1、不熟悉的单词:
- go through
- terminology
-
Thinking About Data Systems
We typically think of databases, queues, caches, etc. as being very different categories of tools. Although a database and a message queue have some superficial similarity— both store data for some time—they have very different access patterns, which means different performance characteristics, and thus very different implementations. So why should we lump them all together under an umbrella term like data systems? Many new tools for data storage and processing have emerged in recent years. They are optimized for a variety of different use cases, and they no longer neatly fit into traditional categories [1]. For example, there are datastores that are also used as mes‐ sage queues (Redis), and there are message queues with database-like durability guar‐ antees (Apache Kafka). The boundaries between the categories are becoming blurred. Secondly, increasingly many applications now have such demanding or wide-ranging requirements that a single tool can no longer meet all of its data processing and stor‐ age needs. Instead, the work is broken down into tasks that can be performed effi‐ ciently on a single tool, and those different tools are stitched together using application code. For example, if you have an application-managed caching layer (using Memcached or similar), or a full-text search server (such as Elasticsearch or Solr) separate from your main database, it is normally the application code’s responsibility to keep those caches and indexes in sync with the main database. Figure 1-1 gives a glimpse of what this may look like (we will go into detail in later chapters).
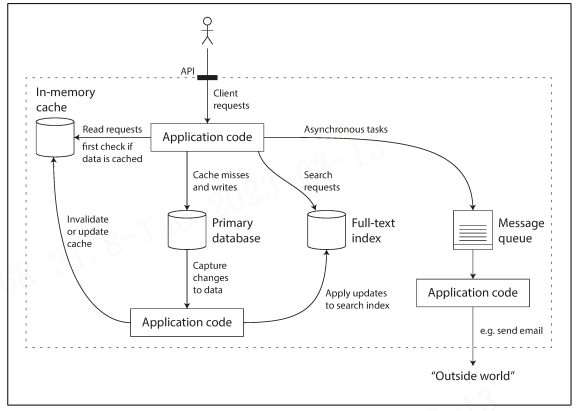
. One possible architecture for a data system that combines several componentsWhen you combine several tools in order to provide a service, the service’s interface or application programming interface (API) usually hides those implementation details from clients. Now you have essentially created a new, special-purpose data system from smaller, general-purpose components. Your composite data system may provide certain guarantees:
e.g., that the cache will be correctly invalidated or updated on writes so that outside clients see consistent results. You are now not only an application developer, but also a data system designer. If you are designing a data system or service, a lot of tricky questions arise. How do you ensure that the data remains correct and complete, even when things go wrong internally? How do you provide consistently good performance to clients, even when parts of your system are degraded? How do you scale to handle an increase in load? What does a good API for the service look like? There are many factors that may influence the design of a data system, including the skills and experience of the people involved, legacy system dependencies|(遗留系统), the time‐ scale for delivery(交付周期), your organization’s tolerance of different kinds of risk, regulatory constraints(法律限制), etc. Those factors depend very much on the situation.
In this book, we focus on three concerns that are important in most software systems:
Reliability
The system should continue to work correctly (performing the correct function at the desired level of performance) even in the face of adversity (hardware or soft‐ ware faults, and even human error). See “Reliability” on page 6.
Scalability
As the system grows (in data volume, traffic volume, or complexity), there should be reasonable ways of dealing with that growth. See “Scalability” on page 10.
Maintainability
Over time, many different people will work on the system (engineering and operations, both maintaining current behavior and adapting the system to new use cases), and they should all be able to work on it productively. See “Maintainabil‐ ity” on page 18.
These words are often cast around without a clear understanding of what they mean. In the interest of thoughtful engineering, we will spend the rest of this chapter exploring ways of thinking about reliability, scalability, and maintainability. Then, in the following chapters, we will look at various techniques, architectures, and algo‐ rithms that are used in order to achieve those goals

若有收获,就点个赞吧
0 人点赞
