- 1.int整型
- 2.str字符串
- 2.1独有功能(18/48)
- 2.1.1判断字符串时候以XX开头,得到布尔值 .startswitch()
- 2.1.2 判断字符串是否以XX结尾,得到一个bool值 .endswith()
- 2.1.3 判断字符串时候为10进制数,得到一个bool值.isdecimal()
- 2.1.4 去除字符串两边的空格换行符制表符,得到一个新的字符串.strip()
- 2.1.5字符串变的大写,得到一个新的字符串.upper()
- 2.1.6 字符串变小写,得到一个新的字符串.lower()
- 2.1.7字符串内容替换,得到一个新的字符串.replace()
- 2.1.8 字符串切割,得到一个列表.split() #默认是从左边开始切割
- 2.1.9 字符串拼接得到新的字符串”符号”.join() 指定使用某种符号进行拼接
- 2.1.10 格式化字符串得到新的字符串.format()
- 2.1.11 字符串转换为字节类型.encode()
- 2.1.12 将字符串居中.center()
- 2.1.13 填充0.zfill()
- find() 返回字符的索引
- count() 统计出现的次数
- expandtabs() 指定制表符的宽度
- capitalize() 首字母大写
- swapcase() 大写边小写,小写变大写
- title() 每个单词的首字母大写
- 2.2公共功能
- 2.3转换
- 2.1独有功能(18/48)
- 3.bool布尔类型
- 4.list列表类型 []
- 6.dict字典类型{}
- 7.set集合类型{}
- 5.变量
- 6.内存的指向关系
- 8.None类型
- 9.输入
- 10.条件语句
- 11.循环语句
- 13.运算符
1.int整型
数字整数就是整型,支持加减乘除% * += -= = 等操作
int(66) 整型float() 浮点型
1.1独有功能
整型没有独有功能
定义形式就是在变量后面跟.功能
1.2共有功能
加减乘除等
1.3转换
bool转整型int(true)#1int(False)#0字符串转整型进制之间转换时需要借助10进制,10进制和其他进制之间可以互相转换,但是16 ,8 2,进制之间无法直接转换int('0x101',base=16)#把字符串看作16进制,然后转换为16进制int('186',base=10)#把字符串看作10进制,然后转换为10进制int('0o10',base=8)#把字符串看作8进制,然后转换为8进制int('ob10110',base=2)#把字符串看作2进制,然后转换为2进制
1.4其他知识
整型在python2和3中的区别
python2中int有整型(限制了长度)和长整型,长整型表示整型表示不了的数据
python3中int没有限制
python3中进行除法运算时得到的是具体的值
python2中除法运算默认得到整数//地板除
from __future__ import division#引入此模块,在2中也可以得到具体的值
2.str字符串
字符串就是文本信息,必须用引号括起来,支持相加或者相乘
相加是将两个字符串拼接起来
相乘是将一个字符串重复多次
单行文本 #对于单行文本,可以使用单引号或者双引号括起来print('你好')多行文本print("""白日依山尽黄河入海流""")
2.1独有功能(18/48)
2.1.1判断字符串时候以XX开头,得到布尔值 .startswitch()
name="刘小流"v2 = name.startswith("刘")print(v2)True
2.1.2 判断字符串是否以XX结尾,得到一个bool值 .endswith()
2.1.3 判断字符串时候为10进制数,得到一个bool值.isdecimal()
还有.isdigit() 此功能再判断时会把①此情况也判断为是10进制数
v1="123"v2=v1.isdecimal()print(v2)True
2.1.4 去除字符串两边的空格换行符制表符,得到一个新的字符串.strip()
只去除两边不去除中间
.lstrip()去除左边的
.rstrip()去除右边的
需要去除指定内容是,再括号里面加上指定的内容既可
v1=" 你好 "v2=v1.strip()print(v2)//你好
2.1.5字符串变的大写,得到一个新的字符串.upper()
v1='abc'v2=v1.upper()print(v2)//ABC
2.1.6 字符串变小写,得到一个新的字符串.lower()
2.1.7字符串内容替换,得到一个新的字符串.replace()
v1='你好好吗'v2=v1.replace("好","坏")print(v2)//你坏坏吗 # 默认所有都改v2=v1.replace("好","坏",1)只改一个 // 你坏好吗
2.1.8 字符串切割,得到一个列表.split() #默认是从左边开始切割
从右边开始切割.rsplit()
从第几个符号开始切割.split(‘|’,2) ,从左边第2个|切割
v1="你好|不好|好不"v2=v1.split('|') #根据特定的字符进行切割,然后保存到列表中print(v2) #["你好",”不好“,”好不“]
2.1.9 字符串拼接得到新的字符串”符号”.join() 指定使用某种符号进行拼接
data_list=["你"," 好"," 吗"]v2="*".join(data_list)//将data_list列表使用*拼接起来你*好*吗
2.1.10 格式化字符串得到新的字符串.format()
text="我叫{},今年{}岁".format("小刘",18)text="我叫{0},今年{1}岁".format("小刘",18)text="我叫{name},今年{old}岁".format(name="小刘",old=18)
%进行格式化
有百分比的情况需要输入两个%%,以表示这是一个百分比
text = "%s,这个片我已经下载了90%%了,居然特么的断网了" %"兄弟"print(text)
text="我叫%s,今年%d岁"%("小刘",18)我叫小刘,今年18岁# %s用与给字符串进行占位,%d给整型占位text="我叫%(name)s,今年%(old)d岁"%("name":"小刘","old":18)我叫小刘,今年18岁
.f
name="小刘"old=18tetx=f"我叫{name},几年{old}岁"f'{print("12+2")}'对于f{}里面的可以当作表达式运行
2.1.11 字符串转换为字节类型.encode()
字节转换为字符串.decode()
name="小刘"v1=name.encode("utf_8")utf8是字节类型v2=v1.decode("utf8")将utf8的字节转换为字符串
2.1.12 将字符串居中.center()
居右.rjust()
居左.ljust()
v1="小流域"v2=v1.center(10,".."),总体长途10,将v1居中,不够的长度用..补全v2=v1.ljust(10,"=") 小流域===========v2=v1.rjust(10,"=") =======小流域
2.1.13 填充0.zfill()
data="alex"v1=data.zfill(10) ,总长度为10不够用0填充到左边000000alex
find() 返回字符的索引
n1 = "xscfg"n1.find('s') # 1找不到的内容返回-1
count() 统计出现的次数
n1 = 'xxxxx'n1.count('x') # 5
expandtabs() 指定制表符的宽度
n1 = 'hello\tworld'n1.expandtabs(2) 两个空格 \t是空格
capitalize() 首字母大写
n1 = 'hello'n1.capitalize() # Hello
swapcase() 大写边小写,小写变大写
n1 = 'Hello'n1.swapcase() # hELLO
title() 每个单词的首字母大写
n1 = 'hello word'n1.title() # Hello Woed
2.2公共功能
2.2.1 字符串相加+
2.2.2 字符串相乘
2.2.3获取长度 len()
v1="小刘"v2=len(v1)
2.2.4 获取字符串中的字符,索引[]
字符串只能同通过索引来取值,无法修改值,字符串在内部存储时不允许修改内部元素,只能重新创建
v1="你还好把"0 1 2 3v1[0] "你"
2.2.5 获取字符串中的子序列,切片[]
前取后不取
切片也是不能修改数据,只能读取
v1="你还好把"0 1 2 3-4 -3 -2 -1v1[0:2:2] 从0开始取,取到2结束不包括2,步长为2 得到 "你"v1[2:-1] "好"v1[::-1] # 字符串倒过来v1[0:3:-1] # 取不到,是0-3但是步长是-1 ,
2.2.6 循环
message = "来做点py交易呀"index = 0while index < len(message):value = message[index]print(value)index += 1=========================================message = "来做点py交易呀"for char in message:print(char)
2.2.7 range()可以创建一系列数字
range(10) [0,1,2,3,4,5,6,7,8,9]range(1,10)[1,2,3,4,5....9]range(1,10,2)[1,3,5,7,9]range(10,1,-1)[10,9,8,7,6,5,4,3,2]
2.3转换
一般只有整型转字符串才有意义
3.bool布尔类型
布尔类型一共有两个值False True
3.1独有功能
没有
3.2公共功能
没有
3.3转换
经常会遇到其他类型转换为bool的场景,
0,空字符串,空列表,空元组,空字典,转换为bool是都为False,其他都是True
3.4其他知识
如果在条件语句的后面跟值的话,会先转换成bool类型再进行条件判断
4.list列表类型 []
列表list 是有序的可以变的容器,里面可以放多个不同类型的元素
4.1定义
不可变类型:字符串,布尔,整型,元组,(内部数据已经最小无法进行修改,不可变指的是值改变id也会变)
可变类型:列表,字典,(内部数据元素可以修改,可变指的是值改变id不会变)
data_list=[1,2,3,'你','13']
4.2独有功能
4.2.1 追加,在列表的尾部追加值.append()
v1=[1,2,3,"你","dir"]v2=100v1.append(v2) 将v2的值追加到v1列表中v1=[1,2,3,"你","dir",100]
4.2.2 批量追加,将一个列表中的元素逐一加到零一个列表.extend()
v1=["ni","好","吗"]v2=['很','好']v1.extend(v2) 将v2中的值逐一加到v1中
4.2.3 插入,在源列表的指定索引位置插入值.insert()
v1=["ni","好","吗"]v1.insert(0,"100") ["100","ni","好","吗"]在第0个索引插入
4.2.4 在原列表中根据值删除(从左到右删除),没有找到值会报错.remove()
没有返回值,None
v1=["ni","好","吗"]v1.remove("好")
4.2.5在原列表中根据索引剔除某个元素(根据索引位置删除).pop()
不传参默认删除最后一个,返回值是删除的那个值
v1=["ni","好","吗"]0 1 2v1.pop("1")
4.2.6 清空原列表.clear()
v1=["ni","好","吗"]0 1 2v1.clear()
4.2.7 根据值获取索引.index()
v1=["ni","好","吗"]0 1 2v1.index(”好“) 1
4.2.8 列表元素排序.sort()
列表里的元素必须是相同类型的才可以排序
数字排序num_list = [11, 22, 4, 5, 11, 99, 88]num_list.sort() 让num_list从小到大排序num_list.sort(reverse=True) 让num_list从大到小排序字符串排序# 字符串排序是根据 ASCI码表按顺序排序user_list = ["王宝强", "Ab陈羽凡", "Alex", "贾乃亮", "贾乃", "1"]# [29579, 23453, 24378]# [65, 98, 38472, 32701, 20961]# [65, 108, 101, 120]# [49]列表对比大小# 是根据相同位置的元素进行对比,且必须是同种类型的元素,第一个比较出大小后不再往后比较n1 = [1,'A','c']n2 = [5,'B,'D']1与5比较,5大于1则n2大于n1
4.2.9 反转列表.reverse()
不是排序就是反转过来
v1=["ni","好","吗"]0 1 2v1.reverse()
4.2.10 查找索引 index()
n1 = ['12','34','56']n1.index('12') # 0
4.3公共功能
4.3.1相加,两个列表相加可以生成一个新的列表相当于拼接起来
v1=[1,2,3]v2=["比",'比']v1+v2=[1,2,3,"比",'比']
4.3.2相乘,列表相乘,将列表中的元素再创建N份获得新的列表
v2=["比",'比']v3=["比",'比']*2["比",'比',"比",'比']
4.3.3 成员运算符 in
列表内部是由多个元素组成的,可以通过in来判断元素是否再列表中
列表再检查元素是否存在的时候,是采用逐一比较的方式,效率比较低
user_list=[1,2,3,"比"]v2= "比" in user_listTrue
4.3.4 获取长度
user_list=[1,2,3,"比"]print(len(user_list))4
4.3.5 索引,针对一个元素的操作
超出索引位置会报错
查user_list=[1,2,3,"比"]0 1 2 3print(user_list[0]) 1print(user_list[1]) 2print(user_list[2]) 3改user_list=[1,2,3,"比"]0 1 2 3user_list[0] = "你" [你,2,3,"比"]删除user_list=[1,2,3,"比"]del user_list[1]user_list.removep[1]v1=user_list.pop[1]
4.3.6 切片,根据索引对列表中的多个元素操作
切片相当于拷贝,且是浅拷贝
前去后不取
查user_list=[1,2,3,"比"]print(user_list[0:2]) [1,2]改user_list[0:2]=[100,200] [100,200,3,"比]user_list = ["范德彪", "刘华强", '尼古拉斯赵四']user_list[10000:] = [11, 22, 33, 44]print(user_list) # 输出 ['范德彪', '刘华强', '尼古拉斯赵四', 11, 22, 33, 44]user_list = ["范德彪", "刘华强", '尼古拉斯赵四']user_list[-10000:1] = [11, 22, 33, 44]print(user_list) # 输出 [11, 22, 33, 44, '刘华强', '尼古拉斯赵四']删user_list = ["范德彪", "刘华强", '尼古拉斯赵四']del user_list[1:]print(user_list) # 输出 ['范德彪']
4.3.7 步长
user_list=['你','好','吗','1',1]0 1 2 3 4user_list[1:3:2] 好 取索引1到3的值,隔2取1列表反转user_list=['你','好','吗','1',1]user_list[::-1]或user_list.reverse()
4.3.8 for 循环
user_list=['你','好','吗','1',1]for i in user_list: 用i去游览列表中的元素print(i)面试题# 错误方式, 有坑,结果不是你想要的。user_list = ["刘的话", "范德彪", "刘华强", '刘尼古拉斯赵四', "宋小宝", "刘能"]for item in user_list:if item.startswith("刘"):user_list.remove(item)print(user_list)正确方法user_list = ["刘的话", "范德彪", "刘华强", '刘尼古拉斯赵四', "宋小宝", "刘能"]for index in range(len(user_list) - 1, -1, -1):item = user_list[index]if item.startswith("刘"):user_list.remove(item)print(user_list)
4.3.9 转换
- int bool类型无法转换为列表类型
str转列表
v1='你好吗'list(v1) ['你','好','吗']
元组和集合,字典转换为列表
```python v1=(11,12,13,145) 元组 list(v1) [11,12,13,145]
v2 = {“alex”,”eric”,”dsb”} 集合 vv2 = list(v2) 列表 [“alex”,”eric”,”dsb”]
v3 = {‘k1’:1,’k2’:2,’k3’:3} list(v3) [k1,k2,k3]
4.4 嵌套
列表属于容器,内部可以存放各种数据,也可以支持列表的嵌套 data = [ “谢广坤”,[“海燕”,”赵本山”],True,[11,22,[999,123],33,44],”宋小宝” ]
嵌套值的索引
data = [ “谢广坤”,[“海燕”,”赵本山”],True,[11,22,[999,123],33,44],”宋小宝” ] 0 1 0 1 2 3 0 1 4 print( data[0] ) # “谢广坤” print( data[1] ) # [“海燕”,”赵本山”] print( data[0][2] ) # “坤” print( data[1][-1] ) # “赵本山”
<a name="1d58d3a6"></a>#### 5.tuple元组类型 tuple()
元组是一个有序且不可变的容器,里面可以存放多个不同类型的元素 (1,1.2,’AAA’) 不可变是指里面的元素不可以该改变,也就是里面元素的内存地址不可以改变(内存地址没变,就是值没变),但是可以增加元素
v1=(11,22,33) v2=(“alex”,”old”)
v3=(1) 1 v4=(1,2) (1,2) v5 = (1,) (1)
<a name="daad225a"></a>#### 5.1独有功能无<a name="6e2dd5d1"></a>#### 5.2公共功能<a name="fc29ccd4"></a>##### 5.2.1 相加,两个元组相加获取一个新的元组```pythondata = ("赵四","刘能") + ("宋晓峰","范德彪")print(data) # ("赵四","刘能","宋晓峰","范德彪")
5.2.2 相乘,列表相乘,将列表中的元素再创建N份并生成一个新的元组
data = ("赵四","刘能") * 2print(data) # ("赵四","刘能","赵四","刘能")v1 = ("赵四","刘能")v2 = v1 * 2print(v1) # ("赵四","刘能")print(v2) # ("赵四","刘能","赵四","刘能")
5.2.3 获取长度
data_list=(1,2,"刘","马")print(len(data_list))
5.2.4 索引
索引元组里面没有的值会报错
data_list=(1,2,"刘","马")0 1 2 3data_list[0]
5.2.5 切片
user_list = ("范德彪","刘华强",'尼古拉斯赵四',)print( user_list[0:2] )print( user_list[1:] )print( user_list[:-1] )
5.2.6 步长
user_list = ("范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能")print( user_list[1:4:2] )print( user_list[0::2] )print( user_list[1::2] )print( user_list[4:1:-1] )
5.2.7 for 循环
user_list = ("范德彪","刘华强",'尼古拉斯赵四',"宋小宝","刘能")for item in user_list:if item == '刘华强':continueprint(name)
5.3转换
目前只有str和list可以转换为元组
name = "刘小刘"v2 = [100]v3 = tuple(name)v4 = tuple(v2) 如果列表中只有一个元素的时候会自动加逗号print(v3)print(v4)('刘', '小', '刘')(100,)
5.4 嵌套
6.dict字典类型{}
字典是无序,元素必须由键值对组成,键不可以重复,是可变的容器
无序在Python3.6字典就是有序了,之前的字典都是无序
v1={"name='刘'",pw="123"}键 值
6.1定义
键:必须是可以哈希的 int bool str tuple 且不能重复,重复只保存一个
值:任意类型
v1={}v1=dict()
6.2独有功能
6.2.1 获取值.get(“键”)
根据键,获取值,key不存在返回None
v1={"name":'刘',"pw":"123"}v2=v1.get("name") 刘v3=v1.get("old") None
6.2.2所有的键.Keys()
python3中获取键后返回的是高仿列表可以被循环
v1={"name":'刘',"pw":"123"}v2=v1.keys() (["name","pw"])
6.2.3所有的值.values()
v1={"name":'刘',"pw":"123"}v2=v1.values() (["刘","123"])
6.2.4所有的键值.items()
v1={"name":'刘',"pw":"123"}v2=v1.items() #([('name','刘'),('pw','123')])是一个迭代器
6.2.5 设置值.setdefault()
如果有key则不添加,返回值是字典中key对应的值
如果没有key则添加进去,返回字典中key对应的值
v1={"name":'刘',"pw":"123"}v1.setdefault("name1",'王'){'name1':'王',"name":'刘','pw':"123"}
6.2.6更新键值对.update({})
v1={"name":'刘',"pw":"123"}v1.update({"name":'王','six':6})//没有的键直接添加进去,有的更新掉
6.2.7移除指定的键值对.pop(键)
v1={"name":'刘',"pw":"123"}v1.pop=("name")//返回值是刘,也就是返回删除的值{pw="123"}
6.2.8按照顺序移除,先移除后面的.popitem()
v1={"name":'刘',"pw":"123"}v2=v1.popitem()// 返回值是("键":"值"){"name"='刘'}
6.3公共功能
6.3.1 求并集 |
6.3.2 求长度
v1={"name":'刘',"pw":"123"}v2=len(v1) #2
6.3.3 是否包含 in not in
v1={"name":'刘',"pw":"123"}v2= "pw" in v1 True
6.3.4索引,是对键操作[]
如果键 不存在的会报错
v1={"name":'刘',"pw":"123"}v1["name"] 刘
6.3.5根据键,修改值,添加值,删除键值对
v1={"name":'刘',"pw":"123"}v1["old"]=16 {"name":'刘',"pw":"123",'old':16}v1['name']= "王"del v1[name]
6.3.6 for循环
由于字典也属于是容器,内部可以包含多个键值对,可以通过循环对其中的:键、值、键值进行循环;
info = {"age":12, "status":True,"name":"武沛齐"}for key,value in info.items():# 键 值print(key,value)
6.4转换
v1=dict([("name","v2"),["A","B"]]){'name':"v2","A":"B"}
keys = ['name','age','gender']将列表的元素取出来作为字典的键,值为Noned = {}.fromkeys(keys,None)原理就是for循环keys将元素作为键,None作为值配对,添加到d
6.5为什么查询速度快
data = {"张三":123,"王五":456,'李四':789}# 字典的每个key都先经过hash生成一段固定的hash值# 字典把生成的hash值放到一个列表里面比如:# [10,20,30]# 当我们想查找张三的信息时候会把张三先hash得到10这个值,然后拿这个值去列表里找,通过算法,只要找到了99的位置就可以定位到张三对应的value值
7.set集合类型{}
- 无序不允许出现重复的值,可变类型,集合的元素必须要可哈希
- 不能通过索引取值
- 可以添加删除元素
- 不允许元素重复
- 用在维护数据量大且不重复的场景,如爬虫,避免找到重复的数据
- 还用在关系运算
data_set{11,12,13}定义空集合的时候 v1=set() 不能v1={}这样是定义一个空字典
7.1 独有功能
7.1.1添加元素.add()
data={"刘","王","李"}data.add("孙") {"刘","王","李","孙"}
7.1.2 删除元素.discard()
删除元素不存在 do nothing
data={"刘","王","李"}data.discard("王") {"刘","李"}
7.1.3交集 .intersection()
取两个集合都有的元素
data={"刘","王","李"}name={"刘","孙","子"}v1=data.intersection(name)v1=data & name
7.1.4并集.union()
取两个结合的并集
data={"刘","王","李"}name={"刘","孙","子"}v1=data.union(name) # {"刘","王","李","孙","子"}
7.1.5差集.difference()
data={"刘","王","李"}name={"刘","孙","子"}v1=data.difference(name) data中有但是name中没有的值 {“王“,”李”}v1=data - name
7.2公共功能
7.2.1 计算差集 -
7.2.2 计算交集 &
7.2.3 计算并集 |
7.2.4 计算长度
7.2.5 对称差集 ^
两个集合的差集进行合并
data={"刘","王","李"}v1=len(data)
7.2.5 for循环
v = {"刘能", "赵四", "尼古拉斯"}for item in v:print(item)
7.3转换
在转换的时候用set包裹一下就可以,并且数据如果有重复会自动删除
int list tuple dict str 都可以转换为集合
v1 = "刘小刘"v2 = set(v1)print(v2) # {"刘","小","刘"}v1 = [1,2,1,4,5,5]v2 = set(v1)print(v2) # {1,2,4,5}v1 = (1,2,3,4)v2 = set(v1)print(v2) # {1,2,3,4}
7.4嵌套
7.4.1集合的存储原理
第一步,将存储的数据转换为一个数值,
第二步,取余数
第三步,将存储的数据放在余数的索引位置

7.4.2 元素必须可哈希
集合的元素必须和哈希,内同通过哈希函数把值转换成一个数字
可哈希的数据类型有 int bool str tuple 不可哈希的有list set
7.4.3对比和嵌套
True和False本质上存储的是 1 和 0 ,集合又不允许重复,所以在整数 0、1和False、True出现在集合中会去重复
| 类型 | 是否可变 | 是否有序 | 元素要求 | 是否可哈希 | 转换 | 定义空 |
|---|---|---|---|---|---|---|
| list | 是 | 是 | 无 | 否 | list(其他) | v=[]或v=list() |
| tuple | 否 | 是 | 无 | 是 | tuple(其他) | v=()或v=tuple() |
| set | 是 | 否 | 可哈希 | 否 | set(其他) | v=set() |
8.float 浮点类型
4.类型之间的转换
想转换成什么数据类型就用什么类型的英文表示进行包裹
字符串转换整型时只支持数字类型的文本进行转换
0,空字符串,空列表,空元组,空集合,空字典,转换为bool时为false,其他转换为bool都为True
str='666'int(str)
5.变量
变量名 :指向赋值符号右侧值的内存地址,用来访问赋值符号右侧的值
赋值符号:将变量值的内存地址绑定给变量名
变量值 :一组数据
变量先定义后引用
id(变量名) # 查看内存地址type(变量名) # 查看类型is # 比较两个变量的内存地址是否一样== # 比较两个值是否一样 ,值相同内存地址不一样(pycharm里会一样)"""小整数池(-5,256) 在python解释器启动的时候就会在内存中先申请 ,当用到这些值的时候不再开辟新的内存空间直接引用"""
变量名规范
- 数字字母和下划线组成
- 不能数字开头
不能是python的内置关键字
建议:
下划线连接命名
- 见明知意
常量
python中没有常量的概念,但是在程序开发过程中会涉及到常量的概念,人为定义变量名全大写为常量
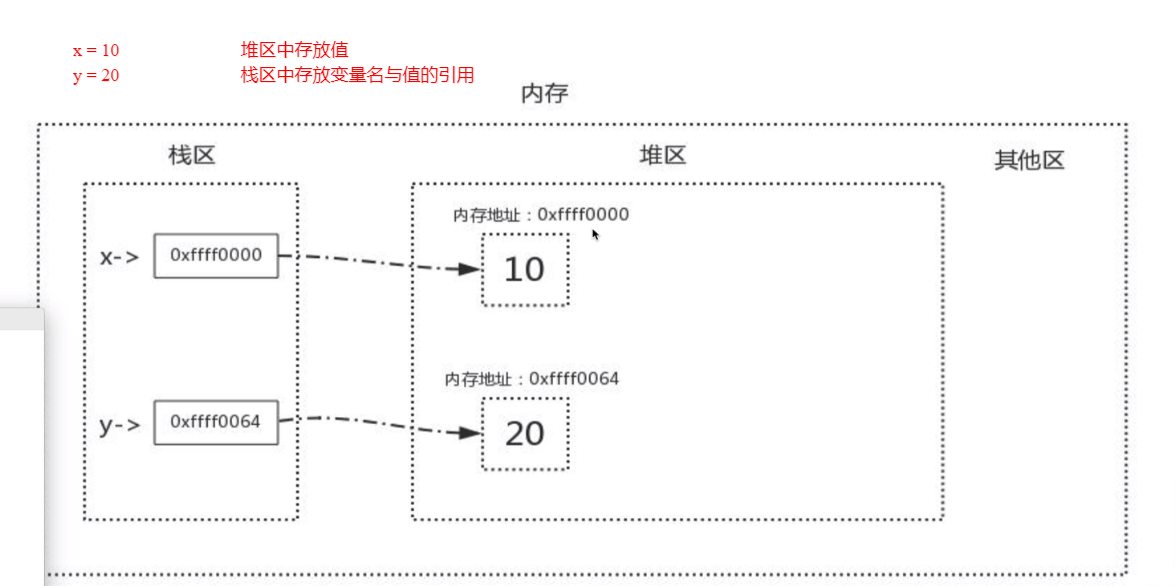
6.内存的指向关系
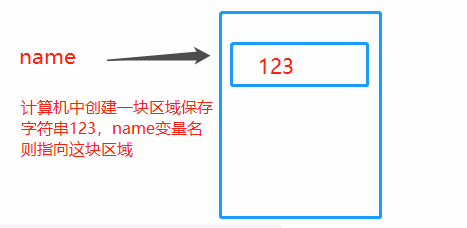
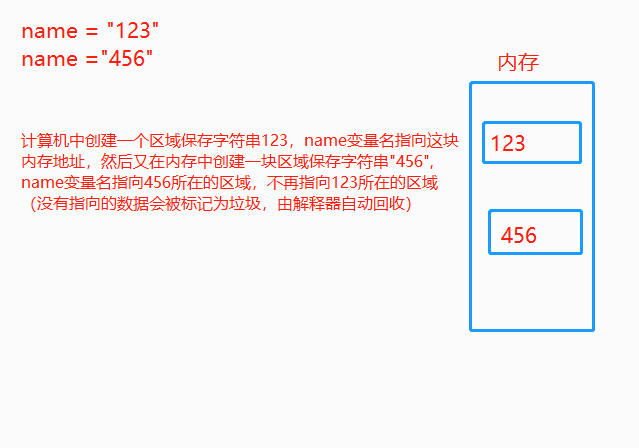
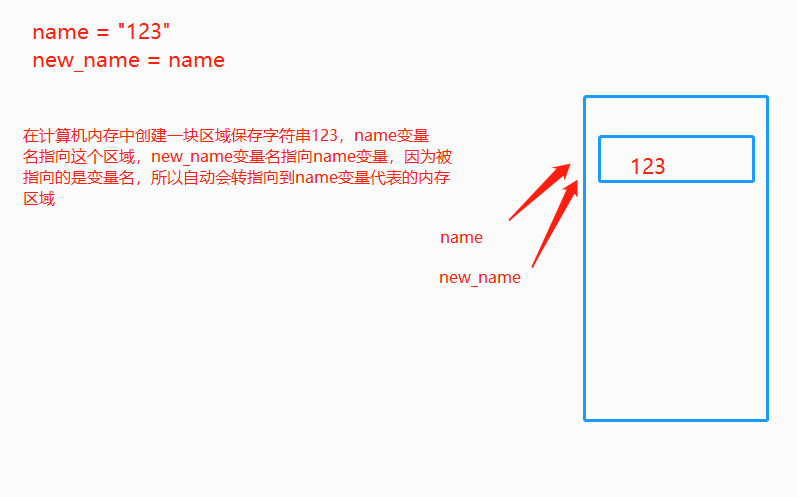
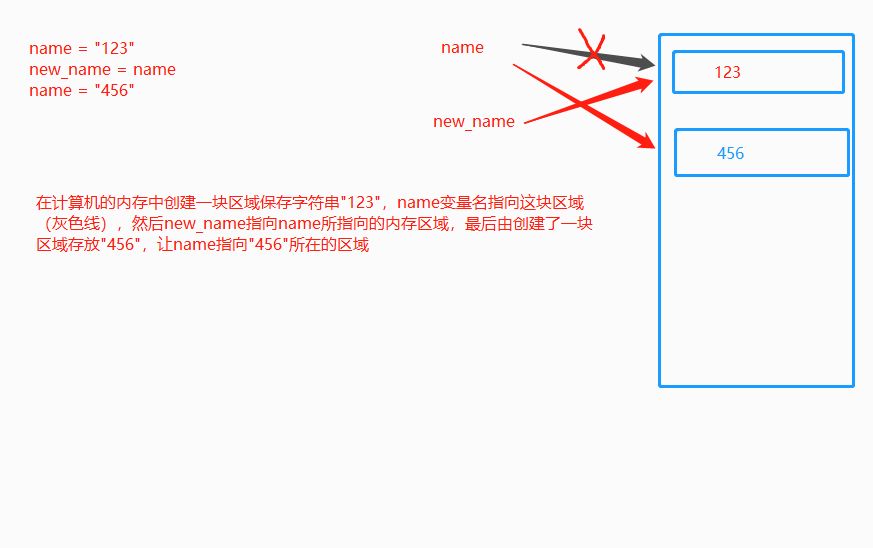
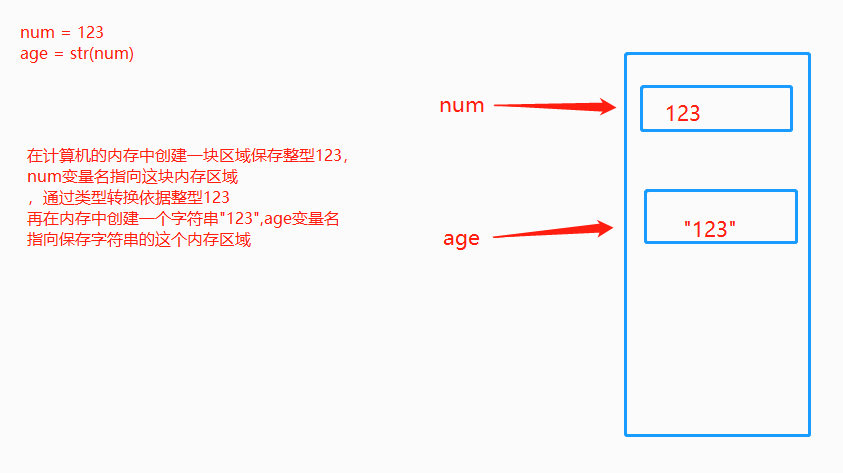
内存管理:
垃圾回收机制(GC)管理的是堆区
垃圾:当一个变量值被绑定的变量名的引用个数为0时候,该变量值无法被访问到,该变量值就是垃圾
程序在运行过程中会申请大量的内存空间。对于一些无用的内存空间如果不及时清理的话会导致内存溢出,导致程序崩溃,因此内存管理是一件重要且繁杂的事情,而python解释器自带的垃圾回收机制会自动的帮我们去管理
python的gc模块主要运用了引用计数来跟踪和回收垃圾,在引用计数的基础上还可以通过 标记-清除 解决容器对象可能产生的循环引用的问题,并且通过分代回收以空间换取时间的方式来进一步提高垃圾回收的效率
引用计数增加:当变量值被多个变量名指向时就叫引用计数增加每有一个变量名指向该值 引用计数加1
变量值被关联次数的增加或减少,都会引发引用计数机制的执行(增加或减少值的引用计数),这存在明显的效率问题。
引用计数减少:当变量名为变量值的引用关系减少时引用计数减1
如: x = 8 ,del x 就是解除x与8的引用关系
标记清除
标记/清除算法的做法是当应用程序可用的内存空间被耗尽的时,就会停止整个程序,然后进行两项工作,第一项则是标记,第二项则是清除
1、标记 通俗地讲就是:标记的过程就行相当于从栈区出发一条线,“连接”到堆区,再由堆区间接“连接”到其他地址,凡是被这条自栈区起始的线连接到内存空间都属于可以访达的,会被标记为存活 具体地:标记的过程其实就是,遍历所有的GC Roots对象(栈区中的所有内容或者线程都可以作为GC Roots对象),然后将所有GC Roots的对象可以直接或间接访问到的对象标记为存活的对象,其余的均为非存活对象,应该被清除。
2、清除 清除的过程将遍历堆中所有的对象,将没有标记存活的对象全部清除掉。
通俗点就是:标记清除不是时刻都运行着的,而是当应用程序可用的内存空间被耗尽的时,就会停止整个程序,然后进行两项工作,第一项则是标记,第二项则是清除,扫描栈区,一栈区中的变量名为起始,判断该变量是否能直接引用到堆区的值,如果可以标记堆区中该直接引用的值为存活,如果该堆区中的值也间接引用着堆区中的其他值,则其他值也标记为存活,其他的就清除掉
循环引用情况下 变量循环引用的时候 存在内存泄露 此时标记清除可以避免这种情况
扫描栈区,变量名存在标记为存活
直接引用指的是从栈区出发直接引用到的内存地址,间接引用指的是从栈区出发引用到堆区后再进一步引用到的内存地址,以我们之前的两个列表l1与l2为例画出如下图像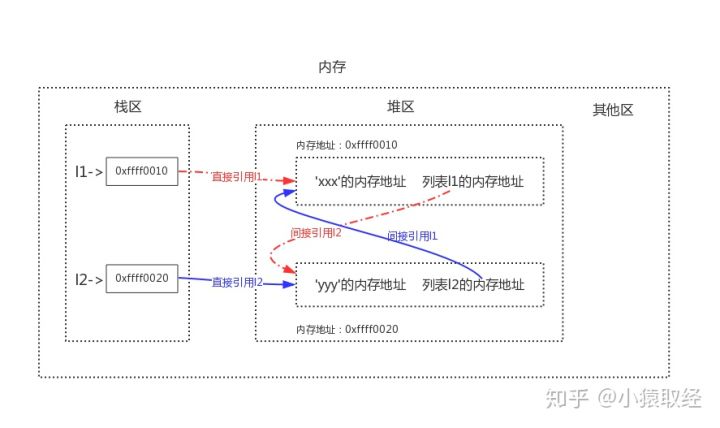
当我们同时删除l1与l2时,会清理到栈区中l1与l2的内容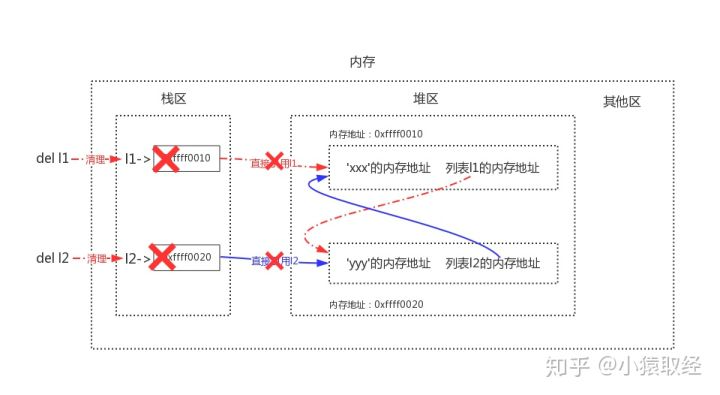
这样在启用标记清除算法时,发现栈区内不再有l1与l2(只剩下堆区内二者的相互引用),于是列表1与列表2都没有被标记为存活,二者会被清理掉,这样就解决了循环引用带来的内存泄漏问题。
l1 = [111] #111引用加一l2 = [222] #222引用加一l1.append(l2) #222引用加一l2.append(l1) #111引用加一del l1 #111引用减一del l2 #222引用减一此时已经无法取到111了 但是 111的引用计数是不为0的 造成内存泄露
分代回收
基于引用计数的回收机制,每次回收内存,都需要把所有对象的引用计数都遍历一遍,这是非常消耗时间,于是引入了分代回收机制来提高回收效率,分代回收采用的是空间换时间的策略
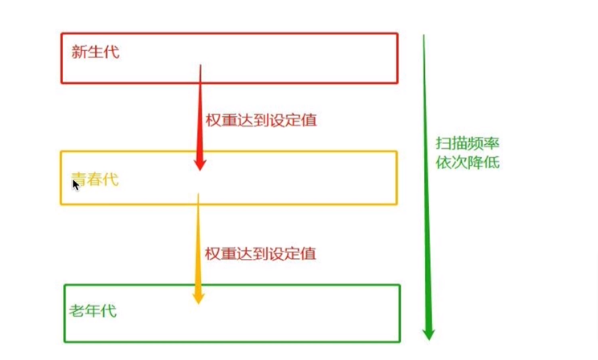
分代:分代回收的核心思想是在历经多次扫描的情况下,都没有被回收的变量,gc机制就会认为,该变量是常用变量,gc会对其扫描的频率降低
具体原理:分代指的是根据存活时间来为变量划分不同的等级
分代指的是根据存活时间来为变量划分不同等级(也就是不同的代) 新定义的变量,放到新生代这个等级中,假设每隔1分钟扫描新生代一次,如果发现变量依然被引用,那么该对象的权重(权重本质就是个整数)加一,当变量的权重大于某个设定得值(假设为3),会将它移动到更高一级的青春代,青春代的gc扫描的频率低于新生代(扫描时间间隔更长),假设5分钟扫描青春代一次,这样每次gc需要扫描的变量的总个数就变少了,节省了扫描的总时间,接下来,青春代中的对象,也会以同样的方式被移动到老年代中。也就是等级(代)越高,被垃圾回收机制扫描的频率越低
虽然分代回收可以起到提升效率的效果,但也存在一定的缺点:
例如一个变量刚刚从新生代移入青春代,该变量的绑定关系就解除了,该变量应该被回收,但青春代的扫描频率低于新生代,所以该变量的回收就会被延迟。
回收:依然是引用计数作为回收依据
8.None类型
python数据类型中有一个特殊的值None,表示为空
9.输入
输入可以实现程序和用户之间的交互
*输入的任何内容实际上都是字符串类型的
name=input('请输入你的名字:')
10.条件语句
注意缩进的问题,4个空格
if 条件:成立执行的代码else:不成立执行的代码
多条件判断if 条件1 :成立指向的代码elif 条件2:条件2成立后指向的代码else:都不成立后执行的代码
11.循环语句
1.while循环
while 条件:条件成立进入此循环,直到条件不成立的时候结束循环或者循环中遇到break 则直接退出本层循环往下执行当遇到contine时则退出本次循环,开始下一次循环#举例while True: # 死循环,因为条件一直成立print('你好')breakprint('结束')#你好结束
2.while else
当while后的条件不成立的时候,else中的代码就会执行
while 条件:代码else:代码
3for循环
理论上for循环能做的事情while循环都可以做
之所以要for循环是因为for循环在循环取值,遍历取值比while循环好用
目前只有list str tuple dict set可以被for循环
for 变量名 in 可迭代对象:代码块
range()
range(5)# [0,1,2,3,4]range(1,5) #[1,2,3,4,]range(1,10,2)#[1,3,5,7,9]range(len(list)-1)python3中是range(5) # range(0,5)迭代器
13.运算符
算数运算符
加减乘除 % ** //(返回商的整数部分)
比较运算符
大于 小于 != == >= <=
赋值运算符
= += -= *= /= %=
成员运算
字典判断的是key
in 在里面,如果在就返回True 不在返回False ,X in Y ,x是否在y里面
not in 不在里面,如果不在就返回True ,在就返回False ,X not in Y ,x不在Y里面
逻辑运算
and 与,都为真时则为真,有一个假则为假
or 或,有一个为真则为真
not 非,not(true)就是False
运算符的优先级
算数>比较>逻辑>not>and>or
有括号的时候括号优先级最大
注释
注释的内容,解释器会忽略不会执行
# 单行注释”“”多行注释多行注释“”“
链式赋值
x = y = z = 10
交叉赋值
m = 10n = 20temp = mm = nn = tempmj,n = n,m
解压赋值
可以解压列表字典,解压字典的时候默认是解压的key
s = [1,2,3,4,5]# 将5个元素赋值给不同的变量名# 变量名的个数必须和元素的个数相同s0,s1,s2,s3,s4=s#超出3个的会被*接收赋值给_x,y,z,*_ = s # 1 2 3*_,x,y,z =s # 3 4 5x,*_,y,z = s # 1 4 5
可变类型和不可变类型
可变类型:值改变,id不改变,证明改的是原值,证明原值是可以被改变的
list dict set
不可变类型,值改变,id也变了,证明是产生的新值,没有改变原值,证明原值不可以被改变,被设计为一个整体
int str float bool tuple
深浅拷贝
深拷贝
- 拷贝一下原列表产生一个新的列表
- 让两个列表完全独立开
浅拷贝
list1 = ['ok','lrt',[1,2]]list2 = list1# 两者分隔不开list做修改list2也跟着修改,因为指向关系
import copylist3 = copy.deepcopy(list1)#对于不可变类型内存地址是不改变的,可变类型的内存地址改变# list3和list1里的不可变类型的id值是一样的,但是可变类型的id是不一样的,这样在修改任意列表里的可变类型的数据时候不会影响另一个列表# 总结就是对于不可变类型拷贝一份id不改变,可变类型拷贝一份但是id会改变,
list2 = list1.copy()# 此时list2 和 list1 的id是不一样的,但是list2列表里的元素的id和list1列表里的元素的id是一样的# 对于浅拷贝如果里面存放的都是不可变类型修改任意一个列表是不会影响另一个列表的,因为不可变类型是重现产生一个新的值,进行id的引用,如果存放可变类型,修改任意一个列表是会影响另一个列表的因为两个列表里的元素id是一样的
队列和堆栈
都是数据结构
队列是先进先出
堆栈是后进先出
字符编码
1.什么是字符编码
计算机中说有的数据本质上都是0和1的组合来存储计算机中有多种编码:使用不同的编码保存文件硬盘中存储的01也是不同的utf-8 :python默认的读写编码gbk以某种编码的形式保存文件以后就要以着用形式的编码去打开否则就会出现乱码设置python解释编码:-- coding:utf-8 --
- ASCII
- 只支持英文字符串
- 采用8位二进制数对应一个英文字符串
- 8bit = 1Bytes = 1字节 = 1字符
- GBK
- 支持英文,中文字符
- 采用8位二进制对应一个英文字符
- 采用16位二进制对应一个中文字符
- unicode
- 万国码
- 采用16位二进制对应一个中文字符串(8bit = 1Bytes)
- 个别生僻字采用4Bytes , 8Bytes
- 与其他字符编码都有对应关系
- UTF-8
- 英文1Bytes 汉字 3Bytes
- 用uncode存储英文的时候会io慢,因为英文8bit就看可以表示,unicode用了16bit
2.过程
- 写文件 指定的是保存到硬盘用的编码
- 读文件 指定读文件用的编码
- 解释器解释文件 ,内存中的编码固定都是unicode
- 保证写文件和读文件用一样的编码,
3.python2和python3区别
- python2用的是ascll码解释文件
- python3是用的utf8 解释文件
4.解决python2乱码问题
- 文件头指定读文件的编码 # coding:utf-8
- 字符串前加u, x = u”weyt” 表示用unicode存
5.编码转换
借助 unicode 进行转换
HASH
hash 一般叫做散列 杂凑 或这是哈希,是把任意长度的输入通过散列算法变换成固定长度的输出,该输出就是散列值,这种转换是一种压缩映射,也就是散列值的空间通常小于输出的空间
hash算法是一个复杂的运算,他的输入可以是字符串,数据,任何文件,经过哈希运算后变成一个固定的长度输出,该输出就是哈希值,哈希算法有一个特点就是不能从结果推算出输入,又叫 不可逆运算
hash()
默认会在末尾加换行符不换行的方式:print("你好",end="")

若有收获,就点个赞吧
0 人点赞
