假设有这么一张表,我们在字段a,b上分别建立了索引,建表语句如下:
CREATE TABLE `t` (`id` int(11) NOT NULL AUTO_INCREMENT,`a` int(11) DEFAULT NULL,`b` int(11) DEFAULT NULL,PRIMARY KEY (`id`),KEY `a` (`a`),KEY `b` (`b`)) ENGINE=InnoDB;
然后,向表中插入10万条数据,每个数据行的内容为(1,1,1),(2,2,2),...,(100000,100000,100000)。<br />假如说现在我们要执行这么一个语句,那么Mysql会走哪个索引呢?
select * from t where a between 10000 and 20000;
如果我们用explain命令来看这条语句会走哪个索引的话,可以看到是走字段a上的索引的。explain命令执行结果如图所示。<br /><br />这个语句走的是字段a上的索引是符合我们预期的,那么现在考虑这么一个场景,现在有两个会话,session A和session B,在这两个会话中分别在不同的时机执行下图中的语句,<br /><br />session A所做的事情很简单,就是开启一个事务,并且拿到的是在开启事务时刻的一致性视图,然后提交事务,在session B中会先删除表t中的数据,然后重新向表t中插入数据,然后再用explain命令来看之前的查询语句会走哪个索引。<br />根据explain的执行结果我们可以看到此时该查询语句就不会走字段a上的索引了。<br />那么在这个场景下这个查询语句的执行过程是什么样的呢?我们可以通过慢查询日志来观察并分析,怎么通过慢查询日志来分析呢?首先把慢查询日志的阈值时间设置为0s,从而确保这个查询语句会被记录在慢查询日志中,那么从慢查询日志中我们可以看到什么呢?<br />从慢查询日志的rows-examined字段的值可以得知Mysql在执行该查询语句时扫描了多少行数据,从下图的慢查询日志中可以看到在执行该查询语句时扫描了10w行,也就是说在执行该语句时进行了全表扫描,并且执行了40ms,当我们强制Mysql的执行器使用字段a上的索引来执行时,就只需要扫描10001行,并且只需要执行21ms,也就是说Mysql自己选择使用的索引并不是性能最优的,这种情况我们称作选错了索引,那么为什么会出现这种情况呢?扫描了多少行数据到底是什么意思?examined是什么意思?<br />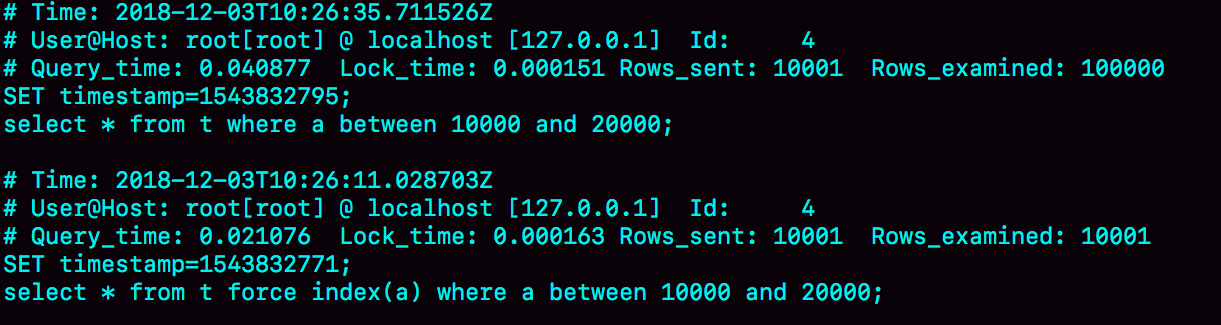<br />这个场景并不特殊,甚至在实际应用场景中出现的很频繁,在实际场景中我们经常需要删除一些无用的数据,并且插入一些新增的数据,所以弄清楚在这种场景下选错索引的原因很有必要。<br />之前说过,选择走哪个索引,执行哪个方案是由优化器来确定的,执行器负责的是具体的执行,优化器会选择执行方案中代价最小的方案并交给执行器来执行,在Mysql中,扫描行数是影响执行方案选择的因素之一,当然影响因素并不只是扫描行数,比如有没有使用临时表,需不需要排序都会影响到具体执行方案的选择。<br />由于此时分析的查询语句在执行时并没有用到临时表,也不需要进行排序,所以Mysql选择错索引一定是因为扫描行数的估计出了问题,Mysql认为走字段a上的索引需要扫描更多的数据行,所以就没有走a索引。<br />在估计扫描行数时,有一个概念很重要,那就是基数,基数指的是在某个索引字段上不同值的个数,通过show index语句,我们可以看到每一个索引的基数,如下图所示。<br /><br />从图中可以看到,虽然我们向表t中插入的数据在三个字段上都是相同的,但是使用show index得到的基数值是不一样的,但是从理论上将三个索引的基数值应该是一致的,这就说明了使用show index得到的基数值是不准确的,那么这些基数值是怎么得出来的呢?又由于这些基数值在大部分情况下与真实值相差不远,所以一定是通过某个合理的方式估算出来的。<br />那么使用show index显示的是使用什么方法估算出来的基数值呢?首先思考一下为什么不通过扫描整张表中的数据行来统计基数值呢?这是因为虽然这样能够得到精确的基数值,但是耗费的资源太多了,资源有哪些东西呢?比如cpu的执行时间,磁盘的读写能力,所以Mysql采用了统计学方法来估计基数值。<br />那么具体是怎么估计的呢?假设在字段a上建立的索引对应的b+树占据了X个数据页,Mysql会从这些数据页中随机抽取N个数据页,并且统计这些数据页上的不同值的个数,经过平均之后可以得到每个数据页上的平均值,然后再乘上该索引占据的数据页的个数,就可以估算出基数的值。<br />由于表中的数据是在不断更新的,所以索引的基数值也是会变化的,如果变更的数据行超过了总数据行的1/M,那么就会重新进行一次基数值的估算。变更的数据行是指哪些数据行?增删改的数据行都算在变更的数据行里面吗?<br />从上图中可以看到,虽然三个索引的基数值不完全相同,但是相差不远,并且a索引的基数值是最小的,所以基数值和扫描行数有什么关系?<br />接下来我们继续来看explain命令的执行结果,其中的row字段记录的就是预计的扫描行数,不强制索引和强制索引的explain命令执行结果如下图所示。所以row字段的值是怎么估计出来的?<br />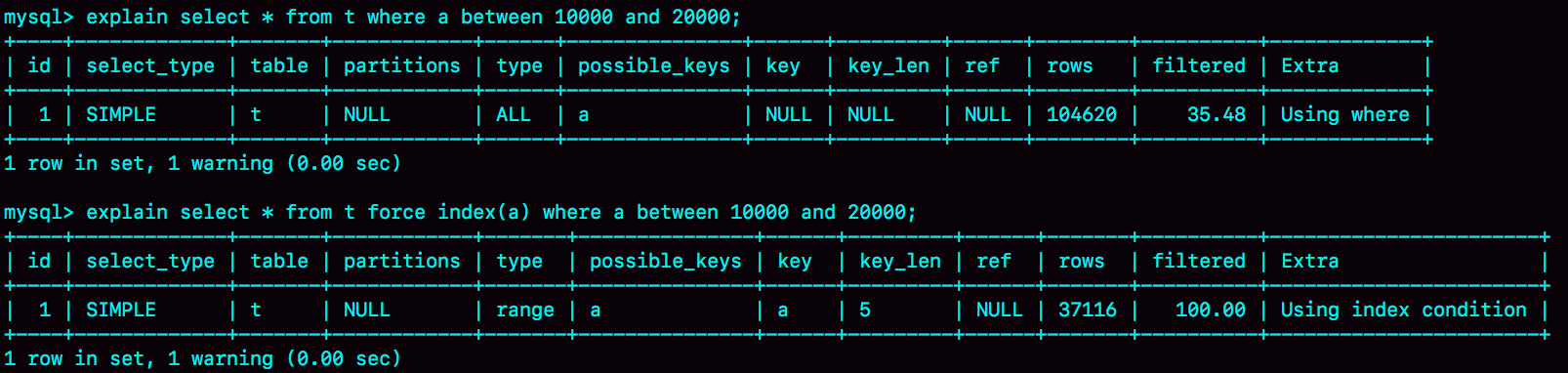<br />什么是explain执行计划?explain执行计划指的就是explain命令的执行结果,就是上图中的表格,就是优化器最终选择的执行方案。<br />如果不走索引的话,那么就要取出主键索引中所有叶子节点的值判断每个节点是否满足条件,扫描的行数是从执行器的角度来说的,存储引擎每调用一次接口就会向执行器返回一个数据行,向执行器返回多少个数据行,我们就说Mysql扫描了多少行。在不走索引的时候,Mysql会对整张表做全表扫描,如果做的是全表扫描,Mysql的扫描行数应该是表中数据的总行数,也就是10w行,此时预估的扫描行数是104620,与真实扫描行数相差不大,这个预估值没什么问题。<br />如果强制走索引a的话,执行这个查询语句的真实扫描行数应该是多少呢?从慢查询日志中可以看到,真实的扫描行数应该是10001行,但是从explain执行计划中可以看到,预估的扫描行数是37116,与真实扫描行数偏差很大,就是这个偏差误导了优化器的判断。那么是怎么误导的呢?<br />第一个问题是,为什么优化器不去选择只需要扫描37000行的执行方案,反而去选择需要扫描10w行的执行方案呢?这是因为如果选择的是扫描3w7行的执行方案,这个执行方案是在索引a上搜索数据的,所以想要获得完整的数据行还需要进行回表的操作,而如果选择的是扫描10w行的执行方案,那么就只需要在主键索引上搜索数据,而不需要进行回表操作,优化器会去评估到底是多扫描6w3行数据划算还是进行3w7次回表操作更划算,从explain执行计划可以看到,优化器最终还是选择了扫描10w行的执行方案,但是实际上这个执行方案并不是最快的,所以会说走错了索引。那么为什么优化器会选择错执行方案呢?原因就在于优化器在预估走索引a时的扫描行数时出现了较大的偏差,那么为什么优化器会出现这么大的偏差呢?<br />那么我们可以怎么解决优化器在预估扫描行数时出现较大偏差的问题呢?执行命令analyze table t就可以重新估计扫描行数,为什么重新估计出的扫描行数就是准确的呢?从下图中可以看到,在使用analyze table t命令后重新估计出的扫描行数就与实际执行时的扫描行数一致了。<br />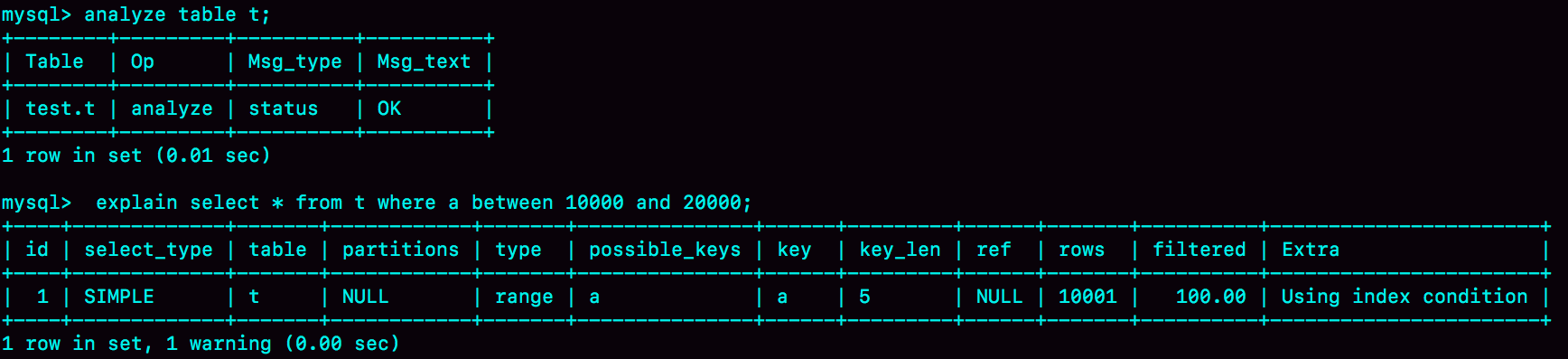<br />所以当我们发现估计出的扫描行数和实际执行的扫描行数偏差较大时就可以这么处理。<br />还是基于上面的表t,现在我们来执行另一个语句。
select * from t where (a between 1 and 1000) and (b between 50000 and 100000) order by b limit 1;
由于并没有满足这个语句中条件的数据行,所以最终的结果集应该是一个空集合。
但是在执行这个语句的时候,Mysql会选择使用哪个索引呢?从我的角度来看,选择使用索引b的代价应该会更小,因为如果在索引b对应的b+树上搜索的话就不需要进行排序了,order by b应该是从小到大进行排列,与b+树的默认排序规则一致,那么我们就可以快速定位到b=50000的数据行,然后回表取到a的值,发现不满足条件,再取下一个数据行,重复上面的过程,直到找到一条满足条件的记录或者是取到表中的最后一个数据行。
如果选择索引a呢?那么就会快速定位到a=1的数据行,然后回表取出b的值,判断是否满足条件,如果满足就添加到结果集中,再取出a=2的数据行,然后回表取出对应的b值,重复上述过程,最终基于字段b对结果集进行排序,并取出其中第一个数据行。
从上面的过程可以看出,如果选择使用索引b的话,需要扫描5w行数据,而如果选择使用索引a的话,只需要扫描1000行数据,所以从扫描行数来决定选择使用哪个索引的话,肯定是选择使用a索引。
那么在执行这个查询语句时Mysql真的使用的就是a索引吗?我们可以执行explain命令看一下。
explain select * from t where (a between 1 and 1000) and (b between 50000 and 100000) order by b limit 1;
从下图的explain命令执行结果可以看到,在执行这个查询语句时Mysql走的是索引b,走索引b的预估扫描行数是50198,虽然与实际扫描行数不是完全一致,但是偏差已经很小了,而在实际执行这个查询语句时,我们可以发现走索引a的执行速度更快,所以这种情况下Mysql又走错了索引,那么这时Mysql为什么会走错索引呢?显然不是因为扫描行数的问题了,因为预估扫描行数的偏差很小,Mysql走错索引的原因在于在查询语句中有order by b,最后的结果集需要基于字段b进行排序,如果走的是索引b的话就不需要对结果集进行排序了,而且在查询语句中还有limit 1,虽然预估的扫描行数是50000行,远远大于走索引a的1000行,但是只要找到第一个满足条件的数据行就不用继续朝下扫描了,所以优化器在综合考虑这些因素后选择了走索引b。
那么遇到索引选择异常的情况我们可以怎么做呢?首先我们可以使用force index(key)的方法强行指定Mysql走哪个索引,Mysql的分析器会对sql语句进行词法分析和语法分析,语法分析的作用是判断sql语句在语法上是否存在问题,对sql语句进行词法分析可以得到Mysql可能走的索引,Mysql会分别评估走这些索引的代价,并选择其中代价最小的执行方案,此时如果使用force index指定的索引是可能走的索引中的一个,那么优化器就会直接选择走这个索引的执行方案,不会再去评估走别的索引的代价。
为什么不推荐使用force index呢?第一个原因是通常都不这么写,突然这么写看上去就会很奇怪,第二个原因是如果索引改了名字,那么这个语句也要进行修改,第三个原因是就算是结构相同的两张表,建立的索引也完全相同,当表中的数据不同时,执行相同的查询语句也可能走不同的索引才是最优的,如果我们写死使用的索引,那么Mysql就不能根据不同的表中数据选用更合适的索引了,第四个原因是不够及时,不够及时是什么意思?不够及时指的是从遇到索引异常问题到使用force index方法解决索引异常问题需要经过很长时间。因为在开发阶段很少会去分析sql语句在执行时有没有走错索引,所以在开发的时候基本上都不会在语句上加上force index,只有在对线上的慢查询日志进行分析时,才会注意到哪些语句选错了索引,这个时候再去修改sql语句,给sql语句加上force index,但是在开发环境的修改显然是不能直接上线到生产环境的,还要先进行测试才能够正式发布,这个过程需要很长的时间,所以说使用force index方法来解决索引选择异常的问题往往不够及时。
那么还有别的方法来解决索引选择异常问题吗?第二种方法就是修改sql语句的写法,从而能够使用正确的索引并查询到相同的数据行,也就是说引导Mysql使用我们期望它使用的索引,还是以上面的查询语句
select * from t where (a between 1 and 1000) and (b between 50000 and 100000) order by b limit 1;
为例,由于字段b的值都是不同的,所以我们不管是使用order by b limit 1,还是使用order by b,a limit 1,所查询到的结果集都会是一致的,假如我们把查询语句像上面说的这样修改的话,先来看一下改之后的查询语句的explain执行计划,如下图所示。
优化器最初选择索引b的原因在于在语句中使用了order by b,如果Mysql选择走的是索引b的话,那么就不需要再对结果集进行排序了,因为对索引b遍历的结果本身就是有序的,此时虽然走索引b的扫描行数比走索引a的扫描行数更多,但是Mysql考虑到排序问题,仍然认为走索引b的代价会更小。
而此时如果把查询语句修改成order by b,a limit 1的形式,那么即使Mysql选择走的是索引b,对结果集仍然需要根据a的值进行排序,既然都要排序,于是Mysql选择走扫描行数更少的索引,也就是索引a。
这样改sql语句的缺点在于sql语句的语义被改变了,那么我们可以在不改变语义的前提下引导Mysql走索引a吗?
select * from (select * from t where (a between 1 and 1000) and (b between 50000 and 100000) order by b limit 100)alias limit 1;
第三种解决索引误用的方法是什么呢?我们还可以新建一个更合适的索引,来提供给优化器进行评估和选择,或者我们也可以删掉误用的索引。可能潜意识里会觉得删掉误用的索引这个方法不太靠谱,虽然在这个语句中这个索引是被误用了,但是在别的场景中仍然可能是必须的,这个想法很合理,但是也有可能存在索引设置不合理的情况,如果发现这个索引在各种场景中都没有存在的必要,那么就可以把这个索引给删了。

若有收获,就点个赞吧
0 人点赞
