模型训练结束后才是业务真正的开始 做好模型监控可以进一步帮助我们更好应用模型
简述
每次模型训练完成后,并不意味着项目的结束,在训练模型后,我们还需要将其稳定上线,然后部署一套相应的监控体系,这时候模型才开始稳定运行在业务场景中。在我们以往接触的大多文章都只是告诉你如何构建模型,但是在模型上线后的监控同样重要,我们需要通过对模型的监控来掌握模型运作情况,了解业务变化趋势。
在我看来对模型的监控主要有两方面:一方面是对模型本身的性能进行监控;另外一方面是监控业务信息,更了解业务发展情况。
对模型本身性能的监控主要涉及以下几个关键指标:
0、Confusion Matrix
1、AUC(binary)
2、KS(binary)
3、PSI
4、Lift & Gain
5、MSE(Regression)
对业务信息的监控主要会设计以下指标:
1、评分监控(评分模型)
2、响应率监控
3、模型变量监控(缺失值,平均值,最大值,最小值等,变量分布)
4、模型调用次数
对模型本身性能的监控
0、Confusion Matrix
混淆矩阵有几个古老的概念:TP(实际为正预测为正),FP(实际为负但预测为正),TN(实际为负预测为负),FN(实际为正但预测为负)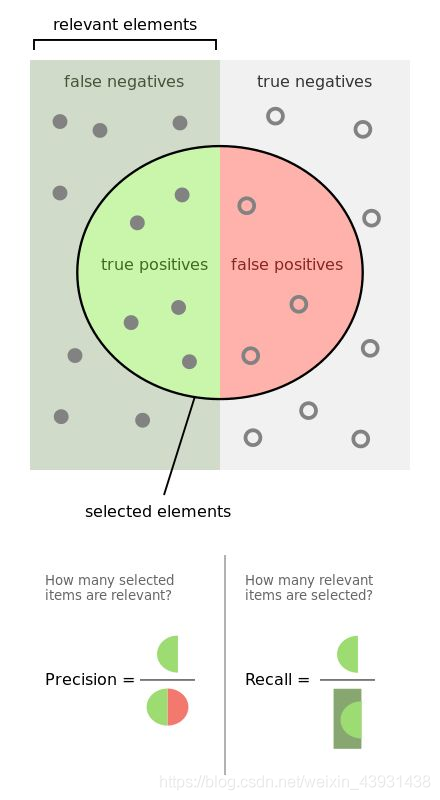
通过混淆矩阵我们可以给出各指标的值:
查全率(召回率,recall):样本中的正例有多少被预测准确了,衡量的是查全率,预测对的正例数占真正的正例数的比率:
查全率=TP / (TP+FN)
Precision:针对预测结果而言,预测为正的样本有多少是真正的正样本,衡量的是查准率,预测正确的正例数占预测为正例总量的比率:
Precision=TP / (TP+FP)
Accuracy:反应分类器统对整个样本的判定能力,能将正的判定为正,负的判定为负的能力,计算公式:
Accuracy=(TP+TN) / (TP+FP+TN+FN)
但是往往准确率并不能直观地反应模型的预测能力:
例如一个集合里有100个样本,99个正样本和1个负样本,全预测为正样本都有99%的准确度,但是没有任何预测能力,后续的KS和AUC可以弥补这些不足。
F1度量
先看公式: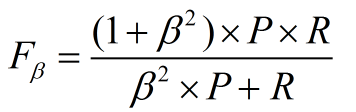
其中β表示查全率与查准率的权重
- β=1,查全率的权重=查准率的权重,就是F1
- β>1,查全率的权重>查准率的权重
- β<1,查全率的权重<查准率的权重
那么问题又来了,如果说我们有多个二分类混淆矩阵,应该怎么评价F1指标呢?
很简单嘛,直接计算平均值就可以:可以计算出查全率和查准率的平均值,再计算F1;或者先计算TP,FP,FN,TN的平均值,再计算F1。
参考来源:https://www.zhihu.com/question/30643044/answer/48955833
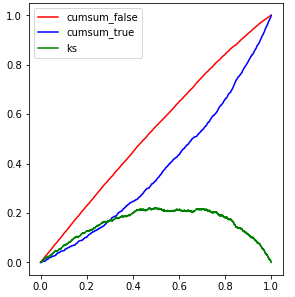
1、KS&AUC
模型在上线应用后,也需要及时地进行验证,在每一次样本走完表现期后,需要及时地选取样本进行验证。关于这两个指标应该不用做过多介绍,和我们在建模时使用的逻辑是一样的。
计算公式: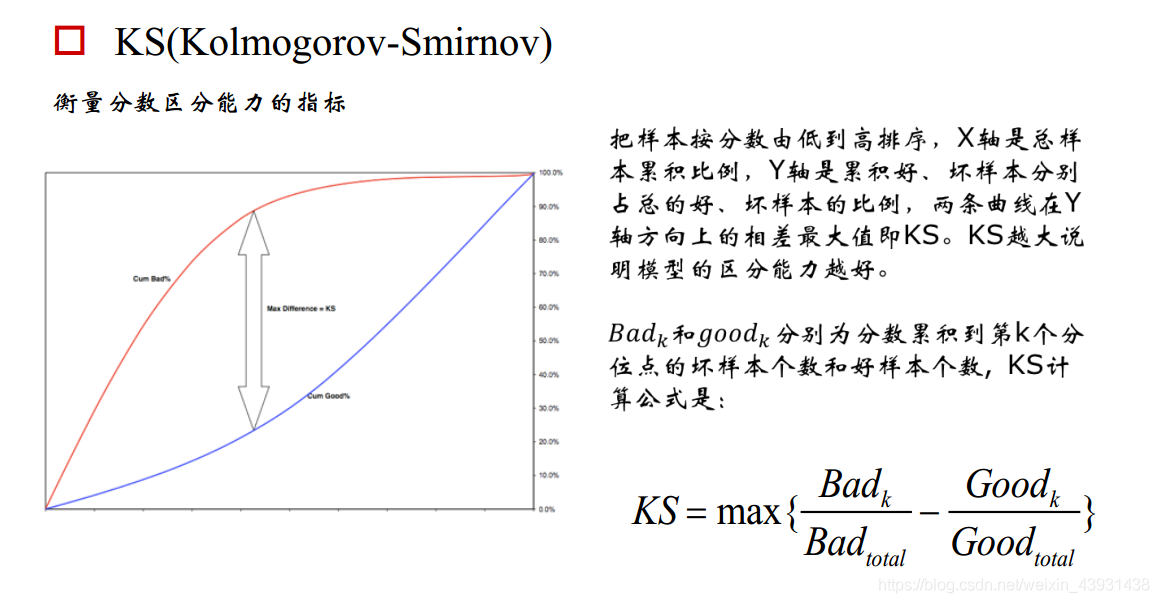
关于KS&AUC推荐一个资料,里面介绍相当详细:http://rosen.xyz/2018/02/01/AUC%E5%92%8CKS%E6%8C%87%E6%A0%87/
KS&AUC 反映了模型开发期间与当前客户的客群变化,当KS和AUC相比建模时的数据没有较大下降时都可以不重新训练模型: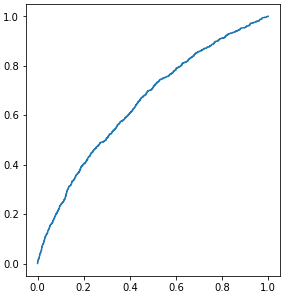
#target rate & KS监控logging.info('生成Targer rate & KS监控')monitor_fst.score_target_monitor(df_target_fst, lag_days=8, interval_days=7, date=run_date)monitor_fst.score_target_plot(show_days=10, lag_days=8, interval_days=7, keep_base=False, date=run_date)monitor_fst.ks_monitor_plot(show_days=10)logging.info('Targer rate & KS监控生成结束')
2、模型分数稳定性分析-PSI
目的在于分析衡量两段时间(模型开发期间与目前)客户的客层变化,作为评分卡有效性的早期预警,并了解通过率的变动是否来自于客群的变动。
PSI的计算公式:
_PSI = sum((实际占比-预期占比) ln(实际占比/预期占比))_
举例:
比如训练一个logistic回归模型,预测时候会有个概率输出p。
测试集上的输出设定为p1,将它从小到大排序后10等分,如0-0.1,0.1-0.2,…。
现在用这个模型去对新的样本进行预测,预测结果叫p2,按p1的区间也划分为10等分。
实际占比就是p2上在各区间的用户占比,预期占比就是p1上各区间的用户占比。
如果p1和p2上各区间的用户相近,占比变化不会很大,预测的结果有额不会有较大差距,那么模型相对比较稳定。
通过观测这些PSI的大小和走势,从而实现对评分卡稳定性的监测。通常PSI会以日、周和月为维度进行计算,同时也会对评分卡模型中各个特征变量分别做PSI监测。
*判断标准:
若PSI<0.1,表示客户群体从模型开发到实施的稳定性较高,模型不需要更新;
若0.1<= PSI <=0.25,表示客户群体发生了一定的变化,模型需要关注,随时需要更新;
若PSI >0.25, 表示客户群体发生较大变化,模型需要更新。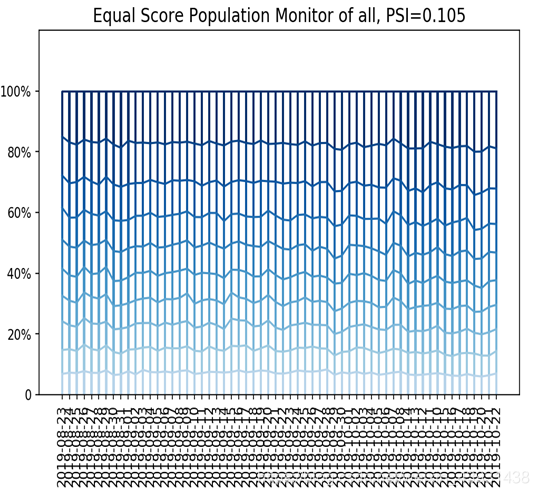
模型分数的变化可能由特征变化引起,也可能是模型本身不稳定引起,若是高分段总数量没变,而PSI值变动较大,认为需要重训模型。若是PSI值没变,高分段总数量变多,认为整体用户变好。
3、Lift 和Gain
Lift图衡量的是,与不利用模型相比,模型的预测能力“变好”了多少,lift(提升指数)越大,模型的运行效果越好。
Gain图是描述整体精准度的指标。
计算公式如下: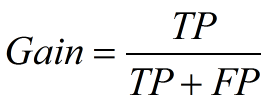
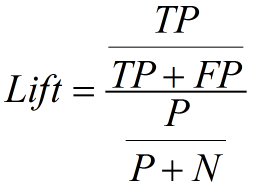
作图步骤:
- 根据学习器的预测结果(注意,是正样本的概率值,非0/1变量)对样本进行排序(从大到小)——-这就是截断点依次选取的顺序
- 按顺序选取截断点,并计算Lift和Gain
—也可以只选取n个截断点,分别在1/n,2/n,3/n等位置
例图: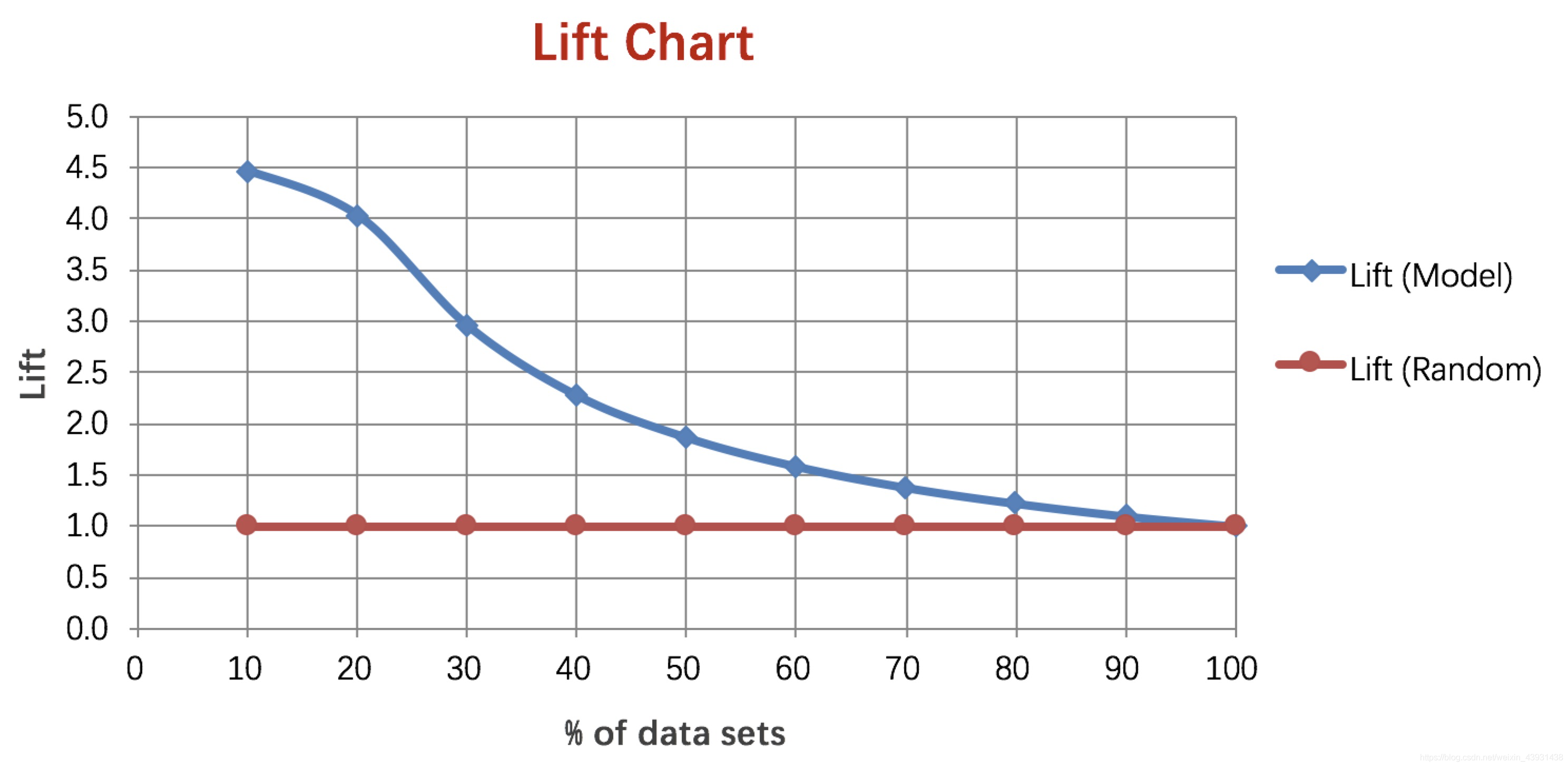
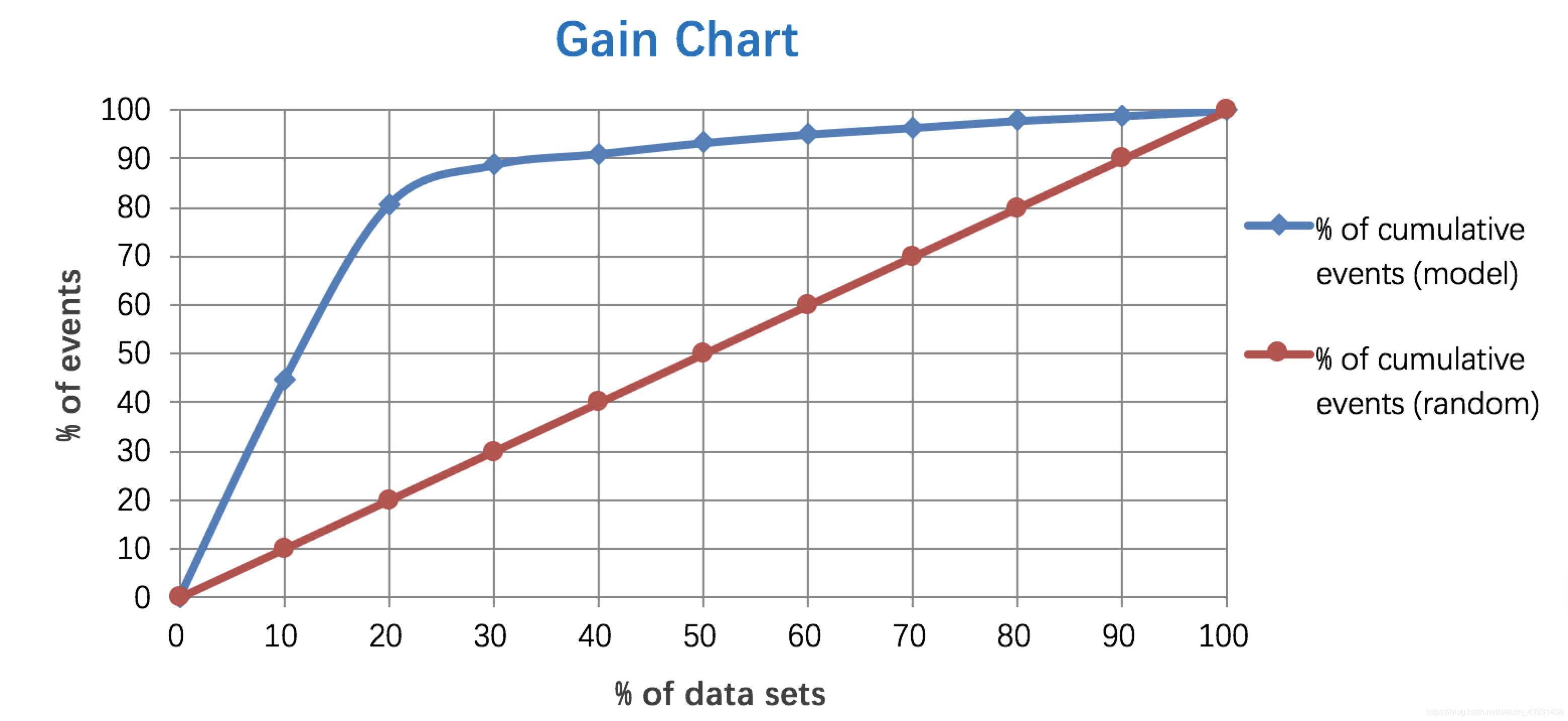
详细解释:
https://cosx.org/2009/02/measure-classification-model-performance-lift-gain/4、MSE
MSE (Mean Squared Error)叫做均方误差。看公式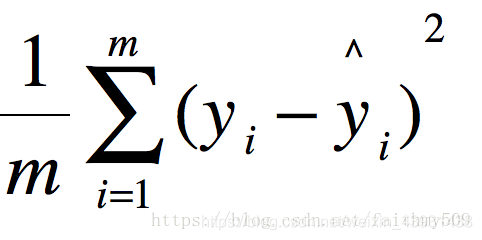 这里的y是测试集上的。
这里的y是测试集上的。
用 真实值-预测值 然后平方之后求和平均。
猛着看一下这个公式是不是觉得眼熟,这不就是线性回归的损失函数嘛!!!对,在线性回归的时候我们的目的就是让这个损失函数最小。那么模型做出来了,我们把损失函数丢到测试集上去看看损失值不就好了嘛。简单直观暴力!
有时计算均方根误差(RMSE)也可以。
不用解释了吧
线性回归算法评价指标三连,可以灵活搭配:MSE、RMSE、R2_score
上面提到的这么多指标不需要每一个都应用起来,可以根据需要选择几个核心指标应用就可以。业务信息相关监控
0、评分分布
通过对模型评分分布的监控,我们可以知道每一个评分周期模型评分的变化情况,可以反映每一个评分周期里不同分数段的占比情况,对应的可能是业务的通过率或者拒绝率等;#评分监控import loggingmonitor_fst = ModelMonitor(score_var='score', target='target', cut_points=fst_cut_points,output_path=os.path.join(output_path, 'monitor_file', 'fst'))logging.info('生成打分监控')monitor_fst.score_monitor(df_score_fst, valid=np.array([0.1] * 10), date=run_date)monitor_fst.score_monitor_plot(show_days=10, keep_base=False)logging.info('打分监控结果生成结束')
1、响应率变化情况
通过分析每一个表现期的响应率,可以清楚看到响应率的变化趋势,同时可以看出真实响应率与预测的响应率之间的差距,
不过这个有一定的滞后性,通常需要等到样本整个表现期走完,才能比较真实的target rate与预测值之间的差距。2、变量监控
除了了解结果,我们也需要掌握每一个变量的变化情况,通过对变量分布的监控,能很快的知道用户群体发生了哪些迁移,这些迁移对模型有哪些影响,这种变化是否是异常情况?还是有变化的趋势?如果变量存在这种变化,我们是否需要refit模型?我们都可以从变量监控里获取这些信息。当然,对于模型refit的问题,不能仅仅依靠这一点来判断,需要综合其他指标来衡量,尤其是对模型本身性能的监控上。
例如下图中对模型中一个变量分布的监控: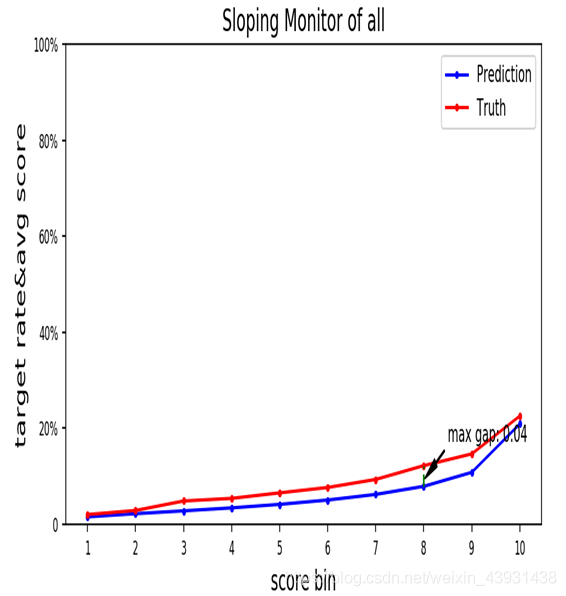
#变量监控logging.info('生成变量监控')monitor_fst.var_monitor(df_orig_fst, file_name='var.csv',var_list=var_list_fst, cat_value_dict=cat_value_dict, date=run_date)monitor_fst.var_monitor_plot('var.csv', show_days=10,var_list=var_list_fst,cat_value_dict=cat_value_dict, keep_base=False, num=6)#输入你所需要的变量var_list_fstlogging.info('变量监控结果生成结束')
3、模型调用次数
对模型调用次数的监控在某种程度上不属于模型监控的范围,但是也有其存在的理由;尤其在特定的业务场景中,比如我们每天有固定数量的用户经过模型评分来判断是否被拒,如果某一天用户数量激增或者骤减,也能从模型评分过程中及时发现问题。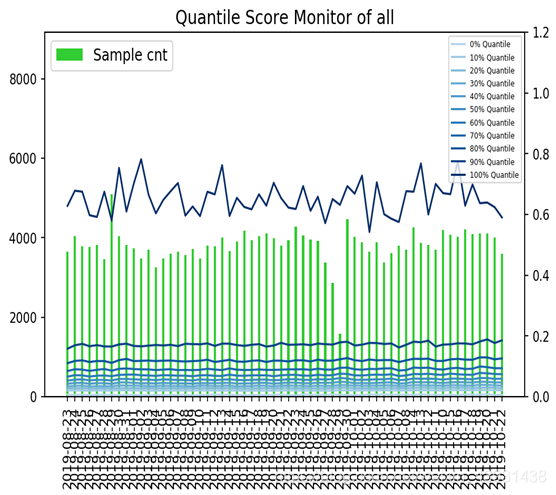

若有收获,就点个赞吧
0 人点赞
