tags: [知识追踪, DSCMN]
categories: [知识追踪, DSCMN]
Abstract
知识追踪(Knowledge Tracing, KT)是对学生的知识状态进行评估,并根据其学习过程中以前的一些练习和结果来预测该学生是否能正确回答下一个问题。KT利用机器学习和数据挖掘技术来提供更好的评估、支持性学习反馈和适应性指导。本文提出了一种新的知识追踪模型—记忆网络动态学生分类(Dynamic Student Classification on Memory Networks, DSCMN),该模型通过捕捉学生长期学习过程中每个时间间隔的时间学习能力来改进现有的KT方法。实验结果证实,该模型在预测学生表现方面明显优于目前最先进的KT建模技术。
Keywords: Massive open online courses, Knowledge tracing, Key-value memory networks, Student clustering, LSTMs
1 Introduction
引导人高效、有效地解决问题是教育研究中反复出现的话题。知识追踪(KT)在这个研究界获得了可信度,在学习过程中提供了适当的和适应性的指导。KT的目标是评估是否掌握了技能,并利用这些信息来定制学习经验,无论是在MOOC,导学系统还是在网络上,结果应用的一些例子。例如,当“1+2×3.5=?”这样的问题给定一个学生,她必须掌握加法和乘法的技能才能解决这道题。得到正确答案的概率主要取决于这道题背后这两项技能的掌握程度。掌握一项技能可以通过做有关这项技能的练习来实现。知识追踪的目标是根据学生先前练习的观察结果来追踪他们的知识状态[5]。这项任务也称为学生建模。KT的研究可以追溯到20世纪70年代末,人们已经探索了大量的人工智能和知识表示技术[3,14]。在学生在与系统交互时学习的环境中(特别是在MOOC等学习环境中),对学生技能掌握情况进行建模涉及时间维度。例如,涉及相同技能集的序列问题一开始可能会失败,但后来会成功,因为学生的技能掌握程度有所提高。然而,其他因素也会影响成功的结果,比如两个问题的难度、遗忘、猜想和失误,以及一系列其他因素,如果不考虑这些因素,就会导致噪音[11,12]。
KT在学习环境中的动态特性导致了能够对时态或顺序数据建模的方法。本文提出了一种新的知识追踪模型—动态学生分类记忆网络(DSCMN)。该模型能够捕捉学生长期记忆中的时间学习能力,同时评估学生对知识状态的掌握程度。时间学习能力是指特定技能的学习速度。这可能与车轮旋转(wheel spinning)之类的现象有关,在这种现象下,学生即使多次尝试也无法学会一项技能[17]。它依靠RNN架构来提高性能预测。我们的假设是,学习能力可以随着时间的推移而变化,追踪这一因素可以帮助预测未来的表现。
本文的其余部分组织如下。第二节回顾了通过数据预测学生表现的学生建模技术的相关工作。第三部分介绍了所提出的DSCMN模型。第4节提到了使用的实验数据集。第五节描述了实验结果,第六节总结了本文的工作,并讨论了未来的研究方向。
2 Knowledge Tracing
成功的学习环境如认知导师系列和ASSISTments平台,都依赖于某种形式的KT[6]。在这些系统中,每个问题都标有正确回答该问题所需的基本技能。KT可以看作是有监督的顺序学习问题的任务,其中模型被给予学生过去与系统的交互,其中包括:技能 以及响应结果
以及响应结果 。KT预测下一个问题得到正确答案的概率,这主要取决于与问题
。KT预测下一个问题得到正确答案的概率,这主要取决于与问题 相关的相应技能的掌握。因此,我们可以将得到正确答案的概率定义为
相关的相应技能的掌握。因此,我们可以将得到正确答案的概率定义为 ,其中
,其中 ,
, 是一个元组,包含时间t−1时对技能s的响应结果r。然后,我们在这里回顾四种最著名的评估学生表现的最先进的KT建模方法。
是一个元组,包含时间t−1时对技能s的响应结果r。然后,我们在这里回顾四种最著名的评估学生表现的最先进的KT建模方法。
2.1 Bayesian Knowledge Tracing (BKT)
BKT可以说是第一个放宽静态知识状态假设的模型。早期的方法,如IRT,会假设学生不会在答案之间学习,这对于测试是合理的假设,但对于学习环境来说则不是。引入BKT是为了在学习环境中追踪知识[5]。在最初的形式中,它还假设每个项目都测试一个技能,但这个假设在之后的工作中被放宽。数据按技能进行划分,在每个数据集上学习一个模型就会得到每个技能的特定模型。标准的BKT模型由4个参数组成,这些参数通常是在为每个技能建立模型时从数据中学习的。该模型的推断概率主要取决于那些参数,这些参数被用来预测学生如何掌握一项技能,在给定该学生到目前为止对该技能下问题s的错误和正确尝试的时间顺序[1]。要估计一名学生在给定其表现历史的情况下掌握技能的概率,BKT需要有四种概率:P(L0),掌握技能L0的初始概率;P(T),从非掌握状态到掌握状态的转移概率;P(S),失误率,尽管掌握但回答错误的概率;P(G),猜测率,尽管不掌握但回答正确的概率。



2.2 Deep Knowledge Tracing (DKT)
与BKT类似,深度知识跟踪(Deep Knowledge Tracing, DKT)[13]对尝试(做题尝试)的技能序列进行跟踪,但作者利用神经网络的优势,打破了技能分离和二元状态假设的限制。它利用学生以前的尝试历史,并将每次尝试转换为一个one-hot编码的特征向量。然后,这些特征作为输入输入到神经网络中,并将信息通过网络的隐藏层传递到输出层。输出层提供学生在系统中正确回答该特定问题的预测概率。
DKT使用长短期记忆(Long Short-Term Memory, LSTM)[8]来动态地表示学生的潜在知识空间和练习次数。学生通过作业增加的知识可以通过利用学生以前的表现历史来推断。DKT在隐含层中将学生所有技能的知识状态归结为一个隐藏状态。学生在特定时间戳的技能掌握状态由以下公式定义:

在DKT中,tanh和sigmoid函数都是按元素应用的,并由输入权重矩阵Whx、递归权重矩阵Whh、初始状态h0和读出权重矩阵Wyh来参数化。潜在单元和读出单元的偏偏差由bh和by表示。
2.3 Dynamic Key-Value Memory Network (DKVMN)
DKVMN是对DKT的一种改进,它利用一个称为外部记忆槽(external memory slots)的神经网络模块来编码学生的知识状态,并将其作为key和value组件对学生的知识状态进行编码[19]。特定技能的学习或遗忘存储在这两个组件中,并通过额外的注意机制——读写操作控制。
与DKT不同,DKVMN通过执行读写操作来执行局部状态转换,从而避免了隐藏层中的全局和非结构化状态到状态的转换。通过使用从输入技能和key记忆槽计算出的相关权重对value记忆槽进行读写来跟踪学生的知识状态。它由三个主要步骤组成:
Correlation:利用softmax激活 和key记忆槽
和key记忆槽 之间的内积计算出输入技能
之间的内积计算出输入技能 的相关权重:
的相关权重:
其中kt是st的连续嵌入向量,且 id differentiable。在后面的读写过程中都使用了相关权值。
id differentiable。在后面的读写过程中都使用了相关权值。
Reading:通过使用wt对值记忆槽中的值进行加权和来检索st的掌握mt:
Prediction:通过使用掌握程度mt来计算用潜在技能回答对问题的概率p(st):

其中 和
和 。
。
Writing: 在学生回答问题后,模型会根据学生的回答(rt)更新value记忆。将xt=(st,rt)的联合嵌入转换为embedding values vt,并将其写入到带有相关权重wt(与读取过程中所使用的相同)的值存储器中。使用以下公式在添加新信息之前执行擦除:

其中E和D是 形状的变换矩阵。这种先擦除后添加的机制允许遗忘和强化学生学习过程的知识状态[19],这在其他基于RNN的模型中是不能做到的。
形状的变换矩阵。这种先擦除后添加的机制允许遗忘和强化学生学习过程的知识状态[19],这在其他基于RNN的模型中是不能做到的。
2.4 Deep Knowledge Tracing with Dynamic Student Classification(DKT-DSC)
尽管上述模型在评估技能掌握程度上比DKT有更好的准确性,但在处理KT任务时都有不足之处。DKT和DKVMN都忽视了当时学生的长期学习能力。因此,该模型不能评估学生在一个长期的学习过程中,在给定的时间间隔内达到的学习能力水平。在DKT和DKT-DSC中,LSTM使用单个状态向量在单个隐含层中编码具有相应学习能力的学生知识状态的时间信息。
为了对学习能力进行建模,我们结合DKVMN和DKT-DSC的优点,提出了一种新的基于记忆网络的动态学生分类模型(Dynamic Student Classification on Memory Networks, DSCMN)。DSCMN在每个时间间隔同时根据评估的当时学生的长期能力和评估的技能掌握情况来预测学生的表现。
Evaluating Temporal Student’s Learning Ability:学习是一个涉及练习的过程:学生在练习中变得熟练。此外,学习也受到个人学习能力的影响,或者说通过或多或少的练习来变得熟练[10]。
为了检测学生在长期学习过程中在一系列时间间隔上的当时学习能力的规律和变化,需要用DKT-DSC的公式17对学生过去的表现进行编码,以预测其在当前时间间隔内的学习能力。在每个时间间隔之后更新学生过去表现的编码向量。K-Means算法[9]用于 通过测量在训练DKT-DSC过程[10]之后获得的质心之间的欧几里德距离,并分配最近的聚类标签 作为学生在时间z的长期学习能力,来评估学生在每个时间间隔z的训练和测试中的当时长期学习能力。评估在学生进行前20次尝试之后开始,并且在学生每20次尝试之后进行更新。对于第一个时间间隔,每个学生都被分配了初始学习能力1,如图1所示。
作为学生在时间z的长期学习能力,来评估学生在每个时间间隔z的训练和测试中的当时长期学习能力。评估在学生进行前20次尝试之后开始,并且在学生每20次尝试之后进行更新。对于第一个时间间隔,每个学生都被分配了初始学习能力1,如图1所示。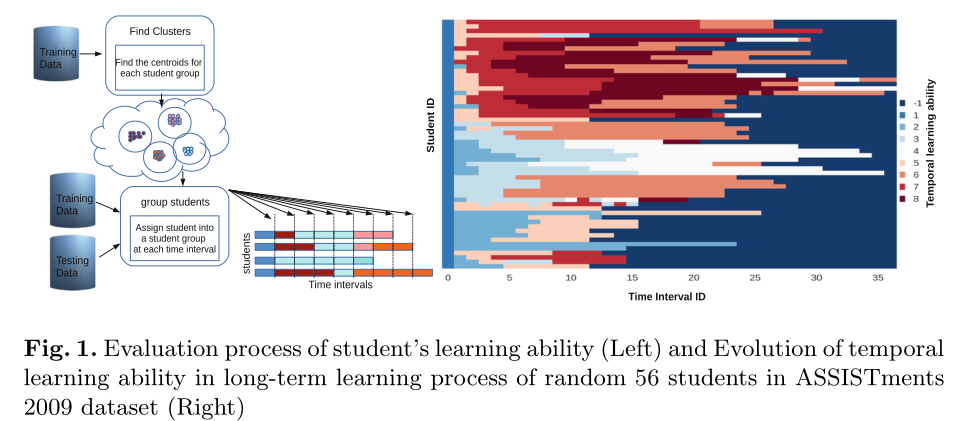
Calculating Problem Difficulty:我们测量问题难度(10个级别)[11,12]。请注意,在这项研究中,难度与问题有关,而与技能本身无关。问题 的难度确定为:
的难度确定为:

其中:
其中Nj是尝试问题Pj的学生集合,而pij是学生i第一次尝试pj问题的结果。结果为0表示失败。常量pd是我们希望保留的问题难度(级别)。它在函数δ(pj,pd)中描述,如公式(20)所示。本质上,δ(Pj,Pd)是将问题Pj的平均成功率映射到(10)个级别的函数。对于那些没有得到至少4个不同学生回答的问题,即数据集中|Nj|<4的问题,我们对这些问题应用,对应于0.5的难度。
3.1 Assessing Student’s Mastery of Skill
为了根据当时学习能力来评估技能掌握情况,我们像DKVMN一样,在两个key和value记忆槽中使用读写过程。DSCMN还使用根据输入技能和key记忆计算出的相关权重来评估技能掌握情况。在DSCMN中,不使用嵌入值,而是使用公式(6)和(7)将one-hot编码的输入直接馈送到记忆网络中。在将xt写入到值存储器之前,从读取过程中获得技能st的掌握mt。然后,学生在时间t回答问题后,模型使用公式(10)和(12)将xt写入值内存(图2)。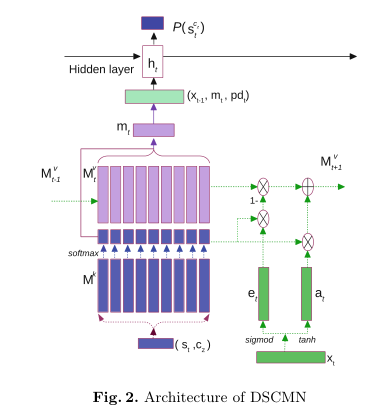
预测:通过将学生在当时学习能力下之前的反应和技能掌握情况输入到额外的隐含层中,来估计在时间间隔z和当时学习能力c下学生使用学生潜在技能正确回答问题的概率 ,并进行如下预测:
,并进行如下预测:

其中cz是该学生在时间间隔t∈z的当时学习能力, 编码了学生i在时间间隔z和当时学习能力下技能st-1的先前反应xt-1、技能id st的掌握情况mt和相关问题难度pdt。DSCMN具有根据当时长期学习能力来评估技能掌握情况的能力。通过使用这些因素来执行预测,并将其存储在隐藏状态ht中。
编码了学生i在时间间隔z和当时学习能力下技能st-1的先前反应xt-1、技能id st的掌握情况mt和相关问题难度pdt。DSCMN具有根据当时长期学习能力来评估技能掌握情况的能力。通过使用这些因素来执行预测,并将其存储在隐藏状态ht中。
Optimization:为了提高基于RNN的模型的预测性能,对于所有基于RNN的模型,我们使用pt和实际响应rt之间的交叉熵损失l进行训练,如下所示:
4 Datasets
为了验证所提出的模型,我们在四个公共数据集上进行了测试,这些数据集来自两个不同的教学场景,其中学生在教育环境中与基于计算机的学习系统交互:(1)ASSISTments:一个最早于2004年创建的在线辅导系统,它让初中生和高中生带有脚手架的提示来参与到他们的数学问题中:(1)ASSISTments1:一个在线辅导系统,它最初创建于2004年,让初中生和高中生参与到他们的数学问题的脚手架提示中来。如果在ASSISTments上学习的学生正确回答了一道题,他们就会得到一道新题。如果他们回答错误,他们会被提供一个小型的辅导课程,在这个课程中,他们必须回答几个问题,将问题分解成几个步骤。数据集如下:ASSISTments 2009-2010(skill builder)、ASSISTments 2012-2013、ASSISTments 2014-2015。(2)Cognitive Tutor。Algebra 2005-2006[4]:是来自PSLC DataShop的卡内基学习(Carnegie Learning Of PSLC DataShop)在KDD Cup 2010比赛中发布的开发数据集。对于所有数据集,我们的实验只考虑对原始问题的第一次正确尝试。我们删除缺少技能值的数据和重复记录的问题。据我们所知,这些是最大的公开可用的知识跟踪数据集(表1)。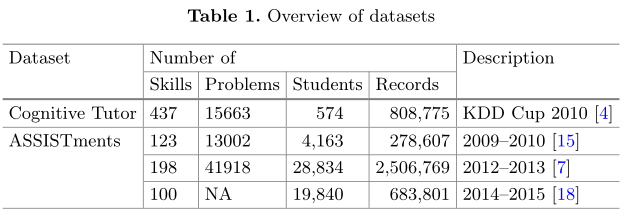
https://sites.google.com/site/assistmentsdata/.
_https://pslcdatashop.web.cmu.edu/KDDCup/downloads.jsp._
5 Experimental Study
在这个实验中,我们假设学生每做20次尝试就是一个时间间隔。DKT-DSC和DSCMN在实验中使用的学生学习能力时间值总数为8个(7个簇,1个为所有学生评估前在初始时间间隔内的初始能力的时间值)。在所有数据集上使用五折交叉验证进行预测。每个fold涉及将每个数据集随机分为80%的训练学生数据和20%的测试学生数据。对于DKVMN的输入,在训练过程中学习到key记忆和value记忆中的初始值。对于其他模型,应用one-hot编码。值记忆中的初始值将初始知识状态表示为每个技能的先验难度,并在测试过程中固定。
我们使用TensorFlow实现了所有模型,DKT,DKT-DSC和DSCMN具有相同的全连接隐藏节点结构,即DKT和DKT-DSC的LSTM隐藏层大小以及DSCMN记忆网络的输出大小都为200。为了加快训练过程,采用小批量随机梯度下降法最小化损失函数。我们的实施的批处理大小为32,对应于32个来拆分每个学生的序列。我们用0.01的学习率训练模型,并采用了dropout来避免过拟合[16]。我们把epochs数设为100。所有模型都在相同的训练和测试学生集上进行训练和测试。
对于BKT,我们使用期望最大化(EM)算法,并将迭代次数限制为200次。我们学习每种技能的模型,并分别做出预测。每项技能的结果取平均值。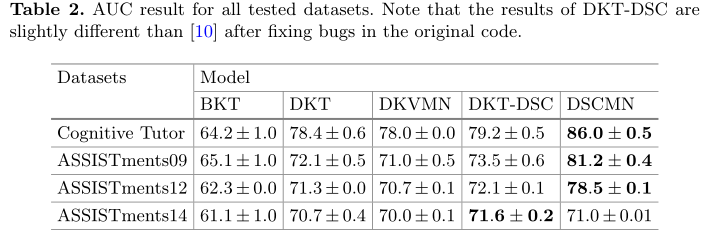
在表2中,DSCMN在三个数据集中的性能明显优于最先进的模型。在认知导师数据集上,与与标准DKT的最大测试AUC为78.4,DKT-DSC的最大测试AUC79.2,DKVMN的最大测验AUC仅为78.0相比。DSCMN模型的AUC=86.0,比原始DKT和DKVMN模型显著提高10%,比DKT-DSC模型提高8%。对于ASSISTments09数据集,在AUC=81.2的情况下,DSCMN也获得了约10%的增益,高于DKT-DSC(AUC=78.5),远高于原始DKT(AUC=71.3)和DKVMN(AUC=70.7)时。在ASSISTments12数据集上,DSCMN仅获得AUC=0.71【数据有错误】。在最新的ASSISTments14数据集(与其他三个数据集相比,ASSISTments14数据集包含的学生更多,数据更少并且缺乏问题信息)中,DSCNM的AUC略低于DKT-DSC。
在表3中,当我们比较上述模型的RMSE时,BKT在ASSISTments09中最低为0.46,ASSISTments12和ASSISTments14为0.51,Cognitive Tutor为0.44。DSCMN在所有数据集中的RMSE结果最低为0.40,而所有其他模型的RMSE结果都不超过0.43(认知导师数据集中的DKT和ASSISTments14中的DSCMN除外)。根据这些结果,DSCMN在Cognitive Tutor、ASSISTments09、ASSISTments 12上的表现优于DKT-DSC,且显著优于其他模型,但在ASSISTts 14上略低于DKT-DSC。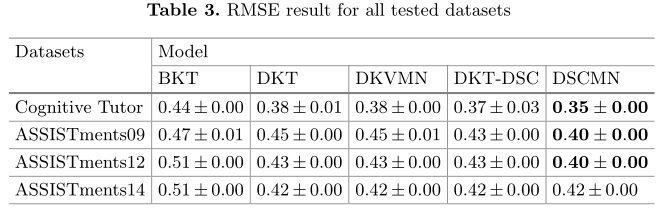
6 Conclusion and Future Work
本文提出了一个新的模型DSCMN,它通过收集技能、问题和学生的信息来预测学生的表现:学生在每个时间步长中对各种问题的技能掌握程度,以及每个时间间隔的学生学习能力。
在四个数据集上的实验表明,该模型比现有最先进的KT模型具有更好的预测性能。对学生在每个时间间隔的当时学习能力的动态评估起着至关重要的作用,它有助于DSCMN捕捉到数据中的更多差异,从而导致更准确的预测。
在我们未来的工作中,我们计划将这个模型应用于与多种技能相关的问题,并将其应用于相关问题的推荐。
References
……

若有收获,就点个赞吧
0 人点赞
