数组形式
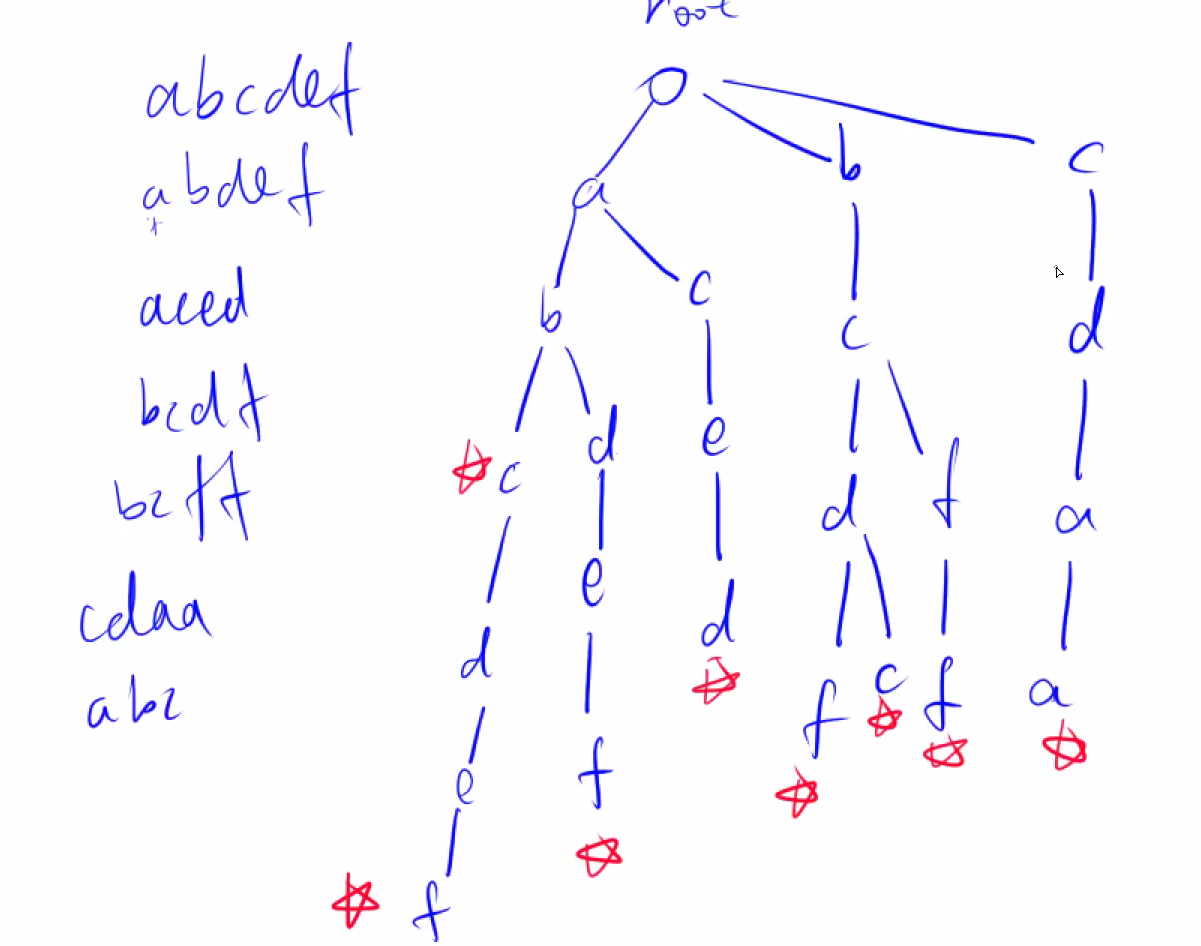
- 高效的存储和查找字符串集合的数据结构。
- 明白上面的存储结构,下面的代码其实有几个地方感觉很别扭,必P = son[p][u],实际检验过了,没什么错误,但是理解起来确实比较别扭。
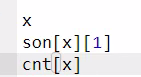 作为理解来讲,这三个已经非常的清楚表达son的含义,其中idx本质上就是结点的下标,其中cnt[x]本质上是以x作为结点的单词有多少。其实根据这个例子我感觉son[i][j],i本质上代表i的一个子结点。
作为理解来讲,这三个已经非常的清楚表达son的含义,其中idx本质上就是结点的下标,其中cnt[x]本质上是以x作为结点的单词有多少。其实根据这个例子我感觉son[i][j],i本质上代表i的一个子结点。- trie树适合的题目主要是针对26个或者52英文字母的
#include <iostream>using namespace std;const int N = 1e5 + 10; // 没轮次输入的字符串的长度int n;char str[N];int idx; // 这个idx很难理解,其实是针对每一个加入的新的结点,基于一个新的编号。这个编号是一次递增的int son[N][26]; // 每个结点下面可能有26个英文字母的结点int cnt[N]; // 通过idx每一个结点都有一个编号,每一轮次都是一个字符串,字符串的肯定需要标记结尾//,cnt【p】++就是结尾轮次的表示。void insert(char str[]) {int p = 0; // 从root开始for (int i = 0; str[i]; i++){int u = str[i] - 'a'; // 定位字符串是当前结点的第a b c d 。。。if (!son[p][u]) son[p][u] = ++idx; // 结点不存在的情况,不存在,给结点赋值为一次递增的序列号p = son[p][u]; // 跳到下一个结点}cnt[p]++;}int query(char str[]){int p = 0;for (int i = 0; str[i]; i++){int u = str[i] - 'a';if (!son[p][u]) return 0;p = son[p][u];}return cnt[p];}int main() {ios::sync_with_stdio(false);cin >> n;while (n--){char op[2];cin >> op;cin >> str;if (op[0] == 'I') insert(str);else cout << query(str) << endl;}return 0;}
链表形式
class Trie {private:// 判断当前结点是不是一个单词的最后一个字母bool isEnd;// 要求小写的英文字母,一共26个Trie* next[26];public:Trie(){// 每个结点初始化的时候,都必须赋值非终点结点isEnd = false;// 指针全部初始化为空memset(next, 0, sizeof next);}void insert(string word){Trie* node = this;for (int i = 0; i < word.size(); i++){//插入碰到的空的时候,需要构造新的结点。if (node -> next[word[i] - 'a'] == NULL){node -> next[word[i] - 'a'] = new Trie();}node = node -> next[word[i] - 'a'];}// 最后一个结点 必须标识为终点node -> isEnd = true;}bool search(string word){Trie* node = this;for (int i = 0; i < word.size(); i++){// 查找的时候只要找不到直接返回falseif (node -> next[word[i] - 'a'] == NULL)return false;node = node -> next[word[i] - 'a'];}// 即使没有碰到空的情况也必须判断这个结点是不是终点return node -> isEnd;}// 判断prefix是不是已经存在字典树的前缀bool startsWith(string prefix){Trie* node = this;for (int i = 0; i < prefix.size(); i++){if (node -> next[prefix[i] - 'a'] == NULL)return false;node = node -> next[prefix[i] - 'a'];}//不需要判断是不是终点,这是判断前缀return true;}// 析构函数,删除当前结点指向的所有的结点~Trie(){Trie* node = new Trie();for (int i = 0; i < 26; i++){if (node -> next[i] != NULL)delete node -> next[i];}}};

若有收获,就点个赞吧
0 人点赞
