tags: [知识追踪, LANA]
categories: [知识追踪, LANA]
一、研究背景/目的
However, DKT often ignores the inherent differences between students (e.g. memory skills, reasoning skills, …), averaging the performances of all students, leading to the lack of personalization, and therefore was considered insufficient for adaptive learning. DKT only trains a unified model for all students due to massive training data and abundant computing resources required by deep learning. Hence, DKT weakly reflects the large inherent property (i.e. memory skills, reasoning skills, or even guessing skills) gaps between students.
Furthermore, the lack of adaptability in DKT is actually a setback since both BKT and IRT have such an ability by assigning different models to different students. LANA was therefore proposed, to bringing personalization back to DKT.
1.2 研究问题
Is it possible to bring personalization back to DKT?
二、解决方案
为了解决这一问题,本文提出了层次注意知识追踪(Leveled Attention KNowledge TrAcing, LANA),该方法首先使用一种新颖的学生相关特征提取器(student-related feature extractor, SRFE),从学生各自的交互序列中提取出学生独特的固有属性(记忆相关特征+表现相关特征(Logical thinking skill, Reasoning skill, Integration skill, etc.))。其次,利用pivot模块根据提取的特征对神经网络的解码器进行动态重构,成功地区分了学生随时间的表现。此外,在项目反应理论(IRT)的启发下,采用可解释的Rasch模型按能力水平对学生进行分组,从而利用分级学习为不同的学生群体分配不同的编码。利用pivot模块重构了针对个体的解码器,并为群体设置了学习专用编码器,实现了个性化的DKT。
Motivated by the observation that the proactive behavior sequence (i.e. interactive sequences) of each individual is unique and changeable over time, we argue that the minimal personalized unit in KT is “a student at a certain time ti” instead of just “a student” , and student’s inherent properties at time ti can be represented by his interactive sequences around time ti. In such a way, these student-related features could tremendously help personalize the KT process since they could be used to identify different students at different stages. Consequently, in our proposed Leveled Attentive KNowledge TrAcing (LANA), unique student-related features are distilled from students’ interactive sequence by a Student-Related Features Extractor (SRFE). Moreover, inspired by BKT and IRT that assign completely different models to different students, LANA, as a DKT model, successfully achieves the same goal in a different manner. Detailedly, instead of separately training each student a model like BKT and IRT,LANA learns to learn correlations between inputs and outputs on attention of the extracted student related features, and thus becomes transformable for different students at different stages. More specifically, the transformation was accomplished using pivot module and leveled learning, where the former one is a model component that seriously relies on the SRFE, and the latter one is a training mechanism that specializes encoders for groups with interpretable Rasch model defined ability levels. Formally, the LANA can be represented by:
三、主要贡献
1、To the best of our knowledge, LANA was the first proposal to distill student-related features from their respective interactive sequences by a novel Student Related Features Extractor (SRFE), exceedingly reducing the difficulty of achieving personalized KT.
2、With distilled unique student-related features, novel pivot module and leveled learning were utilized in LANA to make the whole model transformable for different students at different stages, bringing strong adaptability to the DKT domain.
3、Extensive experiments were conducted on two real world large-scale KT datasets in comparison with other State-Of-The-Art KT methods. The results demonstrated that LANA outperforms any other KT methods substantially. Ablation studies were also performed to investigate the impact of different key components in LANA. The source code and hyper-parameters of experiments are open-sourced for reproducibility.
4、Visualizations of the intermediate features suggest extra impacts of LANA, such as learning stages transfer and learning path recommendation.
四、METHODOLOGY
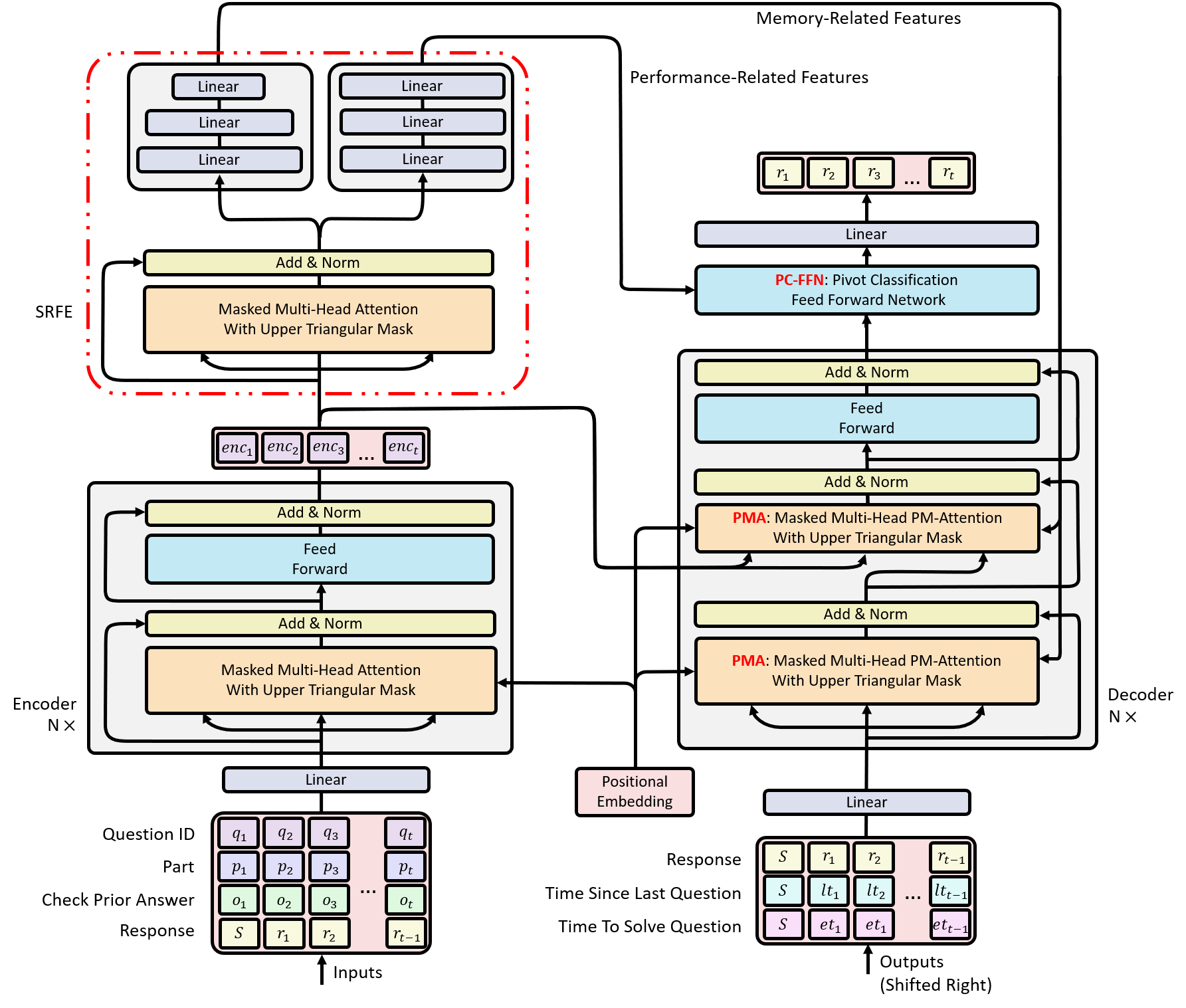
Figure 2: The overall model architecture of LANA. There are mainly three differences compared to vanilla transformer-based KT method [2, 26]: I. Modifications to the basic transformer model. II. Introduced SRFE and III. Introduced Pivot Memory Attention (PMA) Module and Pivot Classification Feed Forward Network (PC-FFN) Module, which collectively referred to as pivot module.
4.1 Overview
LANA method is composed of a LANA model and a training mechanism. LANA model, like SAINT+ [26], is a transformer [31] based KT model. However, different from the SAINT+, the LANA model has mainly 3 improvements: I. LANA model considers KT’s characteristics, and therefore makes modifications to the basic transformer model, such as feeding positional embedding directly into attention modules. II. LANA model uses a novel SRFE to abstract necessary student-related features from the input sequence. III. LANA model utilizes pivot module and extracted student-related features to dynamically construct different decoders for different students. With the reconstructed decoder, retrieved knowledge states, and other contextual information, corresponding personalized responses for future exercises are predicted.
While the pivot module can help the LANA model transform the decoder in terms of students’ inherent properties, the encoder, on the other hand, is fixed for all students after the training. Consequently, a leveled learning mechanism was proposed to address this problem by specializing different encoders and SRFEs to different groups of students with interpretable Rasch model defined student’s ability level. The workflow of the leveled learning was illustrated in Figure 3.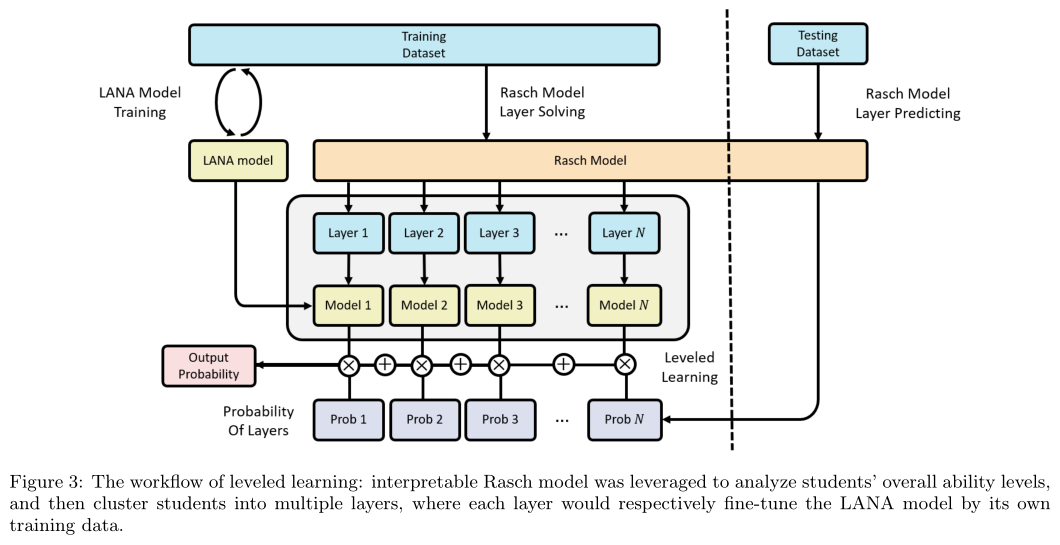
4.2 Base Modifications
There are mainly two base modifications in the LANA model that were made to the basic transformer. Firstly, in the LANA model, the positional information (e.g. positional encoding, positional embedding) was directly fed into the attention module with a private linear projection, instead of being added to the input embedding and shared the same linear projection matrix with other features in the input layer. In the LANA model, multiple input embeddings (i.e. question ID embedding, student ID embedding, etc.) are concatenated instead of added, leading to the second base modification. Specifically, assumes there are m input embeddings in total, each with a dimension of Df. Then after concatenating, the input embedding would have a total dimension of Dmf. Hence, a Dmf→Df linear projection layer was used to map the concatenated input embedding of dimension Dmf to dimension Df.
4.3 Student-Related Features Extractor (SRFE)
Inspired by the observation that the proactive behavior sequence of each student actually reflects some of his inner properties, we argue that I. interactive sequences of different students at the same time period are distinguishable (distinctive), and II. interactive sequences of the same student at different time periods are also distinguishable, as long as it satisfies a. the features in an interaction is sufficient enough, b. the length of the interactive sequence is large enough, and c. the time interval of the same student’s sequences is long enough. Accordingly, students’ interactive sequences can be used to identify their own, and summarize the student-related features. As a result, a mild assumption was made for the latter analysis: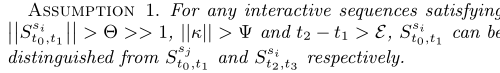
General Attention Mechanism (e.g., SAINT, SAINT+) = Vanilla Memory Attention (VMA) module
Monotonic Attention Mechanism = Pivot Memory Attention (PMA)
Pivot Memory Attention (PMA) Module + Pivot Classification Feed Forward Network (PC-FFN) Module = Pivot Module
In the LANA model there were primarily two SRFEs: memory-SRFE and performance-SRFE, where the former one was utilized to derive students’ memory-related features for the PMA module (be introduced later) and the latter one was dedicated to distill students’ performance related features (i.e. Logical thinking skill, Reasoning skill, Integration skill, etc.) for PC-FFN module (introduced later either).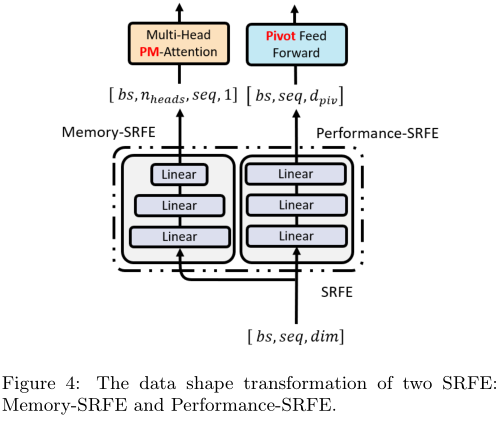
The intuition that memory-related features have a second dimension of n head comes from the theory that each attention head only pays attention to one perspective of the features. ???
Thus it is reasonable that each student has different memory skills for different attention heads (e.g. for different concepts). 意思是:
4.4 Pivot Module
Provided an ordinary input x, a student-related features p and a target output y, pivot module learns the process of learning how to project x to y based on p, instead of simply learning to project x to y (i.e. Pivot module learns to learn)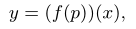
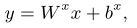
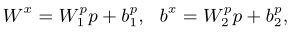
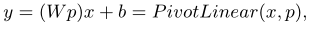

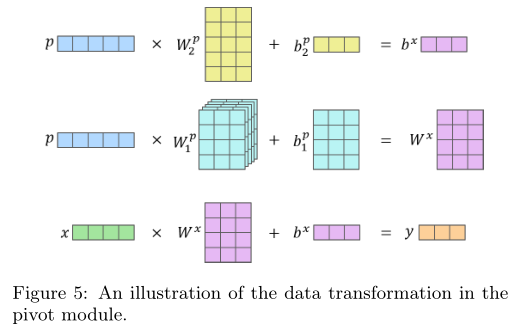
Pivot Memory Attention (PMA) Module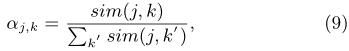
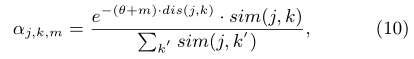

Pivot Classification Feed Forward Network (PC-FFN) Module
补充知识:前馈神经网络(FFN,feedforward neural network),又称作深度前馈网络(deep feedforward network)、多层感知机(MLP,multilayer perceptron),也叫人工神经网络(ANN,Artificial Neural Network)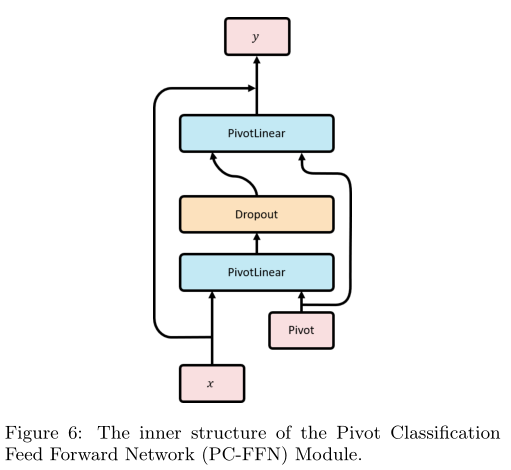

4.5 Leveled Learning
Inspired by the fine-tuning mechanism in transfer learning
The encoder and the SRFE of the LANA model that provides necessary information for the pivot module remains the same for all students. This is not problematic if the length of the input sequence is large enough since Assumption 1 assures long sequences are always distinguishable, unless they both belong to the same student at the same time period. However, DKT, especially transformer-based DKT, can only be inputted with the latest n(commonly n= 100) interactions at once due to the limited memory size and high computational complexity. To alleviate this problem, it is natural to think of assigning different students with different encoders and SRFEs that are highly specialized (sensitive) to their assigned students’ patterns.
LANA首先利用可解释的Rasch模型分析每个学生 的能力水平
的能力水平 ,然后将学生分组到不同的独立层次
,然后将学生分组到不同的独立层次 。假设所有学生的能力分布为服从
。假设所有学生的能力分布为服从 和
和 的高斯分布,则有公式12:
的高斯分布,则有公式12: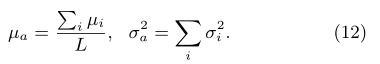




5. EXPERIMENTS
5.1 Experimental Setup
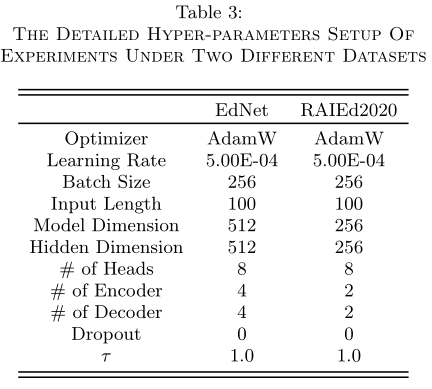
Datasets
The input featuresκ in EdNet contains Question ID,Question part,Students’ responses,Time interval between two consecutive interactions and Elapsed time of an interaction, whereas in RAIEd2020, a new feature is additionally added to κ, which indicates Whether or not the student check the correct answer to the previous question.
5.2 Results And Analysis
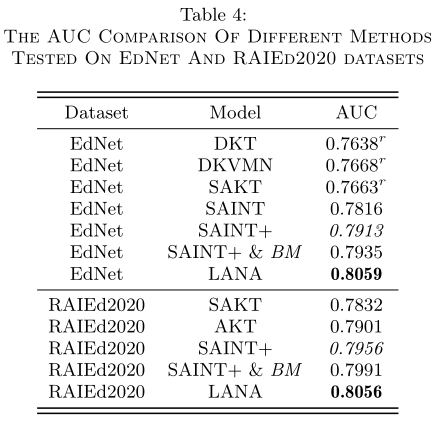
5.3 Ablation Studies
从该实验结果来看,感觉leveled learing作用不太大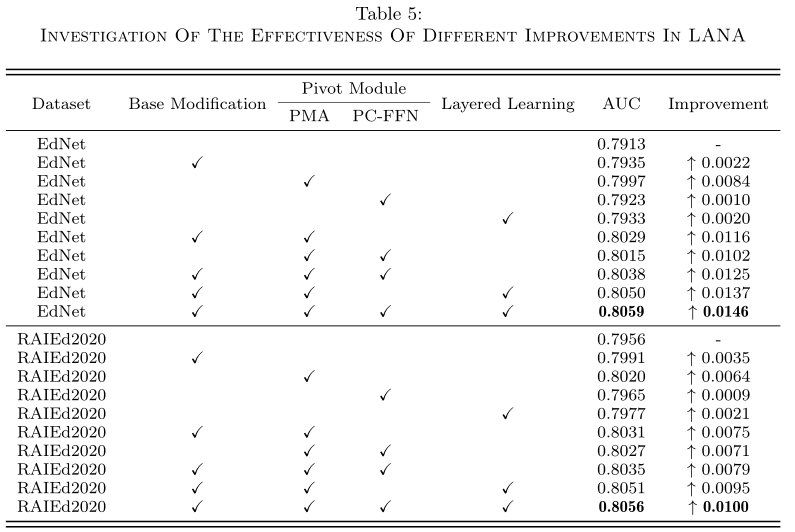
5.4 Features Visualization
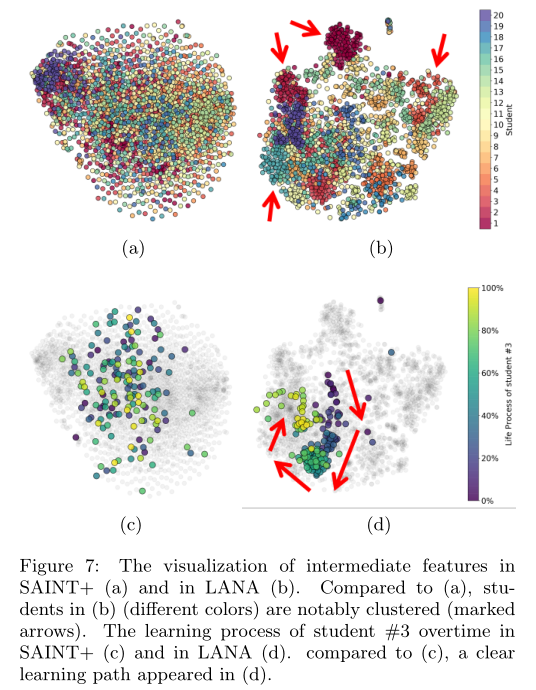

若有收获,就点个赞吧
0 人点赞
