
半监督学习(semi-supervised learning)
数据特点
前提假设
- 连续性假设(continuity assumption):样本之间的特征是相似的话,则这两个样本很有可能是有相同的标注的;如果两个样本 x1,x2 相似,则它们的相应输出 y1,y2 也应如此。
- 聚类假设(Cluster Assumption):假设输入数据点形成簇,每个簇对应于一个输出类,那么如果点在同一个簇中,则它们可以认为属于同一类。
流形假设( Manifold Assumption): 虽然我们收集的数据维度比较高,但是数据有可能是在低维的流型上分布的(可通过降维得到干净点的数据)
方法:
自训练

先用标注好的数据训练一个模型
- 用训练好的模型对未标注的数据进行预测(得到伪标注数据)
- 将伪标注数据与已标好数据合并
- 在合并的数据的基础上再训练模型
不断进行上述过程
P.S.
伪标注数据可能噪音比较大,故将模型比较确信的伪标注数据保留下来。(怎么样选择置信样本)
这里的模型是用来标记数据的,不用考虑该模型的成本,这个模型不会上线
众包
弱监督学习
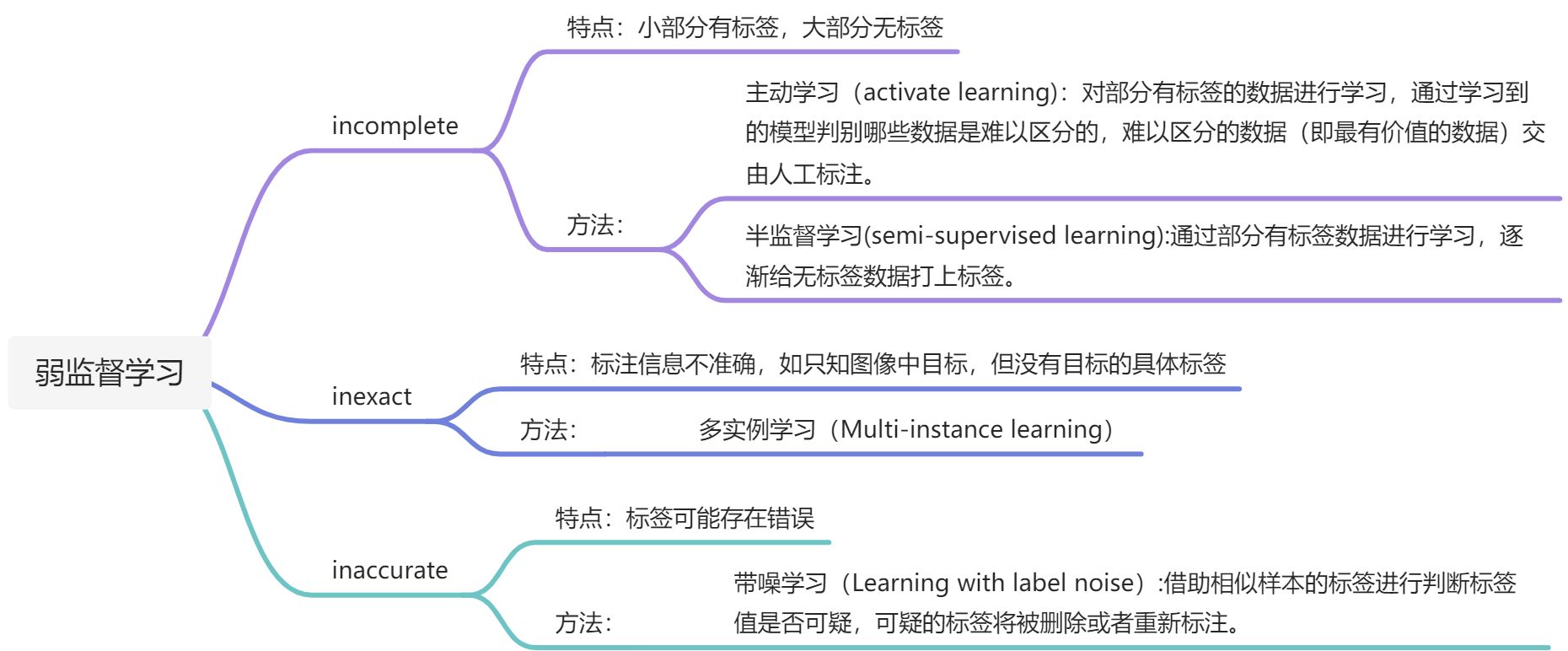
尽管当前监督学习技术已经取得了巨大的成功,但是值得注意的是,由于数据标注过程的成本太高,很多任务很难获得如全部真值标签这样的强监督信息。而无监督学习由于学习过程太过困难,它的发展缓慢。因此,希望机器学习技术能够在弱监督状态下工作。《A Brief Introduction to Weakly Supervised Learning》
在图像分类任务中,训练数据的Groud-Truth标签由人类注释者给出; 虽然很容易从互联网上获取大量图像,而由于人工成本,只能注释一小部分图像。(不完全监督)
在重要目标检测中,我们常常仅有图片级标签,而没有对象级标签。(不确切监督)
在众包数据分析中,当图像标记者粗心或者疲倦时,或者有些图片很难去分类时,这将会导致一些标签被标记错误。(不精确监督)
针对这三种典型的弱监督学习,我们可以考虑使用不同的技术去进行改善和解决

若有收获,就点个赞吧
0 人点赞
