
回归损失
MAE Loss
公式:

图像:
MAE 的曲线呈 V 字型,连续但在 y-f(x)=0 处不可导,计算机求导比较难。且 MAE 大部分情况下梯度相等,这意味着即使对于小的损失值,其梯度也是大的,不利于函数的收敛和模型的学习
优点:由于MAE 计算的是绝对误差,无论是 y-f(x)>1 还是 y-f(x)<1,没有平方项的作用,惩罚力度相同,因此MAE 相比 MSE 对**离群点不过分敏感**,拟合直线能够较好地表征正常数据的分布情况,其鲁棒性更好
缺点:MAE训练中梯度始终很大,且在0点连续但不可导,这意味着即使对于小的损失值,其梯度也是大的。这不利于函数的收敛和模型的学习,模型学习速度慢,同时也会导致使用梯度下降训练模型时,在结束时可能会遗漏全局最小值。
MSE Loss
公式:

图像:
MSE 曲线的特点是光滑连续、可导,便于使用梯度下降算法。平方误差有个特性,就是当 yi 与 f(xi) 的差值大于 1 时,会增大其误差;当 yi 与 f(xi) 的差值小于 1 时,会减小其误差。这是由平方的特性决定的。也就是说, MSE 会对误差较大(>1)的情况给予更大的惩罚,对误差较小(<1)的情况给予更小的惩罚。比如说真实值为1,预测10次,有一次预测值为1000,其余次的预测值为1左右,显然loss值主要由1000决定。
优点:收敛速度快-MSE 随着误差的减小,梯度也在减小,这有利于函数的收敛,即使固定学习率,函数也能较快收敛到最小值。
缺点:离群点影响大从Training的角度来看,模型会更加偏向于惩罚较大的点,赋予其更大的权重,忽略掉较小的点的作用,无法避免离群点可能导致的梯度爆炸问题。如果样本中存在离群点,MSE 会给离群点赋予更高的权重,但是却是以牺牲其他正常数据点的预测效果为代价,因此会导致降低模型的整体性能。
Smooth L1 Loss
公式:
图像:

该函数实际上就是一个分段函数,在[-1,1]光滑,这样解决了MAE的不光滑问题,在[-∞,1)(1,+∞])区间解决了MSE可能导致的离群点梯度爆炸的问题,即:
Huber 函数它围绕的最小值会减小梯度,且相比MSE,它对异常值更具鲁棒性, Huber 函数同时具备了 MSE 和 MAE 的优点,既弱化了离群点的过度敏感问题,又实现了处处可导的功能
优点:
同时具备了 MSE 和 MAE 的优点,既弱化了离群点的过度敏感问题,又实现了处处可导的功能,收敛速度也快于MAE,相比于MAE损失函数,可以收敛得更快;
相比于MSE损失函数,对离群点、异常值不敏感,梯度变化相对更小,训练时不容易抛出奇怪的结果
分类损失
Corss Entropy
对相对熵进行变形可以得到:
等式的前一部分恰巧就是p的熵,等式的后一部分,就是交叉熵
假设N=3,期望输出为p=(1,0,0),实际输出(原始数据):q1=(0.5,0.2,0.3),q2=(0.8,0.1,0.1),那么:
用softmax进行计算交叉熵(cross entropy)
如果在原始数据上你用的是softmax进行的归一化,那么交叉熵:

KL Divergence
KL散度又称为相对熵,信息散度,信息增益。KL散度是是两个概率分布P和Q 差别的非对称性的度量。 KL散度是用来 度量使用基于Q的编码来编码来自P的样本平均所需的额外的位元数。 典型情况下,P表示数据的真实分布,Q表示数据的理论分布,模型分布,或P的近似分布。
从KL散度公式中可以看到Q的分布越接近P(Q分布越拟合P),那么散度值越小,即损失值越小。
因为对数函数是凸函数,所以KL散度的值为非负数。
有时会将KL散度称为KL距离,但它并不满足距离的性质:
- KL散度不是对称的;
- KL散度不满足三角不等式。
作者:erwin 链接:https://www.zhihu.com/question/41252833/answer/515095695
从信息编码的角度分析:信息熵完美编码,交叉熵不完美编码,相对熵是两者的差值,交叉熵减去信息熵。差值即差异,也即KL散度。
从信息编码的角度举个例子,假设一个信源是一个随机变量X,且该随机变量取值的正确分布p如下: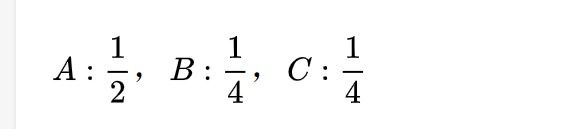
那么可以简单认为,平均每发送4个符号其中就有2个A,1个B,1个C。因为我们知道信道传输是只能传二进制编码的,所以必须对A、B、C进行编码,根据哈夫曼树来实现,如下所示:
也就是说A被编码为0,B被编码为10,C被编码为11。所以每4个字符的平均编码长度为:1.5 ,因为平均有2个A,1个B,1个C。
那么这个随机变量的信息熵是什么呢?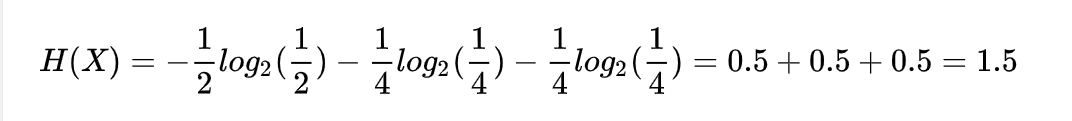
正好也是1.5。所以说信息熵是随机变量平均编码的最小长度。
JS散度
JS散度度量了两个概率分布的相似度,基于KL散度的变体,解决了KL散度非对称的问题。一般地,JS散度是对称的,其取值是0到1之间。定义如下:
Dice Loss
主要用于语义分割任务中,旨在应对语义分割中正负样本强烈不平衡的场景。
dice loss 对正负样本严重不平衡的场景有着不错的性能,训练过程中更侧重对前景区域的挖掘。
def dice_loss(target,predictive,ep=1e-8):intersection = 2 * torch.sum(predictive * target) + epunion = torch。sum(predictive) + torch.sum(target) + eploss = 1 - intersection / unionreturn loss
Wasserstein distance(推土机距离)
参考

若有收获,就点个赞吧
0 人点赞
