文章来源:心中有光
无论你是作为智能对话系统的产品经理、测试人员还是采购方,都需要对系统进行测评,可以通过以下几个方面:
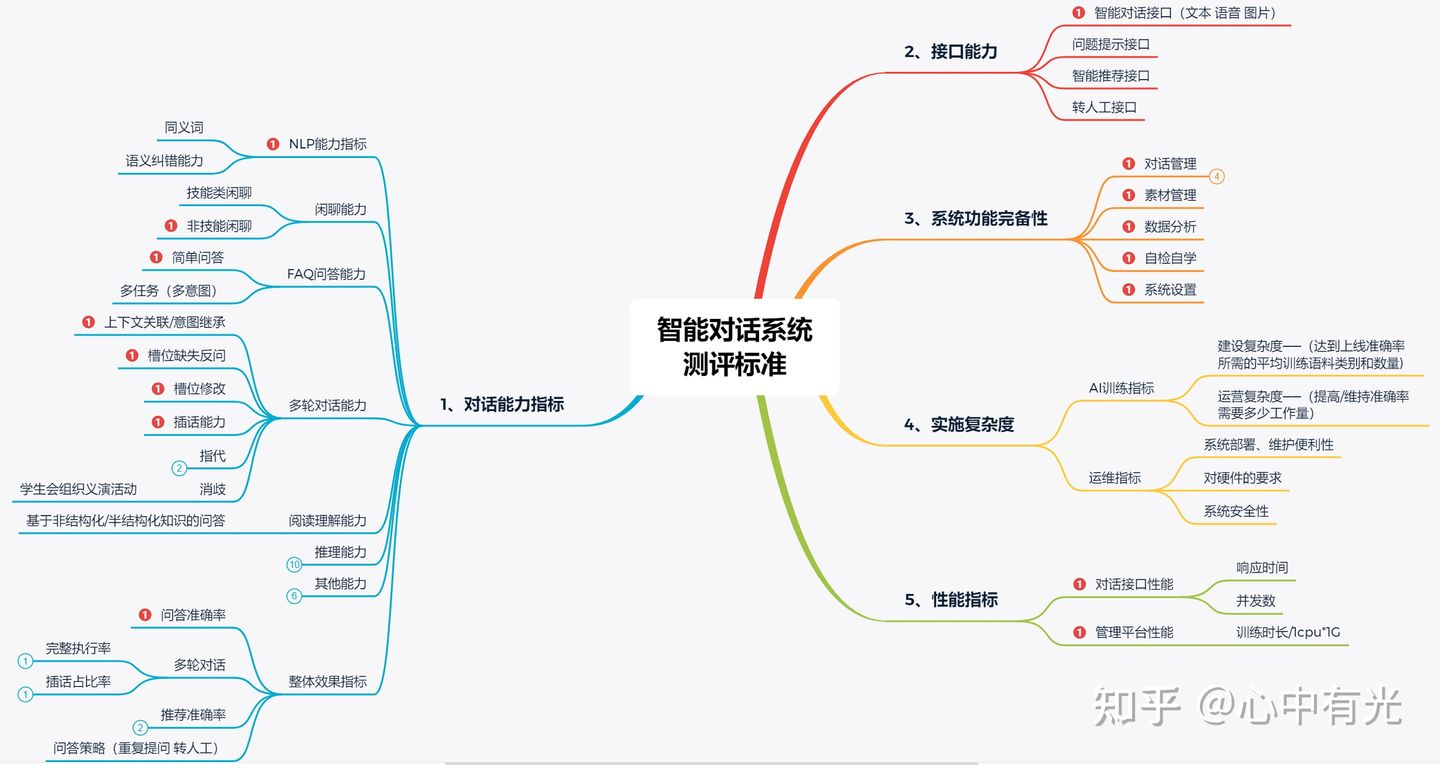
- 系统的对话能力指标
- 系统的接口能力
- 系统功能完备性
- 实施复杂度
- 性能指标
一、系统的对话能力指标
要测评一个智能对话系统,最重要的是其对话能力的智能性。
对于采购方来说,一般是直接看整体效果的,把测试的语料灌到系统中进行训练,然后其实验证其对话效果。
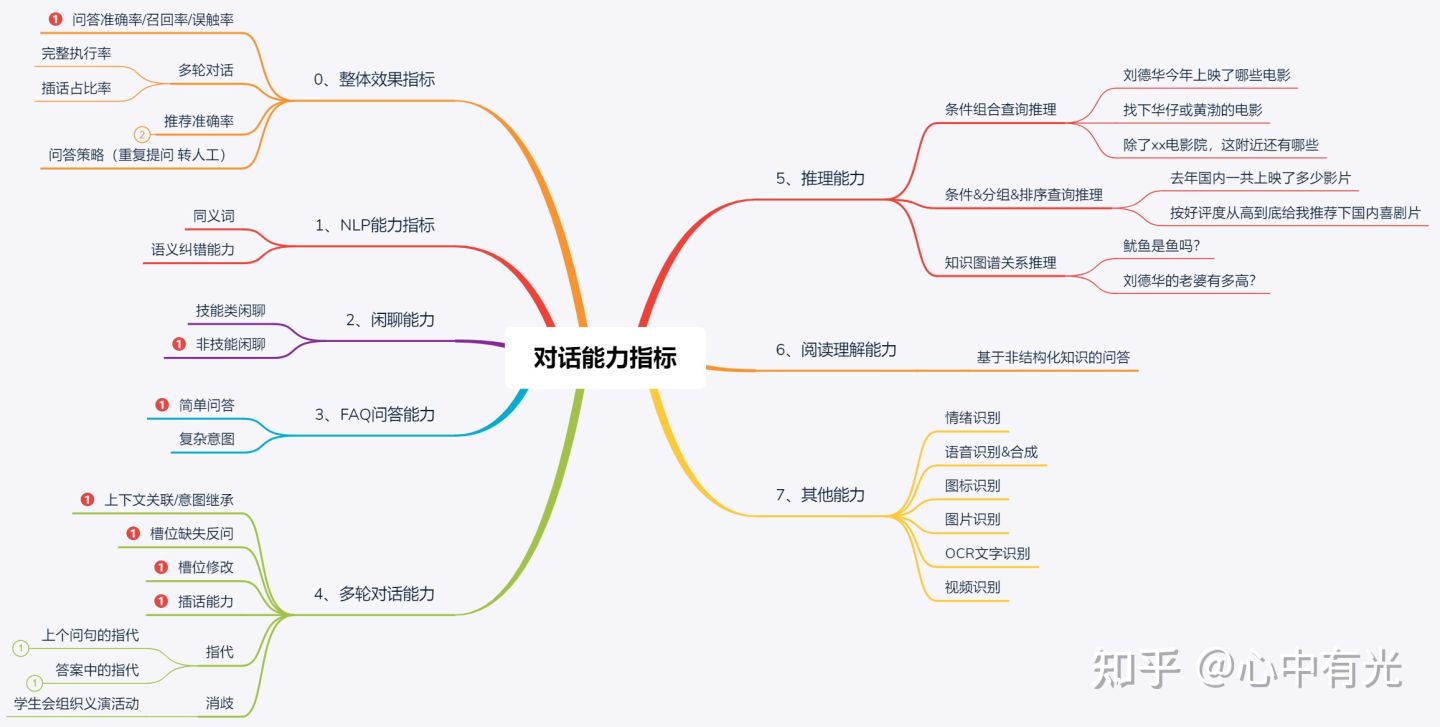
- 整体效果指标
- 问答准确率是最重要的一个指标了
Accurace=(正确召回数+正确拒绝数)/ 所有测试样本数
- 召回率:
RecallRate=(正样本中被正确召回数/正样本数)大部分采购方只看问答准确率,是因为测试样本都是正样本,或者大部分都是正样本。这种情况下如果只用问答准确率这一个指标其实并不足够。一般智能对话系统的意图识别都会设置一个阈值,超过这个阈值就会给出对应的意图,如果测试样本大部分或者全部都是正样例,那么只需要把阈值调到最低,准确率也不会太低。所以准备正负测试样本时要尽量均衡。
- 误触率
FAR(false acceptance rate)=(负样本中被召回数+正样本中被预测到其他意图数)/模型预测为正样本数当采购方对智能对话系统给出回复有严格精准要求时,那么误触率应该要尽可能低。
- 多轮对话
完整执行率= x任务被完整执行的次数/x任务的对话总数进入多轮对话任务后,完整执行率越高,意味着该任务设计越合理,语义准确率也较高插话占比率(节点)= 某节点插话的数量/任务某节点的交互总数插话占比越高的节点可以优化其话术
- 推荐准确率
RecomRate=推荐的内容中包含用户所需要的次数 / 推荐总次数推荐在智能问答系统中对用户来说时一种比较好的体验。(系统知用户所想也是智能性的体现)一般在以下集中情况下会进行推荐:
A、什么都没问:用户进入系统后,根据用户画像推荐可能感兴趣的业务或产品
B、正在问:用户边打字,系统边推荐和用户输入文字中强相关的问题
C、问完了,系统计算出有对应答案,推荐与用户问题相关的其他问题(相关性可自定义设置、也可通过NLP引擎计算相关性、或者通过用户日志计算相关性)
D、问完了,系统计算出没有对应答案,推荐与用户问题相关的其他问题
- 问答策略
一个具有智能对话能力的系统,除了能正确回答用户的问题,完整执行多轮对话任务、推荐可能关联的问题,还应该在一些特殊情况下有良好的应对策略。
A、用户连续多次问同一个问题(适当的变换了说法)都给出一样的回复时——转人工
B、用户问题连续多次即未正面回答问题也没有给出任何推荐时——转人工
以下1-7条都是整体效果问答准确率的单点能力验证,为测试样本的准备提供一些参考。准确率高的情况下不一定具备下面的能力(因为测试样本可能不够多样化),但是具备以下能力的准确率和泛化性都不会低。
1、NLP能力指标——问答中最基础的能力
同义词:其实应该叫语义相关词,包含同义词(如:为啥=为什么=why)、同类词(如:NER实体词)。语义纠错能力:比如拼音纠错(账单=帐单),方言纠错(可以=中【河南方言】)多字纠错(xx活动怎怎么参加)少字纠错(xx活动怎参加=xx活动怎样参加)
2、闲聊能力——toC类智能对话产品必备能力
技能类闲聊——需要调用第三方数据或应用的闲聊,如查天气、定闹钟等非技能闲聊——日常闲聊:你是男的女的,你会干啥
3、FAQ问答能力——toB类智能对话项目核心能力
简单问答——xx活动的规则复杂意图——多意图(xx活动的规则及截至时间)、长句问题(如叙述型问题)
4、多轮对话能力——根据上下文内容,进行连续的对话(超过1轮对话)。(还有一种窄一些的定义:为达到解决某一类特定任务为目的,根据上下文内容进行的连续对话)
- 上下文关联/意图继承——“xx活动的开始时间?” 那截至时间呢?
- 槽位缺失反问——“关灯” 请问你想关哪个房间的等还是所有的?
- 槽位修改——“定下明天下午3点的闹钟” “还是5点吧”
- 插话能力——“帮我定一张明天去北京的高铁” 请问你的出发城市或者出发站是哪里? “对了,明天北京天气怎么样?”
- 指代
上个问句的指代——XX活动什么时候开始?这个活动什么时候结束呢?其中这个活动就是指的XX活动。答案中的指代——去年主演的电影?打开第一部
- 消歧
学生会组织义演活动吗?是问的“学生会”还是“学生”会不会组织义演活动?
5、推理能力——是智能对话系统中比较高端的能力(一般标准化智能对话系统不提供推理能力)
- 条件组合查询推理
(与)刘德华今年上映了哪些电影(或)找下华仔或黄渤的电影(非)除了xx电影院,这附近还有哪些
- 条件&分组&排序查询推理
去年国内一共上映了多少影片按好评度从高到底给我推荐下国内喜剧片
- 知识图谱关系推理
(ISA 是非题)鱿鱼是鱼吗?(attribute of)刘德华的老婆有多高?
6、阅读理解能力——大部分智能对话系统不提供阅读理解能力,能回答的问题的比较简单
基于非结构化知识的问答
7、其他能力——以下能力既可以自己支持,也可以对接第三方,评测是其框架是否支持,并可快速对接
情绪识别语音识别&合成图标识别图片识别OCR文字识别视频识别以上单点能力或者整体效果的测试数据可以从网上找些公开的数据。
二、接口能力
- 智能对话接口(文本 语音 图片)
- 问题提示接口
- 智能推荐接口
- 转人工接口
一般智能对话的前端根据不同的渠道由客户方或者客户指定的第三方来开发。比如在APP上加入智能对话能力或者在智能音箱或手表植入对话能力。那么智能对话系统就需要对外提供对应的问答接口、问题提示接口、智能推荐和转人工接口。
三、系统功能完备性
- 对话管理
定制化闲聊管理FAQ问答管理阅读理解文档管理知识图片管理
- 素材管理
- 数据分析
- 自检自学
- 系统设置具体可参考另一篇介绍智能对话系统产品的文章。智能对话系统设计
四、实施复杂度
实施的复杂程度也是检验智能对话系统的标准之一,如果以上指标都符合,但是如果只能通过大量的人工付出大量的时间成本才能达到基本的效果,那也是得不偿失。
- AI训练指标
建设复杂度——(达到上线准确率所需的平均训练语料类别和数量)
运营复杂度——(提高/维持准确率需要多少工作量)
- 运维指标
系统部署、维护便利性
对硬件的要求
系统安全性
五、性能指标
- 对话接口性能(也包含其他接口)
响应时间:一般从用户发出问题到得到响应的平均时间在500ms左右,如果太久用户就会失去耐心和继续使用的兴趣。并发数:并发数一般取决于引擎服务器性能,同一性能的服务器引擎并发越高硬件的维护成本越低。一般智能对话系统还需要支持平行扩展能力,增加服务器数量亦可提高并发量。
- 管理平台性能
训练时长/1cpu*1G:文本类模型不像语音的声学模型,需要几小时甚至几天的时间进行训练,在保证对话能力效果一致的基础上应选择可以增量和全量训练且训练时间可接受的智能对话系统。

若有收获,就点个赞吧
0 人点赞
