关系型数据库
注意事项
- ER 图用 UML 标记。
- 关系模式是指表模式的定义,如
tableName(field1, field2, ......),注意要标识主键和外键。 - 多对多关系要尽量抽象出一个实体。
- 散列索引适合数据规模小且相对稳定的情况,使用哈希查找只需要
 时间,也不会造成太大的空间浪费;顺序索引适合数据规模大且不太稳定的情况,在排序后使用二分法查找只需要
时间,也不会造成太大的空间浪费;顺序索引适合数据规模大且不太稳定的情况,在排序后使用二分法查找只需要 时间。
时间。 - 因为大多数数据库会自动为主键字段创建索引,因此组合主键的字段顺序对查找性能有很大的影响,要经常站在业务角度组织组合主键的字段顺序。
- 在书写存储过程时,变量一定要放在“=”号的右边,如
name = @nameV。’ SELECT ... INTO tmp1 FROM创建临时表。WITH table(field1, field2, ...) AS创建多表运算结果的临时表。
数据组织的两个原则
- 严格按类分表存储,一个类对应一张表,一张表对应一个类。
- 一个数据只存一份,一个实例对应一行数据,一行数据对应一个实例。
五大问题
- 数据正确性问题。
- 数据完整性问题。
- 数据操作简单性问题。用户通过使用 DA 以图形化的方式进行操作;专业人员使用 SQL 语句进行操作。
- 数据安全性问题。
-
数据库系统的三级模式架构
数据库系统,Management Information System, MIS
三级模式架构和二级映射实现了 MIS 的数据独立性。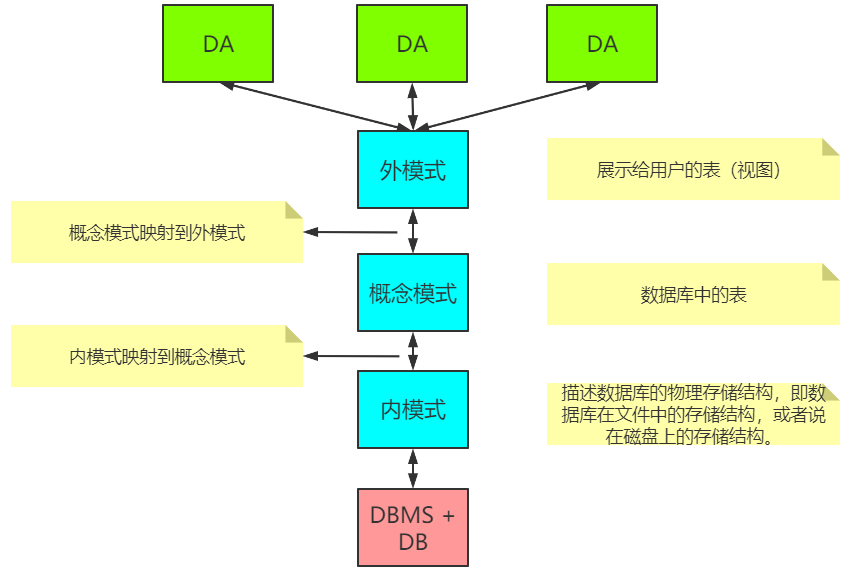
数据库应用程序 Database Application,简称 DA
- 数据库管理系统 Database Management System,简称 DBMS
- 数据库 Database,简称 DB
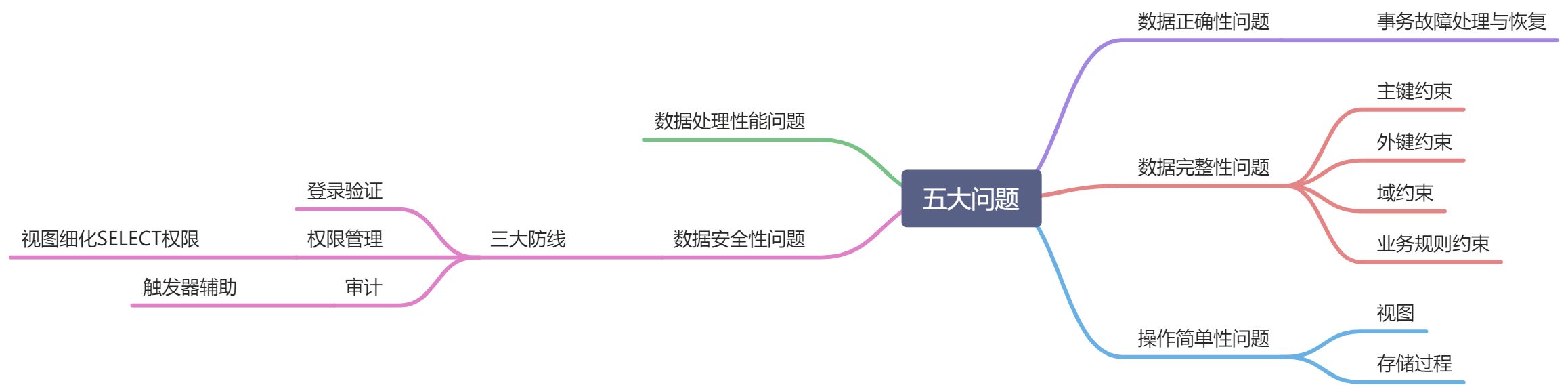
DA与DBMS的邦联性
因为 DBMS 提供了统一的访问 DB 的标准接口 JDBC 和 ODBC,所以 DA 和 DBMS 可以随意组合搭配使用。
但是 DB 与 DBMS 却没有邦联性,一个 DBMS 管一个 DB 。
- Java Database Connectivity
- Open Database Connectivity
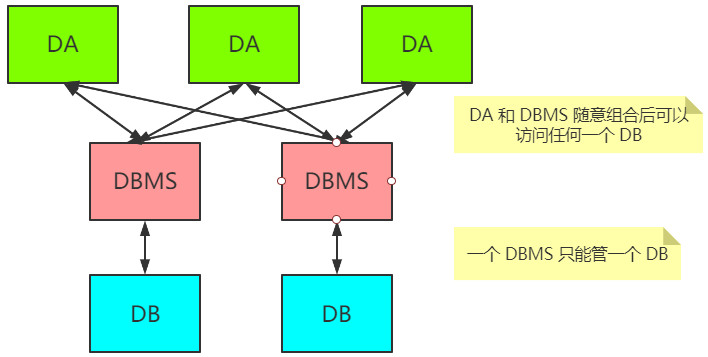
四大约束 — 正确性、完整性的保证
- 主键约束(实体完整性约束)。
- 外键约束(引用完整性约束)。
- 域约束。
- 业务规则约束。
关系代数
五大基本运算
| 名称 | 格式 | 作用 | 备注 |
|---|---|---|---|
选择运算  |
 |
选取符合条件的行 | |
投影运算  |
 |
选取指定的列 | |
笛卡尔乘积  |
 |
组合两张表的所有情况 | 如表 1 有 m 行,表 2 有 n 行,那么结果就有 m * n 行 |
| 并运算 | 属于表 1 或表 2 的所有行 | 相同行只出现一次 | |
| 差运算 — | (表1)—(表2) | 属于表 1 但不属于表 2 的所有行 |
衍生出的三个运算
| 名称 | 格式 | 作用 | 备注 |
|---|---|---|---|
| 自然联接 | 列扩展,把外键代表的实例的其他信息扩充进来 | ||
| 交运算 | 属于表 1 也属于表 2 的行 | ||
| 除运算 | 表示与所有 Z 实例都有关系的 X 实例 |
比较运算符
| 运算符 | 含义 |
|---|---|
| > | 大于 |
| ≥ | 大于等于 |
| < | 小于 |
| ≤ | 小于等于 |
| = | 等于 |
| ≠ | 不等于 |
逻辑运算符
| 运算符 | 含义 |
|---|---|
| ∧ | 与 |
| ∨ | 或 |
| ¬ | 非 |
要点:
- 关系代数的特点是输入为关系,输出结果也为关系。
- 自然联接的要求是两个表有共同字段,该字段在一个表中是主键,在另一个表中是外键。
- 外键所在的表是主表,结果基于它生成。
- 外键为 NULL 的行不会出现在结果中,因此如过主表有 n 行,运算结果
 n 行。
n 行。 - 多表自然联接顺序有要求,否则会出现中间会出现联系中断(即不符合自然联接的要求)。
SQL
Structured Query Language,结构化查询语言。
特点:
- 申明性语言。
- 不区分大小写。
- 两个单引号表示一个单引号字符。
访问数据库的四个步骤
- 建立与数据库的连接。指定数据库服务器的 IP + port,使用账号密码登录。
- 指定要访问的数据库。
- 执行 SQL 语句并得到结果。
- 关闭与数据库的连接。
五大操作
- 增加数据。基本格式:
INSERT INTO table(field1, field2, ...) VALUES (value1, value2, ...) - 删除数据。基本格式:
DELETE FROM table WHERE 条件表达式 - 更新数据。基本格式:
UPDATE table SET field1=xxx, field2=xxx, WHERE 条件表达式
注:增加、删除和更新都有可能会破坏数据的完整性,DBMS 拒绝处理破坏数据完整性的操作。
- 查询数据。
- 统计数据。
 简称“增删查改计”,操作单位是行。
简称“增删查改计”,操作单位是行。
查询
基本格式:SELECT field1, field2, ...FROM table1, table2, ...WHERE 条件表达式ORDER BY 排序条件表达式 (ASC OR DESC)
注意:
- WHERE 后面的自然联接表达式一定要写好。
- 默认升序,降序要指明。
%通配符匹配任意个字符;_通配符匹配一个字符;使用ESCAPE关键字定义转义字符,如ESCAPE #。- 消重处理。当输出字段不包含或只包含部分主键时,结果可能有重复行,可以使用
DISTINCT关键字消重。
嵌套查询
本质:SQL 语句的执行结果是一张表,可以作为其他 SQL 语句的输入表。
- 当结果为一行一列时(最特殊的表),可以当做一个常量参与运算,加减乘除、比较等(适合的运算类型受限于结果类型)。
- 当结果为多行一列时(只有一列的表),可以当做是一个常量的集合。常用操作是
IN,NOT IN等 - 当结果为多行多列时(普通表),可以与同类型的表进行
INTERSECT,UNION,EXCEPT集合运算,还可以作为另一张表的输入INSERT INTO table1(field1, field2, ...) (SELECT filedx, fieldy, ... FROM ...)统计
本质:先查询再统计。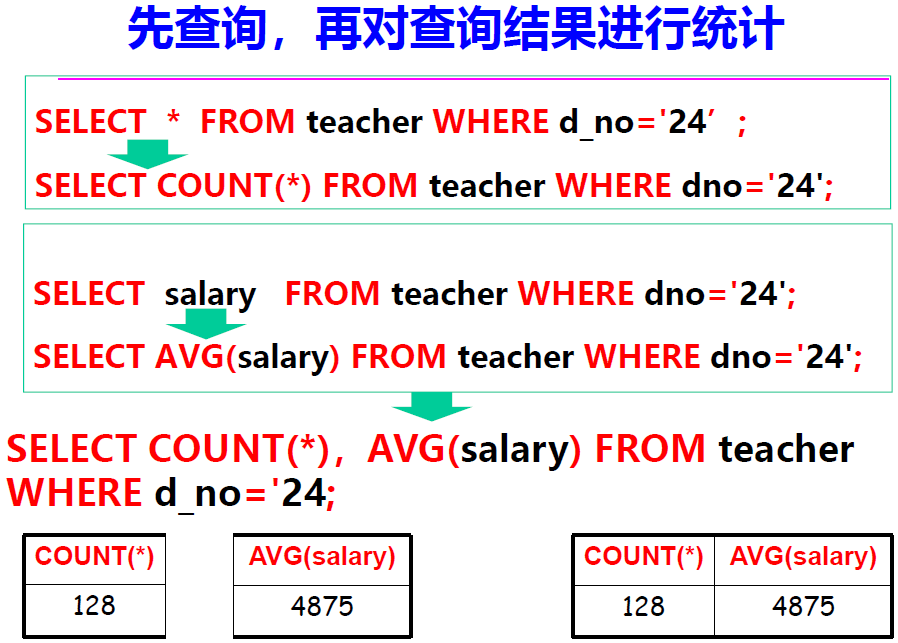
基本格式:
DBMS 对 SELECT 语句的执行顺序如图所示,蓝颜色框可以是最终的输出结果。SELECT field1, field2, ... // 4FROM table1, table2, ... // 1WHERE 条件表达式 // 2GROUP BY 分组条件表达式 // 3HAVING 过滤条件表达式 // 5ORDER BY 排序条件表达式 // 6
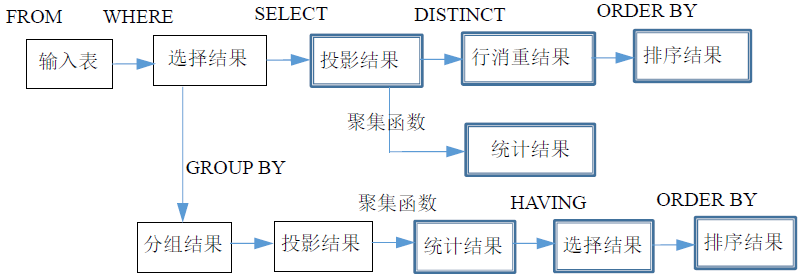
要点:分组了必须统计!
五大聚集函数:
- MAX(),求最大值。
- MIN(),求最小值。
- COUNT(),求行数。
- AVG(),求平均值。
- SUM(),求和。
注:
- 统计结果只有一行数据!
- GROUP BY 后的字段,都要放在 SELECT 后面。
数据库中的对象
列,表,视图,存储过程,函数,用户,角色,索引,用户自定义数据类型。
主键都是它们的名字!(列的主键应该是所属表名+列名)
删除对象的语句
DROP objectType objectName
例如:DROP TABLE student 删除 student 表;DROP VIEW mystudent 删除 mystudent 视图。
建表语句基本格式
CREATE TABLE tableName (fieldName1 type(length) NOT NULL, -- 主键字段指明 NOT NULLfieldName2 type(length), -- 常规字段指明字段名、数据类型和长度-- 限定只有几个取值的字段,用 CHECK 限制fieldName3 type(length) CHECK(fieldName3 IN (NULL, 'x', 'y')) -- 限定只能取 x 或 y 或 NULL...PRIMARY KEY (fieldNameX, fieldNameY) -- 指明表的主键,有多少个写多少个-- 指明外键引自哪张表的哪个字段,同时说明 ON DELETE 和 ON UPDATE 规则FOREIGN KEY (fieldName) REFERENCES 参考表名(参考的主键字段) ON DELETE XXX ON UPDATE XXX);
注意:
- 字段定义之间有逗号分隔,最后一个字段定义没有逗号
- 主键与外键定义之间没有逗号分隔。
- ON DELETE 和 ON UPDATE 都有三种设置方式
- NO ACTION
- SET NULL
- CASCADE
CREATE TABLE student (sno CHAR(10) NOT NULL,name VARCHAR(12),sex CHAR(1) CHECK(sex IN (NULL, '', '')),dno CHAR(8),PRIMARY KEY (sno)FOREIGN KEY (dno) REFERENCES department(dno)ON DELETE SET NULL ON UPDATE CASCADE);
创建视图基本格式
CREATE VIEW viewName(field1, field2, ...) AS常规 SELECT 语句
注意:
- 视图的字段和 SELECT 的字段要一一对应。
创建存储过程基本格式
CREATE PROCEDURE procedureName(@变量1 IN 变量类型, @变量2 IN 变量类型, ...) ASBEGIN/*定义需要的变量变量名 变量类型*/常规 SQL 语句END;
注意:
- 变量一定要放在 = 号的右边!
- 可以定义需要的变量。
- 使用时用 CALL 关键字,CALL procedureName(参数)。
创建触发器基本格式
触发器只针对于 UPDATE, DELETE, INSERT 这三种操作。
- INSERT 只有 NEW ROW ,对插入的每一新行做检测。
- DELETE 只有 OLD ROW ,对要删除的每一旧行做检测。
- UPDATE 既有 OLD ROW 也有 NEW ROW ,对要更新的行,做更新前和更新后的检测。
条件判断都 IF 和 WHEN 两套,WHEN 更简洁。 ```sql IF () THEN — 一些操作 END IF;CREATE TRIGGER 触发器名触发器类型 三种操作之一 OF 针对的字段 ON 针对的表名REFERENCING OLD ROW AS old_row NEW ROW AS new_oldFROM EACH ROWBEGIN/*定义需要的变量变量名 变量类型*/-- 常规 SQL 语句END;
WHEN () — 一些操作
用 raise_application_error(20000, '错误信息'); 来处理异常,让触发器终止工作。<a name="o1Uvt"></a>## 完整性问题总体解决方案:四大约束 + 触发器 + 应用程序。<a name="cuPzg"></a>## 操作简单性问题总体解决方案:视图 + 存储过程 + 应用程序。<a name="VG1UV"></a>## 安全性问题总体解决方案:三大防线 + 视图 + 存储过程 + 触发器 + 应用程序。<br />三大防线:1. 用户登录1. 权限管理1. 审计<a name="c3ML2"></a>### 权限管理三大原则:1. 对象的创建者拥有对其的全部权限。1. 权限可以被授予。1. 权限可以被收回,且有连带性。技巧:<br />**只以角色的身份授权,并且只授权给角色!**<a name="1MJxM"></a>### 用户```sqlCREATE USER 用户名 IDENTIFIED BY 密码; -- 创建DROP USER 用户名; -- 删除
角色
CREATE ROLE 角色名; -- 创建角色DROP ROLE 角色名; -- 删除角色GRANT 角色名 TO 用户名; -- 把角色授予用户
授权与收权
DBMS 的权限管理是粗放型的,体现如下:
- 对 SELECT 和 DELETE 权限只能细化到表。
- 对 UPDATE 和 INSERT 权限可以细化到列。
注:
- 借助视图可以把 SELECT 权限细化到列,甚至行。 ```sql / 授权 / SET CURRENT_ROLE AS 角色名; — 设置为身份为角色,以角色的身份授权 GRANT SELECT ON 表名 TO 角色名; — 细化到表 GRANT DELETE ON 表名 TO 角色名; — 细化到表 GRANT UPDATE(fieldx) ON 表名 TO 角色名; — 细化到列,但不是必须的 GRANT INSERT(fieldx) ON 表名 TO 角色名; — 细化到列,但不是必须的
/ 收权 / REVOKE 角色名 FROM 用户名; — 收回用户的角色 ROVOKE DELETE/SELECT ON 表名 FROM 角色名/用户名; ROVOKE DELETE/SELECT ON 表名 FROM 角色名/用户名; ROVOKE UPDATE/INSERT(field1, field2, …) ON 表名 FROM 角色名/用户名;
预留关键字:`PUBLIC` 代表所有用户;`ALL PRIVILEDGES` 代表以上 4 种权限。<a name="zcnqe"></a>## 正确性问题总体解决方案:事务 ACID 属性 + 故障防备与恢复技术<br />事务:一组 SQL 请求,中间的 SQL 对外部不可见。```sqlTRANSACTION BEGINSQL1;SQL2;SQL3;COMMIT;
事务的五个状态: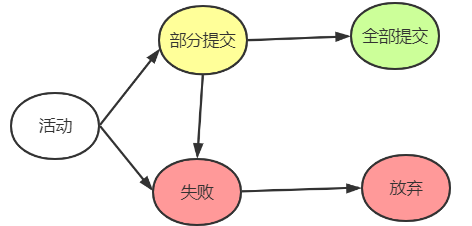
事务的 ACID 属性:
- Atomicity:原子性。一个事务要么执行成功,要么失败。
- Consistency:一致性。事务必须始终保持系统处于一致的状态。即事务必须使数据库从一个一致性状态变换到另外一个一致性状态。数据库的完整性约束没有被破坏,事务执行的前后都是合法的数据状态。
- Isolation:并发执行的事务互不干扰。
- Durability:持久性。一个事务一旦提交了,那么他对数据库的更改将永远保留在数据库中,即使发生故障也不会回滚、丢失。
故障分类:
- 事务故障。特征:事务不能执行下去。
- 系统崩溃故障。特征:服务器崩溃了。
- 数据库磁盘故障。特征:数据库数据全部丢失。
- 日志磁盘故障。特征:日志数据全部丢失。
- 灾难故障。特征:
防备和恢复故障的两种方法:
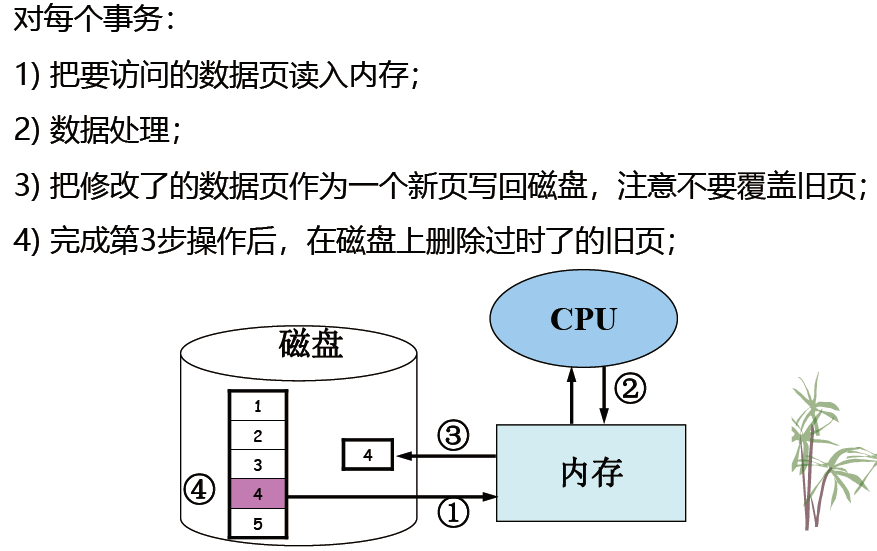
- 分页法。优点是简单,缺点是效率低。
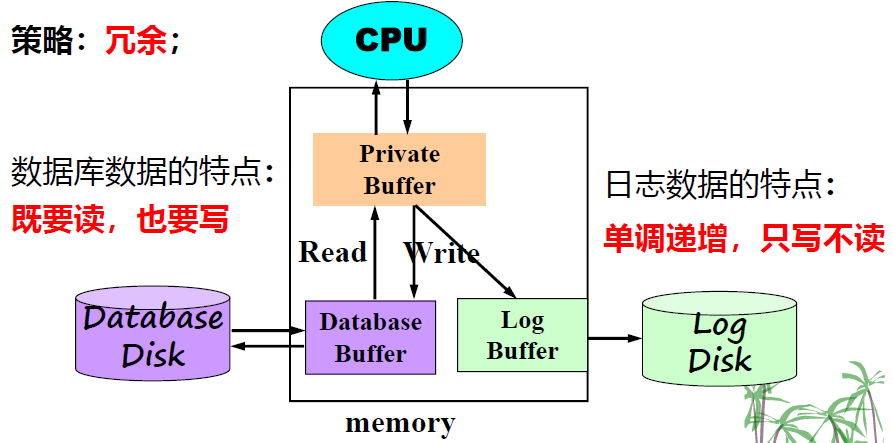
- 日志法。关键是“冗余”,两个同步约束,一个不要。
- 约束一:要把 Database Buffer 里的内容输出到 Database Disk 时,必须把 Log Buffer 里对应的内容输出到 Log Disk .
- 约束二:当事物完成时,即遇到
- 一个不要:日志和数据库不要配置到一个物理磁盘上,否则性能大打折扣。因为数据库磁盘又读又写,磁头来回移动;而日志磁盘只读不写,磁头不需要来回移动。
事务故障处理
回滚。对要撤销的事务T,反向扫描日志,对属于该事务的每一条记录执行 undo 操作,用旧值覆盖新值,直至遇到
系统崩溃故障处理
关键是 undo + redo
先方向扫描日志,对应没有
再正向扫描日志,对有
技巧:很多 
要点:故障处理,日志先行!
数据库磁盘故障处理
备份吧,周期性备份数据库磁盘,发生故障时用最近备份的数据库磁盘替换坏掉的。
备份方法:
要点:故障处理,日志先行;一条灵魂的
恢复方法:
反向扫描恢复备份后的新数据;正向扫描恢恢复备份的数据。
日志磁盘故障处理
不用慌,换个新的就行。
之前的日志不要也罢。
要点:之前的日志没了,之前的数据千万不能丢,因此备份一次数据库磁盘!
灾难故障处理
备份吧,远程备份,狡兔三窟!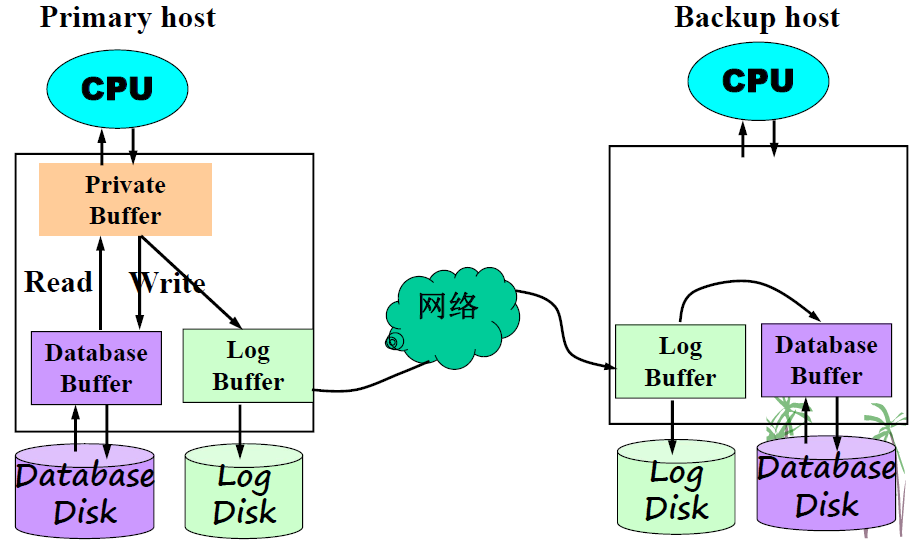
要点:当
性能问题
解决方案:
- B树索引,原理是减少无效运输,方法是压缩和排序。
- 哈希索引,原理是借助哈希函数根据某些字段计算一个哈希值作为在磁盘上的存储地址。
-
B树索引
为一张表的一个或几个字段创建索引(创建过程自动排序),查找时把索引加载到内存,只需要
 的查询时间。
的查询时间。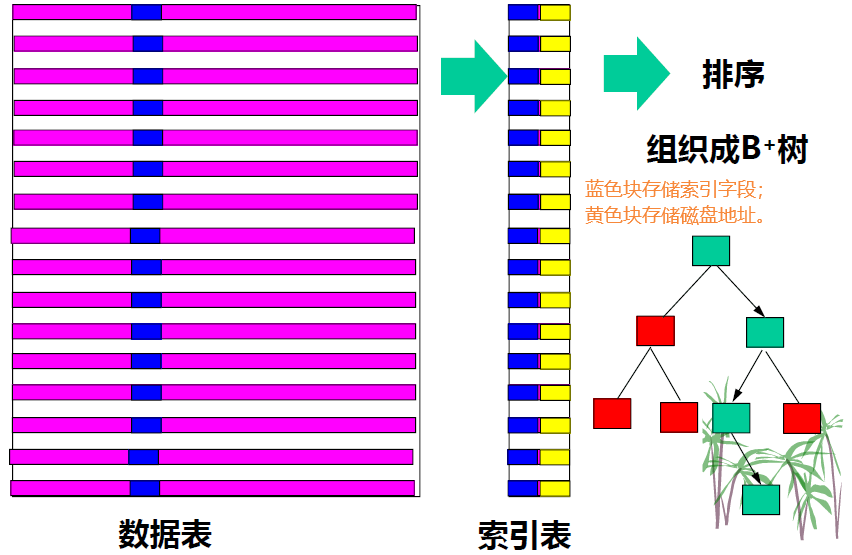
索引的选择技巧: 经常参与联接运算的字段。
- 取值变化很大的字段,比如性别只有男女两个取值就不用创建索引了。
创建和删除的 SQL 语句:
CREATE INDEX 索引名称 ON 表名(field1, field2, ...); -- 创建DROP INDEX 索引名称; -- 删除
多字段索引的顺序问题:
当要为多个字段创建索引时,这些字段的顺序对性能也有影响。
由于 MySQL 会自动为主键字段创建索引,因此多字段主键的顺序也有讲究。
比如 enroll 选课表的主键是 sno, cno, semester,表示某个学生在某个学期选了某门课。
通常情况下,enroll 表的主要业务是:(1)学生查看自己本学期的课表;(2)教师登分。
(semester, sno, cno) 的主键顺序适合业务(1),而 (semester, cno, sno) 的主键顺序适合业务(2)。
哈希索引
原理:借助哈希函数根据某些字段计算一个哈希值作为在磁盘上的存储地址。
适用场景:
- 使用受限的最大因素是:冲突
- 规模不大且相对稳定的表,即多查询、少增加、少修改的表。
数据库设计
三大问题:
- 覆盖性问题:确定有哪些字段。
- 划分问题:哪些字段属于一张表。
- 关系问题:表与表之间的联系是什么。
设计流程
ER建模
建模流程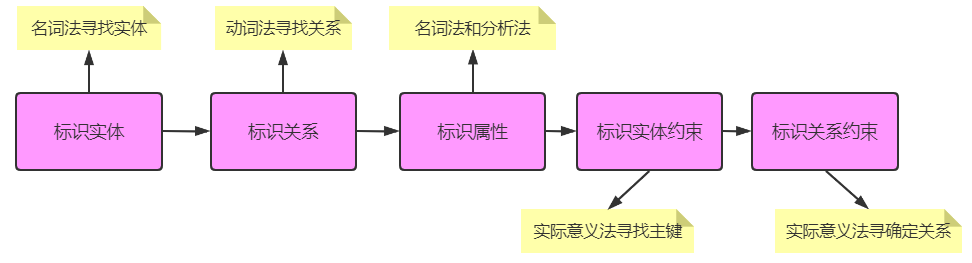
很多情况下,都不遵循这个流程,通常把标识关系和标识关系约束同时做了,因为只有做了标识关系约束,才好做第三步标识属性,有些多对多关系需要弱化成实体,也具有属性。
强弱实体
实体有类型和实例。
表示法:使用矩形标识一个实体。
强实体:只有自己独立的主键,用于标识自己的不同实例。
弱实体:除了自己的主键,还有所依赖实体的主键。
属性
实体自身的属性,比如 student 有性别、年龄、学号等属性。
- 简单属性与组合属性。例如工资和地址。
- 单值属性与多值属性。例如工资和电话号码(个人手机号、座机号等)
- 推导属性。例如年龄由出生日期推出。
联系
表示法:箭头 + 联系名称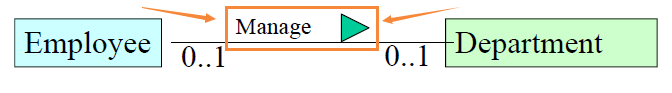
联系有类型和实例。
联系的类型由相关实体的类型表达。
实例:比如 teacher 和 department 有老师管学院关系和学院拥有老师关系等。
实体类型约束
表示法:属性后加 PK 注明。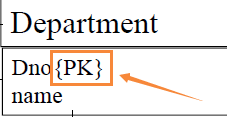
意义:主键约束,标识实例。
实体关系约束
表示法:见图,使用数字表示。
二元关系和多元关系。
有 3 种二元关系约束:一对一,一对多和多对多。
- 一对一关系。
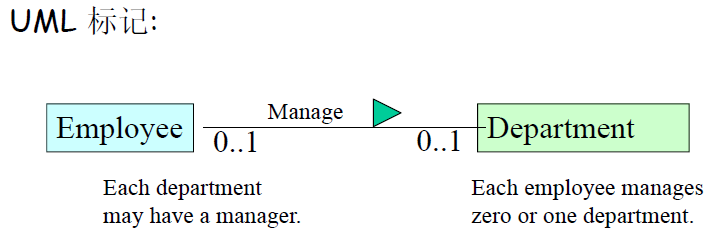
- 一对多关系。
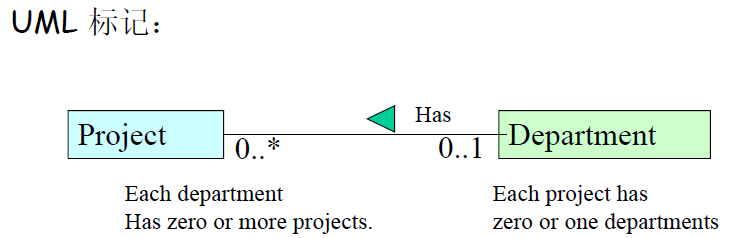
- 多对多关系。
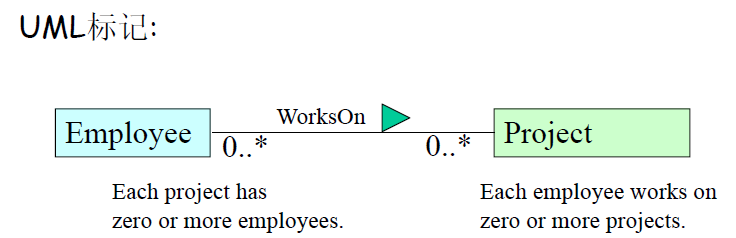
还有多元关系:3个或以上实体之间的关系约束。
建模陷阱
- 扇子陷阱:多个一对多关系混淆实体之间的关系,

解释:一个学院有很多员工、很多项目,那么员工和项目之间是什么关系呢?不清楚!
解决:指明关系即可。
- 裂口陷阱:关系在传递过程中消失,实体间应该存在的关系没有指明。

解释:一个学院有多个项目,一个项目有多个员工参与,那么学院和员工之间是什么关系呢?不清楚!
解决:指明关系即可。
建模实例
大学本科教学管理的业务情况
- 每个学期的教学过程是:老师首先提出开课申请,一个老师可以开一门或者多门课。一门课程也允许有多个老师同时开;
- 然后学生对老师开出的课进行选课, 学生信息有学号,姓名,性别,班级,所在学院;
- 一个学生一个学期可以自由决定是否选课,也可选多门课. 修完一门课后得到一个考试分数,如果考试不及格,可以以后重选、重修。
1、名词法寻找实体
主要是区分哪些名词是实体,哪些只是属性。
在本题中,我们可以快速地找出实体有:学生、老师、课程和学院。
2、动词法寻找关系
老师开课、学生选课、学生重修、学院有学生和老师、学院提供课程。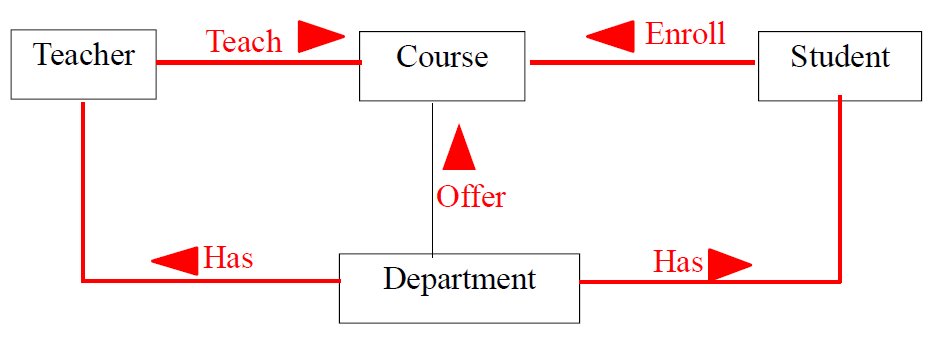
3、名词法寻找属性
学生有学号、姓名、性别、班级、学院,因为学院和学生之间有关系了,所以属性里不需要额外写学院编号。
教师属性也没有显示提示,按照学生属性,模仿一些;再根据实际情况假设一些如 rank 和 email .
课程属性也没有显示提示,根据实际情况,课程编号、课程名称、学时、学分、教材等都可以是它的属性。
学院属性也没有显示提示,根据实际情况,学院编号、学院名称都可以是它的属性。
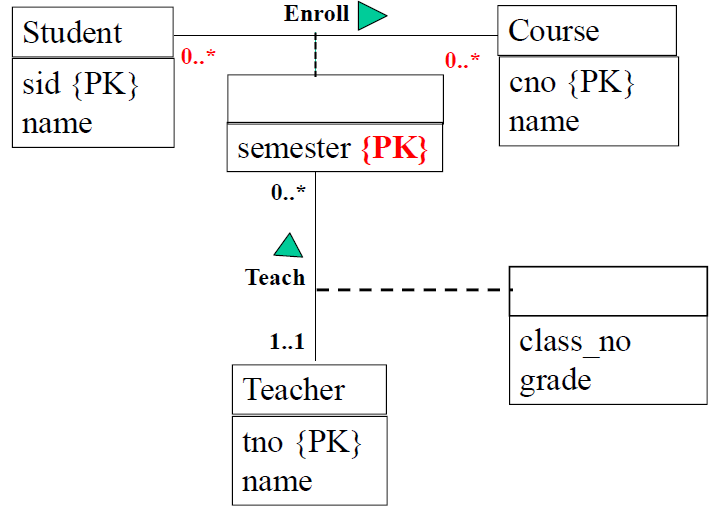
在这里,其实就用到了多对多关系应该弱化成实体的技巧!比如 Teach 和 Enroll 就是多对多关系。
老师开课应该指明在哪个学期为哪个班开的;
学生选课应该指明在哪个学期选的,最后得了多少分。
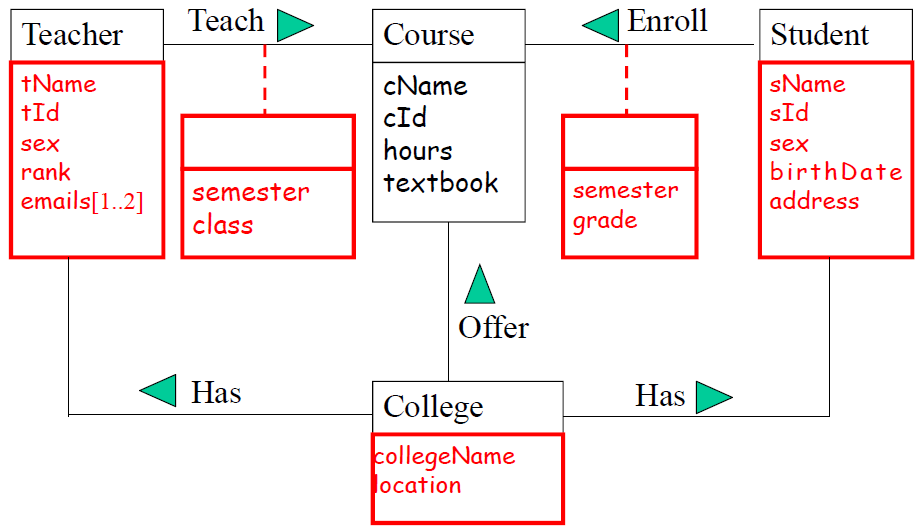
4、实体约束
标识主键,比较简单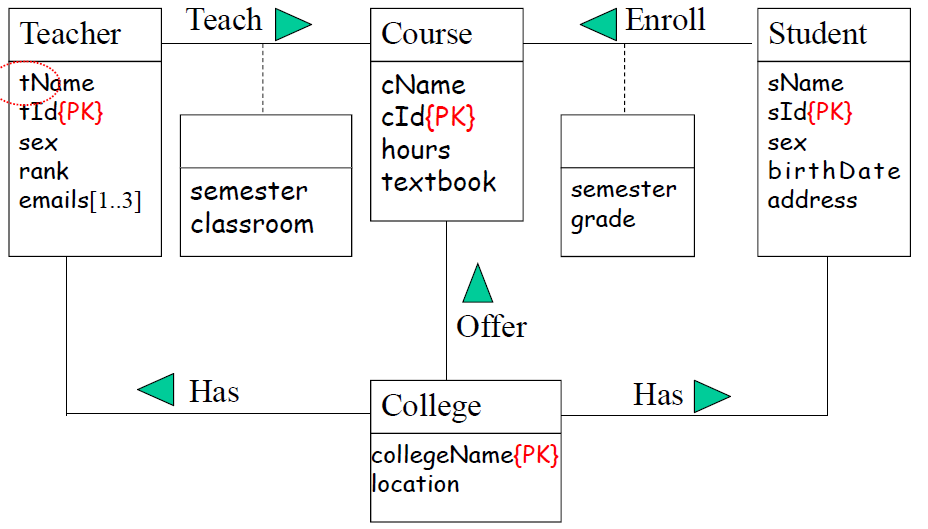
5、标识关系约束
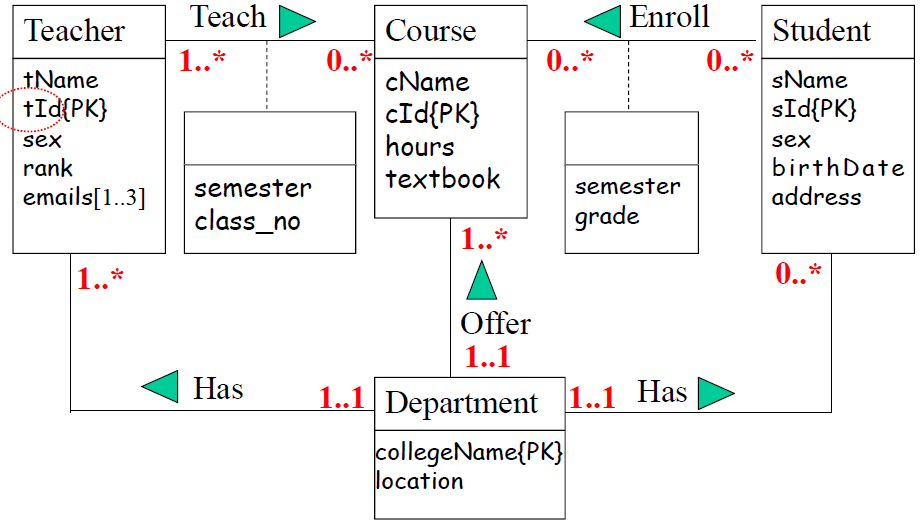
建模技巧
- 多对多关系弱化为一个弱实体。
- 能用属性表达就不要用实体表达。
- 通过关系可以引进的属性不要再写入实体中。
- 将时间和空间抽象成实体。
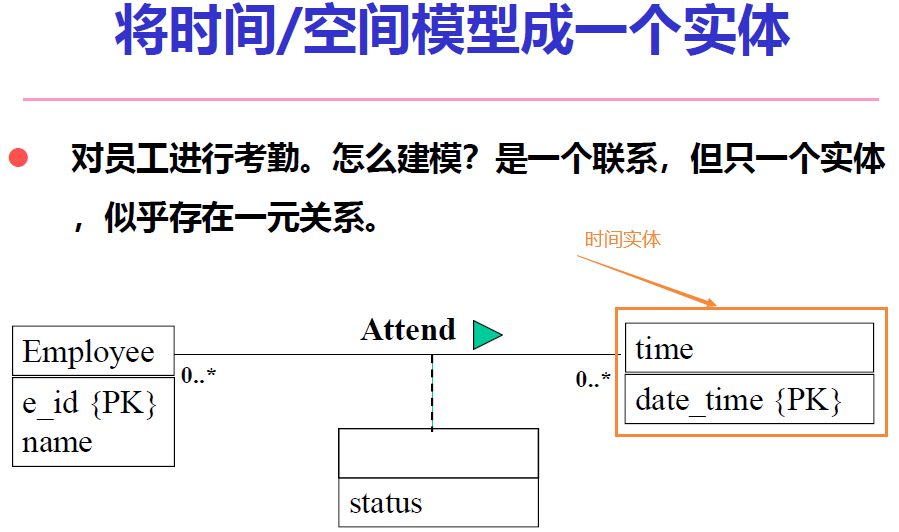
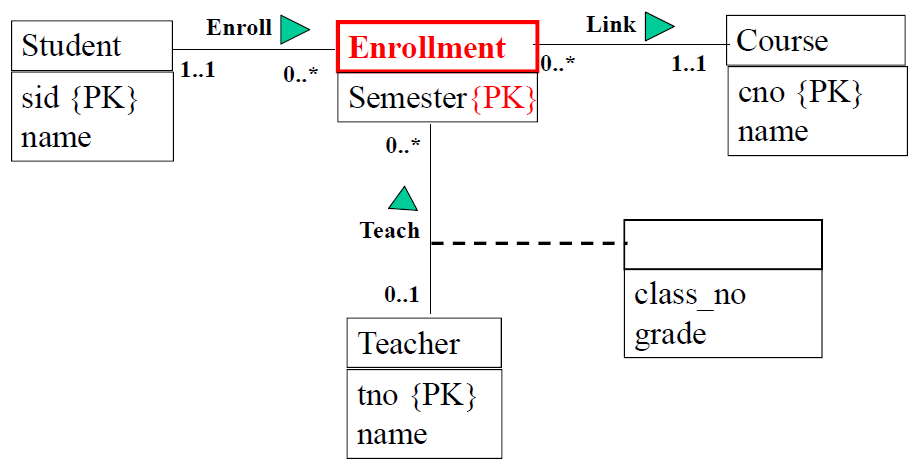
- 当要在多对多的二元联系上再建立联系时,将联系模型化成弱实体。
ER模型转为关系模型
一个关系就是一张表!
- 一个强或弱实体就是一个关系。
- 处理一对一关系,处理方法是外键,不过这个外键放在哪边就要根据实际情况了。
- 比如 teacher(tno{pk}) 和 department(dno{pk}) ,学院有院长是一对一关系。那么这个外键应该放在学院表里,并且应该重命名为 mgrno,如果放在教师表,那么由于很多老师都不是院长,会有很多 NULL 值浪费空间。
- 处理一对多关系。处理方法是外键,把“一”的主键当做“多”的外键。
- 比如学院有老师是一对多的关系,那么应该在教师表里添加一个 dno 字段作为外键。
- 处理多对多关系。处理方法是新增一张表,组合主键 + 外键。
- 处理多元(3元或以上)关系。处理方法是新增一张表,组合主键 + 外键。
- 处理多值属性。处理方法是新增一张表,标明主键。
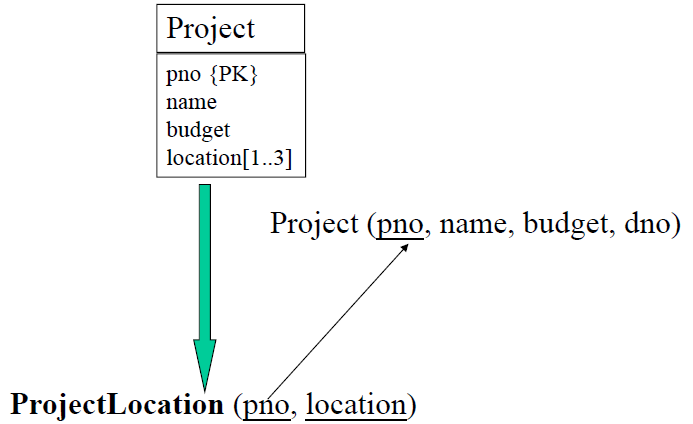
函数依赖理论—合理性验证
函数依赖
对于一个关系 R ,它有属性集 U 和 函数依赖集 F,简写为 R(U, F) .
函数依赖的意义是描述属性与属性之间的依赖关系。比如  表示属性 Y 依赖于属性 X 或属性 X 决定属性 Y .
表示属性 Y 依赖于属性 X 或属性 X 决定属性 Y .
其中 X 和 Y 都可以是单属性也可以是一个属性集合,即 X = (X1, X2, …) 和 Y = (Y1, Y2, …) .
完全依赖于部分依赖
如果左边去掉某一个属性,使得原有依赖仍然成立,那么这个依赖就是部分依赖。
如果左边去掉任何一个属性,原有依赖都不成立了,那么这个依赖就是完全依赖。
比如说  成立,如果去掉左边其中一个属性比如 X,仍然有
成立,如果去掉左边其中一个属性比如 X,仍然有  成立。
成立。
那么 是部分依赖。
是部分依赖。
函数依赖公理

函数依赖的五个应用
- 判断某一个函数依赖
 是否成立。
是否成立。 - 判断某个属性集合 X 是否为候选键。
- 计算函数依赖集 F 的闭包 F+,用于放大函数依赖(推导出所有隐含的函数依赖)。
- 判断两个函数依赖集 F1 和 F2 是否等价。
- 求函数依赖集 F 的最小集(特征集)
求解五个应用的关键技术—求解属性集的闭包
简单的解释闭包:比如某一个属性集 X ,它的闭包为 X+,含义是依赖于属性集 X 的所有属性的集合,依赖类型可以是部份依赖、完全依赖和传递依赖。
例子:已知关系R (A,B,C,D,E,G),函数依赖集合 F = {A → B,C ; C → D ;D → G},计算 {A}+
{A}+ = {A} // 自已依赖自己
= {A, B, C} // 因为 A → B,C
= {A, B, C, D} // 因为 C → D
= {A, B, C, D, G} // 因为 ;D → G
应用一
问题:判断某一个函数依赖 是否成立。
是否成立。
方法:求解 X+,如果  ,那么
,那么 成立。
成立。
证明:根据闭包定义,X+含义是依赖于属性集 X 的所有属性的集合,因此如果 Y 在里面,那么 Y 自然依赖于 X .
例子:无
应用二
问题:判断某个属性集合 X 是否为候选键。
方法:对于 R(U, F),求解 X+,如果 X+ = U,且 X 的任一真子集的闭包都不等于 U,那么 X 是 R 的候选键。
4 种键的定义如下:
- 超键:在关系中能唯一标识元组的属性集称为关系模式的超键。
- 候选键:不含有多余属性的超键称为候选键。
- 主键:用户选作元组标识的一个候选键程序主键。
- 外键:如果关系模式 R1 中的某属性集是另一个关系 R2 的主键,则该属性集是关系模式R1 的外键。
证明:根据超键的定义,因为 X+ = U,所以 X 是超键。又因为 X 的任一真子集的闭包都不等于 U,所以 X 中不含有多余属性,根据候选键的定义,X 是候选键。
推论:若 X 是单属性且 X+ = U,那么 X 必然是候选键,因为它已经没有真子集了。
例子:已知: R = (A,B,C,D), F = {A, B → C ;C → D; D→ A},问(A,B)是R的候选键吗?
解:因为 {A, B}+ = {A, B, C, D}, 所以 (A,B) 是 R 的候选键。
(不要问怎么求闭包了= =!)
应用三
问题:计算函数依赖集 F 的闭包 F+
方法:分类穷举法。对于 R(U, F),求 U 的所有真子集的闭包。
例子:已知R (A,B,C,D) , F = {A → B,C , C → D },求F+
解:
含 1 个属性的闭包:{A}+, {B}+, {C}+, {D}+
含 2 个属性的闭包:{A, B}+, {A, C}+, {A, D}+, {B, C}+, {B, D}+, {C, D}+
含 3 个属性的闭包:{A, B, C}+, {A, B, D}+, {A, C, D}+, {B, C, D}+
含 4 个属性的闭包:{A, B, C, D}+
因为 {A}+ = {A, B, C, D} , {B}+ = {B} , {C}+ = {C, D} , {D}+ = {D}
所以得出新的函数依赖: A → D
因为 {A, B}+, {A, C}+, {A, D}+ ,因为 {A}+ 包含了关系R的所有属性,因此 {A,B}+, {A,C}+, {A,D}+ 都等于 {A}+
所以得出新的函数依赖: A,B → C ; A,B → D ; A,C → B ; A,C → D ;A,D → B ; A,D → C
因为 {B,C}+ = {B,C,D} , {B,D}+ = {B,D} , {C,D}+ = {C,D}
所以得出新的函数依赖: B,C → D
同理 {A,B,C}+, {A,B,D}+, {A,C,D}+ 都等于 {A}+
于是得出新的函数依赖: : A,B,C → D ; A,B,D → C ; A,C,D → B
{B,C,D}+ = {B,C,D} 没有新的函数依赖。
所以 F+ = {A → B,C ; C → D ; A → D ; B,C → D ; A,B → C ; A,B →D ; A,C → B ; A,C → D ; A,D → B ; A,D → C ; A,B,C → D ; A,B,D→C ; A,C,D → B}
应用四
问题:判断两个函数依赖集 F1 和 F2 是否等价。
方法:证明 F1 覆盖 F2 且 F2 覆盖 F1,即互相覆盖。
如何证明 F1 覆盖 F2 :对于 F2 中的每一个函数依赖  对于 F1 都成立,那么 F1 覆盖 F2 .
对于 F1 都成立,那么 F1 覆盖 F2 .
问题转化为:如何判断一个函数依赖是否成立(请参考应用一)
方法:基于 F1 求解 X+,如果  ,那么
,那么 对于 F1 也成立。
对于 F1 也成立。
例子:判断 F = {A → B,C; A → D; C,D → E } 和 G = {A → B,C,E; A → A,B,D; C,D → E }
解:自己求吧,又是求闭包= =!
另外一个判断方法:
F1 和 F2 等价的充分必要条件是 F1+ = F2+
如果你愿意计算 F+ 的话,这也不失为一种方法。
只不过你看一下应用三就知道计算 F+ 多麻烦了= =!
应用五
问题:求函数依赖集 F 的最小集(特征集)
最小集定义如下:
不要问我什么是最小集,我只管怎么求= =!
方法:分解函数依赖 + 去掉多余的函数依赖 + 精炼函数依赖
比如说 F = {A → B,C; A → D; C,D → E }
1、分解函数依赖:根据定义第一点把 F 分解为 F = {A → B; A → C; A → D; C,D → E }
2、去掉多余依赖:
能否去掉 A → B ?假设Fs = F - (A → B) ,基于 Fs 计算 A+ = {A, C} 不包含 B 了,说明不能去掉;
若包含则能够去掉,如果不去掉,说明存在与 F 等价的真子集,与定义矛盾。
对于剩余的每一个函数依赖,都这么判断一次,去掉多余依赖。
3、精炼函数依赖:
针对 C,D → E 这种左边不止一个属性的函数依赖,要考虑能否去掉一些。
其实就是一个左边属性集有传递依赖的问题 。
对于 F 中的 C,D → E,如果在 F 的真子集 Fs = F - (C,D → E) 中能够确定存在传递依赖 C → D,那么就可以原来 F 中的 C,D → E 就可以简化为 C → E
如果不简化,在 Fs 中用 C → E 替换 C,D → E,然后因为 Fs 存在传递依赖 C → D,所以 C,D → E 成立,那么和原来的 F 等价,与定义矛盾。
因为当 C 确定了 D 也就确定了,C 和 D 确定了 E 也就确定了。
范式理论
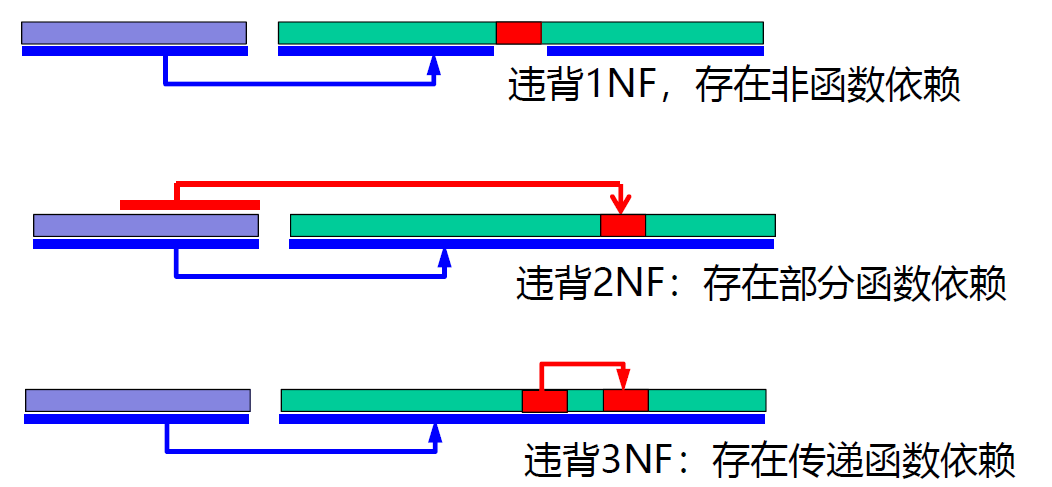
共 6 个范式,每一个范式都是在前一个范式的基础在做更严格的限制,如 2NF = 1NF + 新要求。
对于关系 R(U, F),有多个候选键 K1, K2, …,选定了主键 K
多值属性的意思是,对于一张表里的一行数据(代表一个实例)而言,它的取值有多个,比如一个人的兴趣爱好属性可以有多个取值:篮球、羽毛球等。
| 范式名称 | 理解 | 备注 |
|---|---|---|
| 1NF | 非候选键属性都依赖于候选键 | 不存在多值属性 |
| 2NF | 非主键属性都完全依赖于主键 K | 不能只依赖于 K 的一部分 |
| 3NF | 非主键属性都完全直接依赖于主键 K | 不能通过传递依赖于 K |
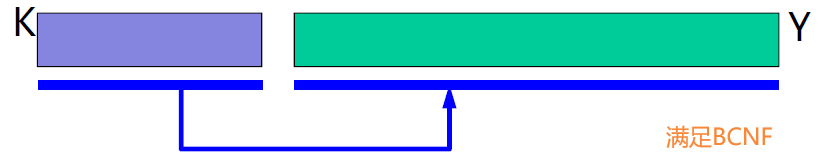
| BCNF | 只能存在非主键属性完全依赖于主键 K | 其他任何依赖都不能有 |
| 4NF | 不允许包含多值依赖 | 避免扇子陷阱 |
| 5NF | 无损联接依赖 | 避免裂口陷阱 |


关系分解
- 若关系 R 存在函数依赖 X → Y 而违背了 2NF,则计算 X+,然后拆分成以下两个关系。
- R1 = X+
- R2 = R - R1 + X
- 若关系 R 违背了 3NF,则把每一个传递依赖Xi→ Yi都拆分出一个关系 Ri,在 R 中只保留 Xi
求所有候选键
对于给定关系模式 R(U, F),U = (A1, A2, …) ,将它的属性分为四类。
L 类:只出现在 F 左边的属性。
R 类:只出现在 F 右边的属性。
LR 类:在 F 左右两边都出现的属性。
N 类:在 F 中从未出现的属性。
定理1:L 类的属性必定是任一候选键的成员属性。
证明:只出现在 F 左边的属性必定被其他属性依赖且不会依赖于其他属性。
推论1:若属性 X 是 L 类的属性且 X+ = U,那么 X 是 R 的唯一候选键。
定理2:R 类的属性必定不是任一候选键的成员属性。
证明:只出现在 F 右边的属性必定依赖于其他属性而不能决定其他属性。
定理3:N 类的属性必定是任一候选键的成员属性。
证明:不决定其他属性也不依赖于其他属性,那么它只能自己依赖自己。
例子:已知关系R(A, B, C, D, E, F, G, H, I, J) ,函数依赖集F={ A,B → C ; A → D, E ; B → F ; F → G,H ; D → I, J }
1、求出R的候选键;
2、把R分解成第二范式和第三范式.
解:将属性分类:
L 类属性:A, B
R 类属性:C, E, G, H, I, J
LR 类属性:D, F
N 类属性:无
(1)
根据定理1,A, B都必然是候选键的成员属性,因此先求 {A, B}+ = {A, B, C, D, E, F, G, H, I, J},所以 (A, B) 是一个候选键。
根据推论1,(A, B) 是唯一候选键。
(2)
(A, D, E)
(D, I , J)
(A, B, C, F)
(F, G, H)
前沿数据库技术
NoSQL
Not Only SQL 的简称,意思是关系型数据库在许多特定的应用场景下有很多缺点,NoSQL 提供了更好的解决方案,当下 NoSQL 共分为 4 大类,分别针对于关系型数据库的在特定的应用场景下的 4 个缺点。
| 类型 | 代表 | 解决的问题 | 特点 |
|---|---|---|---|
| K-V存储数据库 | Redis | 关系型数据库以行为单位存储数据,在范式的约束下不能很好地不能存储数据结构。 | 能够存储数据结构,通过哈希查询性能好。 |
| 文档型数据库 | MogoDB | 关系型数据库强 schema 约束,许多数据类型不能存储。 | 没有 schema 约束,采用类似JSON格式存储,够存储任何类型的数据,不支持事务。 |
| 列式存储数据库 | Hbase | 关系型数据库以行为单位读取数据,但是大数据下经常只需要读取列。 | 按列读取数据和查询性能好,减少磁盘I/O. |
| 全文搜索引擎 | Elasticsearch | 关系型数据库的全文搜索能力很低,尤其是搜索条件多的时候,LIKE 模糊查询需要扫描整张表。 | 根据倒排索引原理,建立关键字到文档的索引,大大提高全文搜索能力。 |
分布式数据库
分布式数据库的意思是,多台数据库服务器上的 DBMS 通过网络协作对外提供服务,在用户看起来好像只有一台数据库服务器。
产生原因:
- 数据量太大,一张表有千万甚至上亿行,需要进行对表进行分割。
- 单台服务器压力太大,承受了太多请求,需要多台服务器分担压力。
作用:
- 提高数据处理性能。
- 实现信息资源共享。
- 提高数据容错率。
- 实现数据操作的简单性。
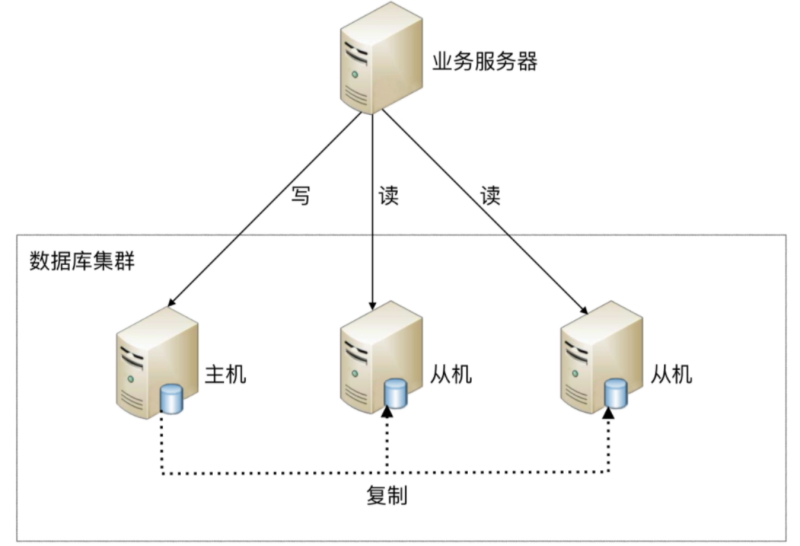
读写分离
采用主从架构,将读写操作分散到多个服务器上。主机可读可写,从机只读,这样可以分散访问的压力,但不能降低存储的压力,反而因为主从复制加大了存储的压力。
分表
- 垂直分表:将一张表中不常用的、占空间大的列拆分出去,提供访问常用数据的性能,减少磁盘I/O.
- 水平分表:单表行数过多,导致查询性能低,根据适当的策略把一部分行拆分出去,复杂度主要来源于分表之后的路由,即如何在多张表中定位到所要的行。
对象-关系型数据库
在关系型数据库的基础上扩展数据类型。
- 根据面向对象原理定义对象数据类型,即类。
- 给类的定义构造函数、成员函数。
- 创建类的实例。
- 类可继承。
数据仓库
将来自多个数据源的数据,以统一的模式,集中存储在某个站点上,用于信息提取、数据分析、数据挖掘等,它的特征是海量历史数据,数据只添加、只读,不修改。
信息提取
对 Internet 上无结构的文本数据进行查找。
数据分析
对数据进行统计分析,找出特征规律。
信息挖掘
从大量数据中发现隐藏的特征模式,为决策作支撑。
数据库安全
在数据库安全方面,三道防线是基础,还要防止许多恶意攻击如:SQL注入攻击、HTML注入攻击(XSS攻击),网站认证要从账号、手机验证码和U盾三个方面做验证,数据传输要加密。

若有收获,就点个赞吧
0 人点赞
