在有的场景中,会需要计算一张表的总行数,这个时候我们可以简单的使用select count() from t就可以实现我们的需求。
但是随着这张表的行数越来越多,执行这个查询语句的时间就会越来越长,那么Mysql为什么不把总行数记录在某个参数上,然后在执行select count() from t语句的时候直接返回这个参数的值不就行了吗?如果Mysql采用了这种方式来实现select count() from t语句,那么即使这张表包含了很多行,也只需要o(1)的时间复杂度就可以获得这张表的总行数。
对于不同的存储引擎来说,执行select count() from t语句会经过不同的过程,Myisam存储引擎采用的做法就是把表的总行数记录在某个参数中,然后在执行select count() from t语句时直接返回这个参数的值,而Innodb存储引擎采用的做法是把表中的每行数据都读出来,然后判断每行数据对当前会话的可见性,可见行的数目才是select count() from t语句的执行结果。
为什么Innodb存储引擎不采用和Myisam一致的实现方式呢?如果采用和Myisam相同的方式来实现select count() from t语句,就不会由于表中数据行的不断增多从而计算一张表的总行数越来越慢。
既然Innodb存储引擎采用了有缺陷的实现方法而没有选择执行速度更快的实现方式,这就说明Innodb存储引擎不能采用第二种执行速度更快的实现方式。为什么Innodb存储引擎不能采用把表的总行数记录在某个参数中的方式来实现呢?
假设现在表t中有10000条记录,我们开启了三个会话,
会话A在开启事务后立马执行了一次计数语句,会话B在开启事务后先插入了一行数据,此时并没有提交事务,会话C在一个事务中插入了一行数据,然后会话A和会话B在同一时刻执行了计数语句,会话C在同一时刻在一个事务中执行了计数语句。为什么会话A、B、C中的计数语句的执行结果分别是10000、10002、10001呢?用MVCC来分析一下。
如果Innodb存储引擎采用的实现方式是返回记录了表的总行数的参数的值,那么由于三个计数语句是在同一时刻执行的,那么这三个计数语句的执行结果应该是同一时刻的参数值,也就是说三个计数语句的查询结果应该是一致的,但是三个计数语句的查询结果一致是不合理的,因为同一个数据行对不同会话的可见性是不一样的,每个会话能够看到的行数确实是不一样的,所以不能用返回参数值的方式来实现计数语句。所以把每行数据都读取出来,判断每一行对会话的可见性,从而决定每个会话执行计数语句的查询结果,这种实现思路才是合理的。
那么Mysql是从哪儿读取每一行的数据来判断可见性的呢?在主键索引树的叶子节点中包含了所有的数据,而普通索引树的叶子节点中只有主键值,所以一个数据页中能够放得下更多的普通索引树的叶子节点,而叶子节点的数目是相同的,所以如果我们从普通索引树来读取数据的话,只需要从磁盘上读取更少的数据页,节省了计数语句的执行时间。普通索引树的叶子节点中应该也记录了隐藏字段的值,要不然没办法判断每一行的可见性。
除了使用计数语句还有别的获取表的行数的方法吗?还可以通过show table status命令来获取,而且这个命令的执行速度很快,当我们使用show table status时,我们能够看到在这个命令的执行结果中有一个叫做table_rows的字段,这个字段的值记录的是表的行数吗?这个字段的值记录的是表行数的估算值,而不是精确值,并且这个估算值经常误差很大,甚至能达到40~50%,所以不能用table_rows字段的值来代替计数语句的执行结果。
根据上面的分析过程,我们知道有三种获取表的总行数的方法,基于Myisam存储引擎的数据表可以快速获取表的总行数,但是由于Myisam存储引擎不支持事务,所以我们不常用,虽然show table status命令的执行速度很快,但是执行结果中的table_rows字段的值和表行数的真实值误差较大,Innodb存储引擎会读取表中的每一个数据行,并且判断每一个数据行对于当前会话的可见性,计数语句最终返回的结果是可见数据行的数量。与show table status命令相比,虽然按照这个过程获取表的总行数得到的结果更准确,但是这个过程会消耗更多的时间,并且这个过程的执行时间会随着表中数据的增加而增加。
那么如果现在有一个页面,在这个页面上需要动态显示某个表的总行数。那么我们怎么实现这个功能最合适呢?如果在每次显示表的总行数的时候都去执行一次select count() from t语句,这显然不会是一个好的选择。因为随着表中的数据行越来越多,这个语句执行的速度就会越来越慢,每次显示之间间隔的时间就会越久。
那么我们可以怎么实现呢?一个很质朴的想法是使用缓存,我们可以使用redis来保存表的总行数,表中每插入一行我们就给redis中记录总行数的变量加上1,表中每删除一行我们就给redis中记录总行数的变量减去1,如果这样实现的话,不管是从redis中读取表的总行数还是在表的总行数发生变化时更新redis中的变量值都很快,但是这样实现的缺点是什么呢?可能会丢失数据,因为redis是把数据保存在内存中的,如果主机发生了断电,保存在内存中的数据都会被丢失,所以redis提供了持久化的机制把内存中的数据保存到硬盘上,但是持久化机制同样存在局限性,假如我们刚向表中插入一个数据行,并且给redis中记录总行数的变量加上了1,这时主机突然断电了,但是还没来得及持久化最新的数据,如果我们根据在过去某个时刻持久化的RDB文件来恢复数据的话,此时redis中的记录表总行数的变量的值是不准确的,但是这个问题很容易被解决,redis中记录总行数的变量我们可以不通过RDB文件来恢复,而是重新在Mysql中执行select count() from t语句获取最新的表的总行数并且记录在redis中,由于在redis中恢复内存中的数据发生的并不频繁,所以只是偶尔的执行计数语句还是可以接受的。
但是使用缓存来记录表中的总行数还存在其它的问题,假如说在页面上我们不仅仅要显示表的总行数,还要显示表中最新的100条数据,假如我们在业务中写的是先从缓存中获取表的总行数,然后再从表中取出最新的100条数据,那么会发生什么呢?
如果按照这个时序图来执行语句,那么会发生什么呢?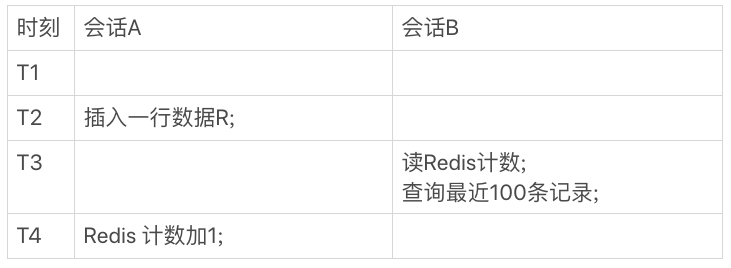
在会话A执行的是插入一行数据,redis中变量加1的逻辑,在会话B中执行的是将要在页面上显示的信息的查询语句,如果按照上图所示的时序来执行这些语句的话,那么在T3时刻会话B执行查询最近100条记录时就会显示会话A在T2时刻插入的数据,但是此时redis中记录的表的总行数还没有加上1,也就是说在T3时刻从redis读取到的表的总行数和查询到的最近的100条记录是不匹配的。
也许你可能会觉得,是因为在会话A中是先插入数据行再给redis中变量加上1,而在会话B中是先读取redis中变量的值,然后再查询表中最近的100条记录,是因为在两个会话中操作redis和Mysql的顺序不一致才导致的不匹配,那么我们换一个时序来执行这四条语句呢?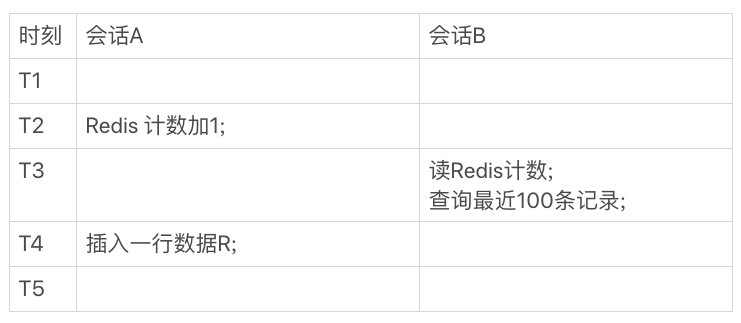
如果按照上图的时序来执行图中的语句,那么在T3时刻会话B从redis中读取到的记录表的总行数中包含了最新插入的数据行所贡献的1,但是从Mysql查询到的最近的100条记录中却没有最新插入的数据行,同样出现了数据不匹配的问题。出现这种问题的原因在于可见性的问题,只要不同会话之间能够立马看到别的会话所做的修改,就会出现这种问题。只要存在某种时序使得数据出现不一致,我们就说这个设计是不安全的。
从上面的分析我们知道了,如果使用缓存来记录表的总行数有丢失数据和数据不一致的问题,那么如果我们使用Mysql中的一张单独的表来记录表的总行数怎么样呢?
现在我们使用一张单独的表来记录表的总行数,这张表中第一条记录的值是通过计数语句来获取的,如果向原有的表中插入一条数据,我们就需要向新的行数表中插入一条值为第一条记录中的值加1的记录。如果这时Mysql突然崩溃了,那么数据会丢失吗?并不会,因为Mysql实现了持久性,数据只要成功插入到数据库中就不会因为崩溃而丢失,也就是说如果我们使用单独的表来记录表的总行数就不需要担心丢失数据的问题了,但是仍然有可能出现数据不一致的问题,比如在向原有的表中插入一条数据后,向新的行数表中插入数据之前,Mysql出现了问题,两张表中的数据就出现了不一致。
那么我们可以解决这个问题吗?解决这个问题很简单,只需要把两条sql语句放在同一个事务中就可以了,因为Mysql中的事务实现了原子性,在同一个事务中的不同sql语句要么都执行,要么都不被执行,从而保证两张表中数据的一致性。
那么还会存在读取到的表的总行数和查询到的100个最新数据行不匹配的问题吗?如果不使用事务还会存在这个问题,而我们使用事务就可以解决数据不匹配的问题。那么怎么用事务解决这个问题呢?
我们只需要把向原有表插入数据的sql语句和向行数表插入新记录的sql语句放在同一个事务中,把从行数表查询表的总行数的sql语句和从原有表中查询100条最新的数据的sql语句放在同一个事务中,如下图所示,就可以解决数据不匹配的问题,为什么这样做可以解决数据不匹配的问题呢?这是因为在可重复读隔离级别下在一个事务提交之前,它所做的修改别的事务是看不到的。
那么即使在T2时刻会话A在表C中计数值加了1,由于会话A中的事务还没有提交,所以会话B在读取表C中的计数值时,仍然是在插入最新的数据行之前的总行数,此时在会话B中执行查询最近100条记录的语句,查询到的100条语句中也不包括最新的数据行,因为最新的数据行此时还没有被插入到表C中,很显然此时会话B中查询到的数据是一致的,表C的计数值中不包括最新的数据行,查询到的最近的100条记录中也不包括最新的数据行,这里指的最新的数据行指的是T4时刻插入的数据行。
在会话A和会话B中都使用事务可以解决数据不一致的问题,那么如果我们只在会话A中使用事务,在会话B中不使用事务会发生什么呢?可以解决数据不一致的问题吗?
count()、count(1)、count(主键)、count(字段)哪个语句执行的最快?
想要回答这个问题,首先要弄清楚count()函数是怎么工作的。存储引擎把满足语句条件的数据行放到结果集中,然后把结果集返回给server层,server层会对结果集中的每一个数据行进行判断,怎么判断呢?把每一个数据行中的数据作为参数传给count()函数,如果count()函数的参数不是null,就把计数变量的值加1,如果是count()函数的参数是null,那么计数变量的值不变,在判断完结果集中的所有数据行后,给客户端返回计数变量的值。
这里结果集中的数据行并不是包含全部信息的数据行,在一个数据行中只有一项数据,比如当我们执行的是count(主键)时,在每个数据行中只有一项主键的值,如果我们执行的是count(1),那么每个数据行中的数据都是一项1。

若有收获,就点个赞吧
0 人点赞
