我们现在已经相当彻底地了解了 execve。在大多数路径的末端,内核将会到达一个包含机器代码的最终程序来启动它。通常,在实际跳转到代码之前需要进行一个设置过程——例如,程序的不同部分必须加载到内存中的正确位置。每个程序需要不同数量的内存用于不同的事情,所以我们有标准的文件格式来指定如何设置一个程序以便执行。虽然 Linux 支持许多这样的格式,但最常见的格式无疑是 ELF(可执行和可链接格式)。

(感谢 Nicky Case 提供的可爱画作。)
附带说明:精灵到处都是吗?
当你在 Linux 上运行一个应用程序或命令行程序时,它极有可能是一个 ELF 二进制文件。然而,在 macOS 上,实际使用的格式是 Mach-O。Mach-O 和 ELF 完成的事情相同,但结构不同。在 Windows 上,.exe 文件使用 Portable Executable 格式,这又是一个不同的格式,但概念相同。
在 Linux 内核中,ELF 二进制文件由 binfmt_elf 处理程序处理,这比许多其他处理程序更复杂,包含数千行代码。它负责从 ELF 文件中解析出某些细节,并利用这些细节将进程加载到内存中并执行它。
我运行了一些命令行技术来按行数对 binfmt 处理程序进行排序:
Shell 会话
$ wc -l binfmt_* | sort -nr | sed 1d2181 binfmt_elf.c1658 binfmt_elf_fdpic.c944 binfmt_flat.c836 binfmt_misc.c158 binfmt_script.c64 binfmt_elf_test.c
文件结构
在更深入地了解 binfmt_elf 如何执行 ELF 文件之前,让我们先看看文件格式本身。ELF 文件通常由四部分组成:

ELF Header
每个 ELF 文件都有一个 ELF 头。它有一个非常重要的任务,即传达关于二进制文件的基本信息,例如:
- 它是为哪种处理器设计运行的。ELF 文件可以包含针对不同处理器类型(如 ARM 和 x86)的机器代码。
- 二进制文件是打算作为可执行文件独立运行,还是打算作为“动态链接库”由其他程序加载。我们很快会详细介绍什么是动态链接。
- 可执行文件的入口点。后续部分准确指定了将 ELF 文件中包含的数据加载到内存中的位置。入口点是一个内存地址,指向整个进程加载后内存中第一条机器代码指令的位置。
ELF 头总是位于文件的开头。它指定了程序头表和节头的位置,这些可以位于文件中的任何地方。这些表又指向文件中其他地方存储的数据。
Program Header Table
程序 header table 是一系列条目,包含在运行时如何加载和执行二进制文件的具体细节。每个条目都有一个类型字段,说明它在指定什么细节——例如,PT_LOAD 表示它包含应该加载到内存中的数据,而 PT_NOTE 表示该段包含不一定需要加载到任何地方的信息文本。

每个条目指定了其数据在文件中的位置信息,有时还包括如何将数据加载到内存中:
- 它指向其数据在 ELF 文件中的位置。
- 它可以指定数据应该加载到内存中的虚拟内存地址。如果该段不打算加载到内存中,这通常会留空。
- 两个字段指定数据的长度:一个是文件中数据的长度,另一个是要创建的内存区域的长度。如果内存区域的长度大于文件中的长度,多余的内存将被填充为零。这对那些希望在运行时使用静态内存段的程序非常有用;这些空内存段通常被称为 BSS 段。
- 最后,标志字段指定如果加载到内存中应允许进行的操作:
PF_R使其可读,PF_W使其可写,PF_X表示它是应允许在 CPU 上执行的代码。
Section Header Table
节头表 是一系列条目,包含关于 节 的信息。这些节信息就像一张地图,绘制出 ELF 文件内部的数据。这使得 像调试器这样的程序 能够理解数据不同部分的预期用途。
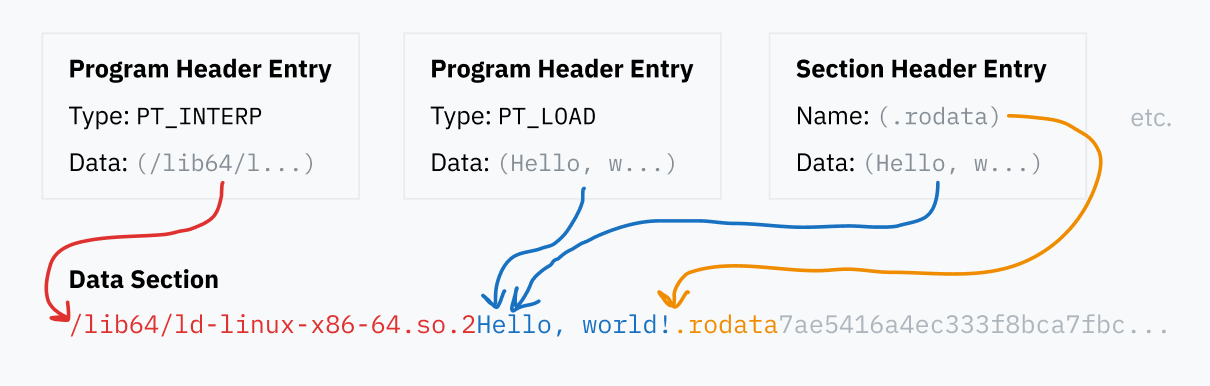
例如,程序头表可以指定一大片数据一起加载到内存中。单个 PT_LOAD 块可能包含代码和全局变量!没有必要将它们分别指定来 运行 程序;CPU 只需从入口点开始并向前执行,在程序请求时访问数据。然而,用于 分析 程序的软件(如调试器)需要确切地知道每个区域的开始和结束位置,否则它可能会尝试将“hello”这段文本解码为代码(由于这不是有效代码,会导致崩溃)。这些信息存储在节头表中。
虽然节头表通常包含,但实际上是可选的。即使完全移除节头表,ELF 文件仍然可以完美运行,那些希望隐藏代码用途的开发者有时会故意从他们的 ELF 二进制文件中剥离或篡改节头表以 使其更难解码。
每个节都有一个名称、类型和一些标志,指定了它的预期用途和解码方式。标准名称通常以点开头。最常见的节是:
.text:要加载到内存并在 CPU 上执行的机器代码。类型为SHT_PROGBITS,带有标志SHF_EXECINSTR表示其为可执行代码,和SHF_ALLOC标志表示其被加载到内存中执行。(不要被名称迷惑,这仍然是二进制机器代码!我总觉得叫.text有点奇怪,尽管它不是可读的“文本”。).data:在可执行文件中硬编码的初始化数据,加载到内存中。例如,包含一些文本的全局变量可能在此节中。如果你写底层代码,这是静态变量所在的节。它的类型也是SHT_PROGBITS,这意味着该节包含“程序信息”。其标志是SHF_ALLOC和SHF_WRITE,表示其为可写内存。.bss:我之前提到过,通常会有一些起始时为零的分配内存。在 ELF 文件中包含一堆空字节是浪费的,所以使用了一种称为 BSS 的特殊段类型。在调试时了解 BSS 段是有帮助的,所以节头表中也有一个条目指定了要分配的内存长度。其类型为SHT_NOBITS,标志为SHF_ALLOC和SHF_WRITE。.rodata:这类似于.data,但它是只读的。在一个非常基础的 C 程序中运行printf("Hello, world!"),字符串 “Hello world!” 将在.rodata节中,而实际打印的代码将在.text节中。.shstrtab:这是一个有趣的实现细节!节本身的名称(如.text和.shstrtab)并未直接包含在节头表中。相反,每个条目包含一个偏移量,指向 ELF 文件中包含其名称的位置。这样,节头表中的每个条目都可以具有相同的大小,使其更易于解析——名称的偏移量是一个固定大小的数字,而包含在表中的名称则是可变大小的字符串。所有这些名称数据都存储在一个称为.shstrtab的节中,类型为SHT_STRTAB。
Data
程序和节头表条目都指向 ELF 文件中的数据块,无论是将它们加载到内存中,指定程序代码的位置,还是仅仅命名节。这些不同的数据部分都包含在 ELF 文件的数据段中。
链接的简要解释
回到 binfmt_elf 代码:内核关注程序头表中的两种类型的条目。
PT_LOAD 段指定了所有程序数据(如 .text 和 .data 节)需要加载到内存中的位置。内核从 ELF 文件中读取这些条目,将数据加载到内存中,以便 CPU 可以执行程序。
内核关注的另一种程序头表条目是 PT_INTERP,它指定了一个“动态链接运行时”。
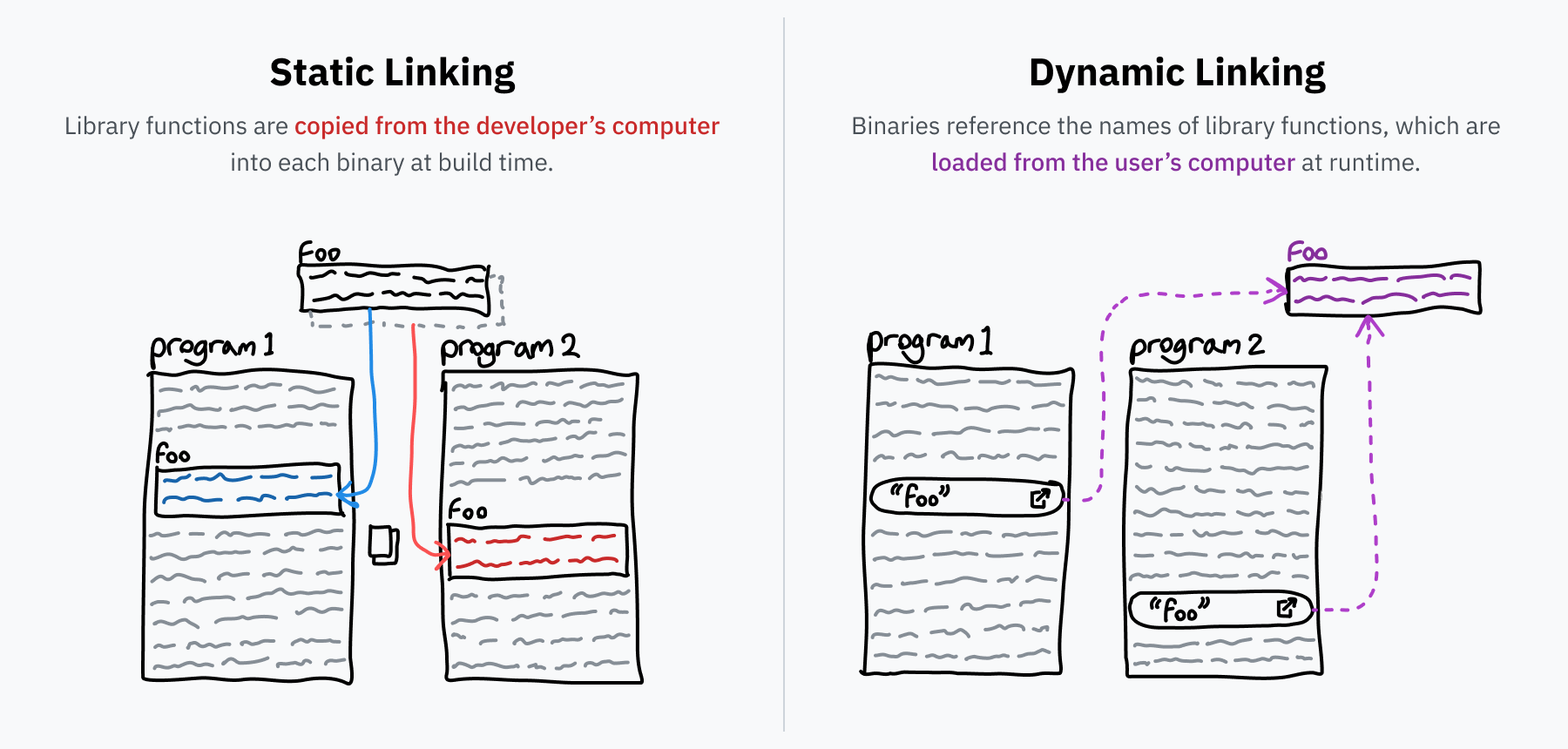
在讨论动态链接是什么之前,让我们先讨论一下“一般的链接”。程序员往往在可重用代码库(例如我们之前提到的 libc)基础上构建他们的程序。在将源代码转换为可执行二进制文件时,一个称为链接器的程序通过查找库代码并将其复制到二进制文件中来解析所有这些引用。这个过程称为 静态链接,这意味着外部代码直接包含在分发的文件中。
然而,有些库非常常见。你会发现 libc 基本上被所有程序使用,因为它是通过系统调用与操作系统交互的规范接口。在你的计算机上的每个程序中包含 libc 的单独副本将是对空间的极大浪费。此外,如果可以在一个地方修复库中的错误,而不是等待每个使用该库的程序进行更新,这可能会很好。动态链接是这些问题的解决方案。
如果一个静态链接的程序需要一个名为 foo 的库 bar 中的函数,该程序将包括整个 foo 的副本。然而,如果它是动态链接的,它只会包含一个引用,说明“我需要库 bar 中的 foo”。当程序运行时,bar 希望已经安装在计算机上,foo 函数的机器代码可以按需加载到内存中。如果计算机上的 bar 库安装更新了,下次程序运行时将加载新代码,而不需要对程序本身进行任何更改。
动态链接
在 Linux 上,可以动态链接的库如 bar 通常打包成扩展名为 .so(共享对象)的文件。这些 .so 文件和程序一样是 ELF 文件——你可能记得 ELF 头包括一个字段来指定文件是可执行文件还是库。此外,共享对象在节头表中有一个 .dynsym 节,该节包含有关从文件导出的符号并可以动态链接的信息。
在 Windows 上,类似 bar 的库打包成 .dll(动态链接库)文件。macOS 使用 .dylib(动态链接库)扩展名。就像 macOS 应用程序和 Windows 的 .exe 文件一样,这些文件的格式与 ELF 文件略有不同,但概念和技术是相同的。
两种链接类型之间一个有趣的区别是,在静态链接中,只有库中使用的部分包含在可执行文件中,从而加载到内存中。而在动态链接中,整个库 被加载到内存中。这听起来可能效率较低,但实际上,它允许现代操作系统通过将库加载到内存中一次,然后在进程之间共享代码来节省更多空间。只有代码可以共享,因为库需要为不同程序提供不同的状态,但节省的内存仍可能达到几十到几百兆字节。
执行
让我们回到内核运行 ELF 文件的过程:如果正在执行的二进制文件是动态链接的,操作系统不能直接跳转到二进制文件的代码,因为会缺少代码——记住,动态链接的程序只包含对所需库函数的引用!
为了运行二进制文件,操作系统需要确定需要哪些库,加载它们,将所有命名指针替换为实际的跳转指令,然后再启动实际的程序代码。这是非常复杂的代码,与 ELF 格式有很深的交互,因此通常是一个独立的程序,而不是内核的一部分。ELF 文件在程序头表的 PT_INTERP 条目中指定它们想要使用的程序的路径(通常类似于 /lib64/ld-linux-x86-64.so.2)。
在读取 ELF 头并扫描程序头表之后,内核可以为新程序设置内存结构。它首先将所有 PT_LOAD 段加载到内存中,填充程序的静态数据、BSS 空间和机器代码。如果程序是动态链接的,内核将不得不执行 ELF 解释器(PT_INTERP),因此它也会将解释器的数据、BSS 和代码加载到内存中。
现在内核需要设置指令指针,以便在返回用户态时恢复。如果可执行文件是动态链接的,内核将指令指针设置为 ELF 解释器代码在内存中的起始位置。否则,内核将其设置为可执行文件的起始位置。
内核几乎准备好从系统调用返回(记住,我们还在 execve 中)。它将 argc、argv 和环境变量推送到栈中,以便程序开始时读取。
寄存器现在被清零。在处理系统调用之前,内核将当前寄存器值存储到栈中,以便切换回用户空间时恢复。在返回用户空间之前,内核会将这部分栈清零。
最后,系统调用结束,内核返回用户态。它恢复寄存器值(现在已清零),并跳转到存储的指令指针。该指令指针现在是新程序(或 ELF 解释器)的起始点,当前进程已经被替换!

若有收获,就点个赞吧
0 人点赞
