Memory 是虚拟的
所以… 关于内存。事实证明,当 CPU 从内存地址读取或写入时,它实际上并不是指 物理 内存(RAM)中的位置。相反,它指向的是 虚拟 内存空间中的位置。
CPU 与一个称为 内存管理单元 (MMU) 的芯片通信。MMU 就像一个翻译器,使用一本字典将虚拟内存的位置转换为物理内存的位置。当 CPU 收到指令读取内存地址 0xfffaf54834067fe2 时,它会要求 MMU 翻译该地址。MMU 在字典中查找,发现匹配的物理地址是 0x53a4b64a90179fe2,然后将该地址返回给 CPU。然后,CPU 可以从 RAM 中的该地址读取数据。
当计算机首次启动时,内存访问直接指向物理 RAM。启动后,操作系统立即创建翻译字典,并告诉 CPU 开始使用 MMU。
这本字典实际上称为 页表,这种翻译每次内存访问的系统称为 分页。页表中的条目称为 页,每一页表示一块虚拟内存如何映射到 RAM。这些块始终是固定大小的,每种处理器架构都有不同的页大小。x86-64 的默认页大小是 4 KiB,这意味着每页指定一个 4,096 字节长的内存块的映射。
换句话说,对于 4 KiB 的页面,地址的最低 12 位在 MMU 翻译前后总是相同的——12 位,因为这是在翻译后索引 4,096 字节页面所需的位数。
x86-64 还允许操作系统启用更大的 2 MiB 或 4 GiB 页,这可以提高地址翻译速度,但会增加内存碎片和浪费。页大小越大,由 MMU 翻译的地址部分就越小。

页面表本身只存储在 RAM 中。虽然它可以包含数百万个条目,但每个条目的大小仅为几个字节,因此页面表占用的空间不多。
在启动时启用分页,内核首先在RAM中构建页面表。然后,它将页面表起始处的物理地址存储在一个称为页面表基址寄存器(PTBR)的寄存器中。最后,内核通过MMU启用分页来转换所有内存访问。在x86-64架构中,控制寄存器3(CR3)的前20位用作PTBR。控制寄存器0(CR0)的第31位,即分页位(PG),被设置为1以启用分页。
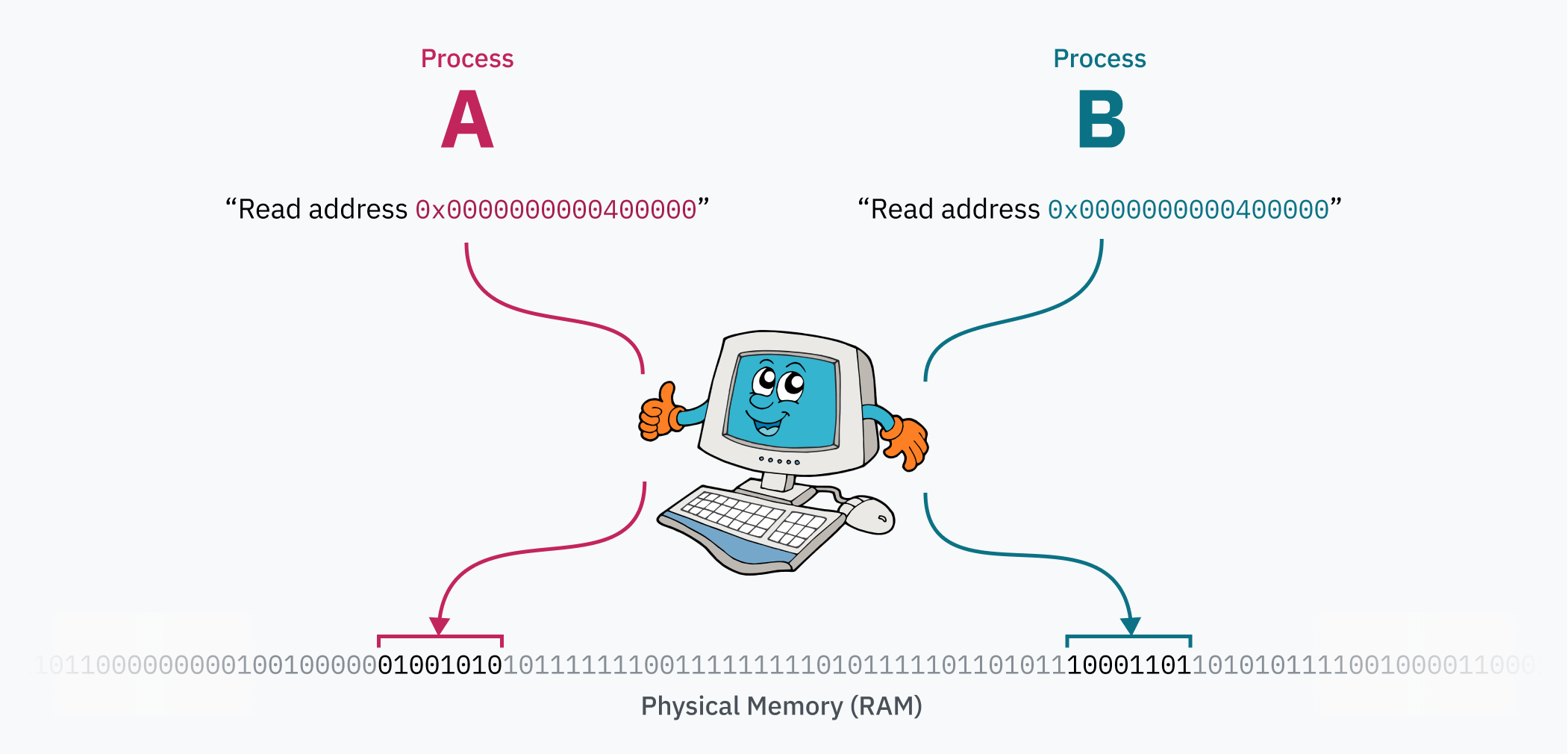
分页系统的魔力在于,可以在计算机运行时编辑页面表。这就是每个进程如何拥有自己隔离的内存空间的原因 — 当操作系统从一个进程切换到另一个进程时,重要的任务是重新映射虚拟内存空间到物理内存的不同区域。假设你有两个进程:进程A的代码和数据(可能从一个ELF文件加载!)位于0x0000000000400000,而进程B可以从完全相同的地址访问其代码和数据。这两个进程甚至可以是同一个程序的实例,因为它们实际上并不争夺该地址范围!当切换到进程时,内核将进程A的数据映射到物理内存中远离进程B的某处,并映射到0x0000000000400000。
旁注:关于 ELF 的事实
在某些情况下,
binfmt_elf必须将内存的第一页映射为零。一些为 UNIX System V Release 4.0(SVr4)编写的程序(这是一种来自 1988 年并首次支持 ELF 的操作系统)依赖于空指针可读的行为。令人惊讶的是,一些程序仍然依赖于这种行为。看起来,实现这一功能的Linux内核开发人员有些不满,他们在代码中写道:
_“你为什么这么做?好吧,SVr4 将页 0 映射为只读,并且某些应用程序‘依赖’于这种行为。由于我们无法重新编译这些程序,我们模拟了 SVr4 的行为。
使用分页的安全性
内存分页提供的进程隔离不仅改善了代码的人机工程学(进程在使用内存时无需关注其他进程),还提升了安全性:进程无法访问其他进程的内存。这在某种程度上回答了本文开头的一个问题:
如果程序直接在 CPU 上运行,而 CPU 可以直接访问 RAM,为什么代码不能访问其他进程的内存,或者更糟的是,内核的内存?
还记得吗?感觉好像很久以前的事情了……
那么内核内存呢?首先要明确的是:内核显然需要存储大量自身的数据,以跟踪所有运行的进程,甚至页面表本身。每当硬件中断、软件中断或系统调用被触发,并且CPU进入内核模式时,内核代码需要以某种方式访问那些内存。
Linux 的解决方案是将虚拟内存空间的顶半部分分配给内核,因此 Linux 被称为“高半部内核”(higher half kernel)。Windows采用了类似的技术,而 macOS 则稍微更为复杂,

对于安全性来说,如果用户态进程能读取或写入内核内存,后果将十分严重,因此分页提供了第二层安全性:每个页面必须指定权限标志。其中一种标志确定区域是否可写或仅可读。另一种标志告知CPU只有内核模式可以访问该区域的内存。这后一种标志用于保护整个高半部内核空间 —— 实际上,内核内存空间完全出现在用户空间程序的虚拟内存映射中,只是它们没有权限访问它。

页面表本身实际上包含在内核内存空间中!当定时器芯片为进程切换触发硬件中断时,CPU将特权级别切换到内核模式并跳转到Linux内核代码。处于内核模式(Intel环级0)允许CPU访问受内核保护的内存区域。然后内核可以写入页面表(位于内存上半部的某处),以重新映射虚拟内存的下半部给新的进程使用。当内核切换到新进程并且CPU进入用户模式时,它将无法再访问任何内核内存。
几乎所有的内存访问都通过 MMU 进行。中断描述符表处理程序指针?它们也地址内核的虚拟内存空间。
分层分页和其他优化
64位系统的内存地址长度为64位,这意味着64位虚拟内存空间大小达到了惊人的16 exbibytes。这是非常大的,远超过任何现有或即将出现的计算机。据我所知,有史以来RAM最多的计算机是Blue Waters超级计算机,拥有超过1.5PB的RAM。但这仍然不到16 EiB的0.01%。
如果每个4KiB虚拟内存空间需要一个页面表条目,那么你需要4,503,599,627,370,496个页面表条目。使用8字节长的页面表条目,你将需要32 pebibytes的RAM仅用于存储页面表。你可能会注意到,这仍然大于有史以来计算机RAM的最大记录。
旁注:为什么使用奇怪的单位?
我知道这些单位不常见且看起来很丑陋,但我认为清楚地区分二进制字节大小单位(2的幂)和度量单位(10的幂)是很重要的。千字节(kB)是国际单位制(SI)的单位,表示1,000字节。而Kibibyte(KiB)是国际电工委员会推荐的单位,表示1,024字节。在CPU和内存地址方面,字节计数通常是2的幂,因为计算机是二进制系统。使用KB(或更糟的是kB)表示1,024将会更加模糊。
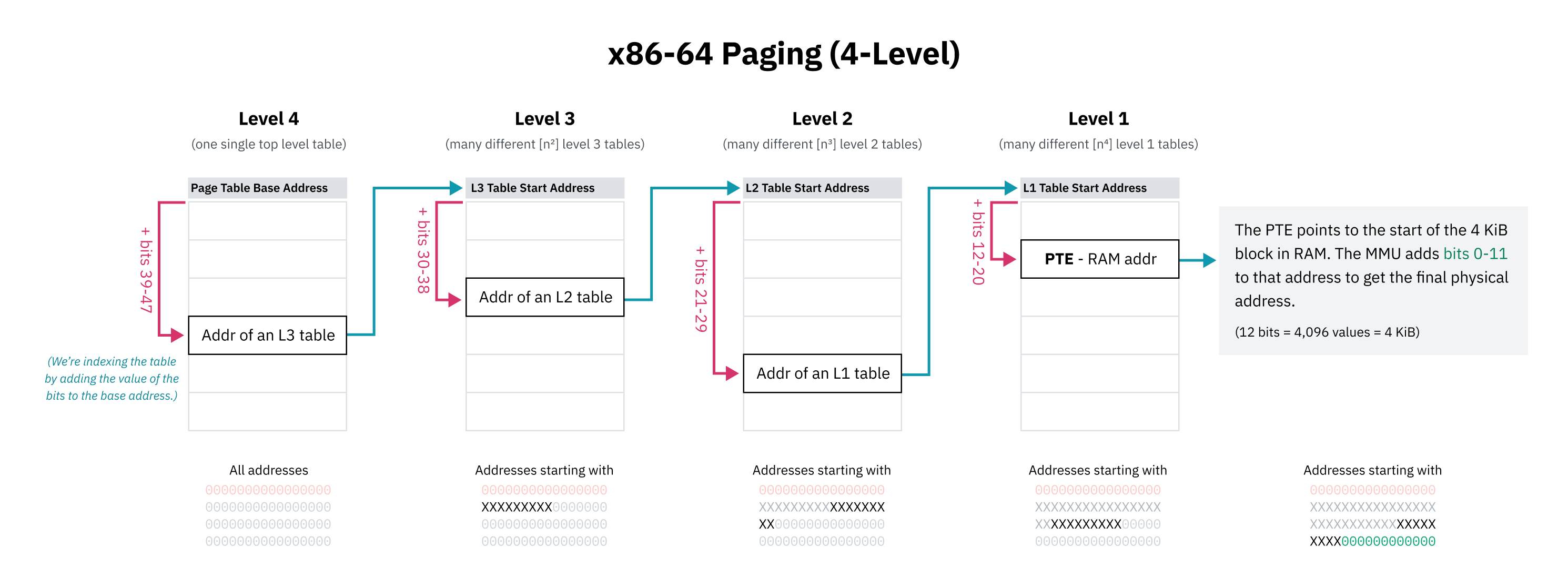
由于在整个可能的虚拟内存空间上都顺序使用页面表条目将是不可能的(或至少极其不实际),CPU架构实现了分层分页。在分层分页系统中,有多级逐渐增细的页面表。顶层条目覆盖大块内存并指向更小块的页面表,形成树结构。对于4KiB或其他页面大小的个别条目则是树的叶子。
x86-64历史上使用4级分层分页。在这个系统中,通过地址的一部分偏移来找到每个页面表条目,这部分从最高有效位开始,作为前缀,使条目覆盖以这些位开头的所有地址。该条目指向下一级表的开始,其中包含该内存块的子树,这些子树再次使用下一组位进行索引。
x86-64的4级分页设计者还选择忽略虚拟指针的顶部16位,以节省页面表空间。48位可以让你获得128 TiB的虚拟地址空间,这被认为是足够大的。(完整的64位将使你得到16 EiB,这实在是很多。)
由于前 16 位被跳过,用于索引页面表第一级的“最高有效位”实际上从第 47 位开始而不是 63 位。这也意味着本章前面的高半部内核图解在技术上是不准确的;内核空间的起始地址应该被描绘为比 64 位地址空间小的中点。
分层分页解决了空间问题,因为在树的任何级别上,指向下一个条目的指针可以是空的(0x0)。这允许页面表的整个子树被省略,意味着虚拟内存空间中未映射的区域在RAM中不占用任何空间。对未映射内存地址的查找可以快速失败,因为CPU一旦在树的更高层看到空条目就可以报错。页面表条目还有一个存在标志,可以将它们标记为不可用,即使地址看起来是有效的也可以这样做。
分层分页的另一个好处是能够高效地切换虚拟内存空间的大片段。一个大块虚拟内存可能被映射到一个物理内存区域供一个进程使用,而映射到另一个进程时可能映射到不同的区域。内核可以将这两个映射都存储在内存中,并在切换进程时仅更新树的顶层指针。如果整个内存空间映射被存储为一个扁平的条目数组,内核将不得不更新大量条目,这将会很慢,并且仍然需要独立跟踪每个进程的内存映射。
我说 x86-64 “历史上”使用4级分页,因为最近的处理器实现了5级分页。5 级分页增加了另一级间接性,并且添加了9位地址位,将地址空间扩展到了128 PiB,使用了 57 位地址。操作系统,包括Linux 自2017年起,以及最近的Windows 10 和 11 服务器版本,都支持 5 级分页。
旁注:物理地址空间限制
就像操作系统不使用全部 64 位虚拟地址一样,处理器也不使用完整的64位物理地址。在4级分页成为标准时,x86-64 CPU 并未使用超过46位,这意味着物理地址空间仅限于 64 TiB。通过 5 级分页,支持已扩展到52位,支持4 PiB的物理地址空间。
在操作系统层面,虚拟地址空间比物理地址空间更大是有优势的。正如 Linus Torvalds 所说的:“[它]需要更大,至少是两倍,这是相当推动的,你最好有十倍以上的因子。任何不明白这一点的人都是白痴。讨论结束。”
交换和需求分页
内存访问可能失败的原因有几种:地址可能超出范围,可能没有被页面表映射,或者可能有一个标记为不存在的条目。在任何这些情况下,MMU 将触发一个称为页错误的硬件中断,让内核处理这个问题。
在某些情况下,读取确实无效或被禁止。在这些情况下,内核可能会因为段错误而终止程序。
Shell会话
$ ./programSegmentation fault (core dumped)$
旁注:段错误的本质
“段错误”在不同的上下文中有不同的含义。当内存未经许可读取时,MMU 触发硬件中断称为“段错误”,但“段错误”也是操作系统可以发送给运行中程序的信号,以终止它们因为任何非法内存访问而出现的情况。
在其他情况下,内存访问可以有意失败,允许操作系统在内存中填充数据,然后将控制权交回 CPU 进行重试。例如,操作系统可以将磁盘上的文件映射到虚拟内存,而不实际将其加载到 RAM 中,然后在请求地址并发生页面错误时将其加载到物理内存中。这就是所谓的需求分页。

首先,这使得像 mmap这样的系统调用能够存在,它可以将整个文件从磁盘惰性映射到虚拟内存中。如果你熟悉LLaMa.cpp,这是一个泄露的 Facebook 语言模型的运行时,Justine Tunney 最近通过使所有加载逻辑使用mmap来显著优化了它。(如果你之前没有听说过她,去看看她的作品吧!Cosmopolitan Libc 和 APE 非常酷,如果你喜欢这篇文章,可能会感兴趣。)
_显然,关于 Justine 在这一变更中的参与有很多争议。我只是指出这一点,以免被随机的互联网用户吵架。我必须承认,我并没有读过大部分的争议内容,但我之前说的 Justine 的东西很酷仍然是非常正确的。
当你执行一个程序及其库时,内核实际上并没有加载任何内容到内存中。它只是创建了文件的mmap — 当CPU尝试执行代码时,页面会立即发生错误,内核会用一个真实的内存块替换这个页面。
需求分页还使得你可能在“换页”或“分页”技术中看到的技术成为可能。操作系统可以通过将内存页面写入磁盘并从物理内存中删除来释放物理内存,但保留它们在虚拟内存中,并将存在标志设置为0。如果读取该虚拟内存,操作系统可以从磁盘恢复内存到RAM,并将存在标志重新设置为1。操作系统可能需要交换RAM的其他部分以腾出空间,用于从磁盘加载的内存。由于磁盘读写速度较慢,操作系统会尽量减少交换操作,采用高效的页面置换算法。
一个有趣的技巧是使用页表的物理内存指针来存储物理存储中文件的位置。由于MMU在看到负的存在标志时会立即引发页错误,这些无效的内存地址并不重要。这种方法并非在所有情况下都实用,但思考起来确实颇有趣味性。

若有收获,就点个赞吧
0 人点赞
