因为没有特定的格式局限,无需多余操作就可横向拓展,所以适合大规模数据存储。
目标:
- 什么是CDN
- 关系型和⾮关系型数据库的区别
- redis是单线程还是多线程
- Redis内存淘汰机制
- Redis数据持久化RDB与AOF
- 什么是Redis事务
- Redis为什么这么快
- redis主从复制原理
- Redis Sentinel的作⽤
- Redis Sentinel原理
- Redis Cluster优缺点
- AOF rewrite原理
- AOF触发机制
Nosql特点:
优点:
RDBMS - Nosql
Nosql:
- 代表着不仅仅是sql
- 没有声明性查询语言
- 没有预定义的模式
- 键值对存储,列存储,文档存储,图形数据库
- 最终一致性,而非ACID属性
- 非结构化和不可预知的数据
- CAP定理
- 高性能,高可用,高伸缩性
RDBMS:
- 高度组织结构化数据
- 结构化查询语言
- 数据和关系都单独存储在表中
- 数据操纵语言,数据定义语言
- 严格的一致性
- 基础事务
缓存的概念
缓存是为了调节速度不一样的两个或多个设备的速度,在中间对速度较快的一方起到一个加速访问速度慢的一方的作用,有多种多样的缓存,例如CPU缓存,内存缓存,磁盘缓存,浏览器缓存等等
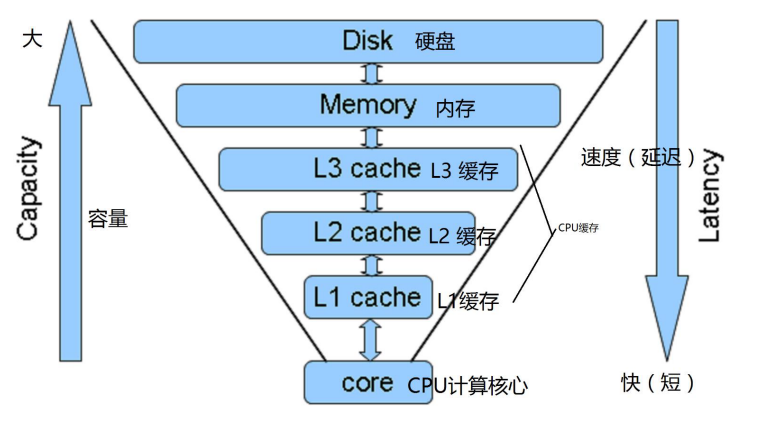
缓存的保存位置:
- 客户端:浏览器
- 内存:本地服务器,远程服务器
- 硬盘:本机硬盘,远程服务器硬盘
缓存的特性:
- 自动过期:给缓存的数据加上有效时间,到期后自动删除
- 强制过期:源网站更新图片后,CDN服务器并不会更新,需要强制更新图片缓存
- 命中率:即缓存的命中率
系统缓存
buffer和cache
Buffer:
- 一般是写缓冲,一般会将数据先写入内存,再写入磁盘
Cache:
-
用户层缓存
DNS缓存:
默认为60s,即60s内再访问同一个域名就不再进行DNS解析
- DNS预获取,一个页面包含多个域名的时候,浏览器会尝试先解析域名,当需要访问的时候不再解析,提高了访问的速度
浏览器缓存:
最后修改时间:
系统调用会获取文件的最后修改时间,如果没有发挥变化会返回浏览器304的状态码,表示没有发生变化,然后浏览器就使用本地的缓存展示资源Etag标记:
基于Etag标记是否一致做判断页面是否发生了变化,比如基于Nginx的Etag on来实现过期时间Expires:
以上两种都需要发送请求,即不管资源是否过期都要发送请求进行协商,这样会消耗不必要的时间,因此有了缓存过期时间。Expires是httpheader中代表资源的过期时间,由服务器端设置,如果有expire在expire过期前不会发生http请求,直接从缓存中读取。用户强制f5除外
以上三种浏览器缓存的方式通常都在一起使用
- 特别是Last-Modified和Expires经常在一起使用,因为Expire可以让浏览器不发起访问,强制F5后又可以判断Last-Modified,可以很好的达到浏览器缓存的效果
- Etag和Expire,先判断Expire,过期后就重新请求页面,如果Etag没有变化则返回304,如果发生了变化则返回200状态码
- Last-Modified,Etag,Expires三个混合使用,先判断Expire再判断Last-Modified最后判断Etag都没有过期才会返回304
CDN缓存
内容分发网络(Content-Delivery-Network,CDN,是建立并覆盖在承载网上,由不同区域的服务器组成的分布式网络,将源站资源缓存到全国各地的边缘服务器,利用全球调度系统使用户能够就近获取,有效降低访问延迟,降低源站压力,提高服务的可用性。
用户请求CDN的流程
假设您的域名已经接入了CDN开始使用加速服务后,当您的用户发起HTTP请求时,实际的处理流程如下:
- 用户向域名发起某图片资源的请求,会向Local-Host发起域名解析请求
- 当Local-Dns解析域名时,发现已经配置了CNAME(CDN服务器的地址),此时这个请求会发向Tencent DNS(GSLB)GSLB为腾讯自主研发的调度体系,会为请求配置最佳IP地址
- Local-host获取Tencent-Dns返回的解析IP
- 用户获取解析的IP
- 用户向Ip发起HTTP请求
- 若该IP节点有缓存资源,则直接返回请求的资源。若没有该IP节点会向业务节点发送HTTP请求,并将请求的资源发送给用户,并且将资源缓存到本地。此时请求已经结束。
利用302实现转发请求重定向到最有服务器集群
腾讯云利用在全国部署的302重定向服务器集群,能够为每一个请求实时决策最优的服务器资源,精准解决小运营商的调度问题,提升用户访问质量,能最快的把用户引导至最优的服务器节点上,避开性能差的或者是有故障的节点
CDN的分层缓存
提前对静态内容进行预缓存,避免大量的请求回源,导致主站网络带宽被打满而导致数据无法更新,另外CDN可以将数据根据访问的热度不同而进行不同级别的缓存,例如访问最高的放在CDN边缘服务器的内存中,其次放在SSD或者SATA,再其次放入云存储,这样兼顾了速度与成本
CDN主要优势:
CDN有效的解决了以下问题:
- 用户与业务服务器地域间物理间隔较远,需要进行多次网络转发,会导致延迟高且不稳定
- 用户所用运营商与业务服务器所在运营商不同,请求需要运营商之间相互互联转发
- 业务服务器网路带宽,处理能力有限,当接受了海量来自用户的请求后,会导致响应速度降低,可用性降低
- 利用CDN防止和抵御DDos攻击实现安全保护,
Redis
是什么:
是一个由c语言写的,开源的key-value数据库。为了保证效率都是把数据存储在内存中,并且会周期性的把内存中的数据写到磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步
特点:
- 速度快,虽然是单线程架构,但是因为Redis的数据都是运行在内存中的,所以运行速度特别快
- 支持五大数据类型(字符串,列表,集合,有序集合,哈希类型)
- 支持事务
- 有丰富的功能特性
Redis单线程架构:
- Redis使用了单线程架构,从客户端发送到服务端的命令并不会被直接执行,而是会放到一个队列中,然后被执行。redis采用了IO多路复用的技术来解决IO的问题
既然是单线程为什么还会这么快:
- 纯内存访问,Redis的所有数据都是放在内存中,内存响应的时间大概只有100ns,所以这是redis每秒万级别的访问的重要基础
- 非阻塞IO,Redis采用的是Epoll作为IO多路复用技术的实现,再加上Redis自身的事件处理模型,将epoll中的连接,读写,和关闭都转换为事件,不在网络IO上浪费过多的时间
- 单线程避免了进程间的切换和竞态产生的消耗
Redis的运用场景:
键过期功能:缓存和Session共享等问题
Redis丰富特性:
- 慢日志查询分析:通过慢日志查询分析,找到有问题的命令进行优化
- Redis-Shell
- PipeLine:通过Pipeline的机制有效提高客户端性能
- 事务与Lua:制作自己的专属原子命令
- Bitmaps:通过在字符串结构上使用位操作,有效节省内存。
- Hyperloglog:一种基于概率的新算法,很节省空间
- 发布订阅:基于发布订阅模式的消息通信机制
- GEO:redis3.2提供了基于地理位置信息的功能
Pipeline:
redis提供了批量操作命令例如mget,mset等,有效节约了RTT,但是大部分命令不支持批量操作,于是PipeLine这个命令就是将一组Redis命令进行打包,通过一次RTT传输给Redis再将这组命令的结果按顺序返回给客户端
消息队列:
消息队列:把要传输的数据放到一个队列中
作用:可以实现多个系统间的解耦,异步,削峰、限流等
常用的消息队列应用:kafka,rabbitmq,redis
消息队列主要分为两种模式,redis都支持:
- 生产者消费者模式
- 发布者订阅者模式
生产者消费者模式:
在此模式下,上层应用接收到了外部请求后开始处理其当前步骤的操作,在操作完成后将数据发布到指定的频道(逻辑队列中),并由其下层的应用监听该频道并继续下一步的操作,如果其完成后没有下一步的操作就将数据返回给外部请求,如果还有下一步的请求,就会将数据发送到另外一个频道,值得注意的是,每个结果都只能被消费一次。
发布订阅:
redis提供了基于发布订阅模式的消息机制,此种模式下,发布者和订阅者不直接通信,发布者客户端向指定频道发布消息,订阅该频道的每一个订阅者都能收到该消息。
GEO功能
数据持久化:
Redis支持RDB和AOF两种持久化机制,持久化功能有效的避免了因进程退出而造成的数据丢失问题,当下次重新启动时即可重新加载持久化的文件实现数据恢复。因为Redis的数据运行在内存中,如果服务挂掉或者服务器DOWN机都会导致数据丢失,就采用了这两种方式来解决数据持久化的问题。
RDB持久化机制:
- RDB是把内存中的数据生成快照保存在硬盘中的机制
- RDB机制分为手动触发和自动触发
优点:
- RDB是一个非常紧凑的文件,它保存了Redis在某个时间点上的全部数据,这种文件有利于备份和灾难恢复
- RDB在恢复大数据集时比AOF的恢复速度更快
缺点:
- RDB方式数据没法做到秒级持久化,因为bgsave每次运行都要fork一个子进程,属于重量级的操作(内存中的数据被克隆了一份,大约两倍的膨胀性)频繁操作影响性能
- RDB文件使用特定的二进制保存,使得版本不一样的Redis难以相互兼容
在做备份期间如果服务器DOWN掉的话,就会丢失最后一次备份之后的数据
触发方式:
手动触发和自动触发
自动触发:主配置文件中的Save字段
手动触发:Save:Save过程中会阻塞主进程,使进程无法响应请求
- Bgsave:主进程执行Fork一个子进程的操作,Fork过程会阻塞,但是时间很短,RDB持久化过程由子进程负责,完成后自动结束。
默认情况执行shutdown命令时,若没有开启AOF持久化配置则自动执行Bgsave
流程说明:
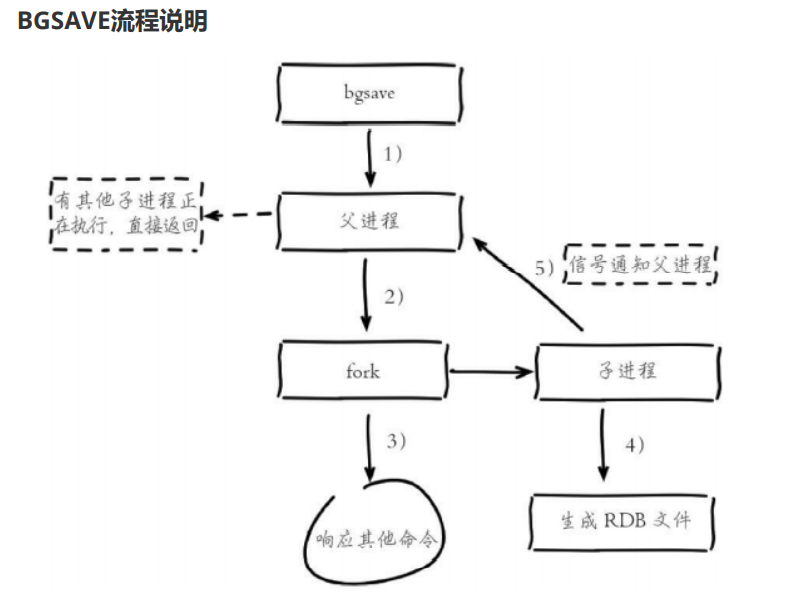
- 执行Bgsave命令,父进程判断当前是否存在正在执行的子进程,如果存在bgsave命令直接返回
- 父进程执行fork操作创建子进程,fork操作的过程中,父进程会阻塞一般为微妙级别
- 父进程fork完成后,继续响应其他命令,bgsave命令返回background saving started信息
- 子进程创建RDB文件,根据父进程内存生成临时快照文件,并且替换原子快照文件
- 进程发送信号给父进程,父进程更新统计信息
运维提示:
- 当遇到坏盘或者磁盘写满的情况。可以通过config set dir{new dir}在线修改文件路径到可用的磁盘路径,之后执行bgsave进行磁盘切换,AOF也同样适用
- Redis默认采用LZF算法对生成的RDB文件进行压缩,压缩后的文件远远小于内存大小。
如果想要恢复相关数据,只需要将相关的RDB文件拷贝到相关的目录即可,Redis启动时会自动将RDB文件里的内容加载到内存中。
AOF持久化机制:
AOF(append only file)持久化,以独立日志的方式记录每一次的写命令,重启时再重新执行AOF文件中的命令达到恢复数据的目的。
- AOF相比较于RDB的优势在于解决了数据持久化的实时性。
优点:
- AOF持久化使用了多种的同步频率,即使使用了默认的同步频率,Redis最多也就是丢失1秒的数据
- AOF文件使用Redis命令追加的形式来构造,因此Redis只能向文件写入命令的片段,使用redis-check-aof工具可以去修正AOF文件
- AOF的文件可读性强,这也为使用者提供了更灵活的处理方式,例如不小心错用了Flushall命令,我们可以将这个命令去掉并重新加载AOF文件即可恢复
缺点:
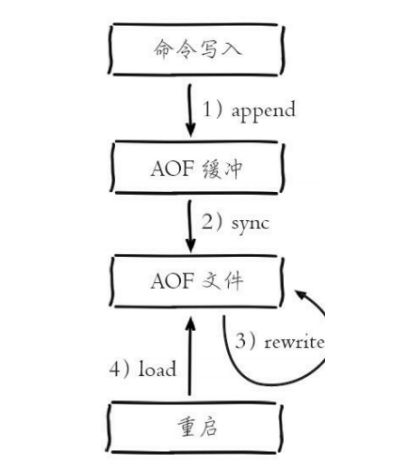
- 所有写入的命令都会追加到AOF-BUF中
- AOF缓冲区根据相应的策略向磁盘做同步操作
- 随着AOF文件越来越大,需要定期对AOF文件进行重写,达到压缩的目的
- 当Redis服务重启时,可以加载AOF文件进行数据恢复
AOF重写机制:
随着命令不断写入AOF的文件会越来越大,为了解决这个问题,Redis引入了AOF重写机制来压缩文件的体积
重写后的AOF文件体积变小,原因如下:
进程内已经过期的数据不再写入文件<br /> 旧的AOF含有无效命令,重写使用进程内的数据直接生成,这样的新AOF只保留最终数据的写 入命令<br /> 多条命令写在一起,为防止多条命令写在一起溢出缓冲区,则会以64个元素为界拆分为多条
手动触发:直接使用bgrewriteaof
- 自动触发:根据auto-aof-min-size和auto-rewrite-percentage参数确定自动触发的时机
重写流程:
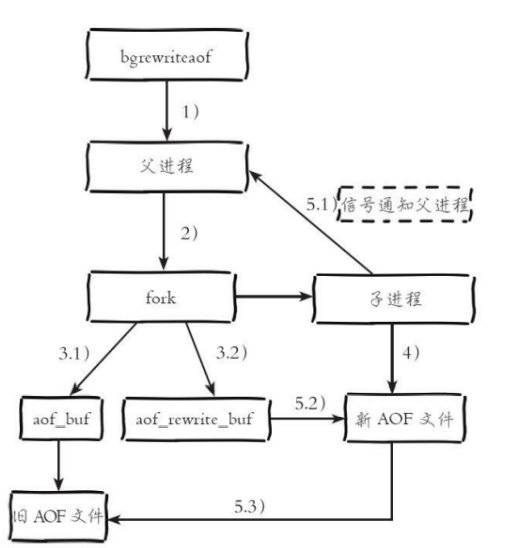
- 执行AOF重写请求
- 父进程执行fork操作创建一个子进程,开销等同于bgsave过程。
- 3.1.主进程fork操作完成后,继续响应其他命令。所以修改命令依旧写入aof-buf缓冲区并根据appendsync策略同步到磁盘中,保证原有AOF机制的正确性 3.2由于Fork操作运用写时复制技术,子进程只能共享fork操作时的内存数据,由于父进程继续响应命令,Redis使用AOF重写缓冲区保存这部分新数据,防止新的AOF文件产生丢掉这部分数据
- 子进程根据内存快照,按照命令合并规则写入到新的aof文件,每次批量写入硬盘数据量由配置aof-rewrite-incremental-fsync控制,默认为32MB,防止单次刷盘数据过多造成硬盘阻塞
- 5.1新AOF文件写入完成后,子进程发送信号给父进程,父进程更新统计信息。5.2父进程把AOF重写缓冲区的数据写入到新的AOF文件。5.3使用新的AOF文件替换老文件,完成AOF重写
重启Redis加载配置文件流程:
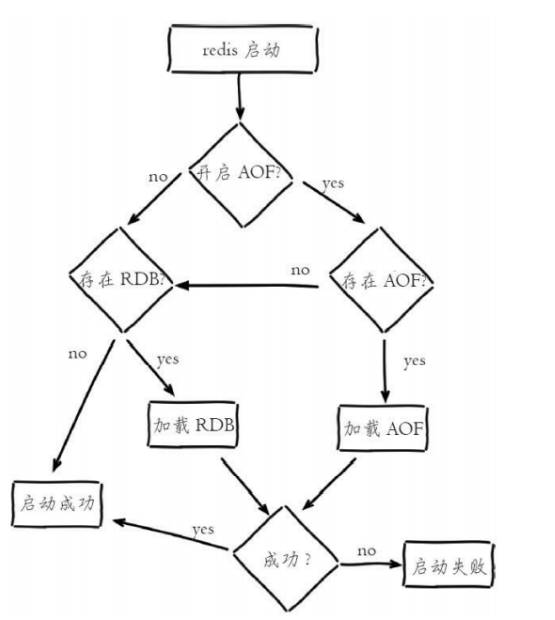
架构——主从复制,哨兵,集群
摆爷加油

若有收获,就点个赞吧
0 人点赞
