一:求解一个范围的最小质数
哈希表取余的p需要是一个小于最大空间的质数,根据题目要求就是找到大于1e5的最小质数,这样能让冲突发生的概率最小。代码:
for (int i = 100000; ; i++){bool flag = true;for (int j = 2; j * j <= i; j++) // 求质数,从2到跟下i的范围没有出现取余为0的时候{if (i % j == 0){flag = false;break;}}if (flag) {cout << i << endl;break;}}
二:哈希表(拉链法的构造)
using namespace std;
const int N = 100003; int h[N], e[N], ne[N], idx; int n;
void insert(int x) { int k = (x % N + N) % N; // x有可能是负数,而且不能直接x+N,因为有可能还是负数 e[idx] = x; ne[idx] = h[k]; // 哈希表h中每一个h[k]开始都是-1,只是构造出形体,本质是单链表存储 h[k] = idx ++; // 单链表本质就是借助数组实现,序号肯定是单调递增,1-5是第一个结点的链表,6-15是第二个,只是举例子 }
bool find(int x) { int k = (x % N + N) % N; for (int i = h[k]; i != -1; i = ne[i]) { if (e[i] == x) return true; } return false; }
int main() { ios::sync_with_stdio(false); cin >> n; memset(h, - 1, sizeof h); // 必须初始化为-1 while (n—) { char op[2]; cin >> op; int x; cin >> x; if (op[0] == ‘I’) { insert(x); } else { if (find(x)) cout << “Yes” << endl; else cout << “No” << endl; } } return 0; }
<a name="jFu1f"></a>## 三:哈希表(开放地址法)题目输入的是1e5的级别,一般构造的哈希表的大小是他的2-3倍,就能让冲突最小。- 使用0x3f3f3f3f作为INF,主要是,memet初始化是按照字节初始化的,所以有0, - 1, 0x3f,这样做的好处一个是方便初始化,不用for遍历每一位,还有其他关于最大值边界的好处,还没碰到具体的例子。- find函数本质就是阅读理解,当我h[k]不是空,而且不等于要找的x的时候,就自动找下一个空的位置,直到找到下一个空的位置,返回k,或者是不满足h[k] != k,意思就是找到元素的位置以后,返回找到的位置。```cpp#include <iostream>#include <cstring>using namespace std;const int N = 2e5 + 3, null = 0x3f3f3f3f;int h[N], n;int find(int x){int k = (x % N + N) % N;while (h[k] != null && h[k] != x){k++;if (k == N) k = 0;}return k;}int main(){ios::sync_with_stdio(false);cin >> n;memset(h, 0x3f, sizeof h); // sizeof 对于变量不用加上括号,对于类型来说必须加上括号,作为运算符的特殊之处while (n--){char op[2];cin >> op;int x;cin >> x;int k = find(x);if (op[0] == 'I') h[k] = x;else {if (x == h[k]) cout << "Yes" << endl;else cout << "No" << endl;}}return 0;}
四:字符串的前缀哈希表
KMP算法的劲敌,可快速判断一个字符串序列中,两个字串是否相等,KMP在求循环节有优势,其他的大概率不如字符串的前缀哈希表有优势。
本质就是把一个长的字符串变成一个一个的数字

使用字符串的前缀哈希的时候,都是假定没有冲突,没有处理冲突的方法
Q = 2e64的构造方法:,只要是溢出了就等于2e64,方法非常巧妙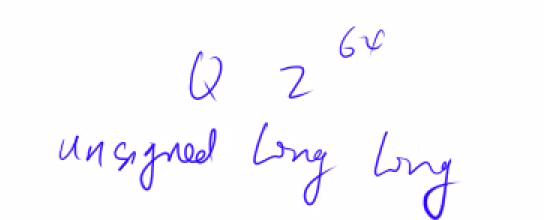
求解一段区间内的哈希值
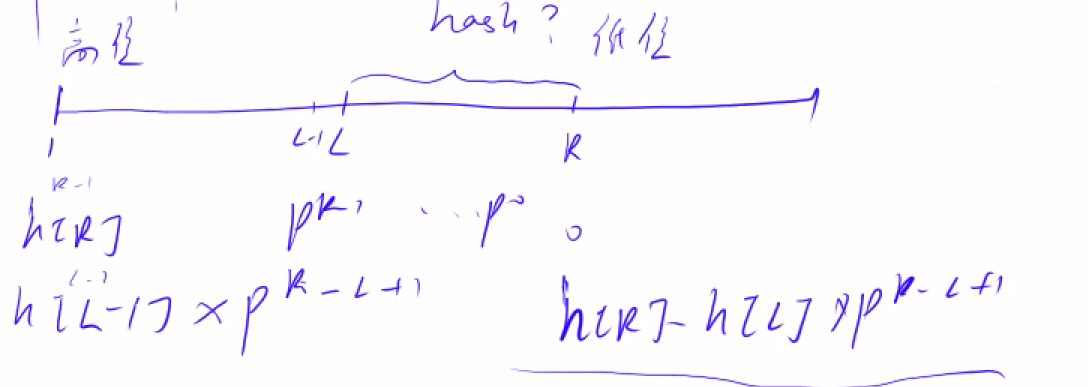
在计算前缀的时候:
#include <iostream>
using namespace std;
const int N = 1e5 + 10, P = 131;
typedef unsigned long long ULL;
ULL h[N], p[N];
int n, m;
char str[N];
int find(int l, int r)
{
return h[r] - h[l - 1] * p[r - l + 1];
}
int main()
{
ios::sync_with_stdio(false);
cin >> n >> m >> str + 1;
p[0] = 1;
for (int i = 1; i <= n; i++)
{
p[i] = p[i - 1] * P;
h[i] = h[i - 1] * P + str[i];
}
while (m--)
{
int l1, r1, l2, r2;
cin >> l1 >> r1 >> l2 >> r2;
if (find(l1, r1) == find(l2, r2))
{
cout << "Yes" << endl;
} else {
cout << "No" << endl;
}
}
return 0;
}

若有收获,就点个赞吧
0 人点赞
