容器是什么呢,容器就是容器。它代表的是指定服务运行的环境,不代表服务本身。它把服务所运行的环境抽象出来,单独作为一个类似于盒子的东西,把服务封装进去。类似于鱼缸,指定的服务就是鱼。鱼只有在鱼缸里面有水时才能活动。水就类比于指定的服务运行的环境。
守护进程:守护进程是运行在后台的一种特殊进程。它独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件,它不需要用户输入就能运行而且提供某种服务,不是对整个系统就是对某个用户程序提供服务。
1. 虚拟机和Docker的区别
虚拟机:隔离性比较好,有自己的操作系统。虚拟机的镜像比较庞大一般为10G-20G,虚拟化性能差,虚拟机启动慢,虚拟机创建慢,虚拟机的镜像在实例化时不能共享,虚拟机的镜像缺乏统一的标准。虚拟化的粒度比较低,
Docker容器:隔离性比较弱,共享主机的os,docker容器较小为几百mb,计算和存储无损耗,没有GuestOS开销,有统一的镜像标准,且镜像可以共享,虚拟化粒度高,一台物理机能运行非常多的容器。秒级创建,秒级启动。资源利用率更高,开销更小,创建和启动时间更快。
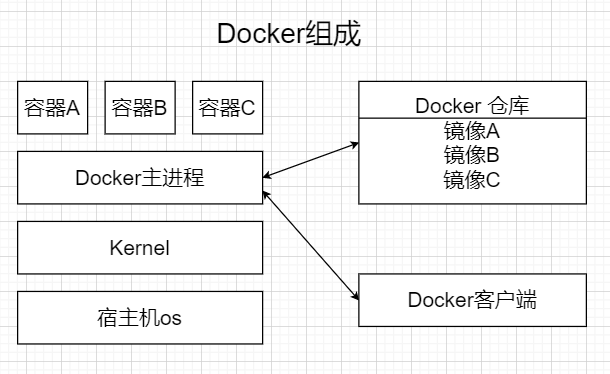
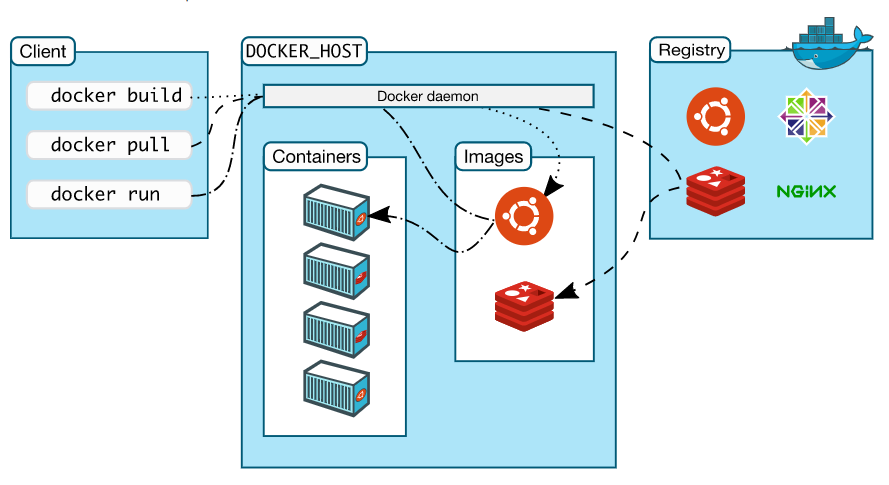
2.Docker的组成:
Docker主机:是一台物理机或者是虚拟机,运行服务端和容器
Docker服务端:运行守护Docker进程,运行容器
Docker客户端:通过Docker命令或其他工具调用DockerApi接口
Docker仓库:是一个存储Docker镜像的地方,最大的仓库是官方提供的Docker仓库
Docker镜像:是实例化时使用的模板
Docker容器:是镜像模板的实例化,对外提供服务的一个或一组服务。
3.Docker两个核心原理
Linux NameSpace技术
NameSpace是linux内核层的概念,即有一些不同类型的命名空间都部署在核内,各个docker容器运行在一个docker主进程上,共享一个宿主机系统的内核,各个容器运行在宿主机的用户空间,但是也要像虚拟机一样拥有互相隔离的运行空间,但是容器技术是在一个进程中实现运行指定服务的运行环境(容器就是给指定服务提供运行的环境,类似于一个盒子),并且还可以保护宿主机的内核不受其他进程的干扰和影响,如文件系统,网络空间,进程空间等,于是就通过NameSpace技术实现容器运行空间的相互隔离。
隔离类型:
mnt:提供磁盘挂载点和文件系统的隔离能力
ipc:提供进程间通信的隔离能力
UTS:提供主机名的隔离能力
pid:提供进程的隔离能力
net:提供网络的隔离能力
user:提供用户的隔离能力
MNT Namespace:每个容器都要有独立的根文件系统和用户空间,以实现容器中启动服务并且使用容器的运行环境。宿主机使用了chroot技术将容器锁在一个目录下运行。
IPC NameSpace:一个容器中的进程数据可以互相访问,但是不能访问其他容器的数据
UTS NameSpace:包含了运行内核的名称,版本,底层体系结构类型等信息用于系统表示,其中包含了hostname和域名,其中Hostname用来标识不同的容器,主机名标识独立于宿主机和其他容器。
PidNameSpace:linux系统中有一个进程号为1的进程,它是所有linux进程的父进程,那么在每个容器下也要有类似的父进程来管理其下属的进程,那么这多个进程都有PidNameSpace隔离
NetNameSpace:每个容器都类似于虚拟机一样有自己的虚拟网卡,端口,TCP/IP协议栈。Docker使用net启动vethx接口,这样容器将拥有自己的桥接ip地址,通常是Docker0,Docker0就是虚拟网桥。
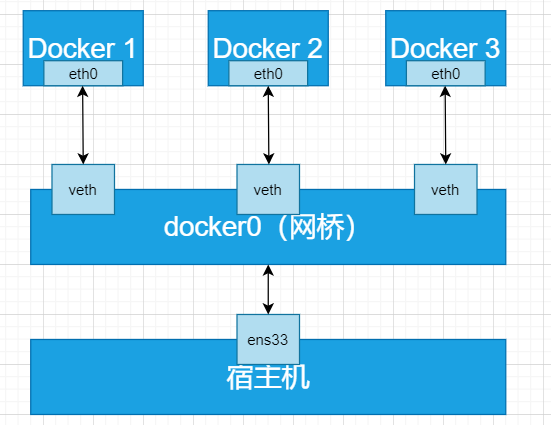
UserNamespace:各个容器可能创建相同的用户和组,而UserNameSpace技术允许在各个宿主机的各个容器空间中,可以创建相同的用户名和相同的uid和Gid,只是此用户的有效范围仅仅是当前的容器内。不能访问另一个容器的文件系统。
LinuxControlGroup
在一个容器内部,倘若不对资源做任何限制,理论上它可以占用完宿主机的所有资源,影响到其他进程的正常运行,为了防止这种情况的产生,宿主机就通过Cgroup技术来限制容器对资源的占用比例。例如CPU,内存,磁盘,网络等。它最重要的作用是限制进程组使用的资源上限。
Cgroup术语:
Task:任务就是系统的一个进程
控制族群(control group)是按照某个规定划分的一组进程,cgroup中的资源控制都是以控制族群为单位实现,一个进程可以加入迁移到指定的cgroup群组,可以使用该cgroup划分的资源
层级;就是一颗控制族群树,由控制族群组成,树上的子节点是父节点控制族群的孩子,继承父控制节点的属性。
子系统:一个子系统就是一个资源控制器,例如cpu子系统就是控制cpu时间分配的一个资源控制器。子系统必须附加到一个层级上面才能起作用,一个子系统加入到某个层级后,这个层级的所有控制族群都受此分配器的控制。
子系统介绍:
CPU:使用调度程序为Cgroup任务提供CPU的访问
cpuacct:产生cgroup任务的cpu资源报告
cpuset:如果是多核cpu,可以为cgroup限制单个cpu和内存供cgroup使用
device:设置cgroup对设备的访问
freezer:暂停和恢复cgroup任务
memory:设置每个cgroup的内存限制和内存使用报告
net_cls:标记每个网络包方便cgroup使用
ns:命名空间子系统
perf event:增加了对每个group的检测能力。
4.Docker镜像分层原理
https://www.cnblogs.com/handwrit2000/p/12871493.html // 镜像的分层结构
1.bash镜像:base镜像简单来说就是不依赖于其他镜像,完全从0开始建起,其他镜像都建立在他之上,可以理解为docker大厦的地基。
Docker镜像的操作系统都特别的小只有几百mb,但是理论上一个操作系统的大小肯定不止几百mb,那么到底是什么原因导致了这种情况?
首先是我们要明白linux启动要运行两个fs,bootfs+rootfs如下图:
内核空间是kernel linux刚启动时会加载bootfs文件系统,之后bootfs会被卸掉。用户空间的文件系统是rootfs,包括我们熟悉的各种目录。对于bash镜像来说,只需要加载rootfs即可,可以与host共用一个kernel。
bootfs:主要包含了bootloader和kernel,当内核成功启动后,bootfs就被umount了。
rootfs:包含的就是典型linux系统中的/dev,/proc,/bin,/etc等标准目录和文件。
由此可见不同的linux发行版本,bootfs基本是一致的,只不过是rootfs会有差别。因此不同的发行版可以用公用的bootfs。
所以docker可以同时支持多种linux镜像,模拟出多种操作环境。
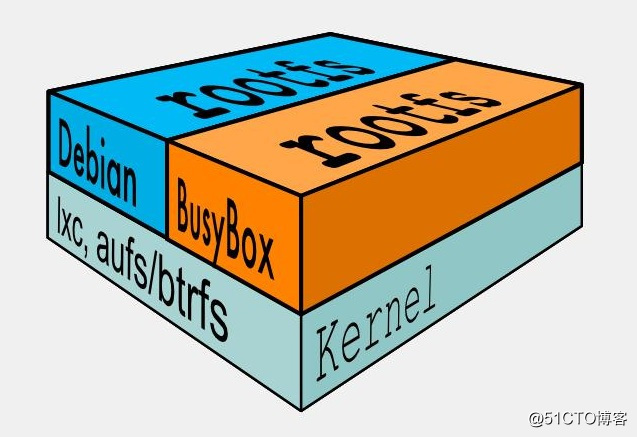
上图的busybox,和debian上层提供了各自的rootfs,底层共用了dockerhost的kernel。
需要注意的是:bash镜像只是在用户空间与发行版一致,kernel版本与发行版是不同的。
#镜像内核root@slave5 ~]# docker run -it ubuntu bashroot@2dcc10f14170:/# uname -r3.10.0-693.el7.x86_64#宿主机内核[root@slave5 ~]# uname -r3.10.0-693.el7.x86_64
容器只能使用host的kernel,并且不能修改。在容器中没法对kernel升级。
镜像的分层结构
镜像都是一层一层在bash镜像的基础上累加的,为什么会使用这种结构呢?
答案是为了共享资源,比如有多个镜像是从bash镜像构建而来,那么只需要将bash镜像保存一份到硬盘和内存中,不用创建多次镜像来占据资源。但是资源共享又有一个问题,当我们修改etc下的文件时,其他镜像是否也能看到我们修改的内容。答案是否定的。因为这就是容器的copy-on-write特性
1.新数据会直接存放在最上面的容器层
2.修改现有数据会将数据从镜像层复制到容器层,修改后的数据直接保存在容器层,镜像层不修改
3.如果多个层中有相同的文件,用户只能看到最上面那层中的文件
可写的容器层
当容器启动时,一个新的可写层被加载到镜像的顶部,这一层被称为容器层,容器层之下的都叫镜像层。
典型的linux启动后,会将rootfs置为readonly,进行一些列检查后将其设置为readwrite供用户使用。在docker中,起初也是将 rootfs 以readonly方式加载并检查,然而接下来利用 union mount 的将一个 readwrite 文件系统挂载在 readonly 的rootfs之上,并且允许再次将下层的 file system设定为readonly 并且向上叠加, 这样一组readonly和一个writeable的结构构成一个container的运行目录, 每一个被称作一个Layer。
镜像层的数量会非常多,所有镜像层会组合在一起形成一个统一的文件系统
容器层记录对镜像的修改,所有镜像层都是只读的,不会被容器修改,所以镜像可以被多个容器共享。
5.联合文件系统
联合文件系统概念
联合挂载是一种文件系统,它可以在不修改其原始源的情况下创建多个目录,并把内容合并为一个文件的错觉。因为我们可能将相关文件集存储在不同位置中,但我们希望在单个合并视图中显示它们。
对于联合文件系统的不同实现:有unionfs,aufs,overlayfs等等。overlayfs被集成到了linux内核中,docker容器的存储引擎默认就是它
为什么需要类似的联合文件系统?
它可以说是 Docker 镜像和容器的基础,因为它可以使 Docker 可以把镜像做成分层的结构,从而使得镜像的每一层可以被共享。例如两个业务镜像都是基于 CentOS 7 镜像构建的,那么这两个业务镜像在物理机上只需要存储一次 CentOS 7 这个基础镜像即可,从而节省大量存储空间。
联合文件系统在主机上使用多层目录存储,但最终呈现给用户的则是一个普通单层的文件系统,我们把多层以单一层的方式呈现出来的过程叫作联合挂载。
联合文件系统还提供隔离功能,因为容器对共享镜像层具有只读访问权限。如果他们需要修改任何只读共享文件,他们会使用写时复制策略(稍后讨论)将内容复制到可以安全修改的可写层。
Docker中的实现
首先每一个镜像层都会有一个唯一id标识这一镜像层的身份。然后对应的镜像层在/var/lib/docker/overlay2/目录中都会有一个对应的目录,目录下有diff,work,merged,lower,link这几个文件或者目录。如果运行了容器,则会生成一个对应的目录,下面也有同样的文件,并且我们修改的文件将会存放到diff目录下。
总的目录:
merged目录:
diff目录:都是修改的文件
lower目录:是当前镜像的父镜像。
upperdir也就是diff目录:
LowerDir:是只读镜像层的目录
MergedDIR:镜像和容器所有图层的合并视图
UpperDir:写入更改的读写层
WorkDir:linux overlayFS用于准备合并视图的工作目录。
对文件的修改,和读取
读取文件:
容器内进程读取文件分为以下三种情况。
- 文件在容器层中存在:当文件存在于容器层并且不存在于镜像层时,直接从容器层读取文件;
- 当文件在容器层中不存在:当容器中的进程需要读取某个文件时,如果容器层中不存在该文件,则从镜像层查找该文件,然后读取文件内容;
- 文件既存在于镜像层,又存在于容器层:当我们读取的文件既存在于镜像层,又存在于容器层时,将会从容器层读取该文件。(由于写时复制,所以此时肯定是修改过的文件才会复制到容器层,所以应该读取容器层的文件)
修改文件或者目录:
- overlay2对文件的修改采用的是写时复制的工作机制,这种工作机制可以最大程度节省存储空间,当我们第一次在容器中修改某个文件时,overlay2会触发写时复制机制,overlay2首先从镜像层复制文件到容器层,然后再容器层执行对应的文件修改操作。
overlay2 写时复制的操作将会复制整个文件,如果文件过大,将会大大降低文件系统的性能,因此当我们有大量文件需要被修改时,overlay2 可能会出现明显的延迟。好在,写时复制操作只在第一次修改文件时触发,对日常使用没有太大影响。
- 删除文件或目录,当文件或目录被删除时,overlay2并不会真正从镜像中删除它,因为镜像层是只读的。
6. 镜像制作
手动制作
就是先下载一个系统镜像,然后进入到容器中,将所需要的服务部署完成,通过commit命令提交。在企业中不会用到。
Dockerfile制作
Docker程序读取Dockerfile并根据指令生成Docker镜像。
配置指令
ARG:定义创建过程中使用到的变量
FROM:指定所创建镜像的基础镜像
EXPOSE:生命镜像内服务监听的端口,该指令只起到声明作用,并不会自动完成端口映射。
ENTRYPOINT:指定镜像的默认入口命令,该入口命令会在启动容器时作为根命令执行,所有传入值作为该命令的参数
每个Dockerfile中只能有一个ENTRYPOINT,当指定多个时只有最后一个起效
VOLUME:创建一个数据卷挂载点
WORKDIR:为后续的RUN,CMD,ENTRYPOINT指令配置工作目录,相当于CD到某个目录下。
操作指令
RUN:指定运行的命令,每条RUN指令将在当前镜像的基础上执行指定命令,并提交为新的镜像层
CMD:用来指定启动容器时默认执行的命令,格式:[“nginx”, “g”, “daemon off;”]必须是参数逗号加空格。只能有一条CMD命令。
ADD:添加内容到镜像。该命令将复制指定的SRC路径下内容到容器的dest路径下,src可以是dockerfile所在目录的一个相对路劲, 也可以是一个url,还可以是一个压缩文件。
COPY:复制内容到镜像,与add指令功能相似,当使用本地目录为源目录时,推荐使用copy
思考:copy命令和add命令有什么区别?
在复制压缩文件的情况下,从url拷贝文件到镜像的情况下用ADD。
在其他情况都用copy。并且copy能在多阶段构建中使用前一阶段的产物,在这种情况下能减少镜像的大小。
对于目录而言,copy和add命令具有相同的特点,只复制目录中的内容而不包含目录本身,
workdir /app
copy /test . //只复制test目录下的文件
copy /test ./test 复制test目录
基于dockerfile搭建nginx
[root@slave5 nginx]# cat ./Dockerfile //第一个D必须大写。
FROM centos:7
MAINTAINER cxy1023 1449802341@qq.com
RUN yum install -y vim wget tree lrzsz gcc gcc-c++ automake pcre pcre-devel zlib zlib-devel openssl openssl-devel iproute net-tools iotop
ADD nginx-1.20.2.tar.gz /usr/local/src
RUN cd /usr/local/src/nginx-1.20.2 \
&& ./configure --prefix=/usr/local/nginx --with-http_sub_module \
&& make \
&& make install \
&& cd /usr/local/nginx
WORKDIR /app
COPY /test ./test
RUN useradd -s /sbin/nologin nginx \
&& ln -sv /usr/local/nginx/sbin/nginx /sbin/nginx \
&& echo "test docker" > /usr/local/nginx/html/index.html
EXPOSE 80 443
CMD ["nginx", "-g" ,"daemon off;" ]
7. 数据管理
容器中的数据是临时的,如何将我们创建的容器产生的数据保存下来?
通过数据卷和数据卷容器,将数据保存到宿主机的目录下。
数据卷与数据卷容器:
数据卷是宿主机上的目录或者文件,可以直接被挂载到容器当中使用。
特点:
1.数据卷是宿主机的文件或目录,可以在多个容器之间共同使用。
2.在宿主机对文件内容进行更改后,所有的容器数据内容都会被修改
3.数据卷的数据可以持久保存,即使删除了使用该数据卷卷的容器也不受影响
4.在容器里面写数据不会影响到镜像本身
5.数据卷使用场景包括,日志输出,静态web界面,应用配置文件,多容器间目录或者文件共享。
数据卷容器:
数据卷容器是挂载了数据卷的容器,其他容器可以通过参数—volums引用这个容器间接,挂载数据卷。数据卷容器的功能是使数据在多个docker容器中共享。即可以让b访问a,a访问b的共享数据。
具体实现的方法是:启动一个卷容器,启动两个客户端容器,并加—volum参数,将卷容器传入。既可以访问到卷容器共享的数据。将卷容器停止后,可以创建新的容器。删除卷容器后不可以再创建新容器,但是之前创建好的容器不受影响。
#创建准备挂载的目录
[root@slave5 work]# cat /data/web/index.html
hello
this is docker test
nihao i vim this file in docker countain can you see?
#挂载
docker run -itd --name web1 -v /data/web/:/usr/local/nginx/html/ -p 8080:80 nginx:v1
#测试
[root@slave5 work]# curl localhost:8080
hello
this is docker test
nihao i vim this file in docker countain can you see?
#只读挂载
docker run -itd --name web2 -v /data/web/:/usr/local/nginx/html/:ro -p 8081:80 nginx:v1
#修改只读挂载的容器中的文件
INSERT -- W10: Warning: Changing a readonly file //不能修改
#启动要给卷容器server
root@slave5 work]# docker run -d -it --name nginx-web -v /data/web/:/usr/local/nginx/html/:ro -p 8081:80 nginx:v1
#挂载卷容器
[root@slave5 work]# docker run -d -it --name nginx-web1 --volumes-from nginx-web -p 8082:80 nginx:v1
#测试挂载情况
root@slave5 work]# curl localhost:8082
iiiihello
this is docker test
nihao i vim this file in docker countain can you see?
i can edit this file can you?
几个特点:
- 停止卷容器可以创建新容器
- 删除卷容器后不可创建新容器,但之前创建好的容器不会有任何影响。
数据卷容器可以作为共享的方式为其他容器提供文件共享,可以在生成中启动一个实例挂载本地目录,然后其他的容器分别挂载此容器的目录,即可保证各个容器之间的数据一致性。
8.网络管理
容器之间的互联
在同一个宿主机上的容器可以通过端口映射的方式,经过宿主机中转进行互相访问,也可以通过docker0网桥互相访问
直接互联
使用名称互联
使用别名互联
Docker网络
四种网络模式
- host模式:配置-net=host,容器和宿主机共享netwokrnamespace。
- container模式:配置-net=container:nameorid,容器和另外一个容器共享netnbc
- none模式:配置-net=none,容器有独立的nmsbc。但没有对网络进行任何配置
- bridge模式:配置-net=bridge 默认为该模式。
docker服务安装完成之后,默认在每个宿主机会生成一个名称为docker0的网卡,其ip地址都是172.17.0.1/16.
container网络类型:
这个模式指定新创建的容器和已经存在的一个容器共享一个 Network Namespace,而不是和宿主机共 享。新创建的容器不会创建自己的网卡,配置自己的 IP,而是和一个指定的容器共享 IP、端口范围等。 同样,两个容器除了网络方面,其他的如文件系统、进程列表等还是隔离的。两个容器的进程可以通过 lo 网卡设备通信。 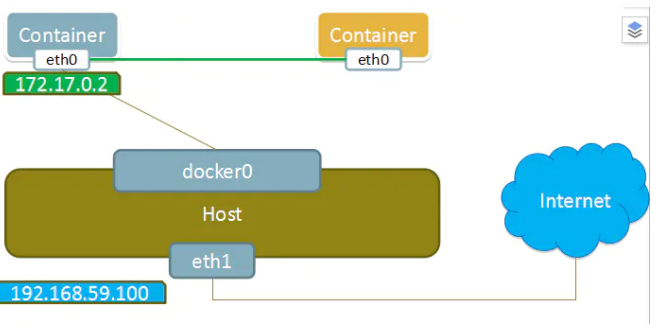
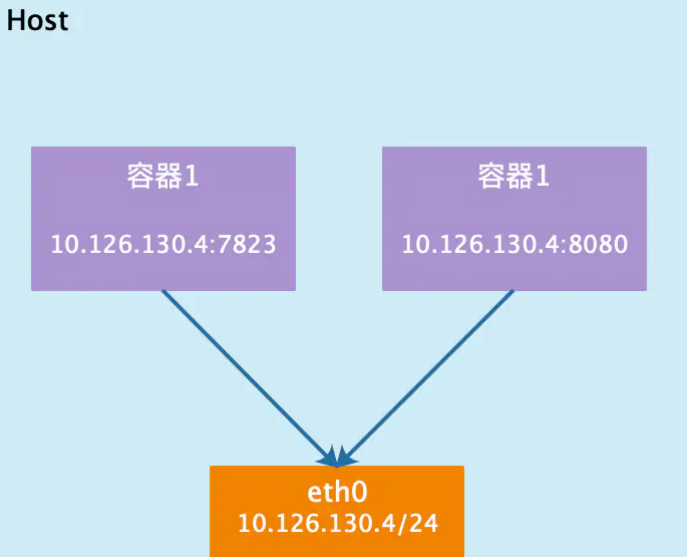
host网络类型:
bridge网络类型
当Docker进程启动时,会在主机上创建一个名为docker0的虚拟网桥,此主机上启动的Docker容器会连 接到这个虚拟网桥上。虚拟网桥的工作方式和物理交换机类似,这样主机上的所有容器就通过交换机连 在了一个二层网络中。 从docker0子网中分配一个IP给容器使用,并设置docker0的IP地址为容器的默认网关。在主机上创建一 对虚拟网卡veth pair设备,Docker将veth pair设备的一端放在新创建的容器中,并命名为eth0(容器 的网卡),另一端放在主机中,以vethxxx这样类似的名字命名,并将这个网络设备加入到docker0网桥 中。可以通过brctl show命令查看。
9.资源限制
对于linux主机如果没有足够的内存来执行其他重要的进程,则会抛出oom异常,随后系统将会开始杀死进程来释放内存,凡是运行在宿主机上的进程都会被kill掉。linux会为每个进程计算一个分数,分数越高越容易被杀掉,我们可以调整进程的分数以防止被杀掉
容器的内存限制
内存限制参数
- -m or —memory:容器可以使用的最大内存量,如果设置此选项,则允许的最小值为4m
- —memory-swap:容器可以使用的交换分区和物理内存大小总和,必须要在设置了物理内存限制 的前提才能设置交换分区的限制,经常将内存交换到磁盘的应用程序会降低性能。如果该参数设置 未-1,则容器可以使用主机上swap的最大空间
- —memory-swappiness:设置容器使用交换分区的倾向性,值越高表示越倾向于使用swap分区, 范围为0-100,0为能不用就不用,100为能用就用。
- —kernel-memory:容器可以使用的最大内核内存量,最小为4m,由于内核内存于用户空间内存 隔离,因此无法于用户空间内存直接交换,因此内核内存不足的容器可能会阻塞宿主机主机资源, 这会对主机和其他容器或者其他服务进程产生影响,因此不要设置内核内存大小
- —memory-reservation:允许指定小于—memory的软限制当Docker检测到主机上的争用或内存不 足时会激活该限制,如果使用—memory-reservation,则必须将其设置为低于—memory才能使其 优先。因为它是软限制,所以不能保证容器不超过限制。
—oom-kill-disable:默认情况下,发生OOM时kernel会杀死容器内进程,但是可以使用该参数可 以禁止oom发生在指定的容器上,仅在已设置-m选项的容器上禁用oom,如果-m参数未配置,产 生oom时主机为了释放内存还会杀死进程
#下载压测工具 docker pull lorel/docker-stress-ng #不限制的情况下,开启两个进程,每个占用256m docker run -it --rm --name test1 lorel/docker-stress-ng --vm 2 #检测每个进程的资源使用情况 [root@slave5 ~]# docker stats容器的CPU限制
一个宿主机,有几十个核心的cpu,但是宿主机上可以同时运行成百上千个不同的进程用以处理不同的任务。所以一个核心cpu可以通过调度而运行多个进程,但是在同一个单位时间内只能由一个进程在cpu上运行,那么这么多的任务是如何cpu上执行和调度的呢?(进程优先级)
对于一些比较重要的进程,我们想要它一直执行,这种情况下我们就可以人为干扰cpu上运行的进程。参数:
—cpus: 指定容器可以使用多少可用cpu资源,例如,如果主机有两个cpu,并且设置了— cpu=1.5,那么该容器将保证最多可以访问1.5个的cpu(如果是4核cpu,那么还可以是4核心上的 每核用一点,但是总计是1.5核心的cpu)
- —cpu-period:设置cpu的调度周期,必须于—cpu-quota一起使用
- —cpu-quota:在容器上添加cpu配额,计算方式为cpu-quota/cpu-period的结果值(现在通常使 用—cpus)
- —cpuset-cpus:用于指定容器运行的cpu编号,也就是所谓的绑核
- —cpuset-mem:设置使用哪个cpu的内存,仅对非统一内存访问(NUMA)架构有效。
- —cpu-shares:值越高的容器将会得到更多的时间片(宿主机多核cpu总数为100%,加入容器A为 1024,容器B为2048,那么容器B将最大时容器A的可以CPU的两倍),默认的时间片时2014,最大为262144
10.docker compose单机编排
stress命令:stress +option
命令图谱: [
[
](https://blog.csdn.net/qyf158236/article/details/110475457)
[
](https://blog.csdn.net/qyf158236/article/details/110475457)

若有收获,就点个赞吧
0 人点赞
