下面的叙述的前提是能够在数据行之间加上间隙锁,而在可重复读隔离级别下执行sql语句才可能会加间隙锁,所以下面的叙述都是在可重复读隔离级别才成立的。
加锁加的都是临键锁;扫描到的叶子节点就要加锁;在进行索引上的等值查询时,如果这个索引是唯一索引,临键锁就会退化为行锁;在进行索引上的等值查询时,如果这个索引是一个普通索引,那么就要一直朝后遍历,直到遍历完所有叶子节点或者是遍历到不满足查询条件的叶子节点。如果是因为遍历到不满足查询条件的叶子节点停止了,那么最后一个临键锁就会退化成间隙锁;(执行的必须是等值查询,才有这两个退化);
首先还是建表和向表中插入数据。
CREATE TABLE `t` (`id` int(11) NOT NULL,`c` int(11) DEFAULT NULL,`d` int(11) DEFAULT NULL,PRIMARY KEY (`id`),KEY `c` (`c`)) ENGINE=InnoDB;insert into t values(0,0,0),(5,5,5),(10,10,10),(15,15,15),(20,20,20),(25,25,25);
下面先来看这个例子。
在表中不存在id=7的数据行,所以会在主键索引树中直接定位到id=10的叶子节点,所以会加上一个(5,10]的临键锁,由于到id=10的叶子节点就停止遍历了,所以只会加上(5,10]的临键锁。
id上是有索引的,而且是唯一索引,这个语句是发生在唯一索引上的等值查询,如果遍历的最后一个叶子节点上的值不满足等值条件,临键锁就会退化成间隙锁,也就是只会加一个(5,10)的间隙锁。
所以,如果会话B向这个间隙中插入id=8的记录就会被锁住,但是会话C中修改id=10的数据行中的值是被允许的。
下面看另一个例子。
c是普通索引,会话A中执行的是一个发生在普通索引上的等值查询,在执行这个语句时会直接定位到c=5的叶子节点,由于加锁的单位是临键锁,所以会加一个(0,5]的临键锁,因为加的临键锁肯定是包含叶子节点的临键锁。因为c是普通索引,所以在查询时会继续遍历,会遍历到id=10的叶子节点后才停止,既然访问了id=10的叶子节点,由于加锁的单位是临键锁,所以会加一个(5,10]的临键锁,由于遍历的最后一个节点不满足查询条件,所以最后一个临键锁会退化成间隙锁,也就是(5,10)的间隙锁。
由于这个查询使用了覆盖索引,并没有发生回表的操作,所以在主键索引树上没有加任何锁,没有对主键索引树上的叶子节点进行加锁,所以会话B中的语句是发生在主键索引树上的,所以能够正常的执行,但是在会话C中向表插入一条(7,7,7)的记录,由于存在(5,10)的间隙锁,所以会被会话A阻塞住。
下面再看一个例子。
先思考这么一个问题,对于表t,下面的两条查询语句,加锁的范围是相同的吗?
mysql> select * from t where id=10 for update;
mysql> select * from t where id>=10 and id<11 for update;
由于id字段的数据类型是整数类型,所以这两条语句的语义是一样的,都是查询表中id=10的数据行,但是这两条语句加的锁是不一样的。
那么会话A会加哪些锁呢?在执行的时候,会在主键索引树上直接定位到id=10的叶子节点,所以会加上一个(5,10]的临键锁,但是由于主键索引树是唯一索引树,所以临键锁就会退化成行锁,也就是只在id=10的数据行上加一个行锁。select from t where id>=10 and id <11 for update;语句的加锁过程可以看成两个阶段,第一个阶段是select from t where id=10 for update;语句的加锁过程,由于是发生在等值查询语句上,所以会发生临键锁的退化,第二个阶段是select from t where id>10 and id<11 for update;语句的加锁过程,这个语句的执行过程会在定位到id=10的叶子节点的基础上继续向后遍历,遍历到id=15的叶子节点后,发现这个叶子节点的id值已经超过了范围查询的右界,就会停止遍历,由于扫描了id=15的叶子节点,所以会加上一个(10,15]的临键锁。但是由于这个语句是一个范围查询语句,所以并不会发生临键锁的退化。那么这里为什么不会退化成(10,15)的间隙锁呢?因为只有在执行等值查询语句向后遍历时,临键锁才会退化为间隙锁。
所以在会话B中向表中插入(8,8,8)的数据行是不会阻塞的,而插入(13,13,13)的数据行就会阻塞,锁在索引上是什么意思?
下面再看一个例子。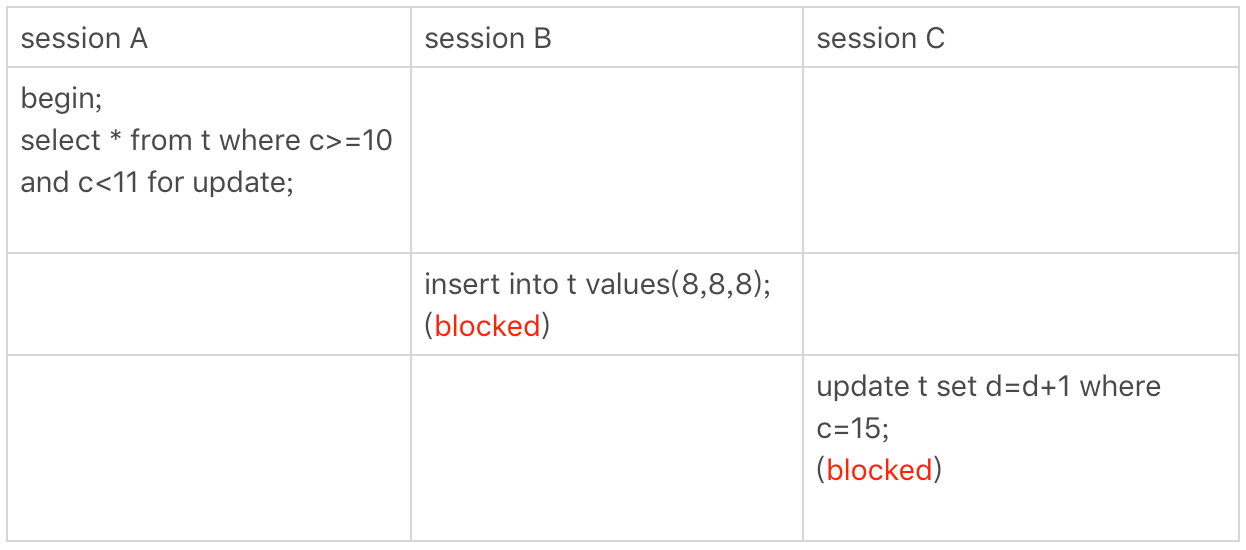
会话A中查询语句的字段是c,select from t where c>=10 and c<11 for update;语句的加锁过程可以看成select * from t where c=10 for update;和select * from t where c>10 and c<11 for update;两个语句的加锁过程的组合。由于在c上建立了索引,所以第一个语句的执行过程会在c字段索引树上直接定位到c=10的叶子节点,所以会加上一个(5,10]的临键锁,但是由于c索引并不是一个唯一索引,所以这个临键锁并不会退化为行锁,第二个语句加的锁没有区别,也是(10,15]临键锁。所以会话A加的锁是(5,10]临键锁和(10,15]临键锁。
所以在会话B中想要插入(8,8,8)数据行是会被阻塞的,
下面再看一个例子。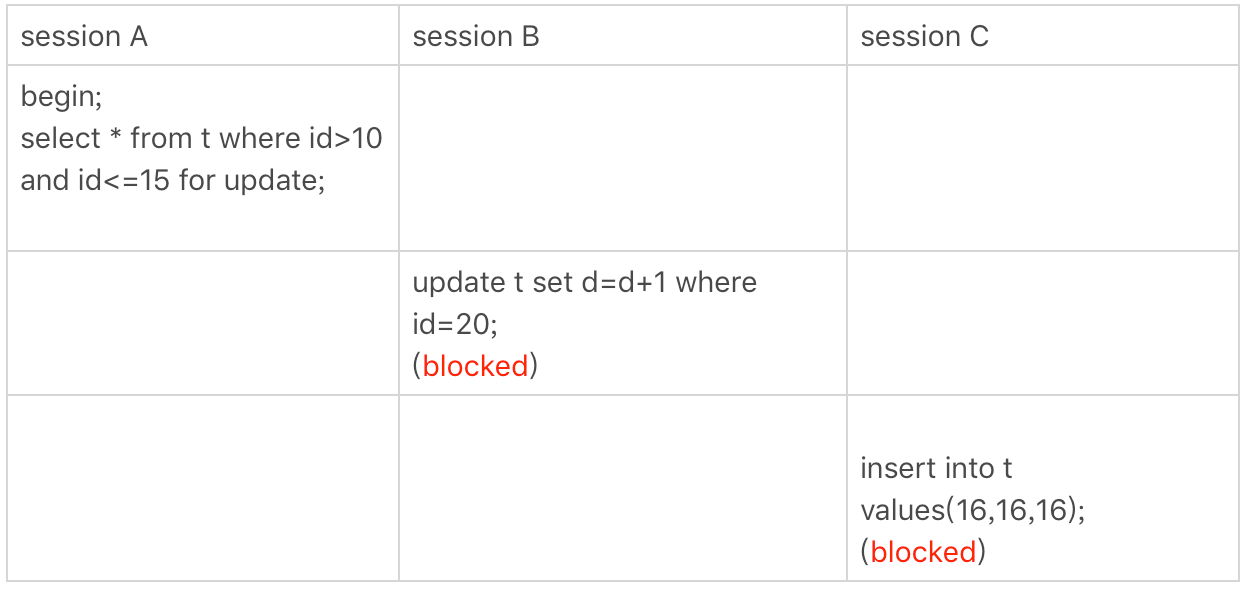
会话A中的语句是一个范围查询,这个语句在执行时会直接定位到主键索引树上id=15的叶子节点,所以会在id索引上加(10,15]临键锁,在索引上加临键锁是什么意思?又由于id字段是唯一字段,所以循环在找到第一个满足条件的叶子节点就应该停止了,但是实际上循环会一直扫描到第一个不符合查询条件的叶子节点才停止,在这个例子中也就是扫描到id=20的叶子节点时遍历停止,所以在这个过程中会在id索引上加上(10,15]临键锁和(15,20]临键锁,并且由于这个查询是范围查询,所以(15,20]临键锁并不会退化为(15,20)临键锁。
为什么在执行范围查询时,唯一字段会在找到第一条满足查询条件的记录时就停止呢?符合条件的记录不一定只有一条呀,循环一直扫描到第一个不符合查询条件的叶子节点才停止,这才是合理的做法吧。
所以在会话B中,在会话C中的向表中插入id=16的数据行的语句也会被阻塞,因为会话A在id索引上加了(15,20]临键锁。
下面再看一个例子。
先向表t中插入一条新纪录。
mysql> insert into t values(30,10,30);
新插入了一个c=10的数据行,所以在表中有了两条c=10的数据行,那么这个时候在索引c上的间隙锁是什么样的呢?前面说的都是值互不相同的表,那么当表中有两行记录的该字段值是一样的时候,那么在这个索引上是怎么加间隙锁的呢?
由于在普通索引的叶子节点中不仅包含c的值,还保存着主键的值,所以即使是两个c值相等的叶子节点,它们之间也是有区别的。
在普通索引树中,当字段的值相等时,主键值不同的叶子节点是怎么排序的呢?假定也是按增序来排列的。
那么我们就要更准确的描述临键锁,还是以这个表中的数据为例,加上的是((c=10,id=10),(c=10,id=30)]临键锁,等等。加上了这个临键锁,会阻塞哪些数据行的插入呢?会阻塞所有的c=10,id大于10且小于等于30的数据行的插入语句的执行。
下面看具体的例子。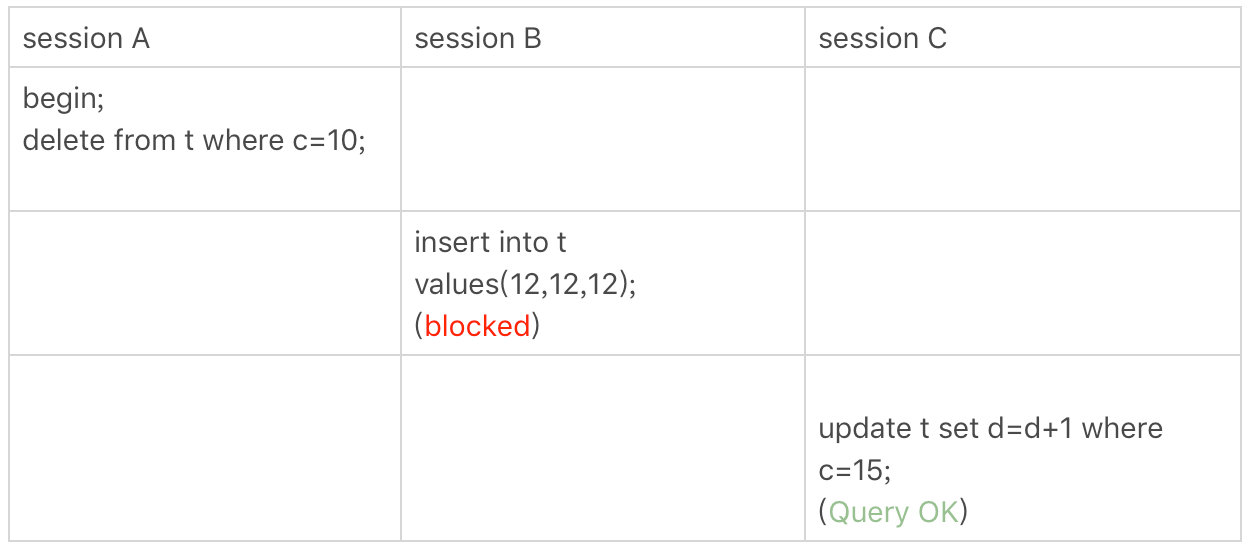
delete语句加的锁和select … for update;语句加的锁是一样的,在执行delete语句时,首先会在c索引树上直接定位到第一个c=10的叶子节点,所以加的是((c=5,id=5),(c=10,id=10)]临键锁,然后继续遍历,直到遍历到(c=15,id=15)的叶子节点,才会停止遍历。因为这是一个等值查询,不仅仅是select关键字是查询语句,delete关键字也是查询语句吗?既然这是一个等值查询,那么在索引树上遍历到了一个不满足查询条件的叶子节点才停止,这满足了临键锁的退化条件,所以会加上从(c=10,id=10)到(c=15,id=15)的间隙锁。从(c=10,id=10)到(c=15,id=15)的临键锁会锁住c=15的数据行吗?不会锁住所有的c=15的数据行,会锁住c=15,id=15的数据行的插入语句,但是id大于15的数据行的插入语句并不会被锁住,也就是说这个临键锁会锁住所有的c=10且id大于等于11的插入语句,会锁住所有的c=11,12,13,14的插入语句,不论id是多少,还会锁住所有的c=15且id小于等于15的数据行的插入语句。所以从(c=10,id=10)到(c=15,id=15)的间隙锁会锁住哪些数据行的插入呢?和对应的临键锁相比,只会少锁住一个c=15,id=15的数据行的插入语句。所以,这个delete语句会在索引c加上一个从(c=10,id=10)到(c=15,id=15)的开区间的间隙锁。
但是当c的值是唯一的时候,虽然此时在这个叶子节点中也有主键值,但是以临键锁(5,10]为例,它锁住的是所有c=10的记录,而不用考虑id的值是多少。
所以会话B想要向表中插入一个(12,12,12)的数据行会被阻塞,
下面再看一个例子。
会话A中的delete语句加上了limit 2,由于表中c=10的数据行只有两条,所以加不加上limit 2关键字,删除语句的执行结果都是一致的,但是这两条语句的加锁情况不同,那么这个例子中是怎么加锁的呢?
因为在delete语句中包含了limit 2关键字,所以在遍历到(c=10,id=30)的叶子节点后就直接停止了遍历,因此会在索引c加上从(c=5,id=5)到(c=10,id=10)的临键锁和从(c=10,id=10)到(c=10,id=30)的临键锁。所以c=12的数据行是能够正常插入到表中的。
这个例子告诉我们,在删除数据的时候能加limit关键字就加limit关键字,这是有好处的,不仅更清晰会删除掉几条数据,还可以减少加锁的范围。

若有收获,就点个赞吧
0 人点赞
