一、概述
1. hadoop 是什么
- hadoop 是 Apache 基金会开发的一个分布式系统架构,主要用于海量数据从存储和分析计算问题,其实从广义的角度上看,hadoop 通常指的是一个生态圈 hadoop 生态圈,如下图

2. 发展历史
- 为了实现类似于 Goole 的全文搜索,Hadoop 创始人 Doug Cutting 在 Lucene 框架上进行优化升级查询引擎和搜索引擎
- 2001年底 Lucene 成为 Apache 基金会的一个子项目
- 对于海量数据, Lucene 面临很大的挑战,尤其是海量数据存储困难,检索效率慢
- 为了解决这些困难,开始学习 Goole 的解决方案 :微型 Nutch
- 后来谷歌发布了三篇论文,GFS —>HDFS Map-Reduce —> MR BigTable —> Hbase
- 2003-2004 年 Goole 公开了部分 GFS 和 MapReduce 的思想细节,以此为基础,Doug Cutting 等人利用业余时间,耗时两年实现了 GFS 和 MapReduce 机制,使得 Nutch 性能飙升
- 2005 年 Hadoop 作为 Lucene 的子项目 Nutch 的一部分 引入到 Apache 基金会
- 2006 年三月份 MapReduce 和 Nutch Distributed File System(NDFS) 分别被纳入 Hadoop 项目中,至此 hadoop 正式诞生,标志着大数据时代来临
hadoop的图标来源于 Doug Cutting 儿子的玩具
3. 三大发行版本
hadoop 目前市面上主要有三大发行版本 Apache 、 Cloudera 、Hortonworks
- Apache : 最基础的版本
官网地址 :http://hadoop.apache.org
下载地址 :https://hadoop.apache.org/releases.html
- Cloudera :内部继承了很多大数据的框架 ,主要产品是 CHD、Cloudera Manager,Cloudera Support,它成立于2008年,是最早将 hadoop 商用的公司,为合作伙伴提供 hadoop 的商用解决方案,包括支持 、 咨询、培训。2009年 hadoop 的创始人 Doug Cutting 加入到 Cloudera 公司,参与到 CHD 的研发,CHD的兼容性、安全性、稳定性都比 Apache Hadoop 强一些。Cloudera Manager 是集群分发管理监控平台,可以在几个小时中完成集群的部署,并对节点数据进行实时监控。
官方地址:https://www.cloudera.com/downloads/cdh
下载地址 : https://docs.cloudera.com/documentation/enterprise/6/releasenotes/topics/rg_cdh_6_download.html
- Hortonworks : 它是2011年雅虎和硅谷风投合资组建的,公司成立之初就吸引了25-30名专业的hadoop研究人员,他们贡献了Hadoop 80% 的代码。主要产品是 Hortonworks Data Platform (HDP)。 目前已经被 Cloudera 收购 推出了新的品牌 CDP
官网地址:https://hortonworks.com/products/data-center/hdp/
下载地址:https://hortonworks.com/downloads/#data-platform
4. 优势
- 高可靠: hadoop 底层存储了多个数据副本,可根据自己的需要进行设置。所以当某个节点down掉后,并比影响整体
- 高扩展: 可以根据实际需求,动态增加/减少节点数
- 高效: 基于 MapReduce 思想设计,Hadoop 是并行工作的
- 高容错: 如果任务执行失败,会重新进行分配,执行、
5. 组成
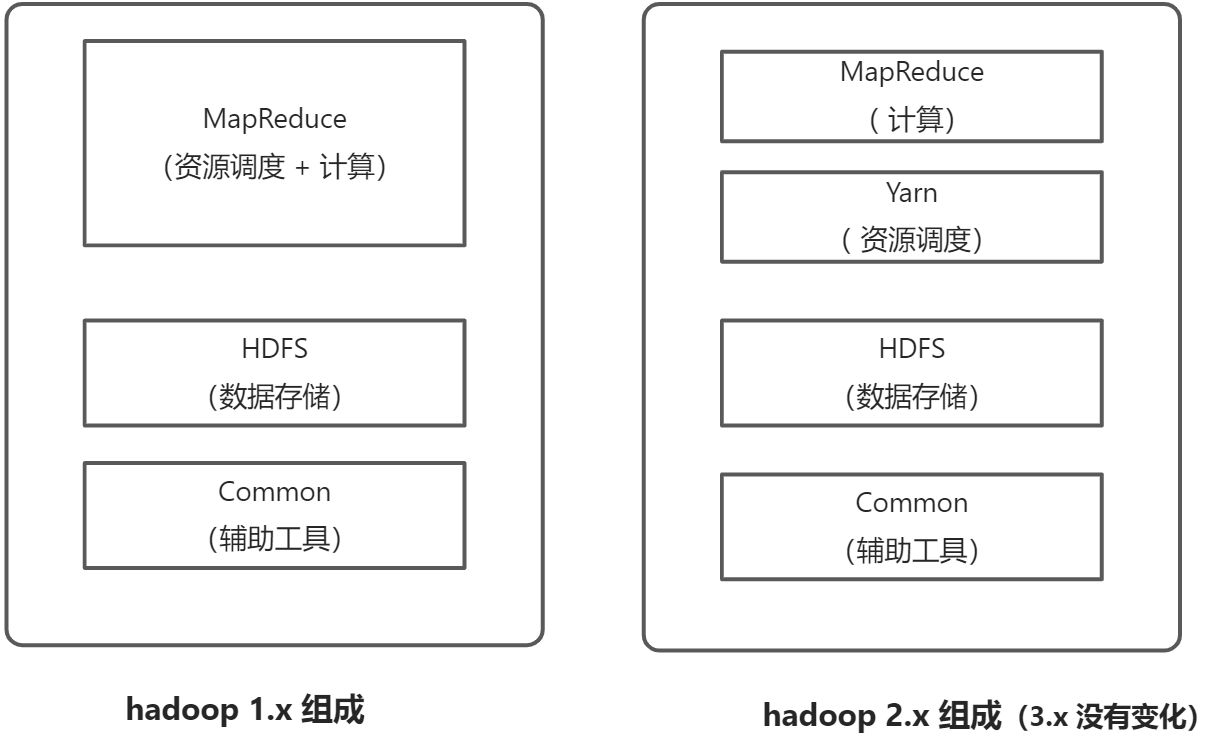
- HDFS
- NameNode(NN): 基于内存的, 存储文件的元数据,比如:文件名。目录结构、文件属性(生成时间、副本数、文件权限)以及文件所在块列表和每块所在的地址
- DataNode(DN): 存储文件块数据,以及块的校验和
- SecondNode(2NN): NN 的数据备份,每隔一段时间去对NN进行备份
YARN
- Yet Another Resource Negotiator(Yarn),资源调度,是 hadoop 的资源管理器
几个概念
ResourceManager
负责整个集群资源(CPU、内存)的分配,是整个集群的老大。NodeManager 以心跳的方式定时向 RM 汇报资源的使用情况
NodeManager
负责单个节点的资源,是节点的老大,负责节点程序的运行和该节点资源的管理和监控。接收并处理 ApplicationManager 的请求,完成 container 的启动、停止等
- ApplicationManager
单个应用程序的老大,负责整个任务,监控任务的执行情况,并在任务运行失败时重新为任务申请资源重启任务。
- Container
任务实际运行的地方,封装了任务执行所需要的资源。(单个NM上可以有多个container)
- 运行流程

1. client 通过 New Application Request 向 RM 的AsM(Applications Manager)的发送任务请求,AsM生成任务 ID 传递给 RM, RM添加些其他信息(比如 集群资源)然后返回给 client,此时 job 的状态是 NEW
2. client 构造任务运行的一些信息(包含调度队列 、任务优先级、用户认证信息 CLC)生成 ASC,提交给 RM,此时 job 的状态是 SUBMIT
3. RM 收到 ASC 后,将作业信息传递给 scheduler(调度器),scheduler 检查client的权限,AM的队列 查询是否有满足请求资源的 container 来运行 AM ,若有,与其通信,启动AM,此时 job 的状态是 ACCEPT
4. AM 启动成功后,开始向RM协调,并传递一些信息(比如 applicationID,host等),RM的scheduler组件回应,返回这个集群最大、最小资源使用情况。此时 job 的状态是 RINNING
5. AM 收到后,启动任务,并把心跳包和任务进度信息发送给RM
6. RM 收到后,根据调度策略,分配container来满足 AM 的请求
7. 任务完成后,AM 给RM 发送结束信息,并退出 此时 job 的状态是 FINISHED / FAILED
- MapReduce
负责任务的计算,分为两个步骤 MAP 和reduce
- map : 负责任务的并行执行
- reduce : 对map 执行的结果进行汇总
- 三者之间的关系

6. 生态体系

二 运行环境搭建
1. 模板虚拟机准备
提前安装好 vmare 配置好模板虚拟机 使用是系统是 centos7.5。要求如下
- yum 正常使用
- 安装额外软件包
yum install -y epel-release
- 安装 net -tools
yum install -y net-tools
- 安装 vim 编辑器
yum install -y vim
- 关闭防火墙
stop firewalld
disable firewalld.service
- 创建新的用户 并赋予root权限
useradd allen
passwd allen
vim /etc/sudoers %wheel后添加上 allen ALL=(ALL) NOPASSWD:ALL
- 卸载自带的jdk
rpm -qa | grep -i java | xargs -n1 rpm -e —nodeps
2. 虚拟机克隆
- 利用上一步制作的虚拟机 生成三台新的虚拟机 hadoop102 hadoop103 hadoop104
- 修改ip vim /etc/sysconfig/network-scripts/ifcfg-ens33
- 修改主机名 vim /etc/hostname
安装 jdk 并配置环境
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
sudo vim /etc/profile.d/my_env.sh
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
source /etc/profile
java -version3. 在hadoop102上安装jdk
卸载之前的jdk
- 将 JDK 上传到 /opt/software 目录下
- 解压 配置环境
- 测试

4. 在hadoop102上安装 hadoop
- hadoop 下载地址
https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/
- 将下载的压缩包上传到 /opt/software
- 解压 tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
- 配置到环境变量中
- 测试是否安装成功

5. hadoop 目录介绍

- bin : 存放在 hadoop 相关服务的一些脚本 (hdfs yarn mapred)
- etc : 存放 hadoop 的配置文件
- lib : hadoop 的本地库
- sbin : 存放启动 或者停止 hadoop 相关服务的脚本
share: 存放 hadoop 依赖的 jar 包、文档 和官方样例
三、 hadoop 运行模式
hadoop 官网网址 http://hadoop.apache.org/
1. 三种运行模式
编写集群分发脚本 xsync
scp : 安全拷贝 实现服务器与服务器之间的数据拷贝
用法: scp -r dir/filename user@host:dir/path <br />递归拷贝 要拷贝的文件路径/名称 目的地用户@主机:目的路径/名称<br />缺点 :不考虑目的主机是否有某个文件,全部拷贝
rsync : 远程同步工具 用于文件的备份和镜像,可以避免重复复制,且支持符号连接复制
用法: rsync -av dir/filename user@host:dir/path<br /> -a:归档拷贝 要拷贝的文件路径/名 目的地用户@主机:目的路径/名称<br /> -v:显示复制过程
将以下文件 路径放入到环境变量中 ```bash
!/bin/bash
1. 判断参数个数
if [ $# -lt 1 ] then echo Not Enough Arguement! exit; fi
2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104 do echo ==================== $host ====================
#3. 遍历所有目录,挨个发送for file in $@do#4. 判断文件是否存在if [ -e $file ]then#5. 获取父目录pdir=$(cd -P $(dirname $file); pwd)#6. 获取当前文件的名称fname=$(basename $file)ssh $host "mkdir -p $pdir"rsync -av $pdir/$fname $host:$pdirelseecho $file does not exists!fidone
done
注意:如果用了sudo,那么xsync一定要给它的路径补全。2. 配置 ssh 无密码登录1. 生成公钥和私钥 ssh-keygen -t rsa1. 拷贝秘钥到相应的机器上 ssh-copy-id hadoop1023. 集群规划| | hadoop102 | hadoop103 | hadoop104 || --- | --- | --- | --- || HDFS | NameNode<br />DataNode | DataNode | SecondaryNameNode<br />DataNode || Yarn | DataManager | DataManager<br />ResourceManager | DataManager |注意: NameNode 不要和 SecondNameNode 放在同一台机器上<br />ResourceManager很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上4. 关于配置文件1. hadoop 的配置文件分为两种 一是默认配置文件 二:用户自定义配置文件1. 默认配置文件 xxx-default.xml1. 自定义配置文件 xxx-core.xml5. 集群配置1. 修改 core-site.xml```bash<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 指定NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://hadoop102:8020</value></property><!-- 指定hadoop数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-3.1.3/data</value></property><!-- 配置HDFS网页登录使用的静态用户 --><property><name>hadoop.http.staticuser.user</name><value>allen</value></property></configuration>
- 修改 hdfs.xml 配置文件 ```bash <?xml version=”1.0” encoding=”UTF-8”?> <?xml-stylesheet type=”text/xsl” href=”configuration.xsl”?>
3. 修改yarn-site.xmlbash
<?xml version=”1.0” encoding=”UTF-8”?>
<?xml-stylesheet type=”text/xsl” href=”configuration.xsl”?>
4. 修改mapred-site.xml```bash<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- 指定MapReduce程序运行在Yarn上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>
- 配置 works 在workers 中添加节点ip
- 配置历史服务器
```bash
mapreduce.jobhistory.address hadoop102:10020
bash
7. 启动集群第一次启动需要 格式化 NameNode 注意:如果需要重新格式化 一定要删除 data 和log 目录<br /> hdfs namenode -format8. 启动 hdfssbin/start-dfs.sh <br />访问 [http://hadoop102:9870/](http://hadoop102:9870/)<br />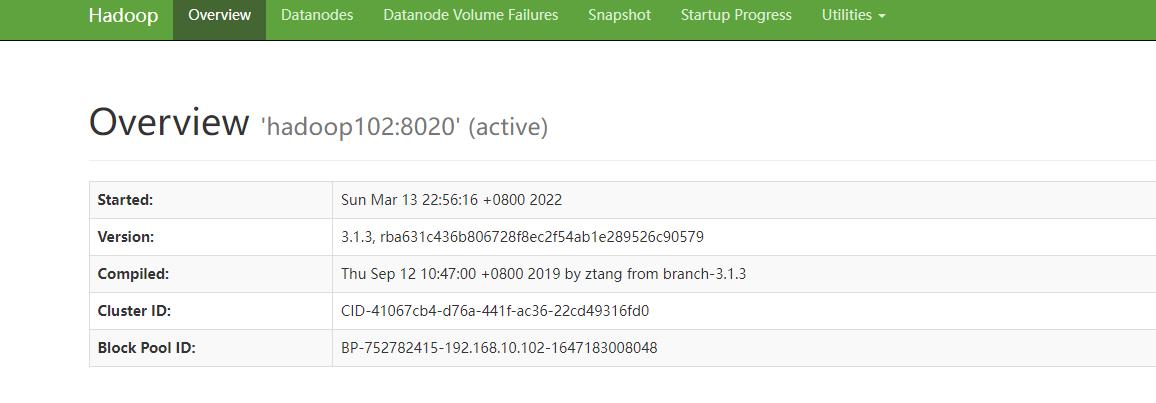9. 启动 yarn 在hadoop103上sbin/start-yarn.sh 访问 : [http://hadoop103:8088/](http://hadoop103:8088/)<br />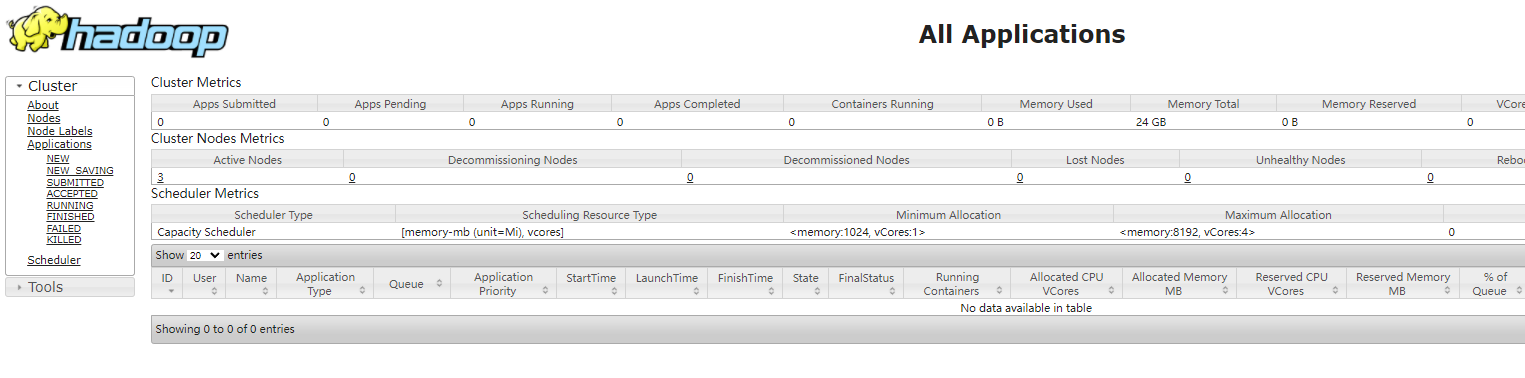10. 启动历史服务器,在hadoop102上mapred --daemon start historyserver 访问 [http://hadoop102:19888/](http://hadoop102:19888/)<br /><a name="WeOS6"></a>### 3. 集群启动1. 各个模块做个启动- hdfs start-dfs.sh / stop-dfs.sh- yarn start-yarn.sh / stop-yarn.sh2. 各个服务启动- hdfs hdfs --daemon start/stop namenode/datanode/secondarynamenode- yarn yarn --daemon start/stop resourcemanager/nodemanager3. 整体启动- hdfs start-dfs.sh /stop-dfs.sh- yarn start-yarn.sh / stop-yarn.sh4. 编写脚本启动启动 myhadoop.sh start<br />查看是否启动成功 :jpsall 5 4 4 <br />关闭 : myhadoop.sh stop```bash#!/bin/bashif [ $# -lt 1 ]thenecho "No Args Input..."exit ;ficase $1 in"start")echo " =================== 启动 hadoop集群 ==================="echo " --------------- 启动 hdfs ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"echo " --------------- 启动 yarn ---------------"ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"echo " --------------- 启动 historyserver ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver";;"stop")echo " =================== 关闭 hadoop集群 ==================="echo " --------------- 关闭 historyserver ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"echo " --------------- 关闭 yarn ---------------"ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"echo " --------------- 关闭 hdfs ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh";;*)echo "Input Args Error...";;esac
#!/bin/bash# 同时查看三台节点的数据for host in hadoop102 hadoop103 hadoop104doecho =============== $host ===============ssh $host jpsdone
4. 测试是否安装成功
- 上传文件 ```bash hadoop fs -mkdir /input
vim word.txt hello hadoop hello spark
hadoop fs -put ./word.txt /input ```
- 查看是否上传成功
hadoop fs -cat /input/word.txt
- 下载
hadoop -get /input/word.txt
- 执行样例程序 wordcount
hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
5. 常见端口号
| 端口名称 | hadoop 2.x | hadoop 3.x |
|---|---|---|
| NameNode 内部通信端口 | 8020 / 9000 | 8020 / 9000/9820 |
| NameNode 外部访问端口 | 50070 | 9870 |
| MapReduce 内部访问接口 | 8032 | 8032 |
| MapReduce 外部访问接口 | 8088 | 8088 |
| 历史服务器 内部访问端口 | 10020 | 10020 |
| 历史服务器 外部访问端口 | 19888 | 19888 |
6. 常见错误
- NameNode 和 DataNode 只能启动一个
原因分析: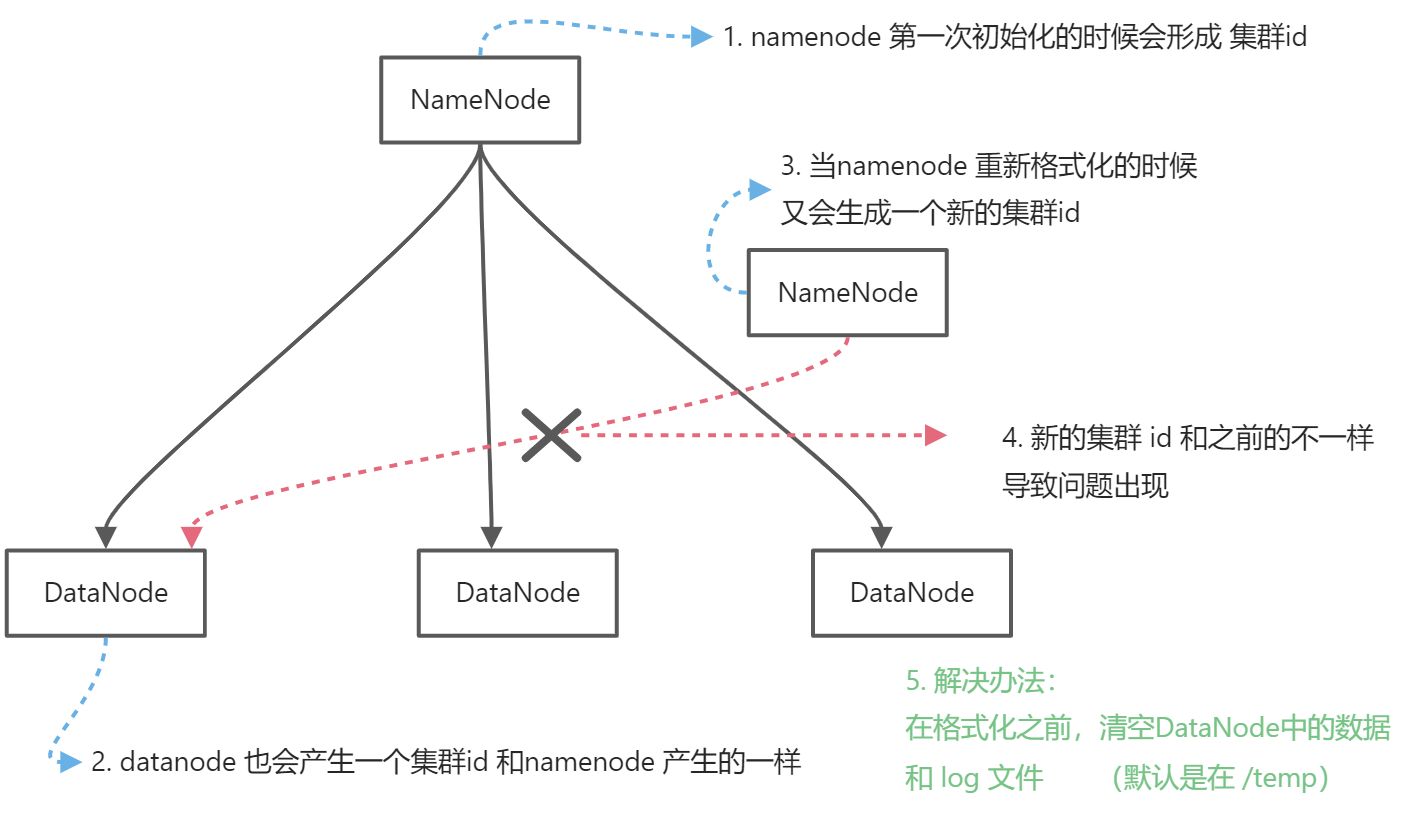

若有收获,就点个赞吧
0 人点赞
