到目前为止,我们已经讨论了 CPU 如何执行从可执行文件加载的机器代码、基于环的安全性是什么以及系统调用如何工作。在本节中,我们将深入探讨 Linux 内核,了解程序最初是如何加载和运行的。
我们将特别关注 x86-64 架构上的 Linux。为什么?
- Linux 是一个功能齐全的生产操作系统,适用于桌面、移动和服务器场景。Linux 是开源的,因此只需阅读其源代码就可以轻松研究。在本文中,我将直接引用一些内核代码!
- x86-64 是大多数现代台式计算机使用的架构,也是大量代码的目标架构。我提到的x86-64特定行为的子集将很好地推广到其他架构。
我们学习的大部分内容将很好地推广到其他操作系统和架构,即使它们在某些具体方式上有所不同。
Exec 系统调用的基本行为
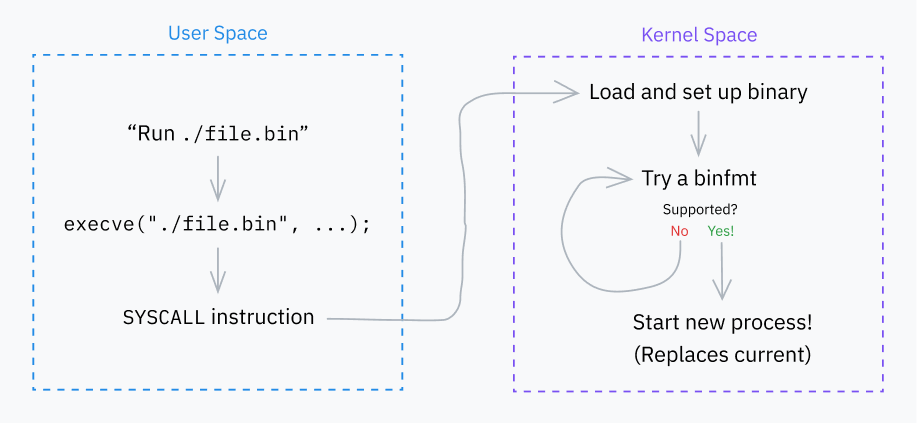
让我们从一个非常重要的系统调用开始:execve。它加载一个程序,如果成功,则用该程序替换当前进程。还有一些其他系统调用(execlp、execvpe等)存在,但它们都以各种方式层叠在execve之上。
旁注:
execveat
execve实际上是建立在execveat之上的,一个更通用的系统调用,它运行一个带有一些配置选项的程序。为了简单起见,我们主要讨论execve;它唯一的区别在于,它为execveat提供了一些默认值。好奇
ve代表什么吗?v表示参数之一是参数向量(列表)(argv),而e表示另一个参数是环境变量向量(envp)。其他各种exec系统调用有不同的后缀来指定不同的调用签名。execveat中的at只是 “at”,因为它指定了运行execve的位置。
execve的调用签名是:
int execve(const char *filename, char *const argv[], char *const envp[]);
filename参数指定要运行的程序的路径。argv是一个以空指针结尾的参数列表。你通常会看到传递给C主函数的argc参数实际上是由系统调用稍后计算的,因此需要以空指针结尾。envp参数包含另一个以空指针结尾的环境变量列表,用作应用程序的上下文。它们通常是KEY=VALUE对。通常。我爱计算机。
有趣的事实!你知道程序的第一个参数是程序名称的惯例吗?这只是一个惯例,并不是由execve系统调用本身设置的!第一个参数将是传递给execve的argv参数中的第一个项,即使它与程序名称无关。
有趣的是,execve确实有一些代码假定argv[0]是程序名称。稍后我们在讨论解释型脚本语言时会详细说明这一点。
第0步:定义
我们已经知道系统调用是如何工作的,但我们还没有见过一个真实的代码示例!让我们看看Linux内核的源代码,看看execve在底层是如何定义的:
SYSCALL_DEFINE3(execve,const char __user *, filename,const char __user *const __user *, argv,const char __user *const __user *, envp){return do_execve(getname(filename), argv, envp);}
这是Linux内核中execve系统调用的定义。SYSCALL_DEFINE3是一个宏,它帮助定义一个带有三个参数的系统调用。在这种情况下,三个参数是:
filename:程序的路径argv:参数列表envp:环境变量列表
这个定义表明,execve系统调用最终调用了do_execve函数,将filename参数转换为内部表示形式,并将argv和envp参数传递给它。
do_execve 函数是实现实际执行过程的地方。接下来,让我们深入研究do_execve 函数,了解更多细节。
SYSCALL_DEFINE3(execve,const char __user *, filename,const char __user *const __user *, argv,const char __user *const __user *, envp){return do_execve(getname(filename), argv, envp);}
SYSCALL_DEFINE3是一个宏,用于定义一个带有三个参数的系统调用的代码。
关于为什么在宏名称中硬编码了参数数量(即“arity”),我查了一下并学到,这是为了修复某些安全漏洞的一种解决方法。
filename参数被传递给一个名为getname()的函数,该函数将字符串从用户空间复制到内核空间,并进行一些使用跟踪操作。它返回一个filename结构体,该结构体在include/linux/fs.h中定义。它保存了指向用户空间原始字符串的指针,以及指向内核空间复制值的新指针:
struct filename {const char *name; /* pointer to actual string */const __user char *uptr; /* original userland pointer */int refcnt;struct audit_names *aname;const char iname[];};
execve系统调用接着调用do_execve()函数。这个函数进而调用do_execveat_common(),带有一些默认选项。前面提到的execveat系统调用也调用do_execveat_common(),但会传递更多用户提供的选项。
在下面的片段中,我包含了do_execve和do_execveat的定义:
static int do_execve(struct filename *filename,const char __user *const __user *__argv,const char __user *const __user *__envp){struct user_arg_ptr argv = { .ptr.native = __argv };struct user_arg_ptr envp = { .ptr.native = __envp };return do_execveat_common(AT_FDCWD, filename, argv, envp, 0);}static int do_execveat(int fd, struct filename *filename,const char __user *const __user *__argv,const char __user *const __user *__envp,int flags){struct user_arg_ptr argv = { .ptr.native = __argv };struct user_arg_ptr envp = { .ptr.native = __envp };return do_execveat_common(fd, filename, argv, envp, flags);}
在execveat中,会将一个文件描述符(一种指向某些资源的标识)传递给系统调用,然后传递给do_execveat_common。这指定了执行程序的相对目录。
在execve中,文件描述符参数使用了一个特殊值AT_FDCWD。这是Linux内核中的一个共享常量,告诉函数将路径名解释为相对于当前工作目录的路径。通常会在接受文件描述符的函数中进行类似于 if (fd == AT_FDCWD) { /* special codepath */ } 的手动检查。
步骤 1:设置
我们现在来到了do_execveat_common,这是处理程序执行的核心函数。为了更全面地理解这个函数的作用,我们稍微远离代码来看看整体情况。
do_execveat_common的第一个主要任务是设置一个叫做linux_binprm的结构体。我不会包含整个结构体的定义,但有几个重要的字段需要讨论:
- 定义了像
mm_struct和vm_area_struct这样的数据结构,为新程序准备虚拟内存管理。 - 计算并存储
argc和envc,以便传递给程序。 filename和interp分别存储程序的文件名和其解释器。它们最初相等,但在某些情况下会有所改变:比如在运行带有Shebang)的解释脚本时。例如,在执行Python程序时,filename指向源文件,而interp则是Python解释器的路径。buf是一个数组,填充了要执行文件的前256个字节。它用于检测文件的格式并加载脚本的Shebang。
(TIL:binprm代表binary program。)
让我们更仔细地看看这个缓冲区buf:
char buf[BINPRM_BUF_SIZE];
正如我们所看到的,它的长度被定义为常量 BINPRM_BUF_SIZE。通过在代码库中搜索这个字符串,我们可以在 include/uapi/linux/binfmts.h 中找到对它的定义:
/* sizeof(linux_binprm->buf) */#define BINPRM_BUF_SIZE 256
因此,内核将执行文件的开头256字节加载到这个内存缓冲区中。
旁注:什么是UAPI?
你可能注意到上面代码路径中包含
/uapi/。为什么长度没有在与linux_binprm结构体相同的文件include/linux/binfmts.h中定义呢?UAPI代表“用户空间API”。在这种情况下,它意味着有人决定缓冲区的长度应该作为内核的公共API的一部分。理论上,所有的UAPI都暴露给用户空间,而非UAPI的部分则是内核代码的私有部分。
内核和用户空间代码最初是混在一起的一团。2012年,UAPI代码被重构到一个单独的目录中,试图提高可维护性。
步骤 2:Binfmts
内核的下一个重要任务是遍历一系列“binfmt”(二进制格式)处理程序。这些处理程序在诸如 fs/binfmt_elf.c 和 fs/binfmt_flat.c 等文件中定义。内核模块也可以向池中添加自己的binfmt处理程序。
每个处理程序暴露一个名为 load_binary() 的函数,该函数接受一个 linux_binprm 结构体,并检查处理程序是否理解程序的格式。
这通常涉及在缓冲区中查找魔数),尝试解码程序的开头(同样来自缓冲区),和/或检查文件扩展名。如果处理程序支持该格式,则准备程序以执行并返回成功代码。否则,它会提前退出并返回错误代码。
内核会尝试每个binfmt的 load_binary() 函数,直到找到一个成功的。有时这些函数会递归运行;例如,如果脚本指定了一个解释器,并且该解释器本身也是一个脚本,那么层次结构可能是 binfmt_script > binfmt_script > binfmt_elf(其中ELF是链条末端的可执行格式)。
格式高亮:脚本
在Linux支持的许多格式中,binfmt_script 是我想特别谈谈的第一个。
你是否曾经读过或写过Shebang)?那些在一些脚本开头指定解释器路径的行?
#!/bin/bash
我一直以为这些由Shell处理,但原来不是!Shebang 实际上是内核的一个特性,脚本使用与其他程序相同的系统调用来执行。计算机真是太酷了。
让我们看看 fs/binfmt_script.c 如何检查文件是否以 shebang 开头:
/* Not ours to exec if we don't start with "#!". */if ((bprm->buf[0] != '#') || (bprm->buf[1] != '!'))return -ENOEXEC;
如果文件确实以shebang开头,binfmt处理程序会读取解释器路径,以及路径后面的任何以空格分隔的参数。它在遇到换行符或缓冲区结束时停止读取。
这里有两个有趣而古怪的地方。
首先,记住linux_binprm中那个填充了文件前256字节的缓冲区吗?它用于检测可执行格式,但在binfmt_script中也用来读取shebang。
在我的研究中,我读过一篇文章描述该缓冲区长度为128字节。在那篇文章发布之后的某个时刻,长度被加倍到了256字节!好奇为什么会这样,我查看了Git blame —— 这是Linux源代码中编辑某一行代码的所有人的日志 —— 找到了定义BINPRM_BUF_SIZE 的那行代码。果然……
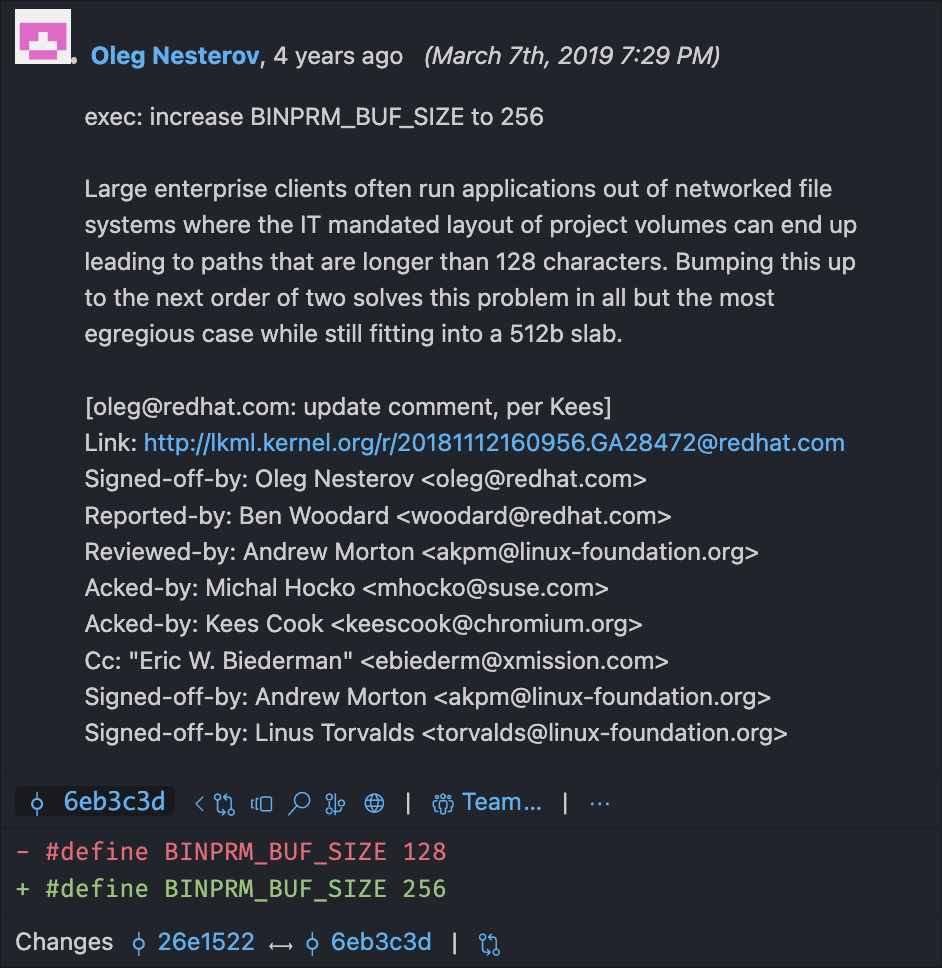
计算机真酷!
由于 shebang 由内核处理,并从 buf 中提取而不是加载整个文件,它们 总是 被截断到 buf 的长度。显然,4 年前,有人因内核截断其超过 128 个字符的路径而感到恼火,他们的解决方案是通过将缓冲区大小加倍来使截断点加倍!今天,在你自己的 Linux 机器上,如果你的 shebang 行超过 256 个字符,超过 256 个字符的部分将 完全丢失。

想象一下因为这个问题而出现了一个错误。想象一下试图找出破坏你代码的根本原因。想象一下发现问题深藏在 Linux 内核中的感觉。可怜下一个在大型企业中发现部分路径神秘消失的 IT 人员。
第二个怪事: 还记得 argv[0] 只是 惯例 是程序名吗,调用者可以将任何 argv 传递给 exec 系统调用并且它将未经审核地通过?
恰好 binfmt_script 是那些 假定 argv[0] 是程序名的地方之一。它总是移除 argv[0],然后在 argv 的开头添加以下内容:
- 解释器的路径
- 解释器的参数
- 脚本的文件名
示例:参数修改
我们来看一个示例
execve调用:
// 参数:文件名,argv,envpexecve("./script", [ "A", "B", "C" ], []);这个假设的
script文件的第一行包含以下 shebang:script
#!/usr/bin/node --experimental-module最后传递给 Node 解释器的修改后的
argv将是:
[ "/usr/bin/node", "--experimental-module", "./script", "B", "C" ]
在更新 argv 之后,处理程序通过将 linux_binprm.interp 设置为解释器路径(在本例中为 Node 二进制文件)完成了文件的执行准备。最后,它返回 0 以表示成功准备程序执行。
格式亮点:杂项解释器
另一个有趣的处理程序是 binfmt_misc。它通过在 /proc/sys/fs/binfmt_misc/ 挂载一个特殊的文件系统,打开了通过用户空间配置添加一些有限格式的能力。程序可以对该目录中的文件执行特别格式化的写操作以添加自己的处理程序。每个配置条目指定:
- 如何检测它们的文件格式。这可以指定某个偏移量处的魔术数或要查找的文件扩展名。
- 解释器可执行文件的路径。没有办法指定解释器参数,因此如果需要这些参数,需要一个包装脚本。
- 一些配置标志,包括一个指定
binfmt_misc如何更新argv的标志。
这个 binfmt_misc 系统通常由 Java 安装使用,配置为通过它们的 0xCAFEBABE 魔术字节检测类文件,并通过其扩展名检测 JAR 文件。在我的特定系统上,配置了一个处理程序,通过 .pyc 扩展名检测 Python 字节码并将其传递给适当的处理程序。
这是一个非常酷的方法,允许程序安装程序添加对其自身格式的支持,而无需编写高度特权的内核代码。
最后
exec 系统调用总是会有两个路径之一:
- 它最终会到达一个可执行的二进制格式,可能经过几层脚本解释器,然后运行该代码。在这一点上,旧代码已经被替换。
- ……或者它将耗尽所有选项并返回一个错误代码给调用程序,夹着尾巴。
如果你曾经使用过类 Unix 系统,你可能已经注意到,从终端运行的 shell 脚本即使没有 shebang 行或 .sh 扩展名仍然可以执行。如果你有一个非 Windows 终端,可以立即测试一下:
$ echo "echo hello" > ./file$ chmod +x ./file$ ./filehello
(chmod +x 告诉操作系统一个文件是可执行的。否则你将无法运行它。)
那么,为什么 shell 脚本会作为 shell 脚本运行呢?内核的格式处理程序应该没有明显的方式检测没有任何可识别标签的 shell 脚本!
事实证明,这种行为不是内核的一部分。实际上,这是你的 shell 处理故障情况的一种常见方式。
当你使用 shell 执行一个文件并且 exec 系统调用失败时,大多数 shell 将会 重试将文件作为 shell 脚本执行,方法是以文件名作为第一个参数执行一个 shell。Bash 通常会使用自身作为解释器,而 ZSH 则使用任何 sh,通常是 Bourne shell。
这种行为非常常见,因为它在 POSIX 中有所规定,这是一个旨在使代码在 Unix 系统之间可移植的旧标准。虽然大多数工具或操作系统并不严格遵循 POSIX,但它的许多惯例仍然被共享。
如果 [一个 exec 系统调用] 因等同于
[ENOEXEC]错误的错误而失败,shell 应执行等同于以命令名作为其第一个操作数调用 shell 的命令,其余任何参数传递给新 shell。如果可执行文件不是文本文件,shell 可能会绕过此命令执行。在这种情况下,它应写一个错误消息并返回 126 的退出状态。
计算机真酷!

若有收获,就点个赞吧
0 人点赞
