在Redis为什么可以这么快 中大致总结了一下原因,本文将详细总结Redis中的底层数据结构
简单动态字符串 SDS
Redis 是用 C 语言写的,但是对于Redis的字符串,却不是 C 语言中的字符串(即以空字符’\0’结尾的字符数组),它是自己构建了一种名为 简单动态字符串(simple dynamic string,SDS)的抽象类型,并将 SDS 作为 Redis的默认字符串表示。
定义
这是一种用于存储二进制数据的一种结构, 具有动态扩容的特点. 其实现位于src/sds.h与src/sds.c中。
- DS的总体概览如下图:

其中sdshdr是头部, buf是真实存储用户数据的地方. 另外注意, 从命名上能看出来, 这个数据结构除了能存储二进制数据, 显然是用于设计作为字符串使用的, 所以在buf中, 用户数据后总跟着一个\0. 即图中 “数据” + “\0” 是为所谓的buf。
- 如下是6.0源码中sds相关的结构:
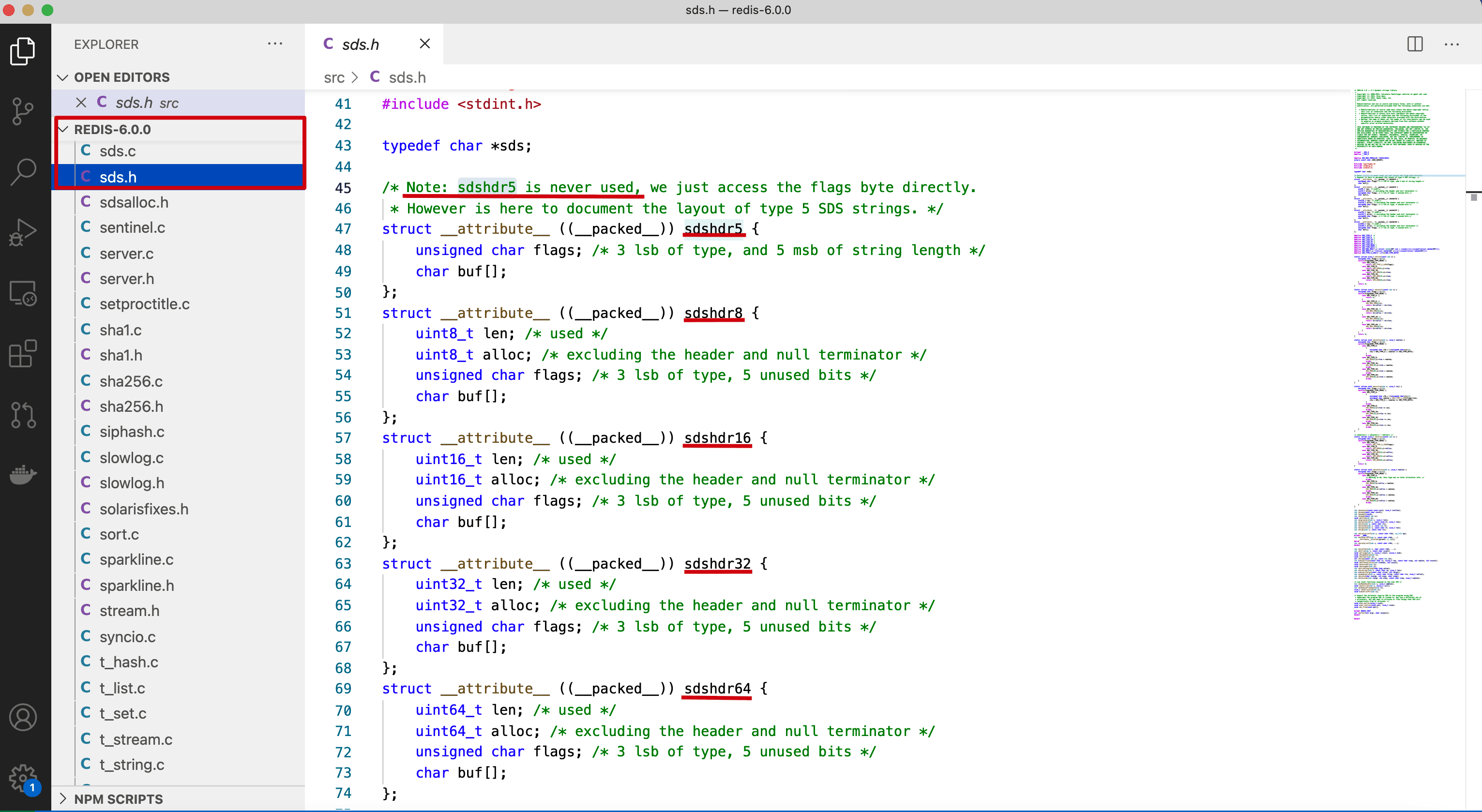
通过上图我们可以看到,SDS有五种不同的头部. 其中sdshdr5实际并未使用到. 所以实际上有四种不同的头部, 分别如下: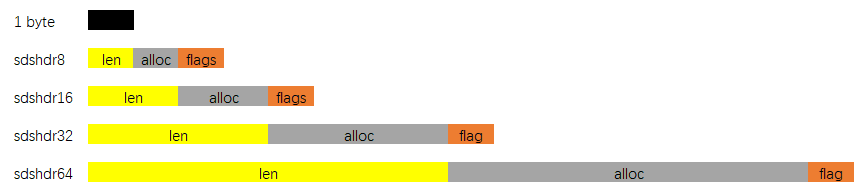
其中:
- len 保存了SDS保存字符串的长度
- buf[] 数组用来保存字符串的每个元素
- alloc分别以uint8, uint16, uint32, uint64表示整个SDS, 除过头部与末尾的\0, 剩余的字节数.
- flags 始终为一字节, 以低三位标示着头部的类型, 高5位未使用.
特点
- 常数复杂度获取字符串长度
由于 len 属性的存在,我们获取 SDS 字符串的长度只需要读取 len 属性,时间复杂度为 O(1)。而对于 C 语言,获取字符串的长度通常是经过遍历计数来实现的,时间复杂度为 O(n)。通过 strlen key 命令可以获取 key 的字符串长度。
- 杜绝缓冲区溢出
我们知道在 C 语言中使用 strcat 函数来进行两个字符串的拼接,一旦没有分配足够长度的内存空间,就会造成缓冲区溢出。而对于 SDS 数据类型,在进行字符修改的时候,会首先根据记录的 len 属性检查内存空间是否满足需求,如果不满足,会进行相应的空间扩展,然后在进行修改操作,所以不会出现缓冲区溢出。
- 减少修改字符串的内存重新分配次数
C语言由于不记录字符串的长度,所以如果要修改字符串,必须要重新分配内存(先释放再申请),因为如果没有重新分配,字符串长度增大时会造成内存缓冲区溢出,字符串长度减小时会造成内存泄露。
而对于SDS,由于len属性和alloc属性的存在,对于修改字符串SDS实现了空间预分配和惰性空间释放两种策略:
1、空间预分配:对字符串进行空间扩展的时候,扩展的内存比实际需要的多,这样可以减少连续执行字符串增长操作所需的内存重分配次数。
2、惰性空间释放:对字符串进行缩短操作时,程序不立即使用内存重新分配来回收缩短后多余的字节,而是使用 alloc 属性将这些字节的数量记录下来,等待后续使用。(当然SDS也提供了相应的API,当我们有需要时,也可以手动释放这些未使用的空间。)
- 二进制安全
因为C字符串以空字符作为字符串结束的标识,而对于一些二进制文件(如图片等),内容可能包括空字符串,因此C字符串无法正确存取;而所有 SDS 的API 都是以处理二进制的方式来处理 buf 里面的元素,并且 SDS 不是以空字符串来判断是否结束,而是以 len 属性表示的长度来判断字符串是否结束。
- 兼容部分 C 字符串函数
虽然 SDS 是二进制安全的,但是一样遵从每个字符串都是以空字符串结尾的惯例,这样可以重用 C 语言库
空间预分配补进一步理解
当执行追加操作时,比如现在给key=‘Hello World’的字符串后追加‘ again!’则这时的len=18,free由0变成了18,此时的buf=’Hello World again!\0………………..’(.表示空格),也就是buf的内存空间是18+18+1=37个字节,其中‘\0’占1个字节redis给字符串多分配了18个字节的预分配空间,所以下次还有append追加的时候,如果预分配空间足够,就无须在进行空间分配了。在当前版本中,当新字符串的长度小于1M时,redis会分配他们所需大小一倍的空间,当大于1M的时候,就为他们额外多分配1M的空间。
思考:这种分配策略会浪费内存资源吗?
答:执行过APPEND 命令的字符串会带有额外的预分配空间,这些预分配空间不会被释放,除非该字符串所对应的键被删除,或者等到关闭Redis 之后,再次启动时重新载入的字符串对象将不会有预分配空间。因为执行APPEND 命令的字符串键数量通常并不多,占用内存的体积通常也不大,所以这一般并不算什么问题。另一方面,如果执行APPEND 操作的键很多,而字符串的体积又很大的话,那可能就需要修改Redis 服务器,让它定时释放一些字符串键的预分配空间,从而更有效地使用内存。
ZipList
ziplist是为了提高存储效率而设计的一种特殊编码的双向链表。
- 它可以存储字符串或者整数,存储整数时是采用整数的二进制而不是字符串形式存储。
- 它能在O(1)的时间复杂度下完成list两端的push和pop操作。
- 因为每次操作都需要重新分配ziplist的内存,所以实际复杂度和ziplist的内存使用量相关。
ziplist结构
先看下6.0中对应的源码和介绍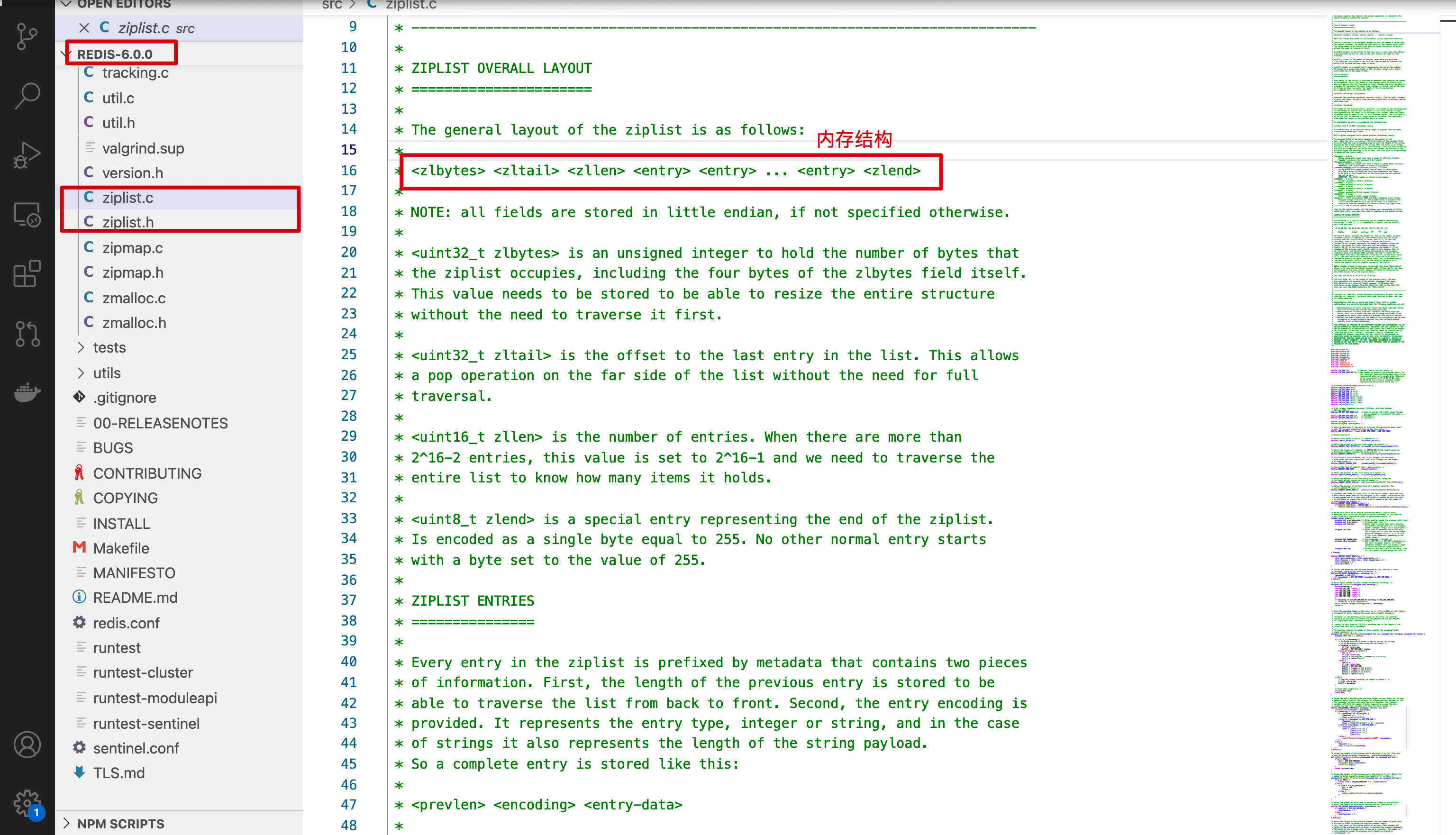
整个ziplist在内存中的存储格式如下 :
:
- zlbytes字段的类型是uint32_t, 这个字段中存储的是整个ziplist所占用的内存的字节数
- zltail字段的类型是uint32_t, 它指的是ziplist中最后一个entry的偏移量. 用于快速定位最后一个entry, 以快速完成pop等操作
- zllen字段的类型是uint16_t, 它指的是整个ziplit中entry的数量. 这个值只占2bytes(16位): 如果ziplist中entry的数目小于65535(2的16次方), 那么该字段中存储的就是实际entry的值. 若等于或超过65535, 那么该字段的值固定为65535, 但实际数量需要一个个entry的去遍历所有entry才能得到.
- zlend是一个终止字节, 其值为全F, 即0xff. ziplist保证任何情况下, 一个entry的首字节都不会是255
Entry结构
有点难度
为什么说ZipList特别省内存
- 连续存储:ZipList中所有元素都是按顺序连续存储的,这意味着ZipList不需要像链表那样为每个元素分配一个节点,从而节省了内存空间。
- 紧凑存储:ZipList中的每个元素都是按照一定规则进行编码的,比如整数可以使用1字节、2字节或5字节进行编码,字符串可以使用长度前缀和字节数组进行编码。这种紧凑的存储方式可以减少内存碎片和空间浪费。
缺点
- ziplist也不预留内存空间, 并且在移除结点后, 也是立即缩容, 这代表每次写操作都会进行内存分配操作.
- 结点如果扩容, 导致结点占用的内存增长, 并且超过254字节的话, 可能会导致链式反应: 其后一个结点的entry.prevlen需要从一字节扩容至五字节. 最坏情况下, 第一个结点的扩容, 会导致整个ziplist表中的后续所有结点的entry.prevlen字段扩容. 虽然这个内存重分配的操作依然只会发生一次, 但代码中的时间复杂度是o(N)级别, 因为链式扩容只能一步一步的计算. 但这种情况的概率十分的小, 一般情况下链式扩容能连锁反映五六次就很不幸了. 之所以说这是一个蛋疼问题, 是因为, 这样的坏场景下, 其实时间复杂度并不高: 依次计算每个entry新的空间占用, 也就是o(N), 总体占用计算出来后, 只执行一次内存重分配, 与对应的memmove操作, 就可以了
块表
quicklist这个结构是Redis在3.2版本后新加的, 之前的版本是list(即linkedlist), 用于String数据类型中。
这里定义了6个结构体:
- quicklistNode, 宏观上, quicklist是一个链表, 这个结构描述的就是链表中的结点. 它通过zl字段持有底层的ziplist. 简单来讲, 它描述了一个ziplist实例
- quicklistLZF, ziplist是一段连续的内存, 用LZ4算法压缩后, 就可以包装成一个quicklistLZF结构. 是否压缩quicklist中的每个ziplist实例是一个可配置项. 若这个配置项是开启的, 那么quicklistNode.zl字段指向的就不是一个ziplist实例, 而是一个压缩后的quicklistLZF实例
- quicklistBookmark, 在quicklist尾部增加的一个书签,它只有在大量节点的多余内存使用量可以忽略不计的情况且确实需要分批迭代它们,才会被使用。当不使用它们时,它们不会增加任何内存开销。
- quicklist. 这就是一个双链表的定义. head, tail分别指向头尾指针. len代表链表中的结点. count指的是整个quicklist中的所有ziplist中的entry的数目. fill字段影响着每个链表结点中ziplist的最大占用空间, compress影响着是否要对每个ziplist以LZ4算法进行进一步压缩以更节省内存空间.
- quicklistIter是一个迭代器
- quicklistEntry是对ziplist中的entry概念的封装. quicklist作为一个封装良好的数据结构, 不希望使用者感知到其内部的实现, 所以需要把ziplist.entry的概念重新包装一下.
哈希
- 解决冲突:采用链表法解决冲突问题
- 扩容和收缩:
- 如果执行扩展操作,会基于原哈希表创建一个大小等于 ht[0].used*2n 的哈希表(也就是每次扩展都是根据原哈希表已使用的空间扩大一倍创建另一个哈希表)。相反如果执行的是收缩操作,每次收缩是根据已使用空间缩小一倍创建一个新的哈希表。
- 重新利用上面的哈希算法,计算索引值,然后将键值对放到新的哈希表位置上。
- 所有键值对都迁徙完毕后,释放原哈希表的内存空间。
- 扩容条件:
- 服务器目前没有执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且负载因子大于等于1。
- 服务器目前正在执行 BGSAVE 命令或者 BGREWRITEAOF 命令,并且负载因子大于等于5。
- 渐进式 rehash:
- 什么叫渐进式 rehash?也就是说扩容和收缩操作不是一次性、集中式完成的,而是分多次、渐进式完成的。
- 但是如果键值对有几百万,几千万甚至几亿,那么要一次性的进行 rehash,势必会造成Redis一段时间内不能进行别的操作。
- 字典的删除查找更新等操作可能会在两个哈希表上进行,第一个哈希表没有找到,就会去第二个哈希表上进行查找。但是进行 增加操作,一定是在新的哈希表上进行的。
—

若有收获,就点个赞吧
0 人点赞
