Camera Object Detection
目标检测经历了从“传统的目标检测(2014年前)”到“基于深度学习的目标检测(2014年后)”。
基于深度学习的目标检测主要分为两类,一类是以RCNN为代表的两阶段检测,先在图像上产生候选区域,再对候选区域进行分类并预测目标物体位置。一类是以YOLO为代表的一阶段检测,使用一个网络同时产生候选区域并预测出物体的类别和位置。
R-CNN
特点
首次将CNN应用到目标检测领域,采用Selective Search + CNN + SVM。
经典的目标检测算法使用滑动窗法依次判断所有可能的区域。RCNN采用Selective Search方法,预先提取一系列较可能是物体的候选区域,之后仅在这些候选区域上提取特征,进行判断。
步骤
- 候选区域生成: Selective Search方法将一张图像生成1K~2K个候选区域,具体地,
- 使用一种分割手段,将图像分割成小区域
- 查看现有小区域,按照合并规则(颜色(颜色直方图)、纹理(梯度直方图)等)合并可能性最高的相邻两个区域。重复直到整张图像合并成一个区域位置
- 输出所有可能存在的区域,所谓候选区域(Region Proposal)
- 特征提取: 对每个候选区域,使用卷积网络提取特征 (CNN)
- 区域缩放。搜出的候选框是矩形的,而且是大小各不相同。然而CNN对输入图片的大小是有固定的,因此对于每个输入的候选框都需要缩放到固定的227x227大小。缩放方式:1、不管长宽比,直接缩放;2、先扩充再裁剪或者先裁剪再扩充。
- Alexnet特征提取部分包含了5个卷积层、2个全连接层,在Alexnet中p5层神经元个数为9216、 f6、f7的神经元个数都是4096,通过这个网络训练完毕后,最后提取特征每个输入候选框图片都能得到一个4096维的特征向量。
- 有监督预训练。在设计网络结构的时候,是直接用AlexNet的网络及其参数训练,然后再fine-tuning训练。
- 调优阶段。将 selective search 搜索出来的候选框对上面预训练的CNN模型进行fine-tuning训练。假设要检测的物体类别有N类,那么我们就需要把上面预训练阶段的CNN模型的最后一层给替换掉,替换成N+1个输出的神经元(加1,表示还有一个背景) (20 + 1bg = 21),然后这一层直接采用参数随机初始化的方法,其它网络层的参数不变;接着就可以开始继续SGD训练了。
- 类别判断: 特征送入每一类的SVM 分类器,判别是否属于该类
- 将最后一层得到的特征提取出来。然后对于每一个类别,使用该类别的SVM分类器对提取的特征向量进行打分,得到测试图片中对于所有region proposals的对于这一类的分数,再使用非极大值抑制(NMS)去除相交的多余的框。再对这些框进行边缘检测,就可以得到bounding-box。
- 位置精修: 使用回归器精细修正候选框位置
- 回归器:对每一类目标,使用一个线性回归器进行精修。输入为深度网络pool5层的4096维特征,输出为xy方向的缩放和平移,最终得到预测框的坐标。
Ground Truth 与Region proposal 的框有差异,bounding box回归就是微调窗口,使得经过微调后的窗口跟Ground Truth更接近,这样定位会更准确.
结论
缺陷
经典的R-CNN存在以下几个问题:
- 每张图片的每个region proposal都要做卷积,重复操作太多
- 时间和空间开销大(在训练SVM和回归的时候需要用网络训练的特征作为输入,特征保存在磁盘上再读入的时间开销较大)
- SVM和回归是事后操作,在SVM和回归过程中CNN特征没有被学习更新.
- 整体流程分多步骤(先在分类数据集上预训练,再进行fine-tune训练,然后再针对每个类别都训练一个线性SVM分类器,最后再用regressors对bounding box进行回归,并且bounding box还需要通过selective search生成)
Fast R-CNN
步骤
- 利用selective search 算法在图像中从上到下提取2000个左右的建议窗口(Region Proposal);
- 整张图片输入CNN,进行特征提取;
- 把建议窗口映射到CNN的最后一层卷积feature map上;
- 通过RoI pooling层使每个建议窗口生成固定尺寸的feature map;
由于region proposal的尺度各不相同,而期望提取出来的特征向量维度相同。RoI Pooling的提出巧妙的解决了尺度放缩的问题。其思路如下:
- 将region proposal划分为𝐻×𝑊大小的网格(VGG16: H=W=7)
- 对每一个网格做Max Pooling(即每一个网格对应一个输出值)
- 将所有输出值组合起来便形成固定大小为𝐻×𝑊的feature map
- 输出候选区域所属的类,和候选区域在图像中的精确位置。对分类概率和边框回归联合训练,分类使用Softmax来探测分类概率,回归使用Smooth L1
- softmax 是一个分类器,计算的是类别的概率(Likelihood),是 Logistic Regression 的一种推广. Logistic Regression 只能用于二分类,而 softmax 可以用于多分类.
改进
- 卷积不再是对每个region proposal进行,而是直接对整张图像,这样减少了很多重复计算。原来RCNN是对每个region proposal分别做卷积,因为一张图像中有2000左右的region proposal,肯定相互之间的重叠率很高,因此产生重复计算。FAST-RCNN将整张图像归一化后直接送入CNN,在最后的卷积层输出的feature map上,加入建议框信息,使得在此之前的CNN运算得以共享.
- RoI Pooling的提出,巧妙的解决了尺度放缩的问题。
- 将回归放进网络一起训练,同时用softmax代替SVM分类器,更加简单高效。R-CNN在训练时,是在采用SVM分类之前,把通过CNN提取的特征存储在硬盘上.这种方法造成了训练性能低下,因为在硬盘上大量的读写数据会造成训练速度缓慢.
训练所需空间大:R-CNN中独立的SVM分类器和回归器需要大量特征作为训练样本,需要大量的硬盘空间.FAST-RCNN把类别判断和位置回归统一用深度网络实现,不再需要额外存储.
结论
基于VGG16的Fast RCNN模型在训练速度上比R-CNN快大约9倍,比SPPnet快大约3倍;测试速度比R-CNN快大约213倍,比SPPnet快大约10倍,在VOC2012数据集上的mAP大约为66%。
缺陷
Region Proposal耗时
Faster R-CNN
Faster R-CNN的核心在于共享。Faster R-CNN在Fast R-CNN的基础上加入了RPN网络,RPN网络和Fast R-CNN的检测网络共享一套卷积层。
步骤
- 将整张图片输入CNN,进行特征提取,和fast RCNN一致;
- 用RPN生成proposals,这个网络是用来代替之前的search selective。每张图片生成300个建议窗口;
- RPN首先生成一堆Anchor box,对其进行裁剪过滤后通过softmax判断anchors属于前景(foreground)或者后景(background),即是物体or不是物体,所以这是一个二分类;同时,另一分支bounding box regression修正anchor box,形成较精确的proposal。
- 把proposals映射到CNN的最后一层卷积feature map上;
- 通过RoI pooling层使每个RoI生成固定尺寸的feature map;
- 该层利用RPN生成的proposals和VGG16最后一层得到的feature map,得到固定大小的proposal feature map,进入到后面可利用全连接操作来进行目标识别和定位
输出候选区域所属的类,和候选区域在图像中的精确位置。对分类概率和边框回归联合训练,分类使用Softmax来探测分类概率,回归使用Smooth L1
卷积层,用于提取图片的特征,输入为整张图片,输出为提取出的特征称为feature maps,该feature maps会用于后续的RPN层和全连接层。
- RPN网络(Region Proposal Network),用于生成候选区域,这个网络是用来代替之前的search selective的。输入为图片,输出为多个候选区域。(因为这里RPN网络和Fast R-CNN共用同一个CNN,所以这里输入也可以认为是feature maps)。(注:这里的较精确是相对于后面全连接层的再一次box regression而言)
- RoI pooling,和Fast R-CNN一样,将不同大小的输入转换为固定长度的输出,输入输出和Faste R-CNN中RoI pooling一样。
- 该层利用RPN生成的proposals和VGG16最后一层得到的feature map,得到固定大小的proposal feature map,进入到后面可利用全连接操作来进行目标识别和定位
- 分类和回归,这一层的输出是最终目的,输出候选区域所属的类,和候选区域在图像中的精确位置。
改进
- 提出了Region Proposal Network RPN, 替换selective search 来提取proposals。FASTER-RCNN创造性地采用卷积网络自行产生建议框,并且和目标检测网络共享卷积网络,使得建议框数目从原有的约2000个减少为300个,且建议框的质量也有本质的提高.
- 提出了anchors。anchors可以理解为一些预设大小的框,anchors的种类用k表示,在原文中k=9,由3种面积(128 256 512)和3种长宽比(1:1,1:2,2:1)组成,这里anchors的大小选取是根据检测时的图像定义。
- Faster RCNN网络支持输入图像的多尺度训练,由于RPN是FCN网络 和 RoI Pooling,使得faster rcnn对输入图像的尺寸无感
RPN的实现方式:在feature map上用一个3*3的滑窗生成一个长度为256维长度的全连接特征.然后在这个256维的特征后产生两个分支的全连接层:
(1)reg-layer,用于预测proposal的中心锚点对应的proposal的坐标x,y和宽高w,h;
(2)cls-layer,用于判定该proposal是前景还是背景
(3)注意:这里2k中的2指cls层的分类结果包括前后背景两类,4k的4表示一个Proposal的中心点坐标x,y和宽高w,h四个参数.
缺陷
Feature Pyramid Networks (FPN)

识别不同大小的物体是计算机视觉中的一个基本挑战,我们常用的解决方案是构造多尺度金字塔。
如上图a所示,这是一个特征图像金字塔,整个过程是先对原始图像构造图像金字塔,然后在图像金字塔的每一层提出不同的特征,然后进行相应的预测(BB的位置)。这种方法的缺点是计算量大,需要大量的内存;优点是可以获得较好的检测精度。它通常会成为整个算法的性能瓶颈,由于这些原因,当前很少使用这种算法。
如上图b所示,这是一种改进的思路,学者们发现我们可以利用卷积网络本身的特性,即对原始图像进行卷积和池化操作,通过这种操作我们可以获得不同尺寸的feature map,这样其实就类似于在图像的特征空间中构造金字塔。实验表明,浅层的网络更关注于细节信息,高层的网络更关注于语义信息,而高层的语义信息能够帮助我们准确的检测出目标,因此我们可以利用最后一个卷积层上的feature map来进行预测。这种方法存在于大多数深度网络中,比如VGG、ResNet、Inception,它们都是利用深度网络的最后一层特征来进行分类。这种方法的优点是速度快、需要内存少。它的缺点是我们仅仅关注深层网络中最后一层的特征,却忽略了其它层的特征,但是细节信息可以在一定程度上提升检测的精度。
因此有了图c所示的架构,它的设计思想就是同时利用低层特征和高层特征,分别在不同的层同时进行预测,这是因为我的一幅图像中可能具有多个不同大小的目标,区分不同的目标可能需要不同的特征,对于简单的目标我们仅仅需要浅层的特征就可以检测到它,对于复杂的目标我们就需要利用复杂的特征来检测它。整个过程就是首先在原始图像上面进行深度卷积,然后分别在不同的特征层上面进行预测。它的优点是在不同的层上面输出对应的目标,不需要经过所有的层才输出对应的目标(即对于有些目标来说,不需要进行多余的前向操作),这样可以在一定程度上对网络进行加速操作,同时可以提高算法的检测性能。它的缺点是获得的特征不鲁棒,都是一些弱特征(因为很多的特征都是从较浅的层获得的)。
FPN架构如图d所示,整个过程如下所示,首先我们在输入的图像上进行深度卷积,然后对Layer2上面的特征进行降维操作(即添加一层1x1的卷积层),对Layer4上面的特征就行上采样操作,使得它们具有相应的尺寸,然后对处理后的Layer2和处理后的Layer4执行加法操作(对应元素相加),将获得的结果输入到Layer5中去。其背后的思路是为了获得一个强语义信息,这样可以提高检测性能。这次我们使用了更深的层来构造特征金字塔,这样做是为了使用更加鲁棒的信息;除此之外,我们将处理过的低层特征和处理过的高层特征进行累加,这样做的目的是因为低层特征可以提供更加准确的位置信息,而多次的降采样和上采样操作使得深层网络的定位信息存在误差,因此我们将其结合其起来使用,这样我们就构建了一个更深的特征金字塔,融合了多层特征信息,并在不同的特征进行输出。
简介
2017年,T.-Y.Lin等人在Faster RCNN的基础上进一步提出了特征金字塔网络FPN(Feature Pyramid Networks)技术。在FPN技术出现之前,大多数检测算法的检测头都位于网络的最顶层(最深层),虽说最深层的特征具备更丰富的语义信息,更有利于物体分类,但更深层的特征图由于空间信息的缺乏不利于物体定位,这大大影响了目标检测的定位精度。为了解决这一矛盾,FPN提出了一种具有横向连接的自上而下的网络架构,用于在所有具有不同尺度的高底层都构筑出高级语义信息。FPN的提出极大促进了检测网络精度的提高(尤其是对于一些待检测物体尺度变化大的数据集有非常明显的效果)。
【性能】
将FPN技术应用于Faster RCNN网络之后,网络的检测精度得到了巨大提高(COCO mAP@.5=59.1%, COCO mAP@[.5,.95]=36.2%),再次成为当前的SOTA检测算法。此后FPN成为了各大网络(分类,检测与分割)提高精度最重要的技术之一。
FPN框架解析
- 利用FPN构建Faster R-CNN检测器步骤
首先,选择一张需要处理的图片,然后对该图片进行预处理操作;
然后,将处理过的图片送入预训练的特征网络中(如ResNet等),即构建所谓的bottom-up网络;
接着,如图5所示,构建对应的top-down网络(即对层4进行上采样操作,先用1x1的卷积对层2进行降维处理,然后将两者相加(对应元素相加),最后进行3x3的卷积操作,最后);
接着,在图中的4、5、6层上面分别进行RPN操作,即一个3x3的卷积后面分两路,分别连接一个1x1的卷积用来进行分类和回归操作;
接着,将上一步获得的候选ROI分别输入到4、5、6层上面分别进行ROI Pool操作(固定为7x7的特征);
最后,在上一步的基础上面连接两个1024层的全连接网络层,然后分两个支路,连接对应的分类层和回归层;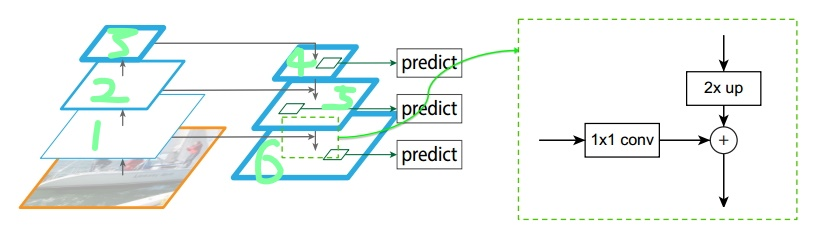
FPN整体架构
注:层1、2、3对应的支路就是bottom-up网络,就是所谓的预训练网络,文中使用了ResNet网络;由于整个流向是自底向上的,所以我们叫它bottom-up;层4、5、6对应的支路就是所谓的top-down网络,是FPN的核心部分,名字的来由也很简单。
为什么FPN能够很好的处理小目标?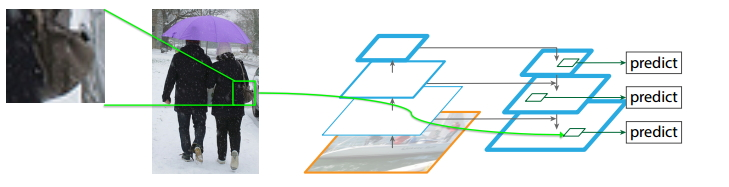
如上图所示,FPN能够很好地处理小目标的主要原因是:
- FPN可以利用经过top-down模型后的那些上下文信息(高层语义信息);
- 对于小目标而言,FPN增加了特征映射的分辨率(即在更大的feature map上面进行操作,这样可以获得更多关于小目标的有用信息),如图中所示;
YOLO
步骤
参考资料

若有收获,就点个赞吧
0 人点赞
