有的时候,在业务高峰期,Mysql可能会出现
如果我们把Mysql的客户端和服务器之间建立的连接设置为短连接的话,那么这个连接会在执行少量的sql语句就断开,然后在执行新的sql语句的时候再重新建立连接,这是因为sql语句的执行在时间上不是连续的,在每次执行少量的sql语句之间有着时间间隔。
在第一个文档中提到过,Mysql建立连接的成本是很高的,除了要进行三次握手之外,还要去验证客户端是否有权限与服务器建立连接,以及这个连接具有对哪些数据库,哪些表的读写权限。
当业务不繁忙时,也就是说同时与Mysql服务器建立连接的客户端的数目并不多时,这些建立连接的成本可以忽略不计。
但是这种工作模式有一个缺点,如果一个sql语句执行的慢一点了,那么这个sql语句所在的连接的存在时间就会变长,在这个连接延长的存活时间里,同时存在的连接的数目就会比正常情况多一个,如果同时有很多个sql语句执行的慢了,在这些sql语句延长的存活时间的交集里,就会增加一定量的同时存在的连接的数目,再加上更活跃的建立新连接的请求,那么同时存在的连接的数目就会显著增加。
那么什么时候会出现很多个sql语句执行变慢呢?
当同时与Mysql服务器建立连接的客户端的数目增多时,也就是业务繁忙时,sql语句的执行时间就会普遍变长。
所以当业务繁忙时,很容易就会出现同时存在的连接数显著增加的现象。
在Mysql中存在一个叫做最大连接数max_connections的参数,这个参数决定了在Mysql数据库中能够同时存在的连接的最大数目。当同时存在的连接数达到了这个参数的值,那么之后的建立连接的请求就会被拒绝,并且会在客户端报错”太多的连接了”(too many connections)。
对于被拒绝建立连接的请求来说,这个Mysql数据库就是不可用的。
那么什么时候同时存在的连接的数目会超过max_connections参数的限制呢?
当同时与Mysql服务器建立连接的客户端的数目增多时,也就是业务压力变大时,sql语句的执行时间就会变长,sql语句所在连接的存活时间就会变长,那么同时存在的连接的数目就会增加,再加上建立新连接的请求变多,就有可能会超过max_connections参数的限制。
那么怎么解决这种问题呢?
最直接的办法就是调高max_connections参数的值,但是这种做法是不合理的,因为Mysql设计这个参数的目的就是防止有太多的连接同时连上Mysql数据库,从而避免Mysql把大量的资源都耗费在三次握手,验证权限上,甚至会导致已经建立的连接拿不到cpu资源去执行具体的sql语句。
那么我们还有别的办法来解决这个问题吗?还有别的办法,但是下面的办法都是有缺陷的。
max_connections的值,记录的是建立的连接的数目,有的建立的连接即使并没有在执行sql语句,也会占用一个计数的位置,所以我们可以使用kill connection命令来主动断开这些连接,我们通过设置wait_timeout参数可以达到相同的效果,wait_timeout参数的作用是当一个连接空闲wait_timeout这么多秒之后,就会被Mysql断开连接。
但是踢掉show processlist结果中状态为sleep的线程,是会对我们的业务造成影响的,踢掉这个线程指的是断开这个线程所在的连接。
在这个例子里,如果我们断开会话A所在的连接,因为事务A并没有被提交,所以事务A会被回滚,而断开会话B所在的连接,则没有任何影响,所以我们更应该优先断开会话B这种在事务外空闲的连接。
那么怎么判断哪些连接是事务外空闲的呢?什么叫空闲的连接?空闲的连接就是指在会话C执行show processlist;命令时没有在执行sql语句的连接。
会话C执行show processlist;的结果如下。
图中id=4和id=5的数据行的命令选项的值都是sleep,那么怎么知道这两个数据行对应的线程在执行show processlist;命令时是位于事务中还是事务外呢?线程和连接是什么关系?我们可以从information_schema库的innodb_trx表中查到。这个表是什么样子呢?为什么从这个表的查询结果是这么一个格式?查询语句最后的\G是什么意思呢?
查询结果如下。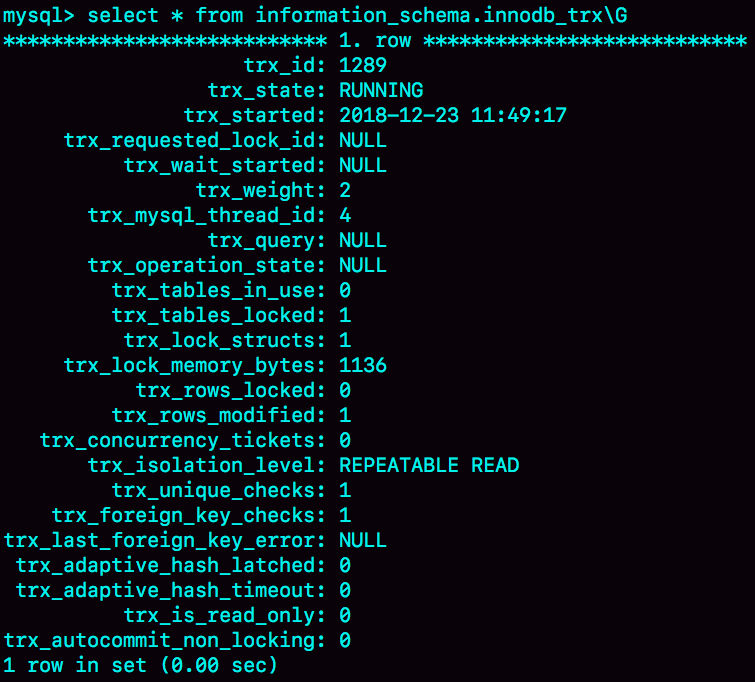
查询结果中的每一项是什么意思呢?
从informaton_schema库的innodb_trx表中就可以查到线程是处在事务中还是事务外了。在查询结果中我们能够看到一个字段叫trx_mysql_thread_id,这个字段的值就代表着id等于这个值的数据行对应的线程此时正在执行事务,所以在这个例子里,trx_mysql_thread_id=4,这就代表着id=4的数据行对应的线程此时正在执行事务,所以,当我们发现Mysql数据库建立的连接数太多的时候,那么我们就可以去断开那些在事务外空闲的连接,如果连接还是不够用的,那么就去断开在事务内空闲的连接。
知道了可以断开哪些连接,那么怎么断开这些连接呢?
除了断开连接的方法来解决同时建立的连接数过多的问题,还有别的办法吗?
有的业务代码会在短时间内建立大量的连接为下一步的工作做准备,比如说建立了一个很大的连接池,如果我们确定是因为同时建立的连接数过多导致Mysql不能正常工作了,那么我们可以让数据库跳过权限验证阶段,
那么怎么让数据库跳过权限验证阶段呢?我们只需要使用-skip-grant-tables参数来重启数据库就可以了,如果我们这么启动了Mysql数据库的话,Mysql就会跳过所有的权限验证阶段,不管是建立连接的权限验证,不是所有的客户端都可以建立连接的,还是对库或者表的操作权限验证,所有人都有权限对所有的库和表进行操作,这显然是很危险的,特别是当你的数据库可以被外网访问时,就更危险了。
在建立连接的时候,是需要输入账号的,账号密码不对是不能建立连接的,即使建立连接了,每个账号的权限也是不一样的,如果我们让数据库跳过了权限验证阶段,那么即使账号密码不对也能建立连接了,这个连接对所有库和表中的数据也能够修改了。
在Mysql8.0版本中,如果我们使用-skip-grant-tables参数来启动数据库的话,那么Mysql就会默认把—skip-networking参数打开,意思是此时数据库只能与本地的客户端建立连接,只能与本地的客户端建立连接指的是只能和同一台电脑上的客户端建立连接。
有哪些导致慢查询的情况呢?
第一种情况就是没有设计好索引,没有设计好索引就可能会出现在业务高峰期,数据库被某个语句打挂的场景,这种情况就是紧急创建新的索引来解决,怎么创建新的索引?如果只有一个主库的话,使用alter table语句就可以了,而且现在Mysql支持Online DDL创建索引了,支持Online DDL的意思是在执行alter table语句的同时可以执行增删改查语句,对业务造成的影响会更小。
如果是Mysql使用了主备模式的话,最好按照下面这个流程来做。假设现在有两个Mysql数据库,一个主库A一个备库B,我们先在备库B上执行set sql_log_bin=off语句,这个语句的作用是让备库B停止向binlog文件中写入内容,然后再执行alter table语句给表加上索引,接着执行主备切换,在主备切换完成之后,同样在A上执行set sql_log_bin=off语句,再执行alter table语句给A中的表加上索引。
那么为什么要先让数据库停止向binlog文件中写入内容呢?
按照这个流程可以一边创建索引一边进行增删改查吗?
这么做的优缺点是什么呢?
语句没写好也会导致慢查询,如果我们犯了之前提到的会导致语句无法使用索引的错误,也会导致查询变慢。那么我们可以怎么解决这个问题呢?
比如语句被错误的写成了select * from t where id+1=10000,那么我们就可以插入一个语句改写规则,如下所示,所有满足指定模式的sql语句都会被改写成另一种模式。
mysql> insert into query_rewrite.rewrite_rules(pattern, replacement, pattern_database) values ("select * from t where id + 1 = ?", "select * from t where id = ? - 1", "db1");call query_rewrite.flush_rewrite_rules();
只有调用了query_rewrite的flush_rewrite_rules()存储过程,query_rewrite是什么?flush_rewrite_rules又是什么?插入的新规则才会生效,那么我们怎么知道新规则有没有生效呢?
通过show warnings;语句可以看到。
为什么我们不直接去改sql语句呢?因为sql语句是在业务代码里的,运维是没有权限改动业务代码的,插入语句改写规则的权限应该也没有,如果直接改sql语句的话,整个业务系统需要先下线,改动sql语句,再重新上线吧。但是为了改一条sql语句把一个业务系统完全下线我觉得也是不可能的,一个合理的做法是下线一部分,改动sql语句,把这部分重新上线,再改动另外一部分。
如果Mysql选错了索引的话,也会导致查询变慢。应急方案就是给这个语句加上force index,怎么加上force index,同样可以用插入语句改写规则的办法,也可以直接在语句中加入force index,做法就是像上面说的那样。
在实际遇到的慢查询情况中,最常出现的情形是前两种,也就是没设计好索引和写错了语句。没设计好索引指的是该创建的索引没有创建。而这两种情形,我们都是可以在业务系统上线之前避免的。通过下面的过程,我们可以在业务还没上线时就发现问题。
上线前,在测试环境,先把慢查询日志打开,把长查询的时间设置为0,确保每个语句都会被记录到慢查询日志中,在测试表中插入线上的模拟数据,测试表指的是用于测试的表,在测试完会把测试表删掉吗?应该不用吧,在测试环境和生产环境能看到的表应该是不一样的,然后观察慢查询日志中每个语句的执行信息,特别去关注rows_examined字段的值,这个值是不是与预期是一致的。
这个过程是很有必要的,会大大减少线上出现问题的概率,也节省了我们对问题进行复盘的时间。
如果新增的sql语句不多,那么手动跑一下就可以了,如果是在新项目上线之前,或者是修改了项目中的表结构,这种情况都是需要进行全量回归测试的,全量回归测试是什么?暂时的理解是对所有的sql语句都进行测试,测试什么?测试实际的扫描行数是否与预期一致。
有的时候某个业务的访问量突然增加了,或者是这个业务代码出现bug了,都可能导致某个语句的qps突然暴涨,qps是什么?qps指的是服务器每秒的响应次数,某个语句的qps太高,可能就会导致整个Mysql实例的压力过大,进而影响到其它sql语句的执行。
如果是由于程序bug导致的qps暴涨,那么我们最好是先把这个功能下掉,那么从数据库的角度怎么下掉一个功能呢?
如果是一个新业务中的bug,
如果这个新功能使用的是独立的数据库用户,那么我们可以直接用管理员账户把这个用户删掉,然后断开这个新功能已经建立的所有连接,这样做的话,这个新功能就没办法建立起新的连接,那么这个新功能中的sql语句的qps就降为0。
如果这个新增的功能和主体功能使用的数据库用户是一个,那么我们可以使用上面提到的插入改写语句规则的方式把qps最高的sql语句改写为”select 1”语句。
这么做的风险很高,它有两个副作用,第一个副作用是如果在别的功能里也用到了相同的sql语句模板,就会被误伤,大部分业务都不是只依靠一个sql语句来完成完整的逻辑的,而是分为若干个sql语句来进行,如果我们把某个语句直接改为select 1语句来返回结果的话,后面的业务逻辑可能也没办法正常执行。
最后一个方案是没办法的办法,和前面去掉权限验证一样,别的办法不能解决问题时才会这么做。

若有收获,就点个赞吧
0 人点赞
