1、线程和进程
1.1进程和线程的关系
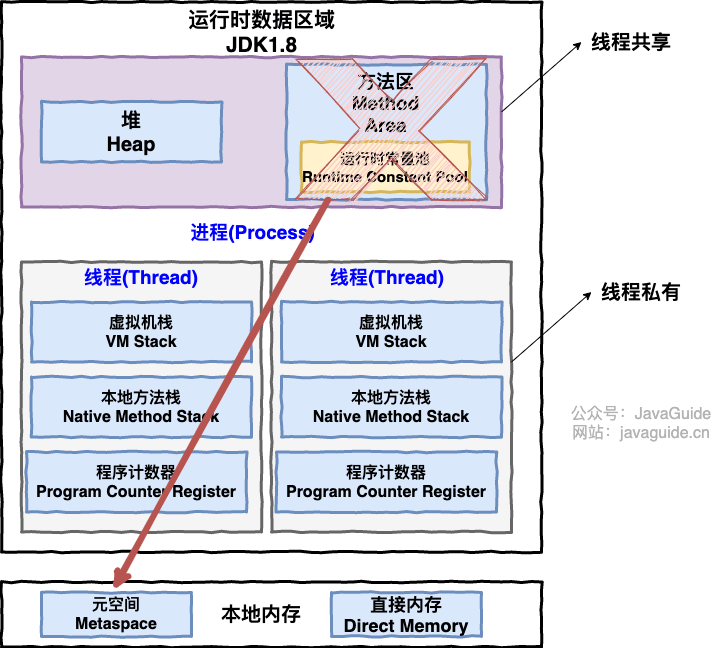
从上图可以看出:一个进程中可以有多个线程,多个线程共享进程的堆和方法区 (JDK1.8 之后的元空间)资源,但是每个线程有自己的程序计数器、虚拟机栈 和 本地方法栈。
总结:线程是进程划分成的更小的运行单位。线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。线程执行开销小,但不利于资源的管理和保护;而进程正相反。
1.2、程序计数器为什么是私有的
作用:
- 字节码解释器通过改变程序计数器来依次读取指令,从而实现代码的流程控制,如:顺序执行、选择、循环、异常处理。
- 在多线程的情况下,程序计数器用于记录当前线程执行的位置,从而当线程被切换回来的时候能够知道该线程上次运行到哪儿了。
需要注意的是,如果执行的是 native 方法,那么程序计数器记录的是 undefined 地址,只有执行的是 Java 代码时程序计数器记录的才是下一条指令的地址。
所以,程序计数器私有主要是为了线程切换后能恢复到正确的执行位置
1.3、虚拟机栈和本地方法栈为什么是私有的?
- 虚拟机栈: 每个 Java 方法在执行的同时会创建一个栈帧用于存储局部变量表、操作数栈、常量池引用等信息。从方法调用直至执行完成的过程,就对应着一个栈帧在 Java 虚拟机栈中入栈和出栈的过程。
- 本地方法栈: 和虚拟机栈所发挥的作用非常相似,区别是: 虚拟机栈为虚拟机执行 Java 方法 (也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。 在 HotSpot 虚拟机中和 Java 虚拟机栈合二为一。
所以,为了保证线程中的局部变量不被别的线程访问到,虚拟机栈和本地方法栈是线程私有的。
1.4、一句话简单了解堆和方法区
堆和方法区是所有线程共享的资源,其中堆是进程中最大的一块内存,主要用于存放新创建的对象 (几乎所有对象都在这里分配内存),方法区主要用于存放已被加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
2、多线程
2.1、基本概念
并发与并行的区别
- 并发:两个及两个以上的作业在同一 时间段 内执行。
- 并行:两个及两个以上的作业在同一 时刻 执行。
# 同步和异步的区别
- 同步 : 发出一个调用之后,在没有得到结果之前, 该调用就不可以返回,一直等待。
-
# 为什么要使用多线程呢?
先从总体上来说:
从计算机底层来说: 线程可以比作是轻量级的进程,是程序执行的最小单位,线程间的切换和调度的成本远远小于进程。另外,多核 CPU 时代意味着多个线程可以同时运行,这减少了线程上下文切换的开销。
- 从当代互联网发展趋势来说: 现在的系统动不动就要求百万级甚至千万级的并发量,而多线程并发编程正是开发高并发系统的基础,利用好多线程机制可以大大提高系统整体的并发能力以及性能。
再深入到计算机底层来探讨:
- 单核时代: 在单核时代多线程主要是为了提高单进程利用 CPU 和 IO 系统的效率。 假设只运行了一个 Java 进程的情况,当我们请求 IO 的时候,如果 Java 进程中只有一个线程,此线程被 IO 阻塞则整个进程被阻塞。CPU 和 IO 设备只有一个在运行,那么可以简单地说系统整体效率只有 50%。当使用多线程的时候,一个线程被 IO 阻塞,其他线程还可以继续使用 CPU。从而提高了 Java 进程利用系统资源的整体效率。
- 多核时代: 多核时代多线程主要是为了提高进程利用多核 CPU 的能力。举个例子:假如我们要计算一个复杂的任务,我们只用一个线程的话,不论系统有几个 CPU 核心,都只会有一个 CPU 核心被利用到。而创建多个线程,这些线程可以被映射到底层多个 CPU 上执行,在任务中的多个线程没有资源竞争的情况下,任务执行的效率会有显著性的提高,约等于(单核时执行时间/CPU 核心数)。
# 使用多线程可能带来什么问题?
并发编程的目的就是为了能提高程序的执行效率提高程序运行速度,但是并发编程并不总是能提高程序运行速度的,而且并发编程可能会遇到很多问题,比如:内存泄漏、死锁、线程不安全等等。
什么是上下文切换?
线程在执行过程中会有自己的运行条件和状态(也称上下文),比如上文所说到过的程序计数器,栈信息等。当出现如下情况的时候,线程会从占用 CPU 状态中退出。
- 主动让出 CPU,比如调用了 sleep(), wait() 等。
- 时间片用完,因为操作系统要防止一个线程或者进程长时间占用 CPU 导致其他线程或者进程饿死。
- 调用了阻塞类型的系统中断,比如请求 IO,线程被阻塞。
- 被终止或结束运行
这其中前三种都会发生线程切换,线程切换意味着需要保存当前线程的上下文,留待线程下次占用 CPU 的时候恢复现场。并加载下一个将要占用 CPU 的线程上下文。这就是所谓的 上下文切换。
上下文切换是现代操作系统的基本功能,因其每次需要保存信息恢复信息,这将会占用 CPU,内存等系统资源进行处理,也就意味着效率会有一定损耗,如果频繁切换就会造成整体效率低下。
1.2、线程的生命周期和状态
- 线程初始状态:NEW
- 线程运行状态:RUNNABLE
- 线程阻塞状态:BLOCKED
- 线程等待状态:WAITING
- 超时等待状态:TIMED_WAITING
- 线程终止状态:TERMINATED
线程进入等待状态,即线程因为某种原因放弃了CPU使用权,阻塞也分为几种情况:
- 等待阻塞:运行的线程执行wait方法,JVM会把当前线程放入到等待队列
- 同步阻塞:运行的线程在获取对象的同步锁时,若该同步锁被其他线程锁占用了,那么JVM会把当前的线程放入到锁池中
- 其他阻塞:运行的线程执行Thread.sleep或者join方法,或者发出了I/O请求时,JVM会把当前线程设置为阻塞状态,当sleep结束join线程终止、I/O处理完毕则线程恢复
线程状态间的转换如下图: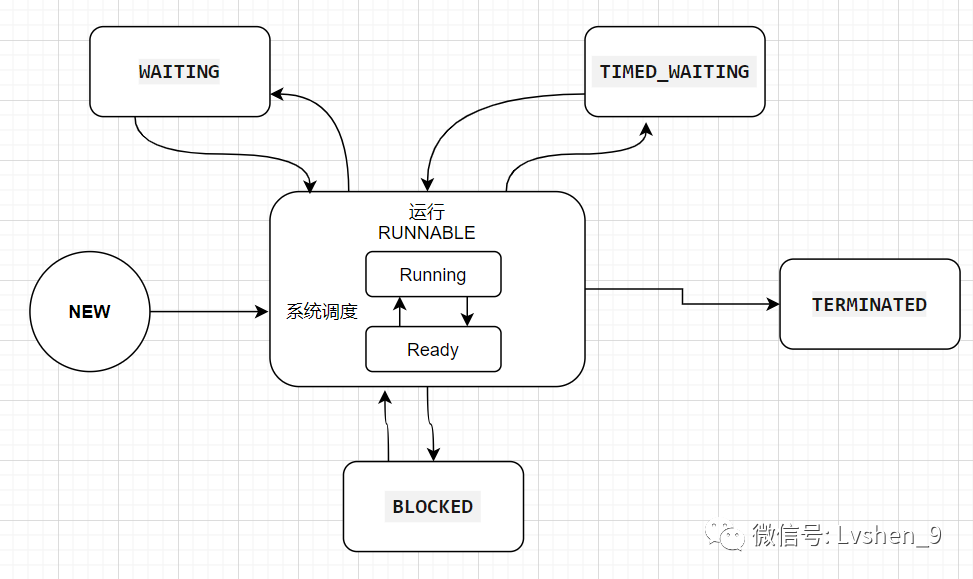
2.3、死锁
死锁的四个必要条件:
- 互斥条件:该资源任意一个时刻只由一个线程占用。
- 请求与保持条件:一个线程因请求资源而阻塞时,对已获得的资源保持不放。
- 不剥夺条件:线程已获得的资源在未使用完之前不能被其他线程强行剥夺,只有自己使用完毕后才释放资源。
- 循环等待条件:若干线程之间形成一种头尾相接的循环等待资源关系
如何预防死锁? 破坏死锁的产生的必要条件即可:
- 破坏请求与保持条件 :一次性申请所有的资源。
- 破坏不剥夺条件 :占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源。
- 破坏循环等待条件 :靠按序申请资源来预防。按某一顺序申请资源,释放资源则反序释放。破坏循环等待条件。
如何避免死锁?
避免死锁就是在资源分配时,借助于算法(比如银行家算法)对资源分配进行计算评估,使其进入安全状态。
安全状态 指的是系统能够按照某种线程推进顺序(P1、P2、P3…..Pn)来为每个线程分配所需资源,直到满足每个线程对资源的最大需求,使每个线程都可顺利完成。称
2.4、sleep() 方法和 wait() 方法对比
共同点 :两者都可以暂停线程的执行。
区别 :
- sleep() 方法没有释放锁,而 wait() 方法释放了锁 。
- wait() 通常被用于线程间交互/通信,sleep()通常被用于暂停执行。
- wait() 方法被调用后,线程不会自动苏醒,需要别的线程调用同一个对象上的 notify()或者 notifyAll() 方法。sleep()方法执行完成后,线程会自动苏醒,或者也可以使用 wait(long timeout) 超时后线程会自动苏醒。
- sleep() 是 Thread 类的静态本地方法,wait() 则是 Object 类的本地方法。为什么这样设计呢?
1、这两个方法来自不同的类分别是,sleep来自Thread类,和wait来自Object类。
sleep是Thread的静态类方法,谁调用的谁去睡觉,即使在a线程里调用了b的sleep方法,实际上还是a去睡觉,要让b线程睡觉要在b的代码中调用sleep。
2、最主要是sleep方法没有释放锁,而wait方法释放了锁,使得其他线程可以使用同步控制块或者方法。
sleep不出让系统资源;wait是进入线程等待池等待,出让系统资源,其他线程可以占用CPU。一般wait不会加时间限制,因为如果wait线程的运行资源不够,再出来也没用,要等待其他线程调用notify/notifyAll唤醒等待池中的所有线程,才会进入就绪队列等待OS分配系统资源。sleep(milliseconds)可以用时间指定使它自动唤醒过来,如果时间不到只能调用interrupt()强行打断。
Thread.Sleep(0)的作用是“触发操作系统立刻重新进行一次CPU竞争”。
3、使用范围:wait,notify和notifyAll只能在同步控制方法或者同步控制块里面使用,而sleep可以在任何地方使用
synchronized(x){
x.notify()
//或者wait()
}
4、sleep必须捕获异常,而wait,notify和notifyAll不需要捕获异常
sleep(100L)是占用cpu,线程休眠100毫秒,其他进程不能再占用cpu资源,wait(100L)是进入等待池中等待,交出cpu等系统资源供其他进程使用,在这100毫秒中,该线程可以被其他线程notify,但不同的是其他在等待池中的线程不被notify不会出来,但这个线程在等待100毫秒后会自动进入就绪队列等待系统分配资源,换句话说,sleep(100)在100毫秒后肯定会运行,但wait在100毫秒后还有等待os调用分配资源,所以wait100的停止运行时间是不确定的,但至少是100毫秒。
# 为什么 wait() 方法不定义在 Thread 中?
wait() 是让获得对象锁的线程实现等待,会自动释放当前线程占有的对象锁。每个对象(Object)都拥有对象锁,既然要释放当前线程占有的对象锁并让其进入 WAITING 状态,自然是要操作对应的对象(Object)而非当前的线程(Thread)。
类似的问题:为什么 sleep() 方法定义在 Thread 中?
因为 sleep() 是让当前线程暂停执行,不涉及到对象类,也不需要获得对象锁。
# 可以直接调用 Thread 类的 run 方法吗?
这是另一个非常经典的 Java 多线程面试问题,而且在面试中会经常被问到。很简单,但是很多人都会答不上来!
new 一个 Thread,线程进入了新建状态。调用 start()方法,会启动一个线程并使线程进入了就绪状态,当分配到时间片后就可以开始运行了。 start() 会执行线程的相应准备工作,然后自动执行 run() 方法的内容,这是真正的多线程工作。 但是,直接执行 run() 方法,会把 run() 方法当成一个 main 线程下的普通方法去执行,并不会在某个线程中执行它,所以这并不是多线程工作。
总结: 调用 start() 方法方可启动线程并使线程进入就绪状态(就绪队列),直接执行 run() 方法的话不会以多线程的方式执行。
3、关键字
3.1、volatile 关键字
如何保证变量的可见性?
在 Java 中,volatile 关键字可以保证变量的可见性,如果我们将变量声明为 volatile ,这就指示 JVM,这个变量是共享且不稳定的,每次使用它都到主存中进行读取。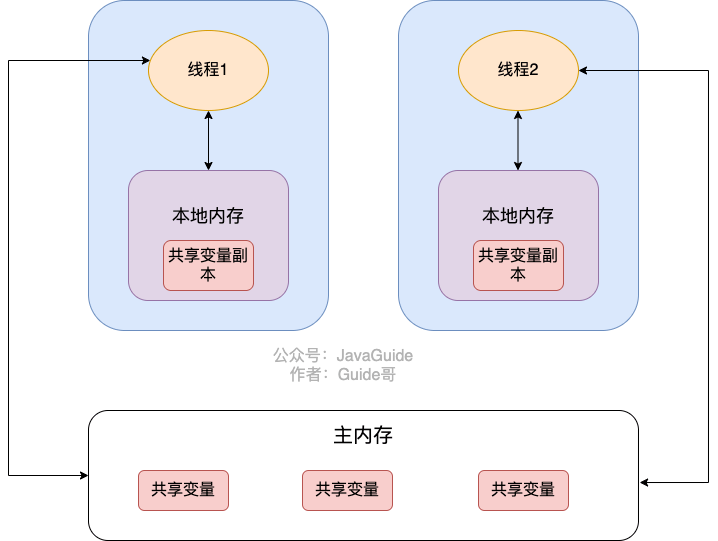
volatile 关键字其实并非是 Java 语言特有的,在 C 语言里也有,它最原始的意义就是禁用 CPU 缓存。如果我们将一个变量使用 volatile 修饰,这就指示 编译器,这个变量是共享且不稳定的,每次使用它都到主存中进行读取。
volatile 关键字能保证数据的可见性,但不能保证数据的原子性。synchronized 关键字两者都能保证。
如何禁止指令重排序?
什么是指令重排:
在创建对象时,例如: Cache cache=new Cache() 这行代码并不是原子指令,使用 javap -c 指令,可以快速查看字节码。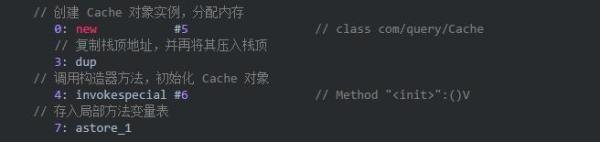
从字节码可以看到创建一个对象实例,可以分为三步:
- 分配对象内存
- 调用构造器方法,执行初始化
- 将对象引用赋值给变量。
虚拟机实际运行时,以上指令可能发生重排序。以上代码 2,3 可能发生重排序,但是并不会重排序 1 的顺序。也就是说 1 这个指令都需要先执行,因为 2,3 指令需要依托 1 指令执行结果。
Java 语言规规定了线程执行程序时需要遵守 intra-thread semantics。intra-thread semantics 保证重排序不会改变单线程内的程序执行结果。这个重排序在没有改变单线程程序的执行结果的前提下,可以提高程序的执行性能。
虽然重排序并不影响单线程内的执行结果,但是在多线程的环境就带来一些问题。
voltile禁用指令重排
在 Java 中,volatile 关键字除了可以保证变量的可见性,还有一个重要的作用就是防止 JVM 的指令重排序。 如果我们将变量声明为 volatile ,在对这个变量进行读写操作的时候,会通过插入特定的 内存屏障 的方式来禁止指令重排序。
在 Java 中,Unsafe 类提供了三个开箱即用的内存屏障相关的方法,屏蔽了操作系统底层的差异:
public native void loadFence();public native void storeFence();public native void fullFence();
双重校验锁实现对象单例(线程安全)
public class Singleton {private volatile static Singleton uniqueInstance;private Singleton() {}public static Singleton getUniqueInstance() {//先判断对象是否已经实例过,没有实例化过才进入加锁代码if (uniqueInstance == null) {//类对象加锁synchronized (Singleton.class) {if (uniqueInstance == null) {uniqueInstance = new Singleton();}}}return uniqueInstance;}}

若有收获,就点个赞吧
0 人点赞
