1、Accuracy——准确率
预测是对的样本数占总样本数的比例。
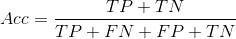
2、Precision——精准率
精准率只和预测的正样本有关系,其定义为预测为正的样本中有多少为真正的正样本。
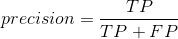
3、Recall——召回率
召回率只和对于正样本的预测有关系,其定义为样本中有的正例有多少被预测正确了。
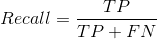
对这几个指标有了明确的定义之后,不禁要问一下用这些指标来干嘛?衡量模型的分类或者检测效果。那么具体如何去衡量呢,须要进一步对召回率和准确率进行探究。
4、进一步探索召回率和准确率
对于极端的分类任务来说,如果只找出一个结果来,而且这个结果是正确的,那么精准率就是100%,而召回率就十分低了。反之,如果召回率十分高的话,那么精准率就会比较低。由此我们可以看出,这两个是比较矛盾的,没有办法统一。当然我们希望我们的模型有较好的精准率同时也有较好的召回率。这就要找一个平衡指标,此时我们可以引出另一个平衡标,称之为F1-Score。
5、F1-Score
F1-score是衡量二分类模型精准度的一种指标,它同时兼顾了分类模型的精准率和召回率。F1-score可以看作是模型精准率和召回率的一种调和平均,最大值是1,最小值是0。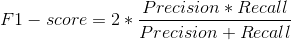
接下来介绍Micro-F1和Macro-F1
6、Micro-F1和Macro-F1
如果对于一个多标签的分类任务,那么我们需要计算每个类的召回率、精准率。对于计算F1-score显然我们将所有类别的指标合并起来进行考虑。
Micro-F1:不区分类别计算总的召回率和精准率。考虑到每个类别的数量,适用于数据分布不平衡的情况。
Macro-F1:计算每一个类别的召回率和精准率,然后对每个类别的精准率和准确率求平均数。然后最终在计算出来F1-score。没有考虑到数据的数量,平等看待每一类,会相对受高precision和高Recall类的影响较大。

若有收获,就点个赞吧
0 人点赞
