Chapter 5 Information Hiding (and Leakage)
Chapter 4 argued that modules should be deep. This chapter, and the next few that follow, discuss techniques for creating deep modules.
5.1 Information hiding
The most important technique for achieving deep modules is information hiding. This technique was first described by David Parnas1. The basic idea is that each module should encapsulate a few pieces of knowledge, which represent design decisions. The knowledge is embedded in the module’s implementation but does not appear in its interface, so it is not visible to other modules.
The information hidden within a module usually consists of details about how to implement some mechanism. Here are some examples of information that might be hidden within a module:
- How to store information in a B-tree, and how to access it efficiently.
- How to identify the physical disk block corresponding to each logical block within a file.
- How to implement the TCP network protocol.
- How to schedule threads on a multi-core processor.
- How to parse JSON documents.
The hidden information includes data structures and algorithms related to the mechanism. It can also include lower-level details such as the size of a page, and it can include higher-level concepts that are more abstract, such as an assumption that most files are small.
Information hiding reduces complexity in two ways. First, it simplifies the interface to a module. The interface reflects a simpler, more abstract view of the module’s functionality and hides the details; this reduces the cognitive load on developers who use the module. For instance, a developer using a B-tree class need not worry about the ideal fanout for nodes in the tree or how to keep the tree balanced. Second, information hiding makes it easier to evolve the system. If a piece of information is hidden, there are no dependencies on that information outside the module containing the information, so a design change related to that information will affect only the one module. For example, if the TCP protocol changes (to introduce a new mechanism for congestion control, for instance), the protocol’s implementation will have to be modified, but no changes should be needed in higher-level code that uses TCP to send and receive data.
When designing a new module, you should think carefully about what information can be hidden in that module. If you can hide more information, you should also be able to simplify the module’s interface, and this makes the module deeper.
Note: hiding variables and methods in a class by declaring them private isn’t the same thing as information hiding. Private elements can help with information hiding, since they make it impossible for the items to be accessed directly from outside the class. However, information about the private items can still be exposed through public methods such as getter and setter methods. When this happens the nature and usage of the variables are just as exposed as if the variables were public.
The best form of information hiding is when information is totally hidden within a module, so that it is irrelevant and invisible to users of the module. However, partial information hiding also has value. For example, if a particular feature or piece of information is only needed by a few of a class’s users, and it is accessed through separate methods so that it isn’t visible in the most common use cases, then that information is mostly hidden. Such information will create fewer dependencies than information that is visible to every user of the class.
5.2 Information leakage
The opposite of information hiding is information leakage. Information leakage occurs when a design decision is reflected in multiple modules. This creates a dependency between the modules: any change to that design decision will require changes to all of the involved modules. If a piece of information is reflected in the interface for a module, then by definition it has been leaked; thus, simpler interfaces tend to correlate with better information hiding. However, information can be leaked even if it doesn’t appear in a module’s interface. Suppose two classes both have knowledge of a particular file format (perhaps one class reads files in that format and the other class writes them). Even if neither class exposes that information in its interface, they both depend on the file format: if the format changes, both classes will need to be modified. Back-door leakage like this is more pernicious than leakage through an interface, because it isn’t obvious.
Information leakage is one of the most important red flags in software design. One of the best skills you can learn as a software designer is a high level of sensitivity to information leakage. If you encounter information leakage between classes, ask yourself “How can I reorganize these classes so that this particular piece of knowledge only affects a single class?” If the affected classes are relatively small and closely tied to the leaked information, it may make sense to merge them into a single class. Another possible approach is to pull the information out of all of the affected classes and create a new class that encapsulates just that information. However, this approach will be effective only if you can find a simple interface that abstracts away from the details; if the new class exposes most of the knowledge through its interface, then it won’t provide much value (you’ve simply replaced back-door leakage with leakage through an interface).
img Red Flag: Information Leakage img
Information leakage occurs when the same knowledge is used in multiple places, such as two different classes that both understand the format of a particular type of file.
5.3 Temporal decomposition
One common cause of information leakage is a design style I call temporal decomposition. In temporal decomposition, the structure of a system corresponds to the time order in which operations will occur. Consider an application that reads a file in a particular format, modifies the contents of the file, and then writes the file out again. With temporal decomposition, this application might be broken into three classes: one to read the file, another to perform the modifications, and a third to write out the new version. Both the file reading and file writing steps have knowledge about the file format, which results in information leakage. The solution is to combine the core mechanisms for reading and writing files into a single class. This class will get used during both the reading and writing phases of the application. It’s easy to fall into the trap of temporal decomposition, because the order in which operations must occur is often on your mind when you code. However, most design decisions manifest themselves at several different times over the life of the application; as a result, temporal decomposition often results in information leakage.
Order usually does matter, so it will be reflected somewhere in the application. However, it shouldn’t be reflected in the module structure unless that structure is consistent with information hiding (perhaps the different stages use totally different information). When designing modules, focus on the knowledge that’s needed to perform each task, not the order in which tasks occur.
img Red Flag: Temporal Decomposition img
In temporal decomposition, execution order is reflected in the code structure: operations that happen at different times are in different methods or classes. If the same knowledge is used at different points in execution, it gets encoded in multiple places, resulting in information leakage.
5.4 Example: HTTP server
To illustrate the issues in information hiding, let’s consider the design decisions made by students implementing the HTTP protocol in a software design course. It’s useful to see both the things they did well and they areas where they had problems.
HTTP is a mechanism used by Web browsers to communicate with Web servers. When a user clicks on a link in a Web browser or submits a form, the browser uses HTTP to send a request over the network to a Web server. Once the server has processed the request, it sends a response back to the browser; the response normally contains a new Web page to display. The HTTP protocol specifies the format of requests and responses, both of which are represented textually. Figure 5.1 shows a sample HTTP request describing a form submission. The students in the course were asked to implement one or more classes to make it easy for Web servers to receive incoming HTTP requests and send responses.
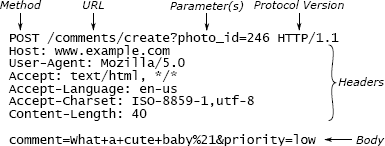
Figure 5.1: A POST request in the HTTP protocol consists of text sent over a TCP socket. Each request contains an initial line, a collection of headers terminated by an empty line, and an optional body. The initial line contains the request type (POST is used for submitting form data), a URL indicating an operation (/comments/create) and optional parameters (photo_id has the value 246), and the HTTP protocol version used by the sender. Each header line consists of a name such as Content-Length followed by its value. For this request, the body contains additional parameters (comment and priority).
5.5 Example: too many classes
The most common mistake made by students was to divide their code into a large number of shallow classes, which led to information leakage between the classes. One team used two different classes for receiving HTTP requests; the first class read the request from the network connection into a string, and the second class parsed the string. This is an example of a temporal decomposition (“first we read the request, then we parse it”). Information leakage occurred because an HTTP request can’t be read without parsing much of the message; for example, the Content-Length header specifies the length of the request body, so the headers must be parsed in order to compute the total request length. As a result, both classes needed to understand most of the structure of HTTP requests, and parsing code was duplicated in both classes. This approach also created extra complexity for callers, who had to invoke two methods in different classes, in a particular order, to receive a request.
Because the classes shared so much information, it would have been better to merge them into a single class that handles both request reading and parsing. This provides better information hiding, since it isolates all knowledge of the request format in one class, and it also provides a simpler interface to callers (just one method to invoke).
This example illustrates a general theme in software design: information hiding can often be improved by making a class slightly larger. One reason for doing this is to bring together all of the code related to a particular capability (such as parsing an HTTP request), so that the resulting class contains everything related to that capability. A second reason for increasing the size of a class is to raise the level of the interface; for example, rather than having separate methods for each of three steps of a computation, have a single method that performs the entire computation. This can result in a simpler interface. Both of these benefits apply in the example of the previous paragraph: combining the classes brings together all of the code related to parsing an HTTP request, and it replaces two externally-visible methods with one. The combined class is deeper than the original classes.
Of course, it is possible to take the notion of larger classes too far (such as a single class for the entire application). Chapter 9 will discuss conditions under which it makes sense to separate code into multiple smaller classes.
5.6 Example: HTTP parameter handling
After an HTTP request has been received by a server, the server needs to access some of the information from the request. The code that handles the request in Figure 5.1 might need to know the value of the photo_id parameter. Parameters can be specified in the first line of the request (photo_id in Figure 5.1) or, sometimes, in the body (comment and priority in Figure 5.1). Each parameter has a name and a value. The values of parameters use a special encoding called URL encoding; for example, in the value for comment in Figure 5.1, “+” is used to represent a space character, and “%21” is used instead of “!”. In order to process a request, the server will need the values for some of the parameters, and it will want them in unencoded form.
Most of the student projects made two good choices with respect to parameter handling. First, they recognized that server applications don’t care whether a parameter is specified in the header line or the body of the request, so they hid this distinction from callers and merged the parameters from both locations together. Second, they hid knowledge of URL encoding: the HTTP parser decodes parameter values before returning them to the Web server, so that the value of the comment parameter in Figure 5.1 will be returned as “What a cute baby!”, not “What+a+cute+baby%21”). In both of these cases, information hiding resulted in simpler APIs for the code using the HTTP module.
However, most of the students used an interface for returning parameters that was too shallow, and this resulted in lost opportunities for information hiding. Most projects used an object of type HTTPRequest to hold the parsed HTTP request, and the HTTPRequest class had a single method like the following one to return parameters:
public Map<String, String> getParams() {return this.params;}
Rather than returning a single parameter, the method returns a reference to the Map used internally to store all of the parameters. This method is shallow, and it exposes the internal representation used by the HTTPRequest class to store parameters. Any change to that representation will result in a change to the interface, which will require modifications to all callers. When implementations are modified, the changes often involve changes in the representation of key data structures (to improve performance, for example). Thus, it’s important to avoid exposing internal data structures as much as possible. This approach also makes more work for callers: a caller must first invoke getParams, then it must call another method to retrieve a specific parameter from the Map. Finally, callers must realize that they should not modify the Map returned by getParams, since that will affect the internal state of the HTTPRequest.
Here is a better interface for retrieving parameter values:
public String getParameter(String name) { ... }public int getIntParameter(String name) { ... }
getParameter returns a parameter value as a string. It provides a slightly deeper interface than getParams above; more importantly, it hides the internal representation of parameters. getIntParameter converts the value of a parameter from its string form in the HTTP request to an integer (e.g., the photo_id parameter in Figure 5.1). This saves the caller from having to request string-to-integer conversion separately, and hides that mechanism from the caller. Additional methods for other data types, such as getDoubleParameter, could be defined if needed. (All of these methods will throw exceptions if the desired parameter doesn’t exist, or if it can’t be converted to the requested type; the exception declarations have been omitted in the code above).
5.7 Example: defaults in HTTP responses
The HTTP projects also had to provide support for generating HTTP responses. The most common mistake students made in this area was inadequate defaults. Each HTTP response must specify an HTTP protocol version; one team required callers to specify this version explicitly when creating a response object. However, the response version must correspond to that in the request object, and the request must already be passed as an argument when sending the response (it indicates where to send the response). Thus, it makes more sense for the HTTP classes to provide the response version automatically. The caller is unlikely to know what version to specify, and if the caller does specify a value, it probably results in information leakage between the HTTP library and the caller. HTTP responses also include a Date header specifying the time when the response was sent; the HTTP library should provide a sensible default for this as well.
Defaults illustrate the principle that interfaces should be designed to make the common case as simple as possible. They are also an example of partial information hiding: in the normal case, the caller need not be aware of the existence of the defaulted item. In the rare cases where a caller needs to override a default, it will have to know about the value, and it can invoke a special method to modify it.
Whenever possible, classes should “do the right thing” without being explicitly asked. Defaults are an example of this. The Java I/O example on page 26 illustrates this point in a negative way. Buffering in file I/O is so universally desirable that noone should ever have to ask explicitly for it, or even be aware of its existence; the I/O classes should do the right thing and provide it automatically. The best features are the ones you get without even knowing they exist.
img Red Flag: Overexposure img
If the API for a commonly used feature forces users to learn about other features that are rarely used, this increases the cognitive load on users who don’t need the rarely used features.
5.8 Information hiding within a class
The examples in this chapter focused on information hiding as it relates to the externally visible APIs for classes, but information hiding can also be applied at other levels in the system, such as within a class. Try to design the private methods within a class so that each method encapsulates some information or capability and hides it from the rest of the class. In addition, try to minimize the number of places where each instance variable is used. Some variables may need to be accessed widely across the class, but others may be needed in only a few places; if you can reduce the number of places where a variable is used, you will eliminate dependencies within the class and reduce its complexity.
5.9 Taking it too far
Information hiding only makes sense when the information being hidden is not needed outside its module. If the information is needed outside the module, then you must not hide it. Suppose that the performance of a module is affected by certain configuration parameters, and that different uses of the module will require different settings of the parameters. In this case it is important that the parameters are exposed in the interface of the module, so that they can be turned appropriately. As a software designer, your goal should be to minimize the amount of information needed outside a module; for example, if a module can automatically adjust its configuration, that is better than exposing configuration parameters. But, it’s important to recognize which information is needed outside a module and make sure it is exposed.
5.10 Conclusion
Information hiding and deep modules are closely related. If a module hides a lot of information, that tends to increase the amount of functionality provided by the module while also reducing its interface. This makes the module deeper. Conversely, if a module doesn’t hide much information, then either it doesn’t have much functionality, or it has a complex interface; either way, the module is shallow.
When decomposing a system into modules, try not to be influenced by the order in which operations will occur at runtime; that will lead you down the path of temporal decomposition, which will result in information leakage and shallow modules. Instead, think about the different pieces of knowledge that are needed to carry out the tasks of your application, and design each module to encapsulate one or a few of those pieces of knowledge. This will produce a clean and simple design with deep modules.
1David Parnas, “On the Criteria to be Used in Decomposing Systems into Modules,” Communications of the ACM, December 1972.

若有收获,就点个赞吧
0 人点赞
