最后一个问题是:我们是如何到达这里的?第一个进程从何而来?
这篇文章快完成了。我们几乎要到达终点了。即将取得一次大成功。继续前进到更美好的地方。以及其他一些用来表示你距离接触草地还有一个“长度为第6章”的单元的可怕习语,或者在你不是在阅读关于CPU架构的1.5万字文章时,你在做什么。
如果execve通过替换当前进程来启动一个新程序,那么如何单独启动一个新程序,在一个新进程中?如果你想在计算机上做多件事情,这是一个非常重要的能力;当你双击一个应用程序来启动它时,该应用程序会在单独的进程中打开,而你之前的程序会继续运行。
答案是另一个系统调用:fork,这是所有多进程操作的基础系统调用。fork其实很简单 — 它克隆当前进程及其内存,保留保存的指令指针不变,然后允许这两个进程像往常一样继续运行。在没有干预的情况下,程序将独立运行,并且所有计算都会加倍。
新运行的进程被称为“子进程”,调用fork的原始进程称为“父进程”。进程可以多次调用fork,从而拥有多个子进程。每个子进程都有一个进程ID(PID),从1开始编号。
毫无头绪地复制相同的代码是相当无用的,所以fork在父进程与子进程上返回不同的值。在父进程中,它返回新子进程的PID,而在子进程中返回0。这使得在新进程上执行不同的工作成为可能,因此fork实际上是有帮助的。
main.c
pid_t pid = fork();// 代码从这点继续执行,就像通常一样,但现在跨两个“相同”的进程。//// 相同……除了从fork返回的PID!//// 这是告诉任何一个程序它们不是同一种类的唯一指标。if (pid == 0) {// 我们在子进程中。// 进行一些计算,并将结果传递给父进程!} else {// 我们在父进程中。// 可能继续之前要做的事情。}
进程分叉可能有点难以理解。从现在开始,我将假设你已经弄清楚了;如果没有,可以查看这个看起来很丑的网站,那里有一个很好的解释。
无论如何,Unix程序通过调用fork启动新程序,然后立即在子进程中运行execve。这称为“分叉-执行模式”。当你运行一个程序时,你的计算机执行类似以下代码的操作:
launcher.c
pid_t pid = fork();if (pid == 0) {// 立即用新程序替换子进程。execve(...);}// 由于我们到了这里,进程没有被替换。我们在父进程中!// 有用的是,我们现在还有新子进程的PID在PID变量中,如果我们需要终止它。// 父进程在这里继续……
哞!
你可能注意到,将一个进程的内存复制一份,只是为了在加载不同的程序时立即丢弃所有这些内容,听起来有点低效。幸运的是,我们有MMU(内存管理单元)。在物理内存中复制数据是慢的部分,而不是复制页表,因此我们根本不复制任何RAM:我们为新进程创建了旧进程的页表副本,并保持映射指向相同的物理内存。
但是,子进程应该是独立且与父进程隔离的!子进程不能随意写入父进程的内存,反之亦然!
引入写时复制(COW)页。使用COW页,只要它们不尝试写入内存,两个进程就会从相同的物理地址读取数据。一旦其中一个进程尝试写入内存,该页面就会在RAM中复制。COW页允许两个进程在不克隆整个内存空间的前提下实现内存隔离。这就是为什么分叉-执行模式是高效的原因;因为在加载新二进制文件之前,不会复制任何旧进程的内存,所以不需要复制内存。
像许多有趣的东西一样,COW是通过分页技巧和硬件中断处理来实现的。在fork克隆父进程后,它将两个进程的所有页面标记为只读。当程序尝试写入内存时,写入会失败,因为内存是只读的。这会触发一个段错误(硬件中断类型),由内核处理。内核复制内存,更新页面以允许写入,并从中断返回以重新尝试写入。
_A: 叮叮当!
B: 谁在敲门?
A: 打断你的牛。
B: 打断你的牛什么 —
A: 哞!
最初的开始(非创世记1:1)
你计算机上的每个进程都是由一个父程序通过分叉-执行启动的,除了一个:init进程。init进程是由内核手动设置的。它是第一个运行的用户态程序,也是关闭时最后被杀死的程序。
想看一个酷炫的即时黑屏吗?如果你在macOS或Linux上,保存你的工作,打开一个终端,然后杀死init进程(PID 1):
Shell session
$ sudo kill 1
作者注:关于 init 进程的知识,遗憾的是,仅适用于像 macOS 和 Linux这 样的类 Unix 系统。从现在开始,大部分你学到的东西都不适用于理解 Windows,因为它有非常不同的内核架构。
就像关于
execve的部分一样,我明确地在这里说明了这一点 — 我可以写一整篇关于NT内核的文章,但我现在还在克制自己。(暂时)
init 进程负责启动组成操作系统的所有程序和服务。其中许多又会产生它们自己的服务和程序。
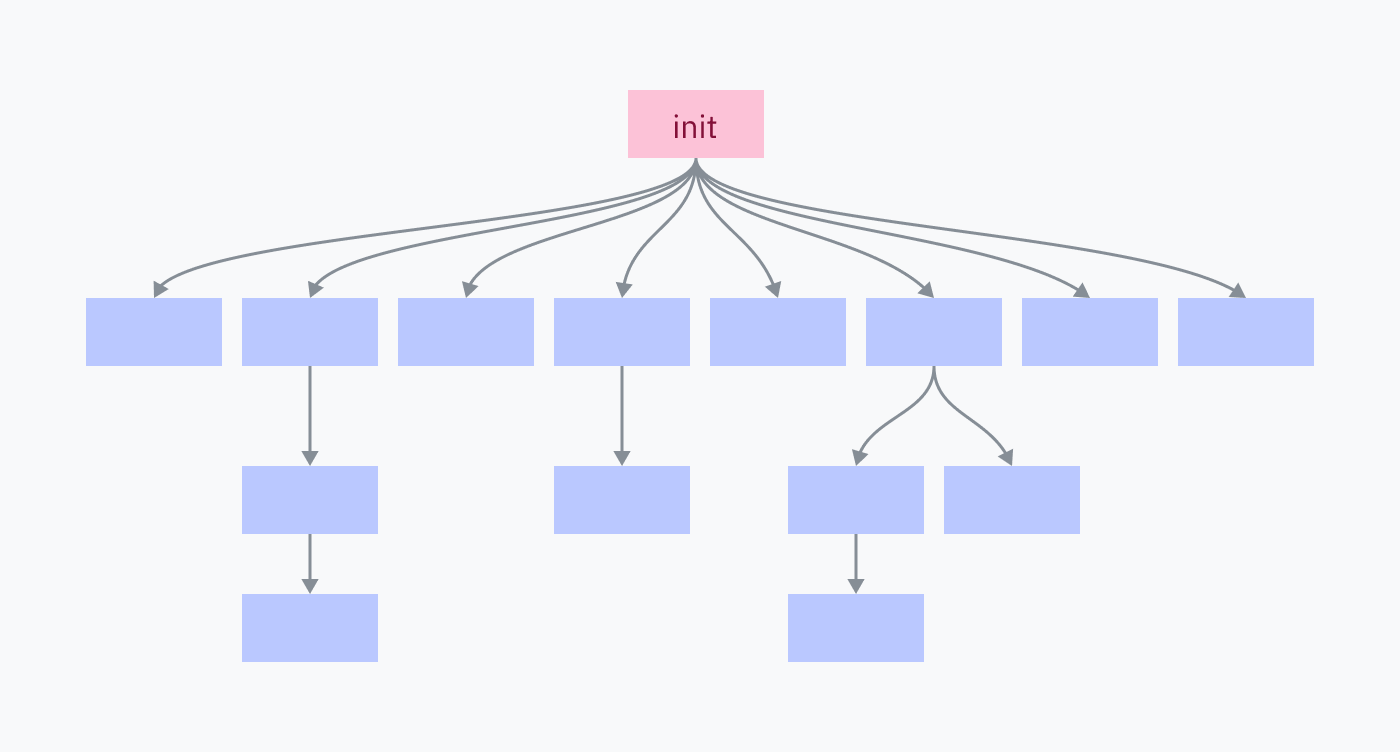
杀死init进程会关闭所有它的子进程以及它们的所有子进程,从而关闭你的操作系统环境。
回到内核
我们之前在第3章里看Linux内核代码时玩得很开心,所以我们要再来一些!这次我们将看一看内核如何启动init进程。
你的计算机启动过程如下:
主板上捆绑有一个小型软件,它搜索连接的磁盘,寻找一个称为引导加载程序的程序。它选择一个引导加载程序,将其机器码加载到RAM中,并执行它。
请记住,我们还没有进入运行中的操作系统的世界。直到操作系统内核启动init进程之前,多进程和系统调用并不存在。在预init上下文中,“执行”一个程序意味着直接跳转到其在RAM中的机器码,而不期望返回。
引导加载程序负责查找内核,将其加载到RAM中,并执行它。一些引导加载程序,如GRUB,是可配置的,或者允许你在多个操作系统之间选择。BootX和Windows Boot Manager分别是macOS和Windows的内置引导加载程序。
现在内核正在运行,并开始执行大量的初始化任务,包括设置中断处理程序、加载驱动程序和创建初始内存映射。最后,内核将特权级别切换到用户模式,并启动init程序。
最终我们进入了操作系统中的用户空间!init程序开始运行初始化脚本,启动服务,并执行如shell/UI等程序。
Linux初始化过程
在Linux上,步骤3的大部分工作(内核初始化)发生在init/main.c中的start_kernel函数中。这个函数超过200行,调用了各种其他初始化函数,所以我不会在这篇文章中包含整个函数,但我建议你浏览一下!在start_kernel函数的结尾调用了一个名为arch_call_rest_init的函数:
10871088
/* Do the rest non-__init'ed, we're now alive */arch_call_rest_init();
非__init’ed意味着什么?
start_kernel函数被定义为asmlinkage __visible void __init __no_sanitize_address start_kernel(void)。像__visible、__init和__no_sanitize_address这样奇怪的关键字都是Linux内核中用来为函数添加不同代码或行为的C预处理宏。在这种情况下,
__init是一个宏,指示内核在启动过程完成后释放函数及其数据,以节省空间。它是如何工作的?不深入细节,Linux内核本身被打包成ELF文件。
__init宏扩展为__section(".init.text"),这是一个编译器指令,将代码放置在一个名为.init.text的节中,而不是通常的.text节。其他宏允许数据和常量被放置在特殊的init节中,如__initdata扩展为__section(".init.data")。
arch_call_rest_init实际上是一个包装函数:
832833834835
void __init __weak arch_call_rest_init(void){rest_init();}
注释中提到“do the rest non-__init’ed”,因为rest_init没有使用__init宏定义。这意味着它在清理初始化内存时不会被释放:
689690
noinline void __ref rest_init(void){
rest_init现在创建了一个线程来运行init进程:
695696697698699700
/** We need to spawn init first so that it obtains pid 1, however* the init task will end up wanting to create kthreads, which, if* we schedule it before we create kthreadd, will OOPS.*/pid = user_mode_thread(kernel_init, NULL, CLONE_FS);
传递给 user_mode_thread 的 kernel_init 参数是一个函数,它完成一些初始化任务,然后搜索一个有效的init程序来执行它。这个过程从一些基本的设置任务开始;我将大部分跳过,除了调用 free_initmem 的部分。这是内核释放我们的.init 节的地方!
1471
free_initmem();
现在内核可以找到一个适合的init程序来运行:
1495149614971498149915001501150215031504150515061507150815091510151115121513151415151516151715181519152015211522152315241525
/** We try each of these until one succeeds.** The Bourne shell can be used instead of init if we are* trying to recover a really broken machine.*/if (execute_command) {ret = run_init_process(execute_command);if (!ret)return 0;panic("Requested init %s failed (error %d).",execute_command, ret);}if (CONFIG_DEFAULT_INIT[0] != '\0') {ret = run_init_process(CONFIG_DEFAULT_INIT);if (ret)pr_err("Default init %s failed (error %d)\n",CONFIG_DEFAULT_INIT, ret);elsereturn 0;}if (!try_to_run_init_process("/sbin/init") ||!try_to_run_init_process("/etc/init") ||!try_to_run_init_process("/bin/init") ||!try_to_run_init_process("/bin/sh"))return 0;panic("No working init found. Try passing init= option to kernel. ""See Linux Documentation/admin-guide/init.rst for guidance.");
在Linux上,init程序几乎总是位于或符号链接到/sbin/init。常见的init包括systemd(它有一个异常好的网站)、[OpenRC](https://
wiki.gentoo.org/wiki/OpenRC/openrc-init)和runit。如果找不到其他程序,kernel_init 将默认使用 /bin/sh —— 如果找不到/bin/sh,那么情况将非常糟糕。
MacOS也有一个init程序!它称为launchd,位于/sbin/launchd。尝试在终端中运行它,你将会被指责为不是内核。
从这一点开始,我们就进入了启动过程的第4步:init进程在用户空间运行,并开始使用fork-exec模式启动各种程序。
Fork内存映射
我对Linux内核在fork进程时如何重新映射内存底部一半感到好奇,所以我稍微搜索了一下。kernel/fork.c似乎包含大部分fork进程的代码。该文件的开头有一条指示我应该查找的线索:
8910111213
/** 'fork.c'包含'fork'系统调用的辅助例程* (也看看entry.S和其他文件)。* 一旦你掌握了它,fork是相当简单的,但内存管理可能会让人头痛。* 查看'mm/memory.c':'copy_page_range()'。*/
看起来 copy_page_range 函数接受一些关于内存映射的信息,并复制页表。快速浏览它调用的函数,这也是页面设置为只读以使它们成为COW页的地方。它通过调用名为 is_cow_mapping 的函数来检查是否应该这样做。
is_cow_mapping在include/linux/mm.h中定义,并且如果内存映射具有指示内存是可写的标志并且不在进程之间共享时返回true。共享内存不需要COW,因为它设计为共享的。请欣赏稍微费解的位掩码:
1541154215431544
static inline bool is_cow_mapping(vm_flags_t flags){return (flags & (VM_SHARED | VM_MAYWRITE)) == VM_MAYWRITE;}
回到 kernel/fork.c,使用简单的Command-F搜索copy_page_range,可以找到它在 dup_mmap 函数中被调用…这个函数又被 dup_mm 调用…它被 copy_mm调用…最终被大量使用的 copy_process 函数调用!copy_process 是fork函数的核心,并且在某种程度上是Unix系统执行程序的中心点 —— 总是复制和编辑在启动时为第一个进程创建的模板。
总结……
那么,程序是如何运行的呢?
在最底层:处理器是愚笨的。它们有一个指针指向内存,并按顺序执行指令,除非遇到一个指令告诉它们跳转到别的地方。
除了跳转指令外,硬件和软件中断也可以通过跳转到预设位置打破执行序列,然后选择跳转到哪里。处理器核心无法同时运行多个程序,但可以通过使用定时器重复触发中断,并允许内核代码在不同的代码指针之间切换来模拟这一过程。
程序被“欺骗”以认为它们在作为一个连贯的、孤立的单元运行。在用户模式下阻止对系统资源的直接访问,使用分页隔离内存空间,并设计系统调用以允许通用I/O访问,而无需太多关于真实执行上下文的了解。系统调用是一种指令,请求CPU运行一些内核代码,其位置在启动时由内核配置。
但是,程序是如何运行的呢?
计算机启动后,内核启动init进程。这是第一个在更高抽象层次上运行的程序,其机器代码不必担心许多特定的系统细节。init程序启动渲染计算机图形环境并负责启动其他软件。
要启动一个程序,它使用fork系统调用来克隆自身。这种克隆是高效的,因为所有内存页都是写时复制的,不需要在物理RAM中复制内存。在Linux中,这是copy_process函数在起作用。
两个进程都检查它们是否是被分叉的进程。如果是,它们使用exec系统调用请求内核用新程序替换当前进程。
新程序可能是一个ELF文件,内核解析它以获取如何加载程序以及在新虚拟内存映射中放置其代码和数据的信息。如果程序是动态链接的,内核还可以准备一个ELF解释器。
然后内核可以加载程序的虚拟内存映射,并返回用户空间,使程序运行,这实际上意味着将CPU的指令指针设置为新程序在虚拟内存中代码的开始处。

若有收获,就点个赞吧
0 人点赞
