主题
pytorch 学习与实践
问题描述
一个简单的回归问题,输入是 100 组数据,每组数据有 1000 个特征;输出也是 100 组数据,但只需要 10 个特征。
问题分析
根据输入特征和输出特征数量,输入层节点和输出层节点个数应该分别是 1000 和 10 个。假设只设置一个隐藏层,节点个数为 n,网络结构如下图所示: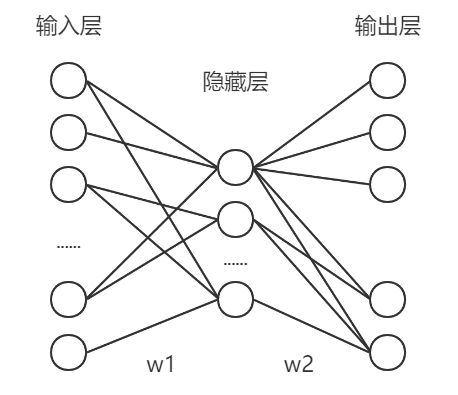
由此可知,
设置超参数:
- 训练次数:epochn = 10000,训练一万次。
- 学习效率:0.000001
损失函数的定义: ,即预测输出与样本值差值的平方。
,即预测输出与样本值差值的平方。
我们的目标就是探索一个适当的 n 的值,使得损失最小。
代码如下:
# a simple regression problem# x is input, including 100 datas, each data has 1000 features# y is output, including 100 datas, each data has 10 features# thus, 1000 nodes for input layer and 10 nodes for output layer# presume only 1 hidden layer with n nodesimport torchdef main():# define input and output, no need tracing gradx = torch.randn(100, 1000, requires_grad=False)y = torch.randn(100, 10, requires_grad=False)# assume n is 100# define weight matrix, need tracing gradw1 = torch.randn(1000, 100, requires_grad=True)w2 = torch.randn(100, 10, requires_grad=True)# define hyper parametersepoch_n = 10000learn_rate = 1e-6# trainfor epoch in range(epoch_n):# forwardh1 = x.mm(w1).clamp(min=0)y_pred = h1.mm(w2)# backwardloss = (y_pred - y).pow(2).sum()loss.backward()# updatewith torch.no_grad():w1 -= learn_rate * w1.gradw2 -= learn_rate * w2.gradw1.grad.zero_()w2.grad.zero_()print(epoch, "-loss:", loss.item())if __name__ == '__main__':main()
关于隐藏层节点个数的设置,没有什么科学依据,都是凭借一些经验,比如:

其中:
 是输入层神经元个数;
是输入层神经元个数; 是输出层神经元个数;
是输出层神经元个数; 是训练集的样本数;
是训练集的样本数;
α 是可以自取的任意值变量,通常范围可取 2-10。隐藏神经元的数量应在输入层的大小和输出层的大小之间。
- 隐藏神经元的数量应为输入层大小的2/3加上输出层大小的2/3。
- 隐藏神经元的数量应小于输入层大小的两倍。
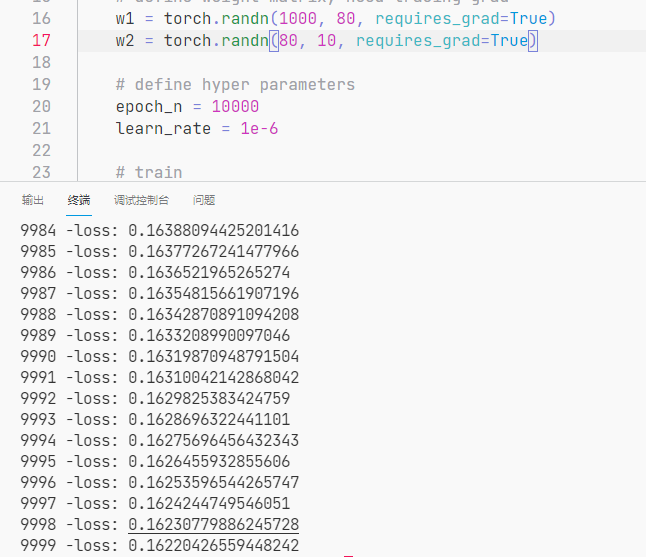
在该问题中,经过反复试验,发现 n = 80 时网络收敛得较快且损失也较小。
- n = 100 时,loss 为 2.86
- n = 80 时,loss 为 0.16

若有收获,就点个赞吧
0 人点赞
