为什么要学数据分析
第 1 个原因是本教程面向纯小白用户,不写代码不写公式,迈出数据分析的第一步。
第 2 个原因是生活中很多的数据分析场合,都是很轻量的,不需要上 Python 爬虫、高并发架构,机器学习等重武器,一个浏览器再加一个 Excel 就足够了:
比如说某门课程论文交稿只有几天了,急需快速爬取数据进行数据分析,这时候临阵磨枪学习 Python 爬虫知识时间完全不够; 做一些市场调研和运营工作需要对数据进行采集,让技术部门支持的话,走流程的周期过长,不如撸起袖子自己做; 工作跳槽,想知道市场上的技能要求和薪资分布,需要采集数据并分析市场需求; ……
这些都是生活中会遇到的问题,面对这些数据量不大(100~10000)的分析需求,非互联网技术人士去学习一些编程知识其实性价比并不高。我们不如利用手头最常见的工具——Excel 和 浏览器,去分析去梳理数据,辅助进行思考和更好的决策。
这也算本门教程的目的——用 20% 的精力解决 80% 的数据分析需求,解放个人的生产力。
本教程主要会从三个方向上进行延伸:数据采集,数据清洗和数据可视化。
数据采集,就是利用爬虫软件从互联网上爬取想要数据,然后存储到本地;
数据清洗,就是对收集到的数据做一些格式化的处理,利于后续分析;
数据可视化,就是采用各种各样分析手法,对数据进行不同维度的解读,并以图表这种直观的形式表现出来,更好的辅助我们决策;
从下一篇文章开始,我们学习如何从互联网上采集数据。
Web Scraper 的下载与安装
调研了很多采集数据的软件,综合评定下来发现最好用的还是 Web Scraper,这是一款 Chrome 浏览器插件。
推荐的理由有这几个:
- 门槛足够低,只要你电脑上安装了 Chrome 浏览器就可以用
- 永久免费,无付费功能,无需注册
- 操作简单,点几次鼠标就能爬取网页,真正意义上的 0 行代码写爬虫
既然这么棒,当然是立马安装啦。
因为 Web Scraper 是 Chrome 浏览器插件,我当然是首推使用 Chrome。但是限于国内的网络环境,可能访问 Chrome 插件应用商店不是很方便,如果第一条路走不通,我们可以尝试第二条路,用 QQ 浏览器曲线救国(360 浏览器暂时不提供 Web Scraper 插件)。
这两个浏览器内核都是一样的,只是界面不一样。我后续的教程都将以 Chrome 浏览器为主力,QQ 浏览器可能会稍有一点点的不同,如果有不一样的地方,还需读者自行分辨差异。
1. 在 Chrome 浏览器上安装 Web Scraper 插件
1.1 安装 Chrome 浏览器
这个没啥好说的,Windows 电脑的各大应用商店都有最新版的 Chrome 浏览器,或者百度一下,首页一般都会有安装包地址,下载安装就好;
(为了减少兼容性问题,最好安装最新版本的 Chrome 浏览器)
1.2 安装 Web Scraper 插件
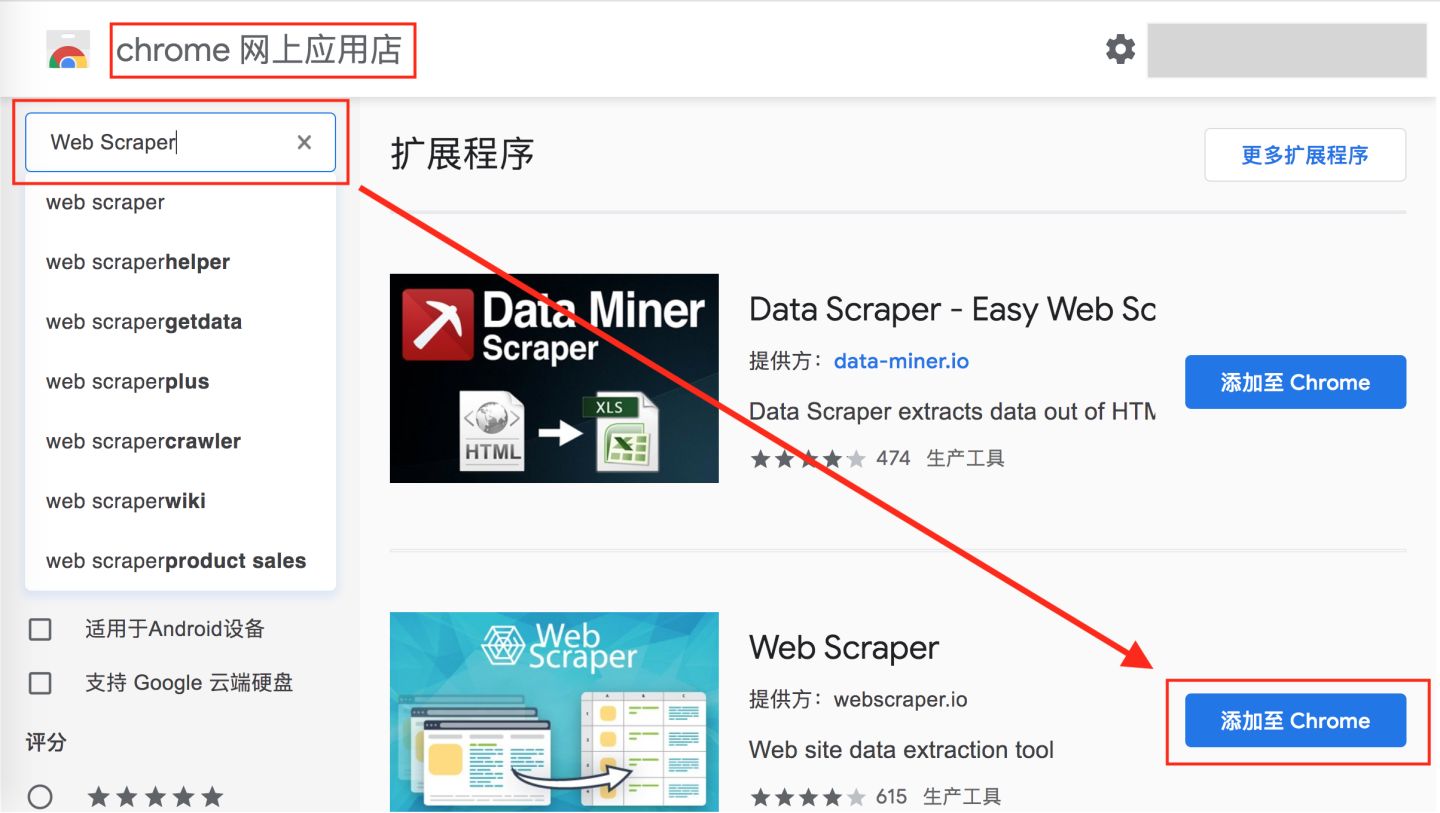
可以访问外网的同学,直接访问”Chrome 网上应用店”,搜索 Web Scraper 下载安装就可:
暂时无条件访问外网,我们可以手动安装插件曲线救国一下,当然和上面比会稍微麻烦一些:
首先,我们访问 www.gugeapps.net 这个国内浏览器插件网站,搜索 Web Scraper,下载插件,注意这时候插件不是直接安装到浏览器上的,而是下载到了本地:

然后,我们在浏览器的的网址输入框里输入 chrome://extensions/ ,这样我们就可以打开浏览器的插件管理后台:
接下来就是解压安装刚刚下载的插件了。
如果你是 Mac 用户,首先要把这个安装包的后缀名 .crx 改为 .zip。

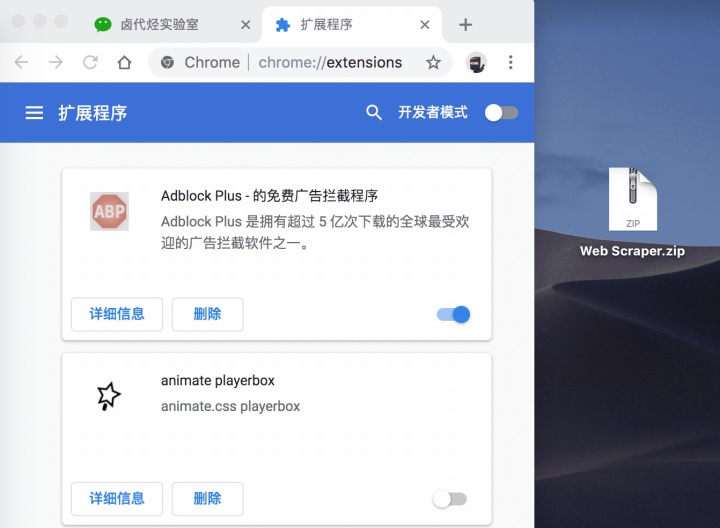
再切到浏览器的插件管理后台,打开右上角的开发者模式,把 Web Scraper.zip 这个文件拖进去,这样就安装好了。
一般这样安装会有一个红色的错误按钮,我们不用管它,直接忽略就行。
如果你是 windows 用户,你需要这样做:
- 把后缀为
.crx的插件改为.rar,然后解压缩 - 进入 chrome://extensions/ 这个页面,开启开发者模式
- 点击”加载已解压的扩展程序”,选择第一步中解压的文件夹,正常情况下就安装成功了。
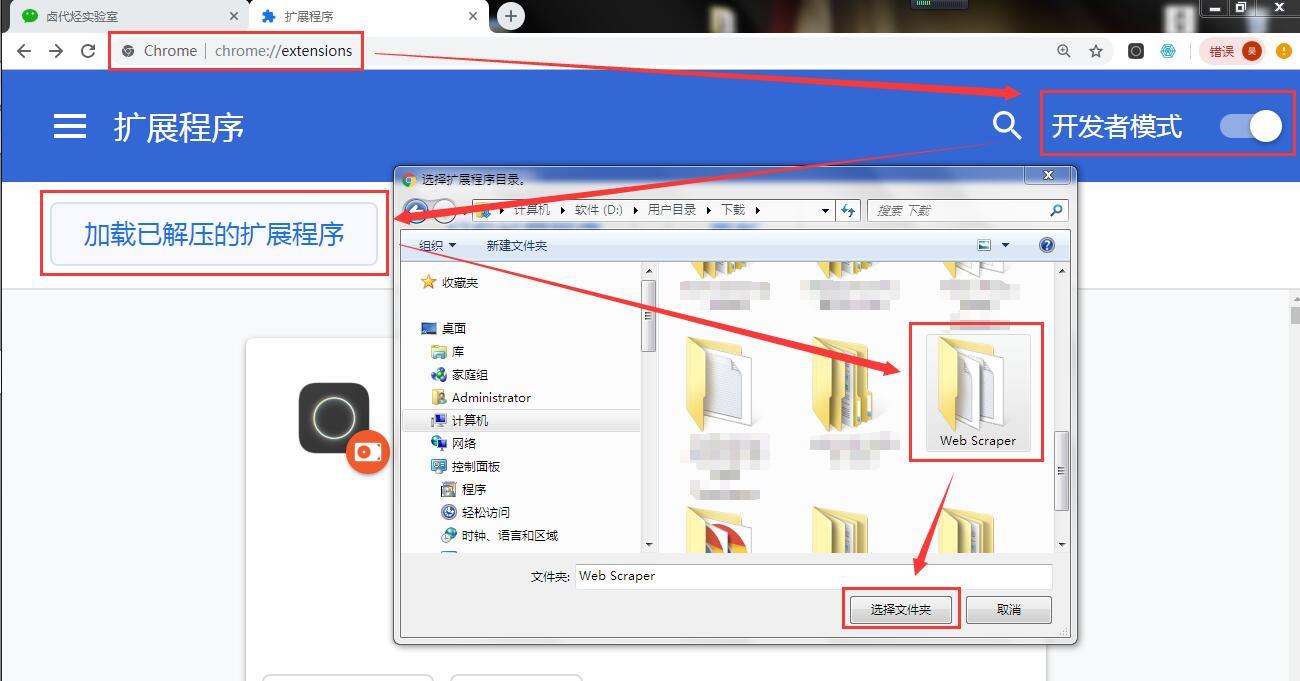
到这里我们的 Chrome 浏览器就成功安装好 Web Scraper 插件了。
2.在 QQ 浏览器上安装 Web Scraper 插件
2.1 安装 QQ 浏览器
去各大应用商店或者访问 QQ 浏览器官网下载安装就可。
QQ 浏览器 PC 版官网下载地址:https://browser.qq.com/
QQ 浏览器 Mac 版官网下载地址:https://browser.qq.com/mac/
2.2 安装 Web Scraper 插件
Mac 用户直接访问浏览器左上角的”应用中心”,点击进入并搜索 Web Scraper 安装即可。
Windows 用户要先点击浏览器左上角的 ≡ 菜单栏,在弹出的菜单栏里选择”应用中心”,点击进入并搜索 Web Scraper 安装即可。
到这里我们的 Web Scraper 插件就安装成功啦,下一篇我们要探索一些浏览器的骚操作,为我们的后续学习打个好的基础。
浏览器中那些不为人知的使用技巧
1 开启开发者后台
这个功能我其实在旧文《造谣成本有多低?一行代码就可以截图造假》中提到过,想从普通浏览模式切换到开发者模式,只要按 F12 就可以实现(QQ 浏览器 F12 被禁掉了)。Mac 电脑也可以用 option + command + I 打开,Win 电脑可以用 Ctrl + Shift + I 打开。
2 一行代码自由伪造截图
这个也是旧文《造谣成本有多低?一行代码就可以截图造假》的内容,已经有很多小伙伴表示他们操作成功了,感兴趣的同学可以了解一下。
3 切换开发者后台的位置
控制台打开后,一般会在网页的下方显示,我们其实也可以切到网页的右边显示,具体的操作是点击后台面板右侧的 ⋮ 按钮,然后修改显示位置,具体操作如下动图。
4 用电脑浏览器模拟手机浏览器
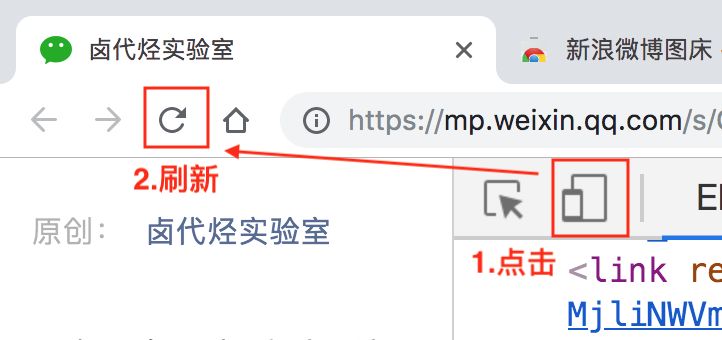
用电脑浏览器模拟手机浏览器是一个很实用的功能。因为现在是移动互联网的时代了,大部分公司的网页都是优先支持移动端,而且手机浏览器的数据结构更清晰,更利于我们抓取数据。
开启模拟手机也很简单,只要点击一下开启开发者后台左侧的手机切换图标,然后刷新就好了。
我们可以拿豆瓣这个网站演示一下。
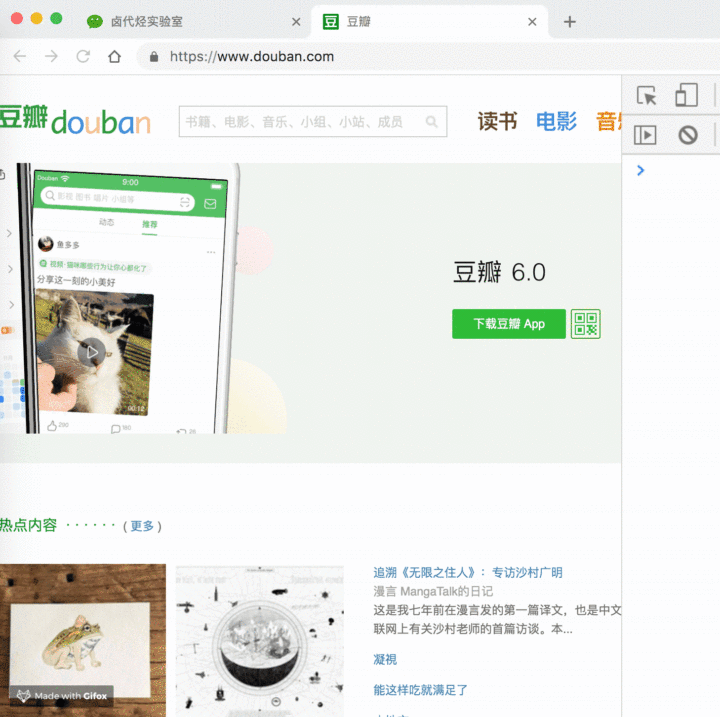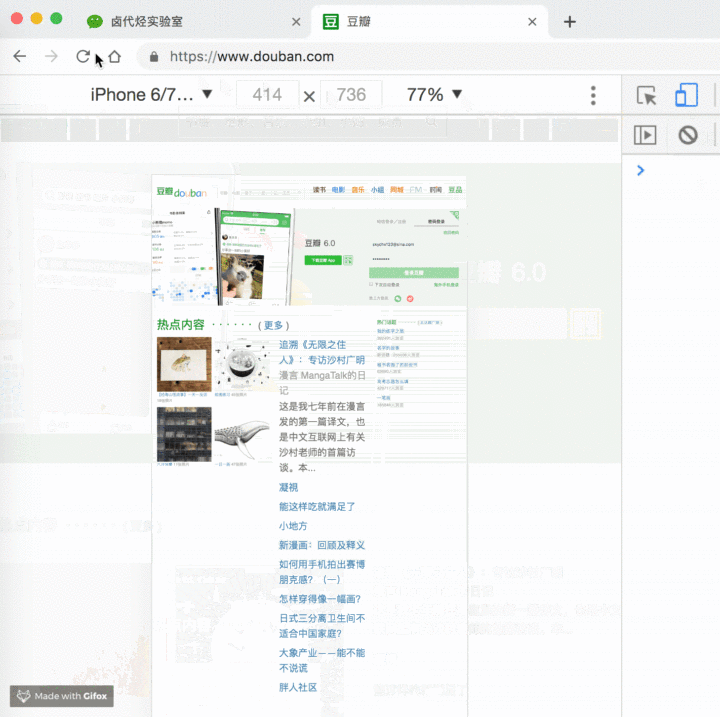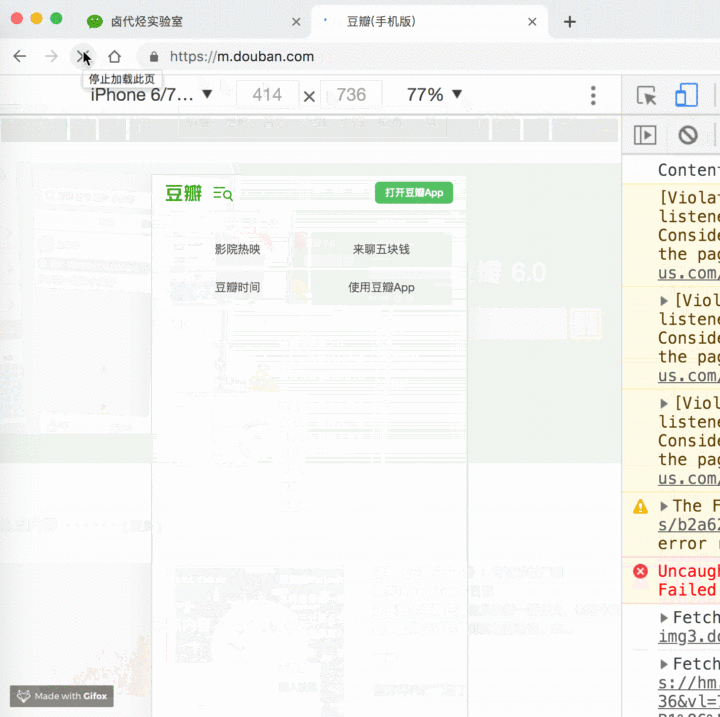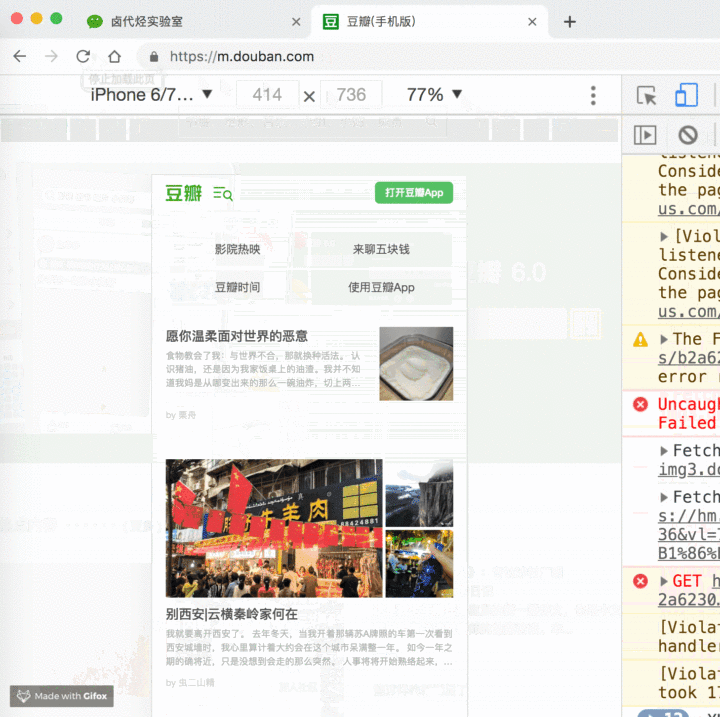
当然,我们还可以利用这个功能做些别的事情,比如说上班时开个小屏幕偷偷摸鱼刷微博。被老板抓住时别说是我教的。
抓取豆瓣高分电影
有人之前可能学过一些爬虫知识,总觉得这是个复杂的东西,什么 HTTP、HTML、IP 池,在这里我们都不考虑这些东西。一是小的数据量根本不需要考虑,二是这些乱七八糟的东西根本没有说到爬虫的本质。
爬虫的本质是什么?其实就是找规律。
而且爬虫的找规律难度,大部分都是小学三年级的数学题水平。
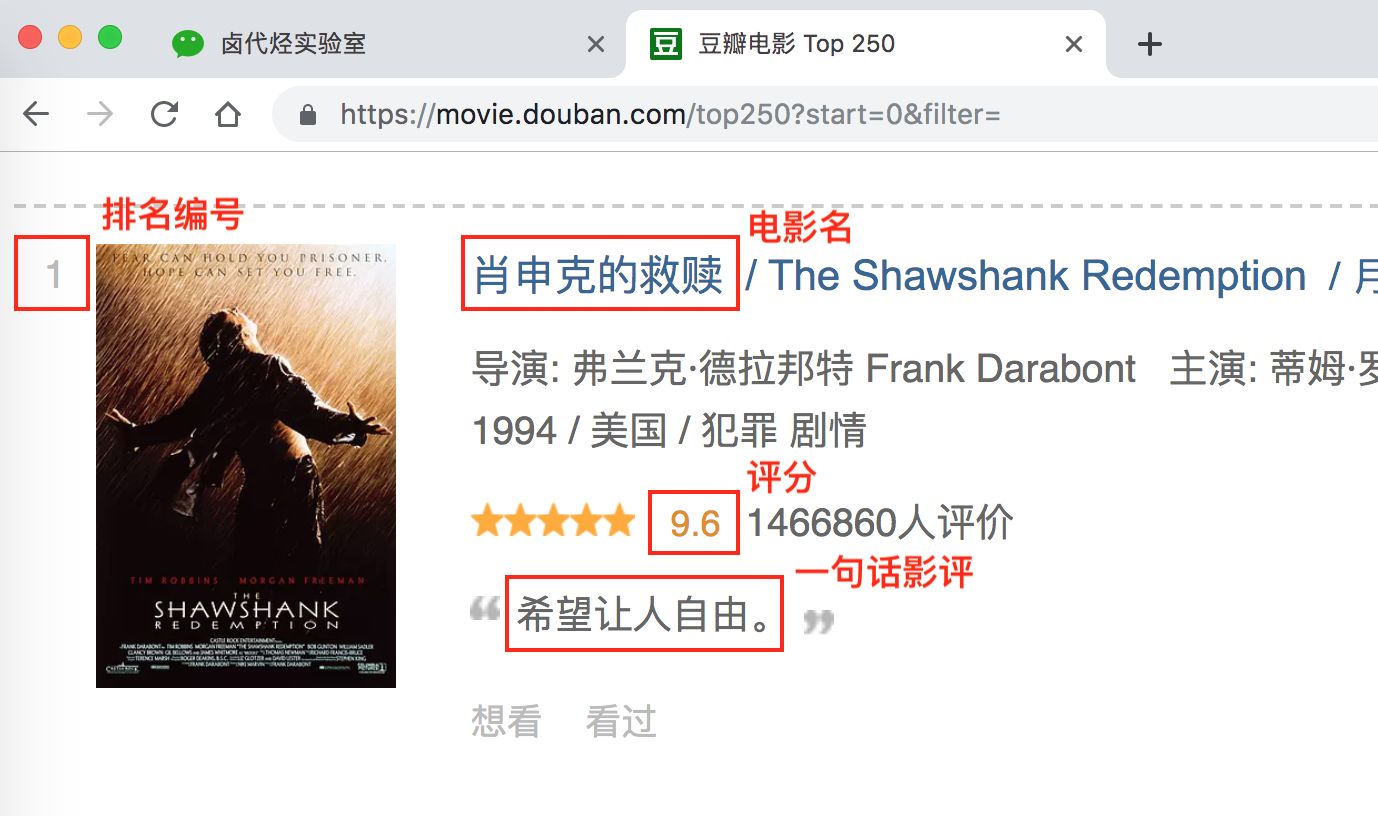
我们下面拿个例子说明一下,下图历史文章的一个截图,我们可以很清晰的看到,每一条推文可以分为三大部分:标题、图片和作者,我们只要找到这个规律,就可以批量的抓取这类数据。
好了,理论的地方我们讲完了,下面我们开始进行实操。
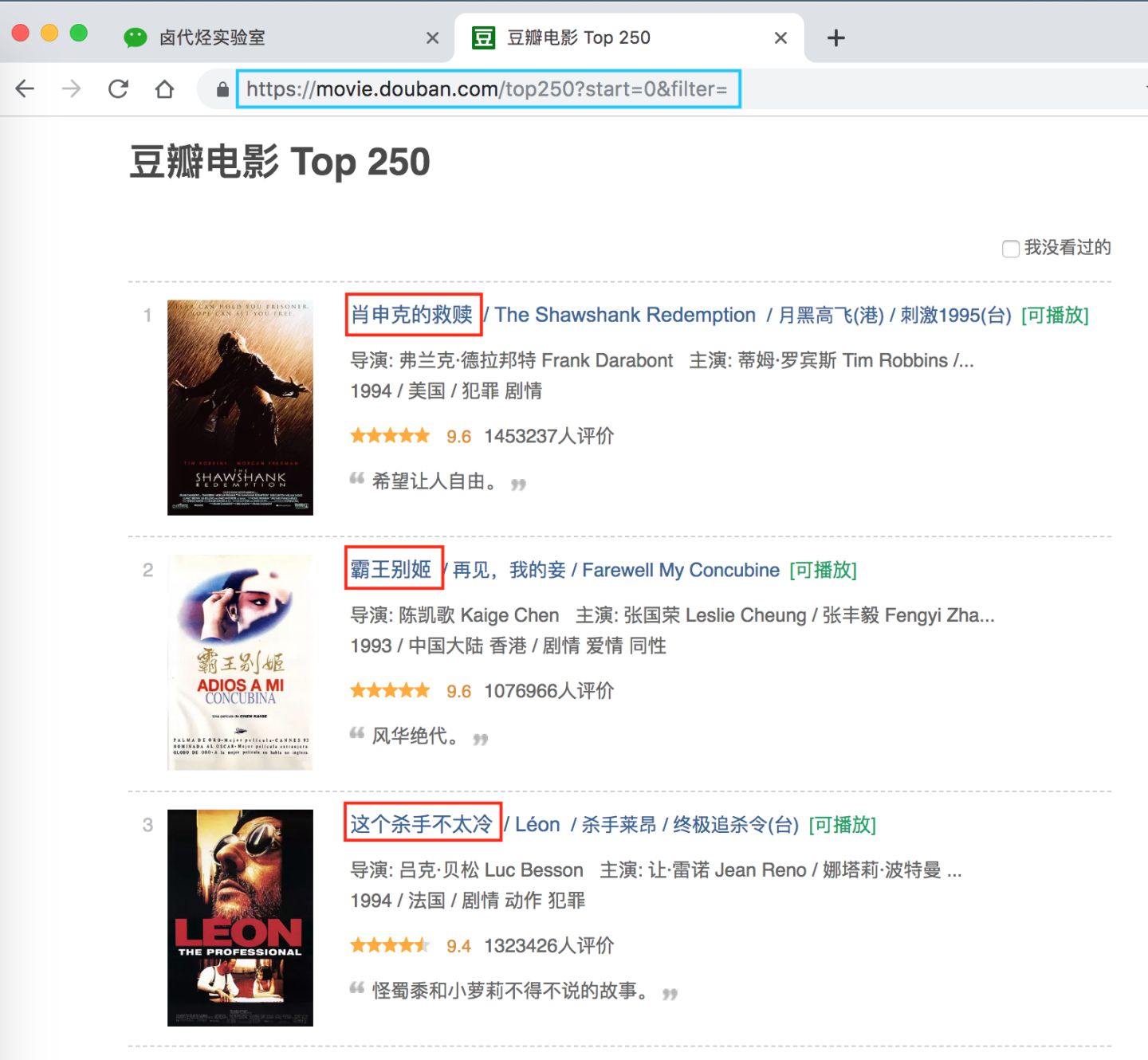
但凡做爬虫练手,第一个爬取的网站一般都是豆瓣电影 TOP 250,网址链接是 https://movie.douban.com/top250?start=0&filter=。第一次上手,我们爬取的内容尽量简单,所以我们只爬取第一页的电影标题。
浏览器按 F12 打开控制台,并把控制台放在网页的下方(具体操作可以看上一篇文章),然后找到 Web Scraper 这个 Tab,点进去就来到了 Web Scraper 的控制页面。

进入 Web Scraper 的控制页面后,我们按照 Create new sitemap -> Create Sitemap 的操作路径,创建一个新的爬虫,sitemap 是啥意思并不重要,你就当他是个爬虫的别名就好了。
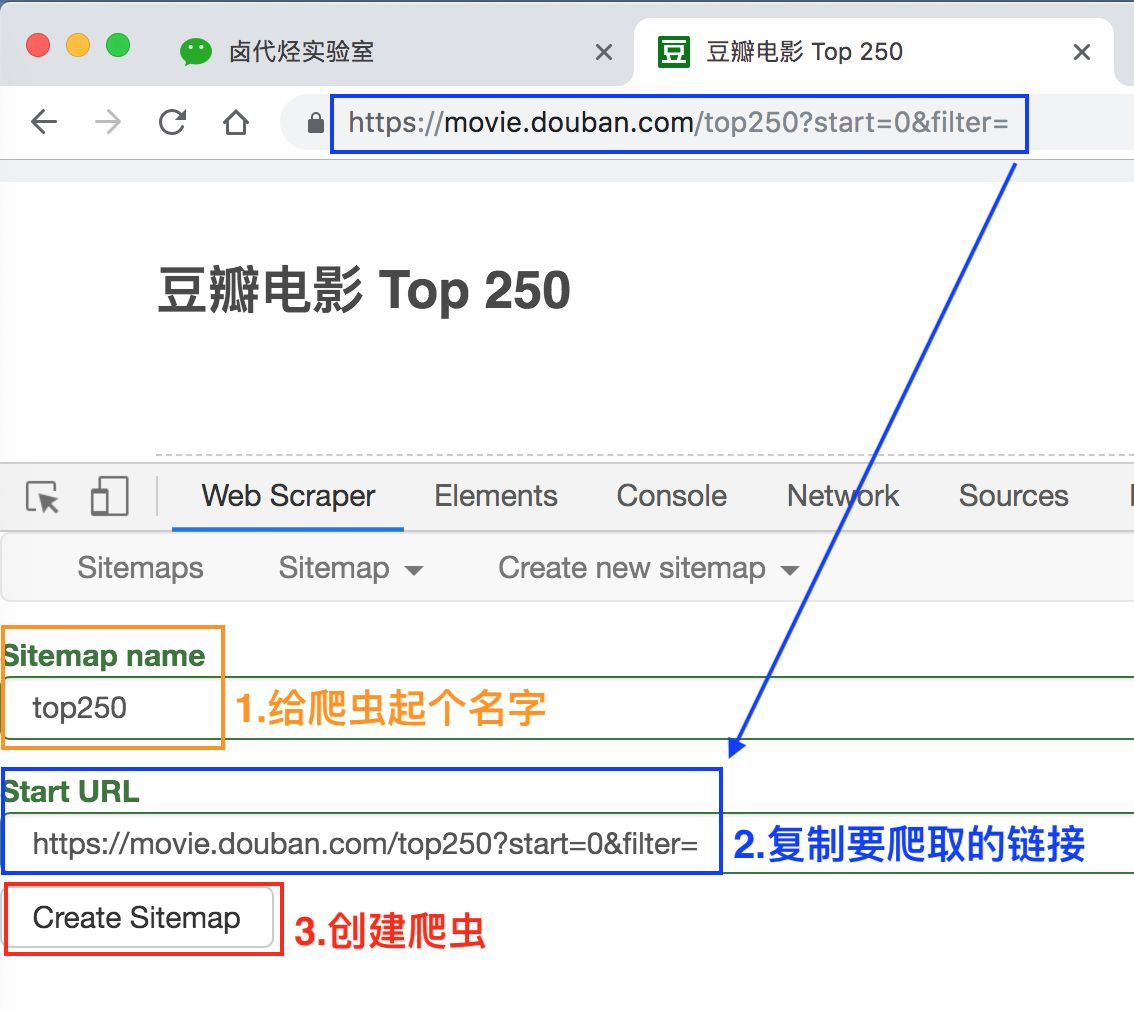
我们在接下来出现的输入框里依次输入爬虫名和要爬取的链接。
爬虫名可能会有字符类型的限制,我们看一下规则规避就好了,最后点击 Create Sitemap 这个按钮,创建我们的第一个爬虫。
这时候会跳到一个新的操作面板,不要管别的,我们直接点击 Add new selector 这个蓝底白字的按钮,顾名思义,创建一个选择器,用来选择我们想要抓取的元素。
这时候就要开始正式的数据抓取环节了!我们先观察一下这个面板有些什么东西:
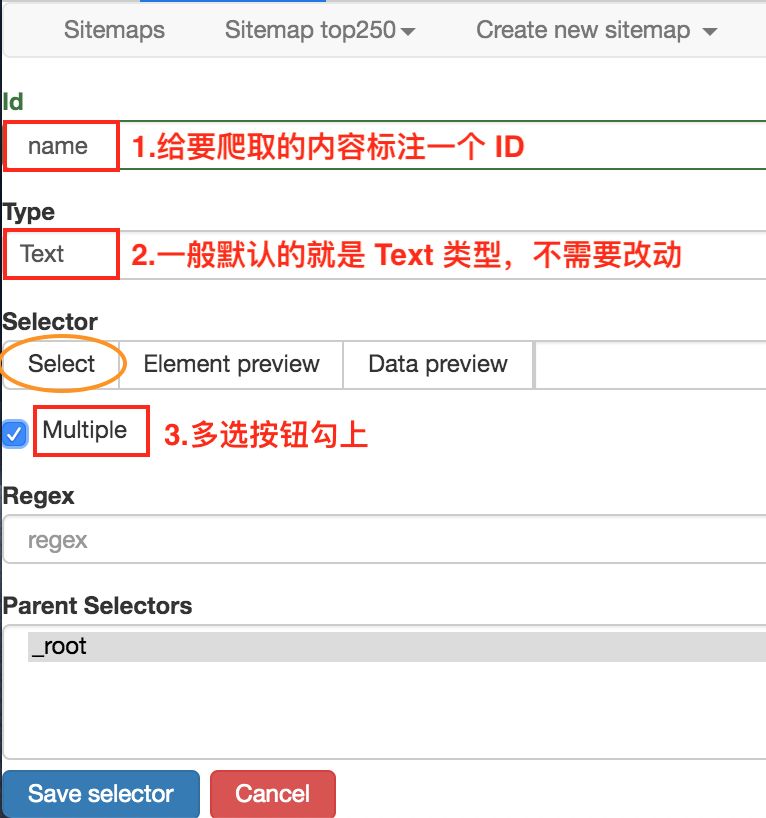
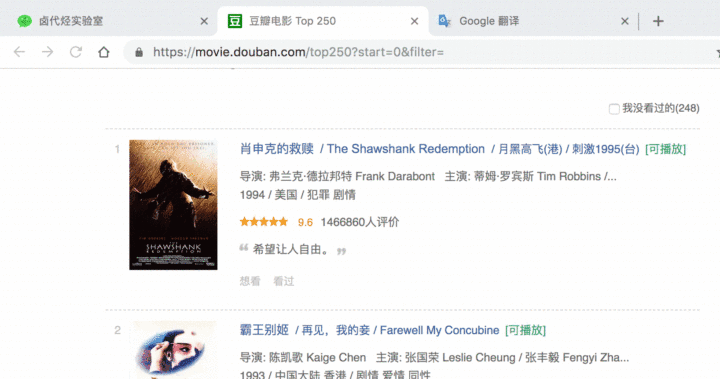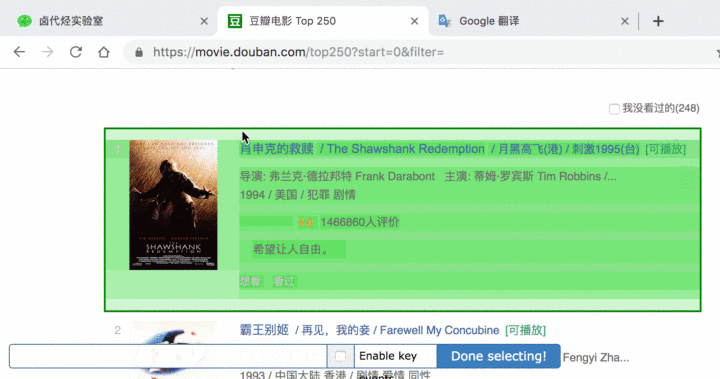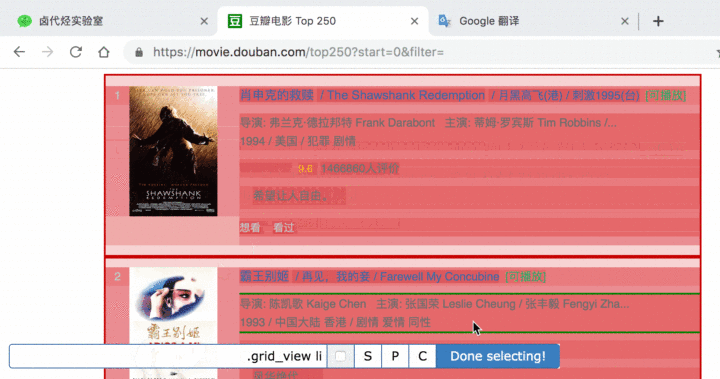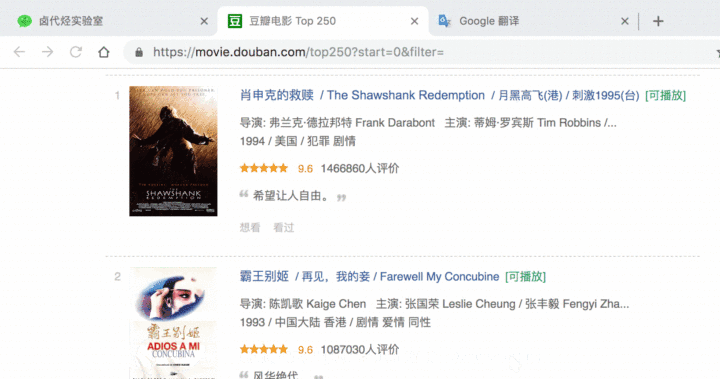
1.首先有个 Id,这个就是给我们要爬取的内容标注一个 id,因为我们要抓取电影的名字,简单起见就取个 name 吧;2.电影名字很明显是一段文字,所以 Type 类型肯定是 Text,在这个爬虫工具里,默认 Type 类型就是 Text,这次的爬取工作就不需要改动了;3.我们把多选按钮 Multiple 勾选上,因为我们要抓的是批量的数据,不勾选的话只能抓取一个;4.最后我们点击黄色圆圈里的 Select,开始在网页上勾选电影名字;
当你把鼠标移动到网页时,会发现网页上出现了绿色的方块儿,这些方块就是网页的构成元素,当我们点击鼠标时,绿色的方块儿就会变为红色,表示这个元素被选中了:
这时候我们就可以进行我们的抓取工作了。
我们先选择「肖生克的救赎」这个标题,然后再选择「霸王别姬」这个标题(注意:想达到多选的效果,一定要手动选取两个以上的内容)
选完这两个标题后,向下拉动网页,你就会发现所有的电影名字都被选中了:

拉动网页检查一遍,发现所有的电影标题都被选中后,我们就可以点击 Done selecting!这个按钮,表示选择完毕;
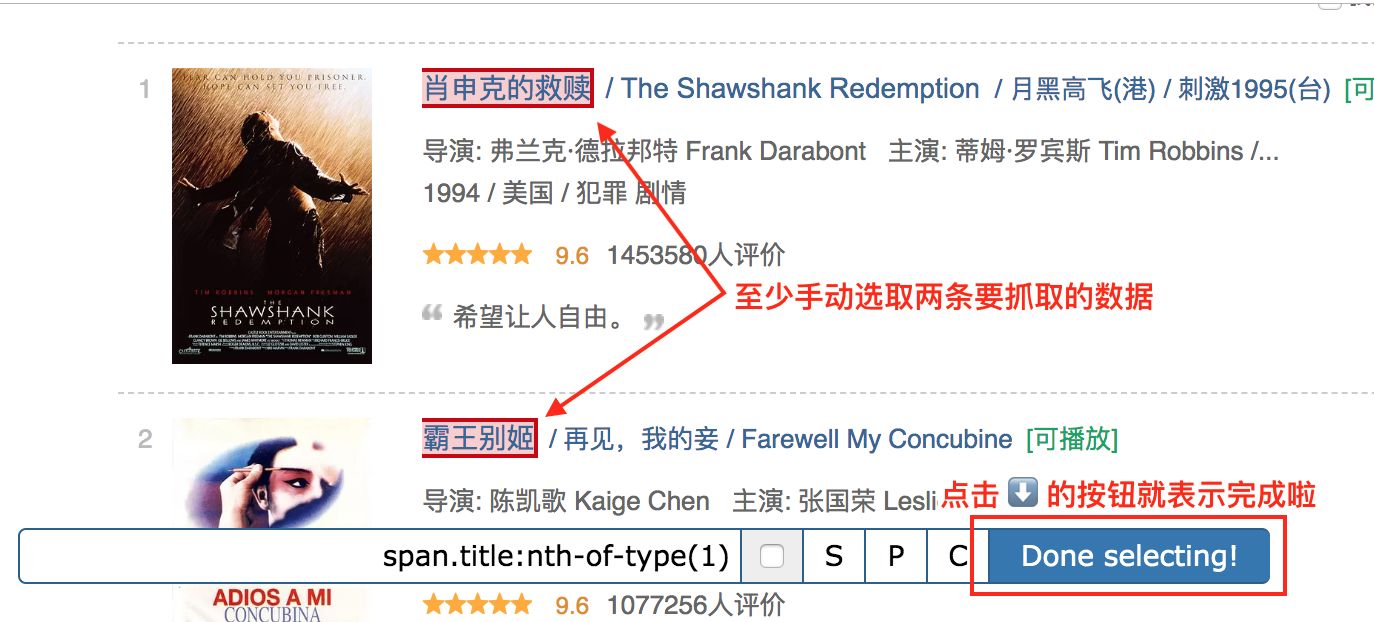
点击按钮后你会发现下图的红框位置会出现了一些字符,一般出现这个就表示选取成功了:

我们点击 Data preview 这个按钮,就可以预览我们的抓取效果了:
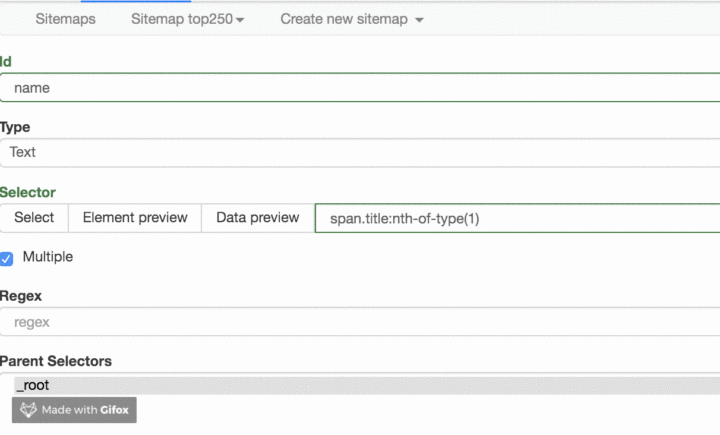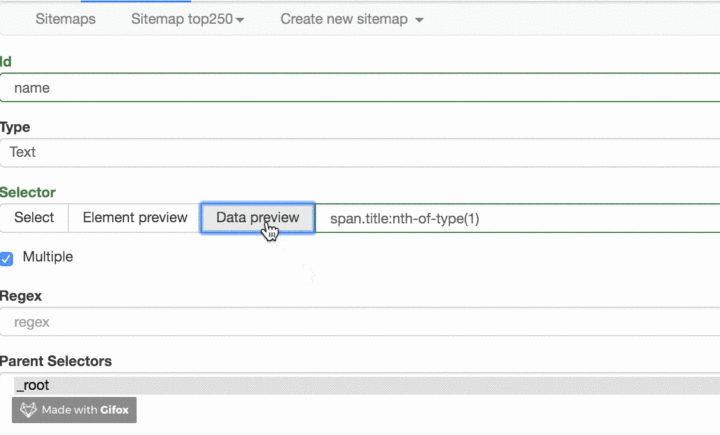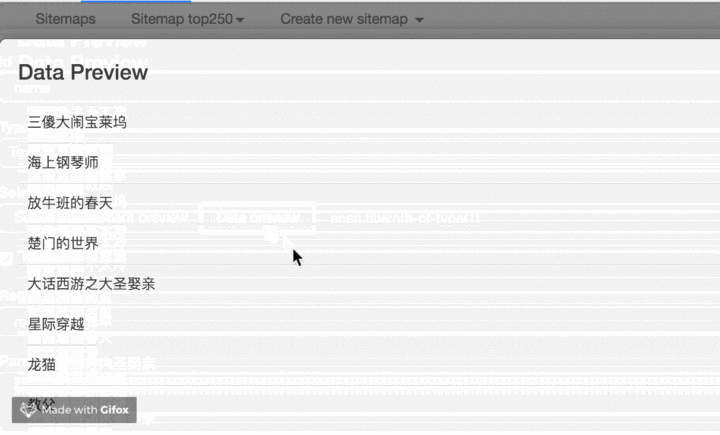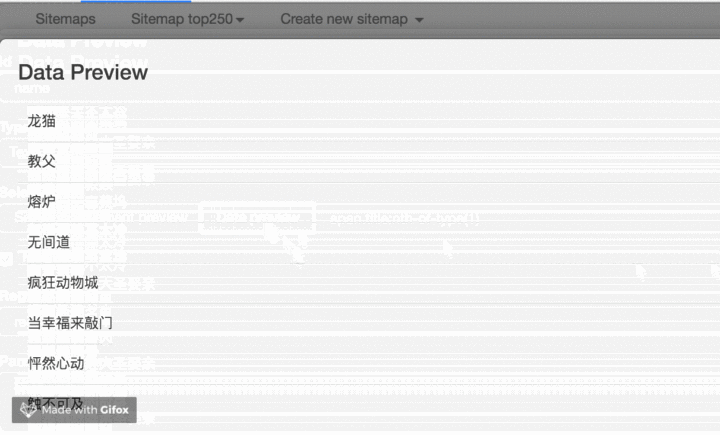
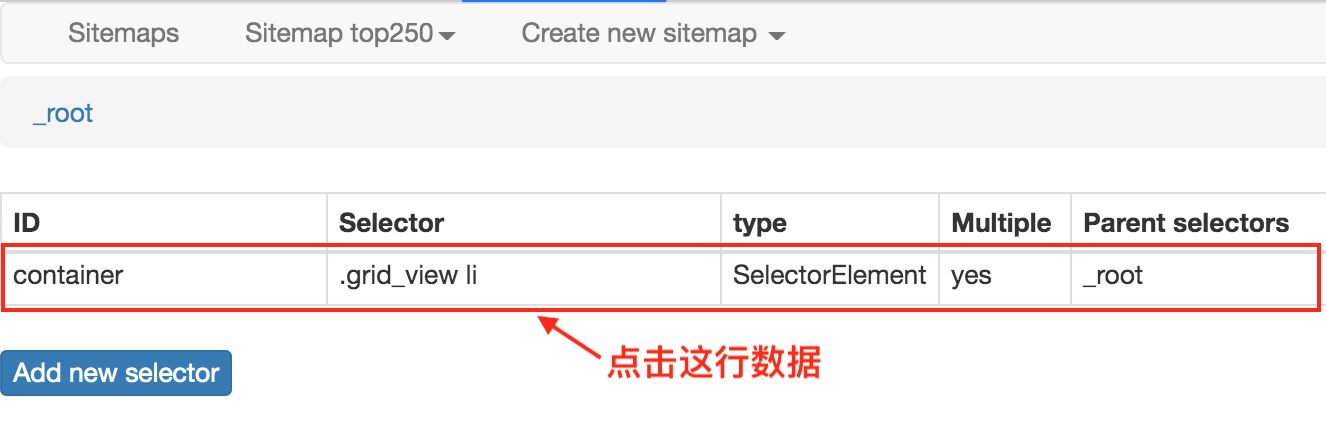
没什么问题的话,关闭 Data Preview 弹窗,翻到面板的最下面,有个 Save selector 的蓝色按钮,点击后我们会回退到上一个面板。
这时候你会发现多了一行数据,其实就是我们刚刚的操作内容被记录下来了。
在顶部的 tab 栏,有一个 Sitemap top250 的 tab,这个就是我们刚刚创建的爬虫。点击它,再点击下拉菜单里的 Scrape 按钮,开始我们的数据抓取。
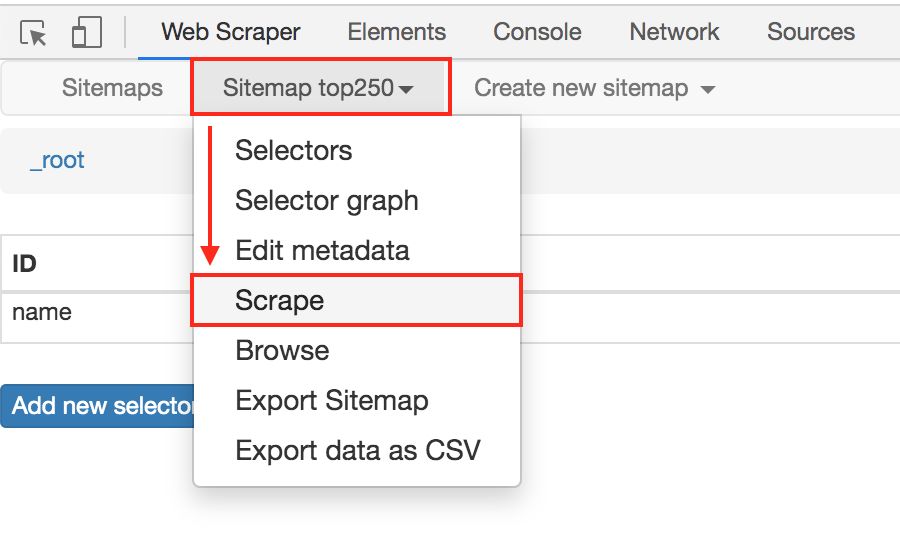
这时候你会跳到另一个面板,里面有两个输入框,先别管他们是什么,全部输入 2000 就好了。
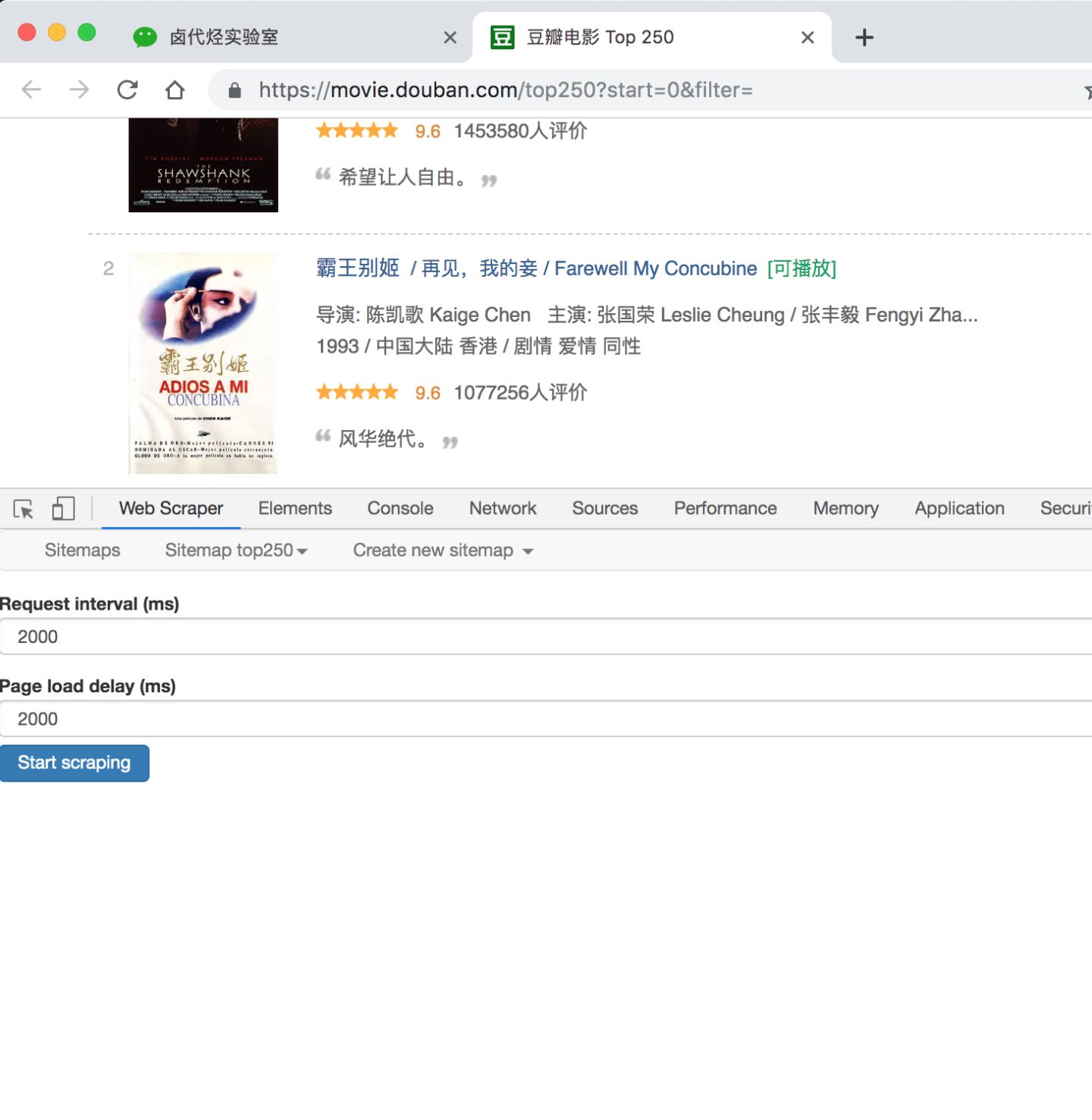
点击 Start scraping 蓝色按钮后,会跳出一个新的网页,Web Scraper 插件会在这里进行数据抓取:
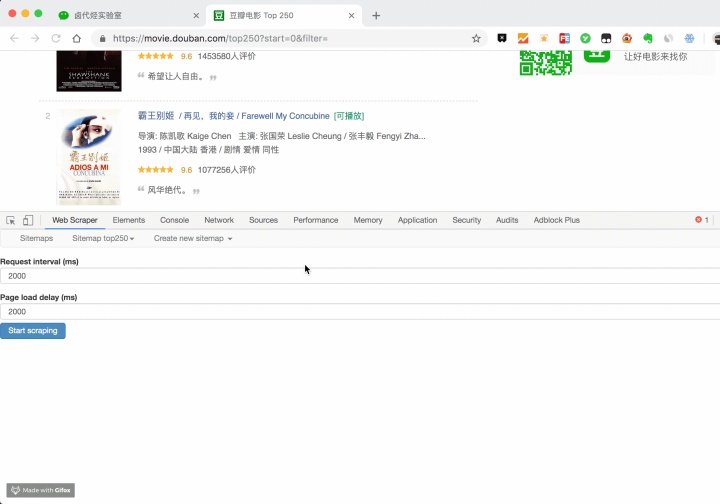
一般弹出的网页自动关闭就代表着数据抓取结束了,我们点击面板上的 refresh 蓝色按钮,就可以看到我们抓取的数据了!
在这个预览面板上,第一列是 web scraper 自动添加的编号,没啥意义;第二列是抓取的链接,第三列就是我们抓取的数据了。
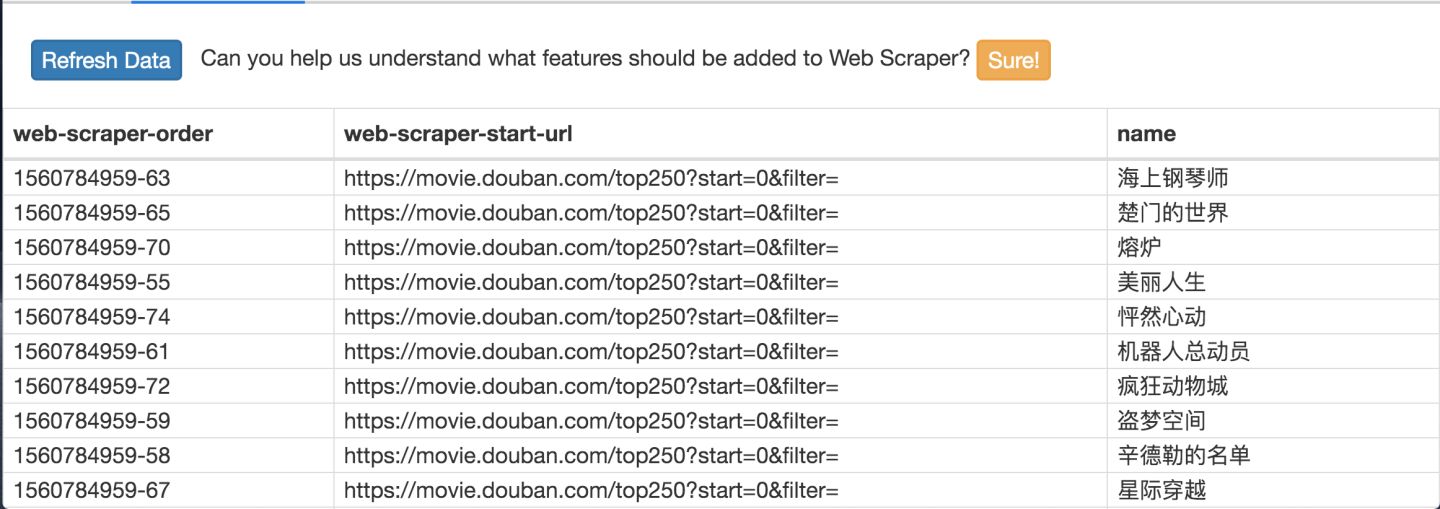
这个数据会存储在我们的浏览器里,我们也可以点击 Sitemap top250 下的 Export data as CSV,这样就可以导出成 .csv 格式的数据,这种格式可以用 Excel 打开,我们可以用 Excel 做一些数据格式化的操作。
今天我们爬取了豆瓣电影TOP250 的第 1 页数据(也就是排名最高的 25 部电影),下一篇我们讲讲,如何抓取所有的电影名。
控制链接批量抓取数据
前面我们同时说了,爬虫的本质就是找规律,当初这些程序员设计网页时,肯定会依循一些规则,当我们找到规律时,就可以预测他们的行为,达到我们的目的。
今天我们就找找豆瓣网站的规律,想办法抓取全部数据。今天的规律就从常常被人忽略的网址链接开始。
1.链接分析
我们先看看第一页的豆瓣网址链接:
[https://movie.douban.com](https://movie.douban.com)这个很明显就是个豆瓣的电影网址,没啥好说的top250这个一看就是网页的内容,豆瓣排名前 250 的电影,也没啥好说的?后面有个start=0&filter=,根据英语提示来看,好像是说筛选(filter),从 0 开始(start)
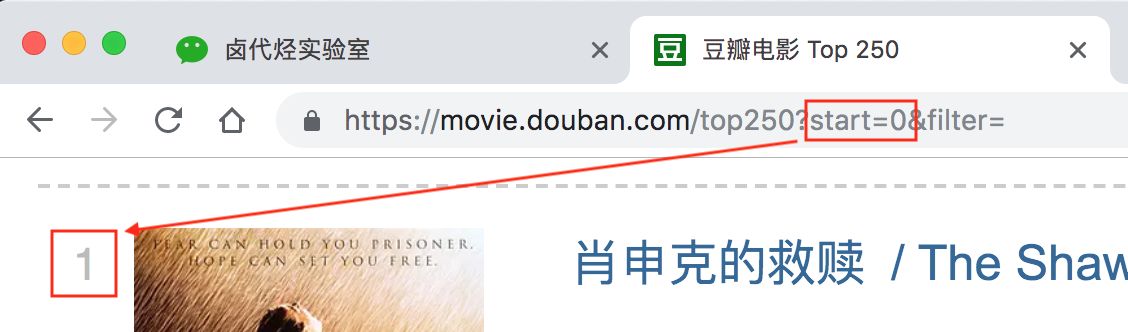
再看看第二页的网址链接,前面都一样,只有后面的参数变了,变成了 start=25,从 25 开始;
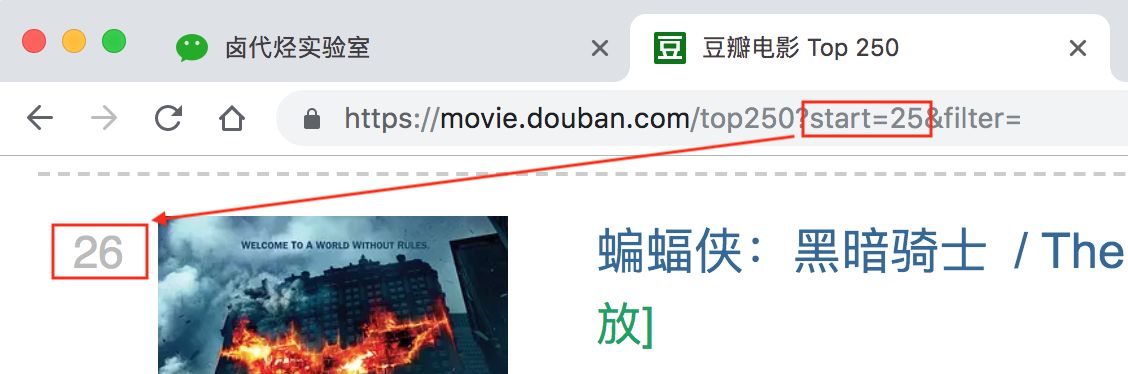
我们再看看第三页的链接,参数变成了 start=50,从 50 开始;
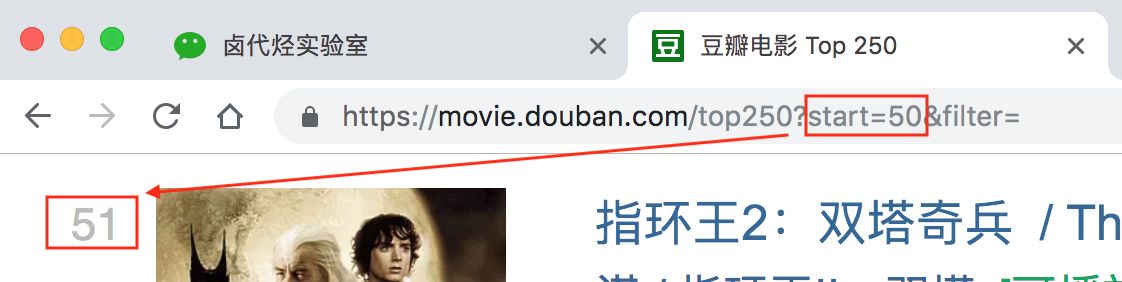
分析 3 个链接我们很容易得出规律: start=0,表示从排名第 1 的电影算起,展示 1-25 的电影start=25,表示从排名第 26 的电影算起,展示 26-50 的电影start=50,表示从排名第 51 的电影算起,展示 51-75 的电影……start=225,表示从排名第 226 的电影算起,展示 226-250 的电影
规律找到了就好办了,只要技术提供支持就行。随着深入学习,你会发现 Web Scraper 的操作并不是难点,最需要思考的其实还是这个找规律。
2.Web Scraper 控制链接参数翻页
Web Scraper 针对这种通过超链接数字分页获取分页数据的网页,提供了非常便捷的操作,那就是范围指定器。
比如说你想抓取的网页链接是这样的:
[http://example.com/page/1](http://example.com/page/1)[http://example.com/page/2](http://example.com/page/2)[http://example.com/page/3](http://example.com/page/3)
你就可以写成 http://example.com/page/[1-3],把链接改成这样,Web Scraper 就会自动抓取这三个网页的内容。
当然,你也可以写成 http://example.com/page/[1-100],这样就可以抓取前 100 个网页。
那么像我们之前分析的豆瓣网页呢?它不是从 1 到 100 递增的,而是 0 -> 25 -> 50 -> 75 这样每隔 25 跳的,这种怎么办?
[http://example.com/page/0](http://example.com/page/0)[http://example.com/page/25](http://example.com/page/25)[http://example.com/page/50](http://example.com/page/50)
其实也很简单,这种情况可以用 [0-100:25] 表示,每隔 25 是一个网页,100/25=4,爬取前 4 个网页,放在豆瓣电影的情景下,我们只要把链接改成下面的样子就行了;
https://movie.douban.com/top250?start=[0-225:25]&filter=
这样 Web Scraper 就会抓取 TOP250 的所有网页了。
3.抓取数据
解决了链接的问题,接下来就是如何在 Web Scraper 里修改链接了,很简单,就点击两下鼠标:
1.点击 Stiemaps,在新的面板里点击 ID 为 top250 的这列数据;

2.进入新的面板后,找到 Stiemap top250 这个 Tab,点击,再点击下拉菜单里的 Edit metadata;
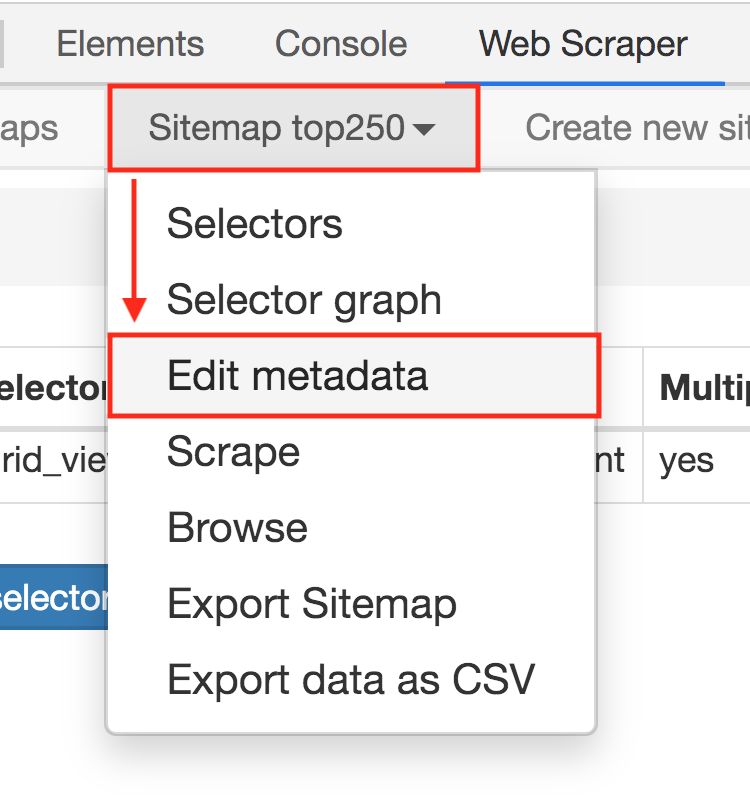
3.修改原来的网址,图中的红框是不同之处:
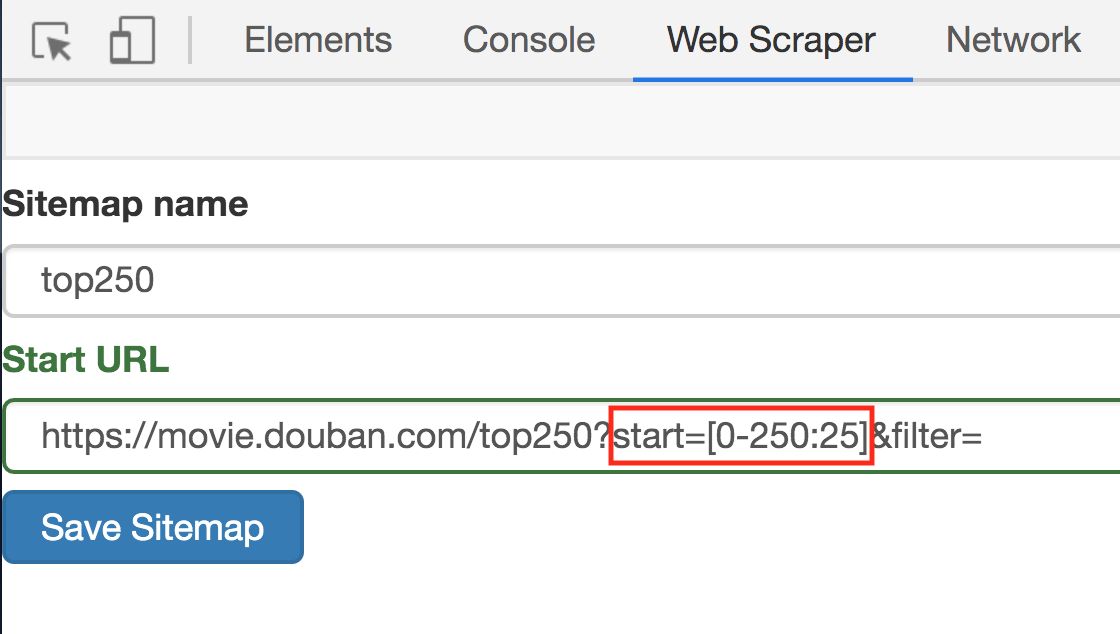
修改好了超链接,我们重新抓取网页就好了。操作和上文一样,我这里就简单复述一下:
- 点击
Sitemap top250下拉菜单里的Scrape按钮 - 新的操作面板的两个输入框都输入 2000
- 点击
Start scraping蓝色按钮开始抓取数据 - 抓取结束后点击面板上的
refresh蓝色按钮,检测我们抓取的数据
如果你操作到这里并抓取成功的话,你会发现数据是全部抓取下来了,但是顺序都是乱的。

我们这里先不管顺序问题,因为这个属于数据清洗的内容了,我们现在的专题是数据抓取。先把相关的知识点讲完,再攻克下一个知识点,才是更合理的学习方式。
这期讲了通过修改超链接的方式抓取了 250 个电影的名字。下一期我们说一些简单轻松的内容换换脑子,讲讲 Web Scraper 如何导入别人写好的爬虫文件,导出自己写好的爬虫软件。
如何导入别人已经写好的 Web Scraper 爬虫
上两期我们学习了如何通过 Web Scraper 批量抓取豆瓣电影 TOP250 的数据,内容都太干了,今天我们说些轻松的,讲讲 Web Scraper 如何导出导入 Sitemap 文件。
前面也没有说,SItemap 是个什么东西,其实它就是我们操作 Web Scraper 后生成的爬虫文件,相当于 python 爬虫的源代码,导入 Web Scraper 一运行就可以爬取数据。学习了这一章节,就可以分享我们的设置好的爬虫文件了。
导出 Sitemap
导出 Sitemap 很简单,比如说我们创建的 top250 Sitemap,点击 Sitemap top250,在下拉菜单里选择 Export Sitemap,就会跳到一个新的面板。
新的面板里有我们创建的 top250 的 Sitemap 信息,我们把它复制下来,再新建一个 TXT 文件,粘贴保存就好了。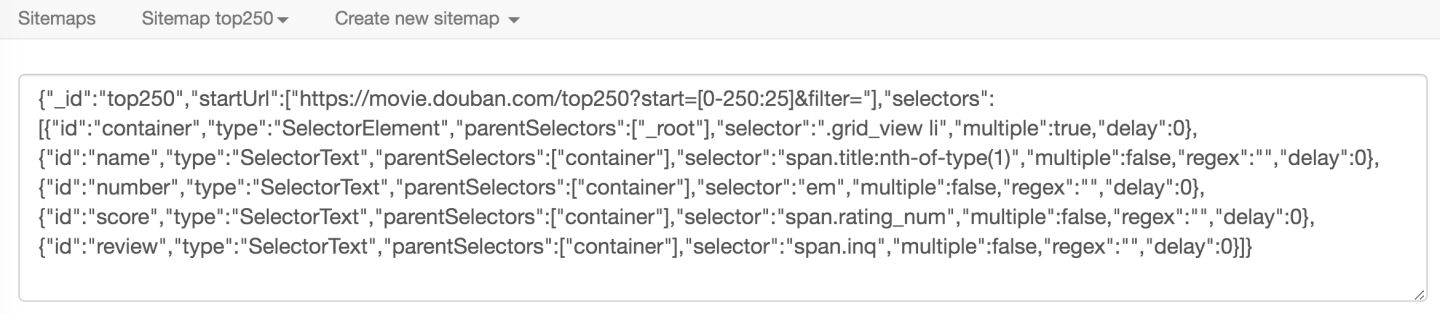
导入 Sitemap
导入 Sitemap 也很简单,在创建新的 Sitemap 时,点击 Import Sitemap 就好了。
在新的面板里,在 Sitemap JSON 里把我们导出的文字复制进去,Rename Sitemap 里取个名字,最后点击 Import Sitemap 按钮就可以了。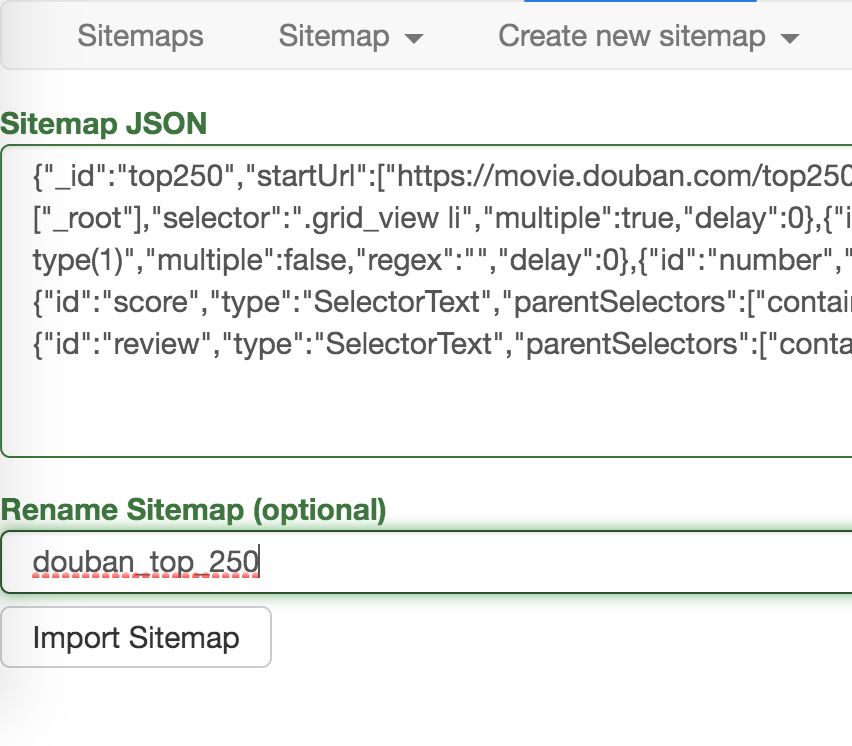
这期我们介绍了 Web Scraper 如何导入导出 Sitemap 爬虫文件,下一期我们对上一期的内容进行扩展,不单单抓取 250 个电影名,还要抓取每个电影对应的排名,名字,评分和一句话影评。
Web Scraper 抓取多条内容
我们在实操前先把逻辑理清:
上几篇只抓取了一类元素:电影名字。这期我们要抓取多类元素:排名,电影名,评分和一句话影评。
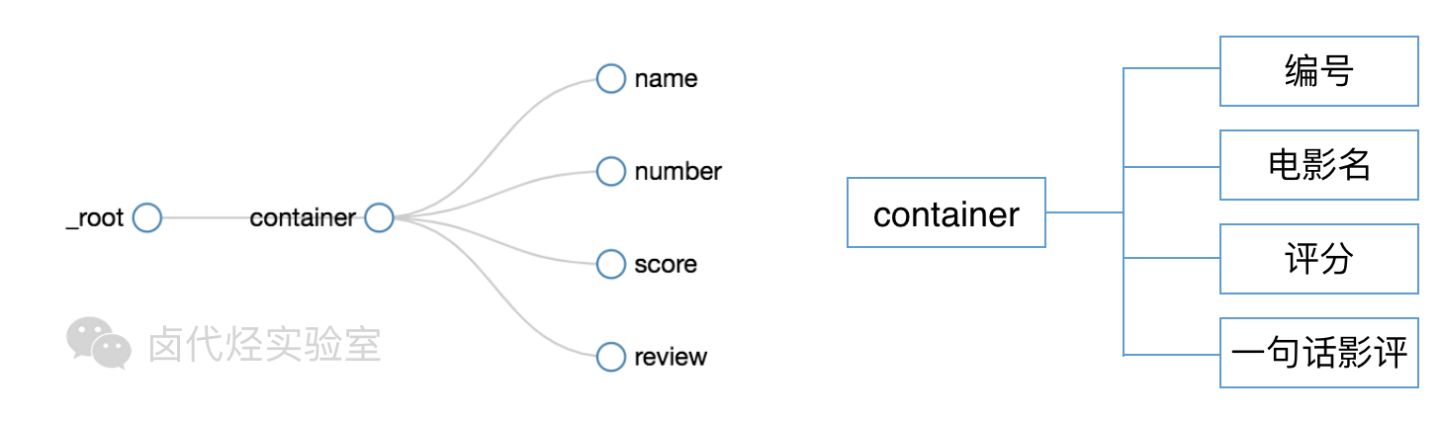
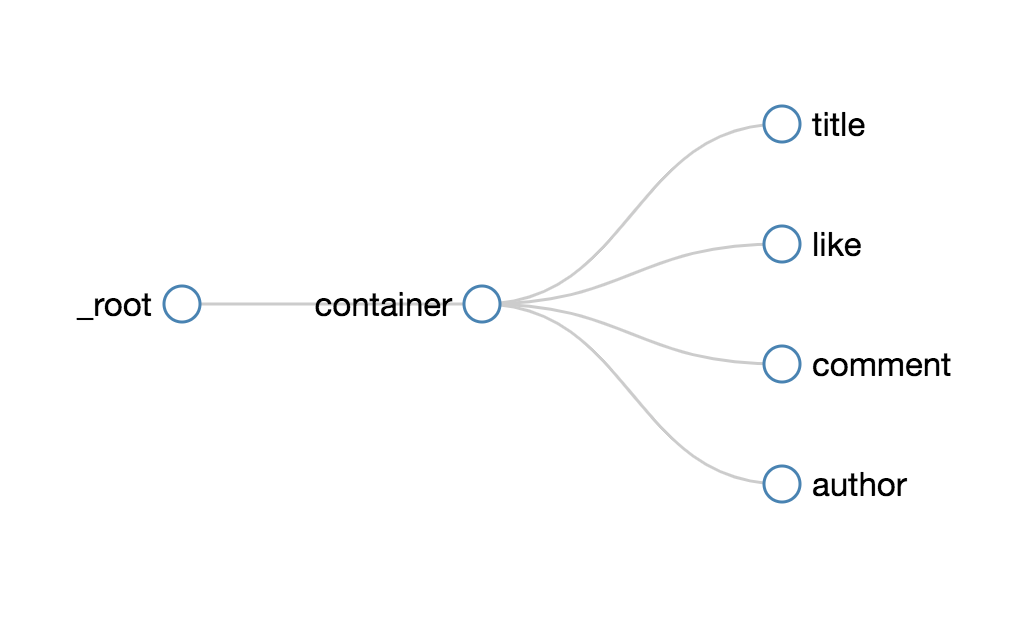
根据 Web Scraper 的特性,想抓取多类数据,首先要抓取包裹多类数据的容器,然后再选择容器里的数据,这样才能正确的抓取。我画一张图演示一下:
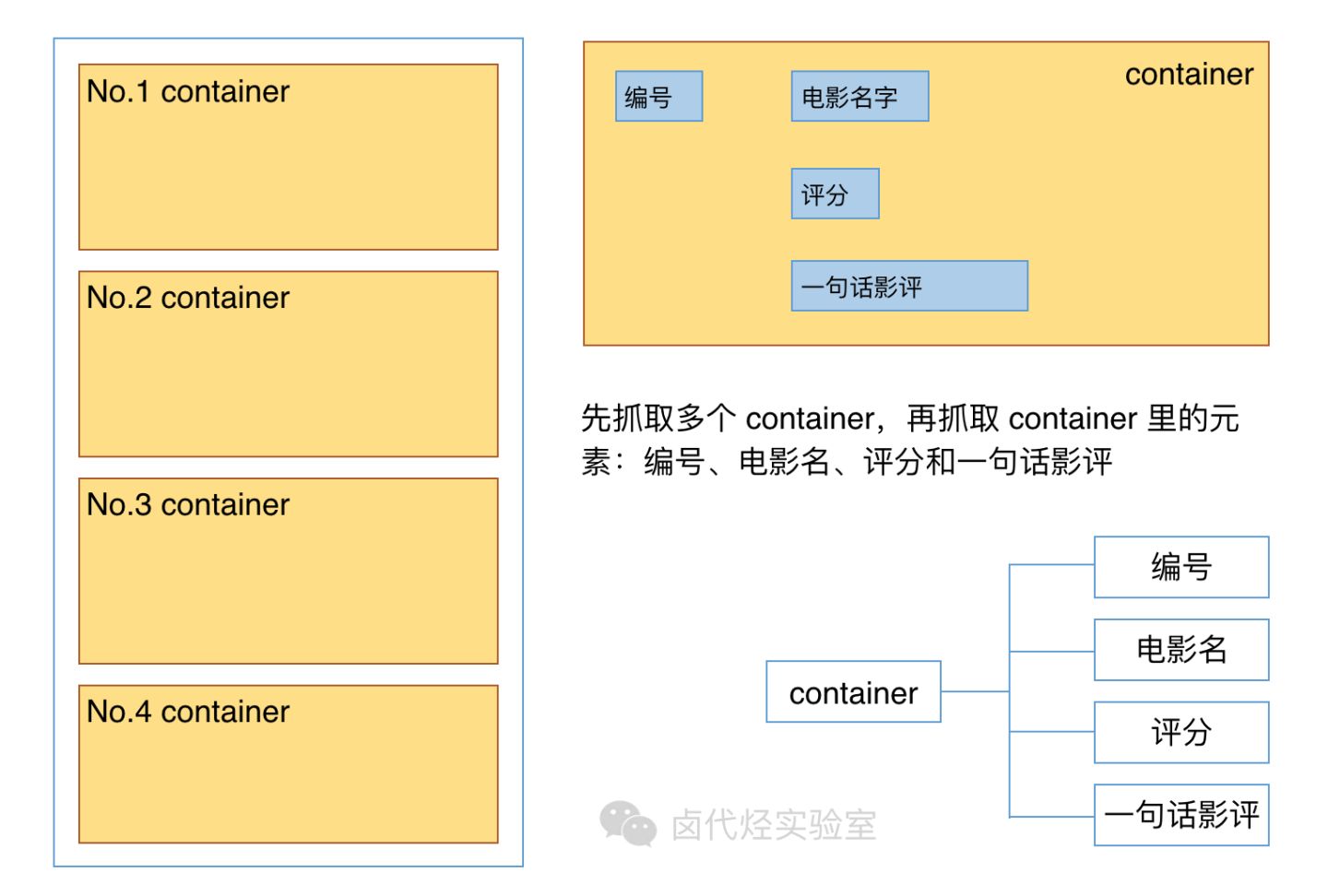
我们首先要抓取多个 container(容器),再抓取 container 里的元素:编号、电影名、评分和一句话影评,当爬虫运行完后,我们就会成功抓取数据。
概念上搞清楚了,我们就可以讲实际操作了。
如果对以下的操作有疑问,可以看 简易数据分析 04 的内容,那篇文章详细图解了如何用 Web Scraper 选择元素的操作
1.点击 Stiemaps,在新的面板里点击 ID 为 top250 的这列数据

2.删除掉旧的 selector,点击 Add new selector 增加一个新的 selector
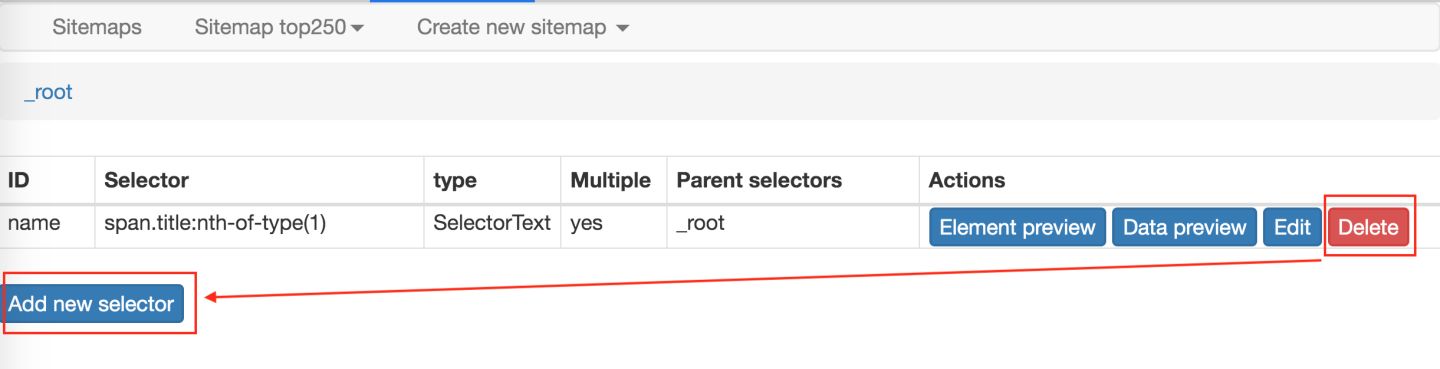
3.在新的 selector 内,注意把 Type 类型改为 Element(元素),因为在 Web Scraper 里,只有元素类型才能包含多个内容。
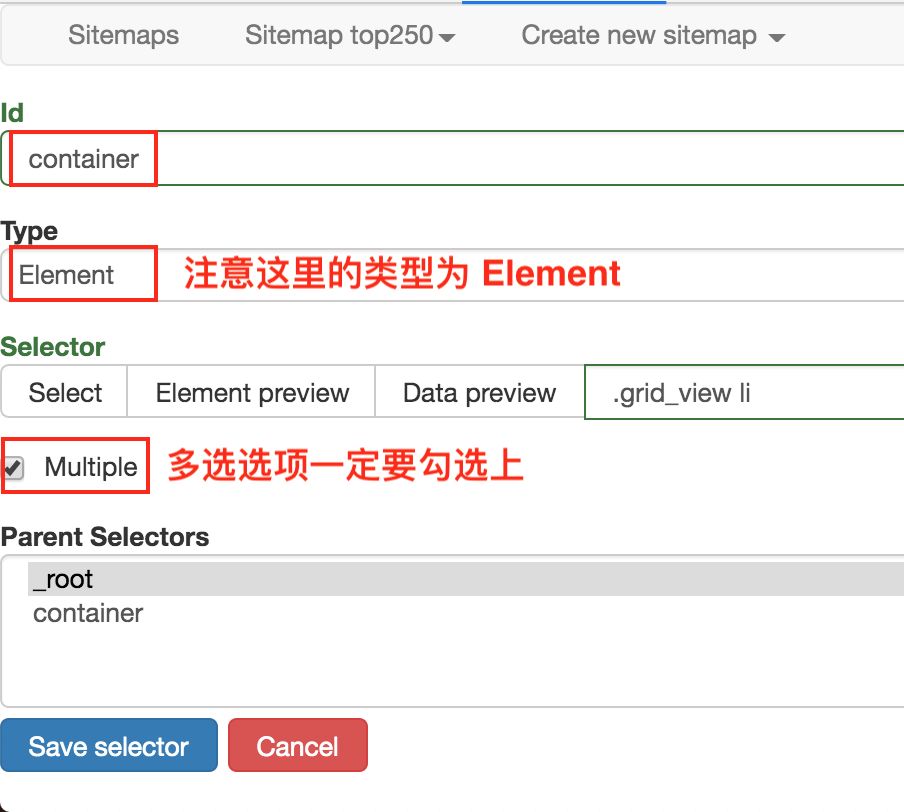
我们勾选的元素区域如下图所示,确认无误后点击 Save selector 按钮,就会回退到上一个操作面板。
在新的面板里,点击刚刚创建的 selector 那行数据:
点击后我们就会进入一个新的面板,根据导航我们可知在 container 内部。
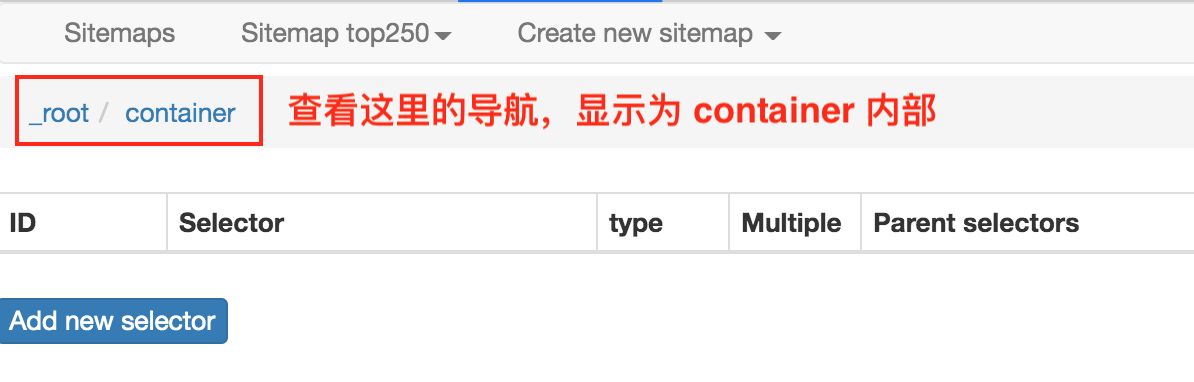
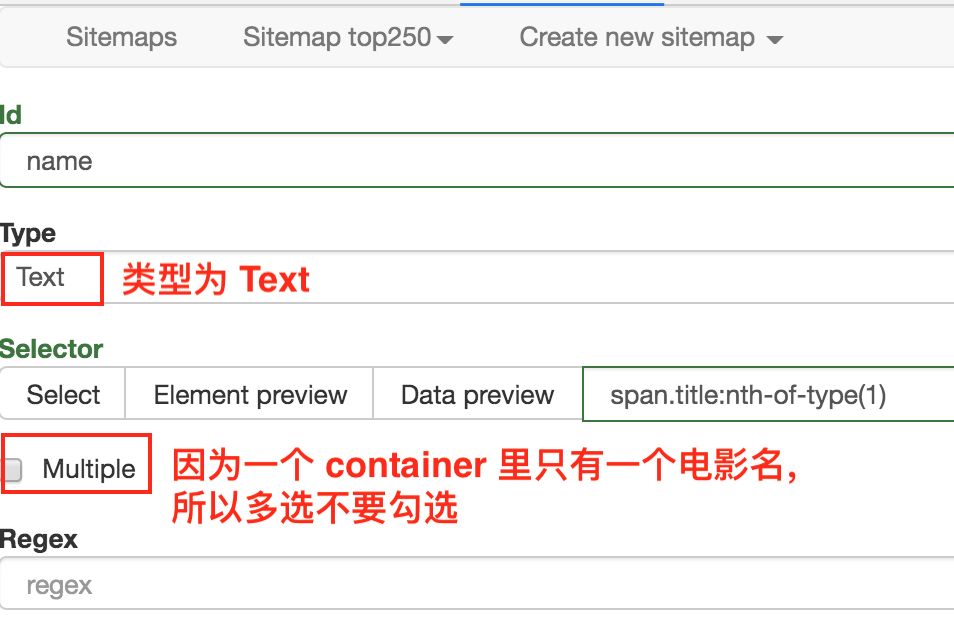
在新的面板里,我们点击 Add new selector,新建一个 selector,用来抓取电影名,类型为 Text,值得注意的是,因为我们是在 container 内选择文字的,一个 container 内只有一个电影名,所以多选不要勾选,要不然会抓取失败。
选择电影名的时候你会发现 container 黄色高亮,我们就在黄色的区域里选择电影名就好了。
点击 Save selector 保存选择器后,我们再创建三个选择器,分别选择编号、评分和一句话影评,因为操作和上面一模一样,我这里就省略讲解了。
排名编号:
评分:
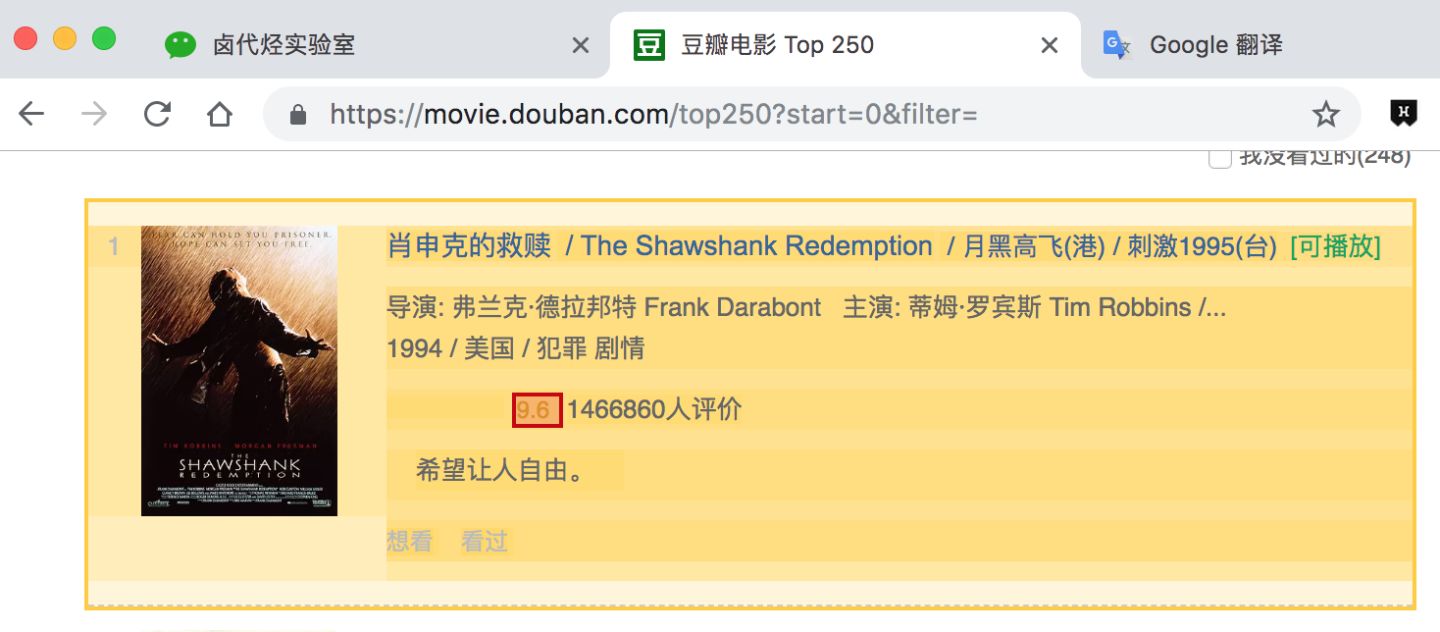
一句话影评:
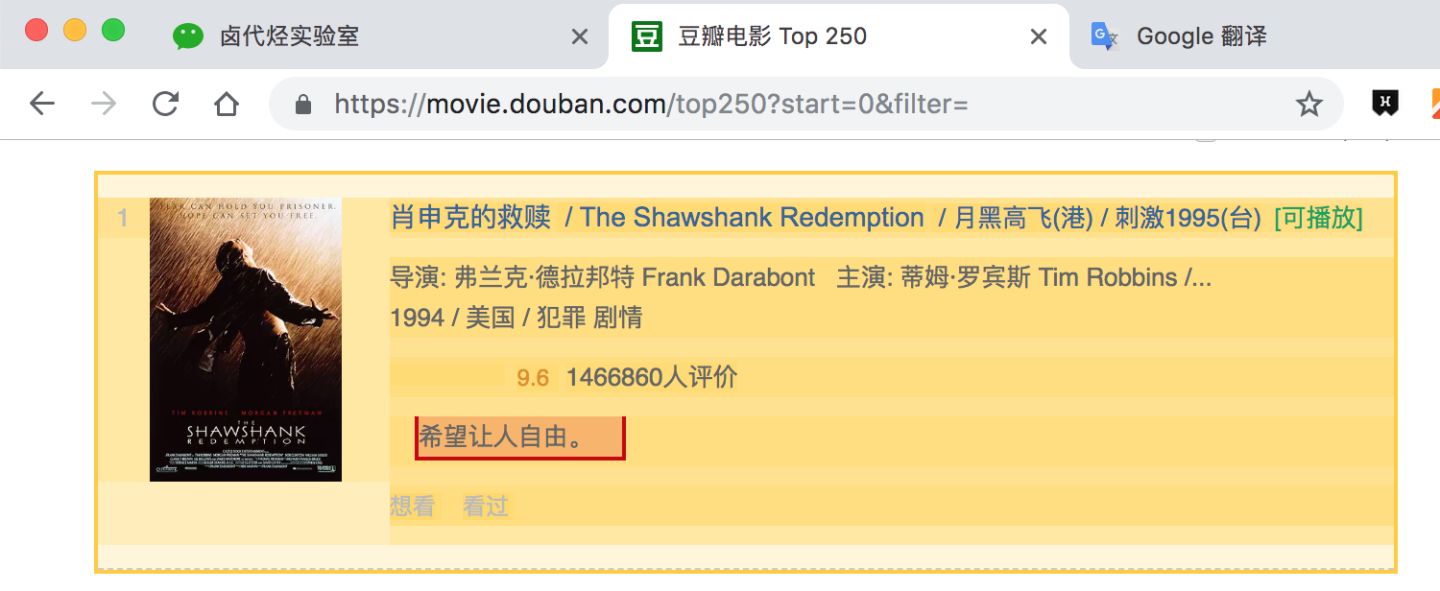
我们可以在面板里观察我们选择的多个元素,一共有四个元素:分别为 name、number、score 和 review,类型都是 Text,不需要多选,父选择器都是 container。
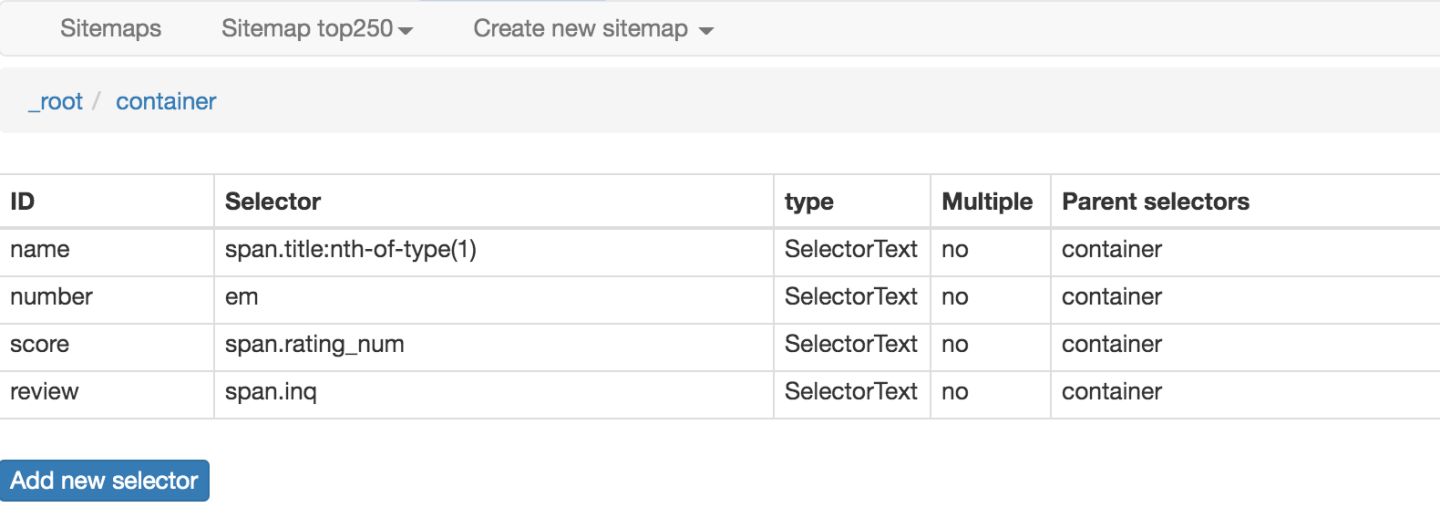
我们可以点击 点击 Stiemap top250 下的 selector graph,查看我们爬虫选择元素的层级关系,确认正确后我们再点击 Stiemap top250 下的 Selectors,回到选择器展示面板。
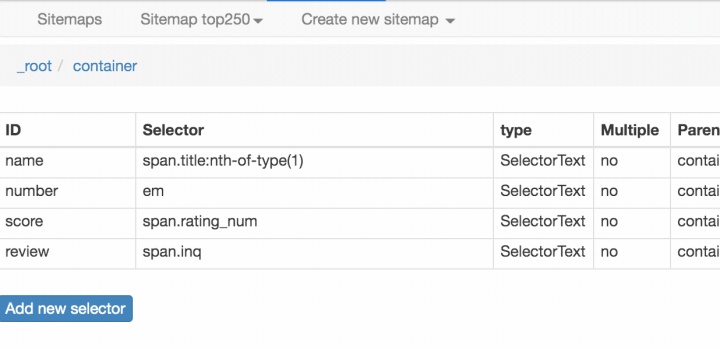
下图就是我们这次爬虫的层级关系,是不是和我们之前理论分析的一样?
确认选择无误后,我们就可以抓取数据了,操作在 简易数据分析 04 、 简易数据分析 05 里都说过了,忘记的朋友可以看旧文回顾一下。下图是我抓取的数据:
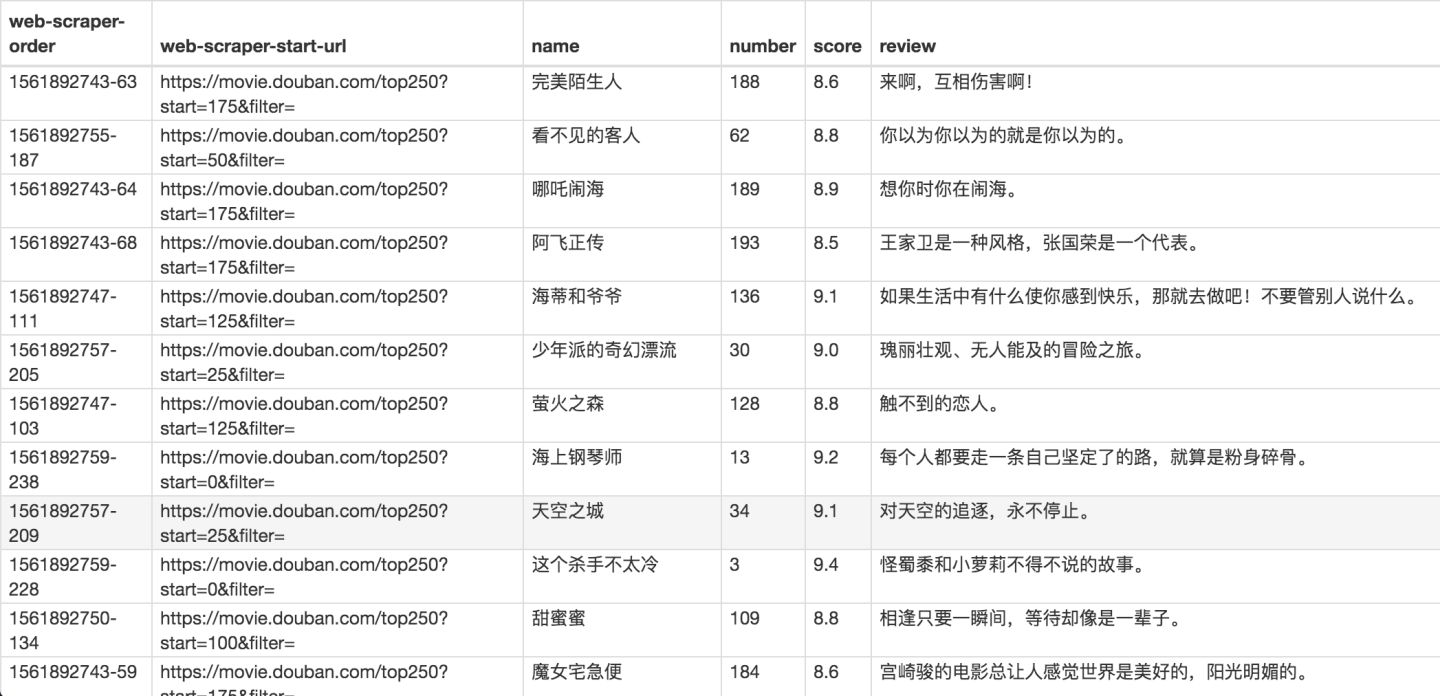
还是和以前一样,数据是乱序的,不过这个不要紧,因为排序属于数据清洗的内容了,我们现在的专题是数据抓取。先把相关的知识点讲完,再攻克下一个知识点,才是更合理的学习方式。
今天的内容其实还是比较多的,大家可以先消化一下,下一篇我们讲讲,如何抓取点击「加载更多」加载数据的网页内容。
Sitemap 分享:
这次的 sitemap 就分享给大家,大家可以导入到 Web Scraper 中进行实验,具体方法可以看我上一篇教程。
Sitemap: {“> _id”:”top250”,”startUrl”:[“https://movie.douban.com/top250?start=[0-250:25]&filter=”],”selectors”:[{“id”:”container”,”type”:”SelectorElement”,”parentSelectors”:[“_root”],”selector”:”.grid_view li”,”multiple”:true,”delay”:0},{“id”:”name”,”type”:”SelectorText”,”parentSelectors”:[“container”],”selector”:”span.title:nth-of-type(1)”,”multiple”:false,”regex”:””,”delay”:0},{“id”:”number”,”type”:”SelectorText”,”parentSelectors”:[“container”],”selector”:”em”,”multiple”:false,”regex”:””,”delay”:0},{“id”:”score”,”type”:”SelectorText”,”parentSelectors”:[“container”],”selector”:”span.rating_num”,”multiple”:false,”regex”:””,”delay”:0},{“id”:”review”,”type”:”SelectorText”,”parentSelectors”:[“container”],”selector”:”span.inq”,”multiple”:false,”regex”:””,”delay”:0}]}
点击「更多按钮」翻页
你在预览一些网站时,会发现随着网页的下拉,你需要点击类似于「加载更多」的按钮去获取数据,而网页链接一直没有变化。
所以控制链接批量抓去数据的方案失效了,所以我们需要模拟点击「加载更多」按钮,去抓取更多的数据。
今天我们讲的,就是利用 web scraper 里的 Element click 模拟点击「加载更多」,去加载更多的数据。
这次的练习网站,我们拿少数派网站的热门文章作为我们的练习对象,对应的网址链接是:
https://sspai.com/tag/%E7%83%AD%E9%97%A8%E6%96%87%E7%AB%A0#home
为了复习上一个小节的内容,这次我们模拟点击翻页的同时,还要抓取多条内容,包括作者、标题、点赞数和评论数。
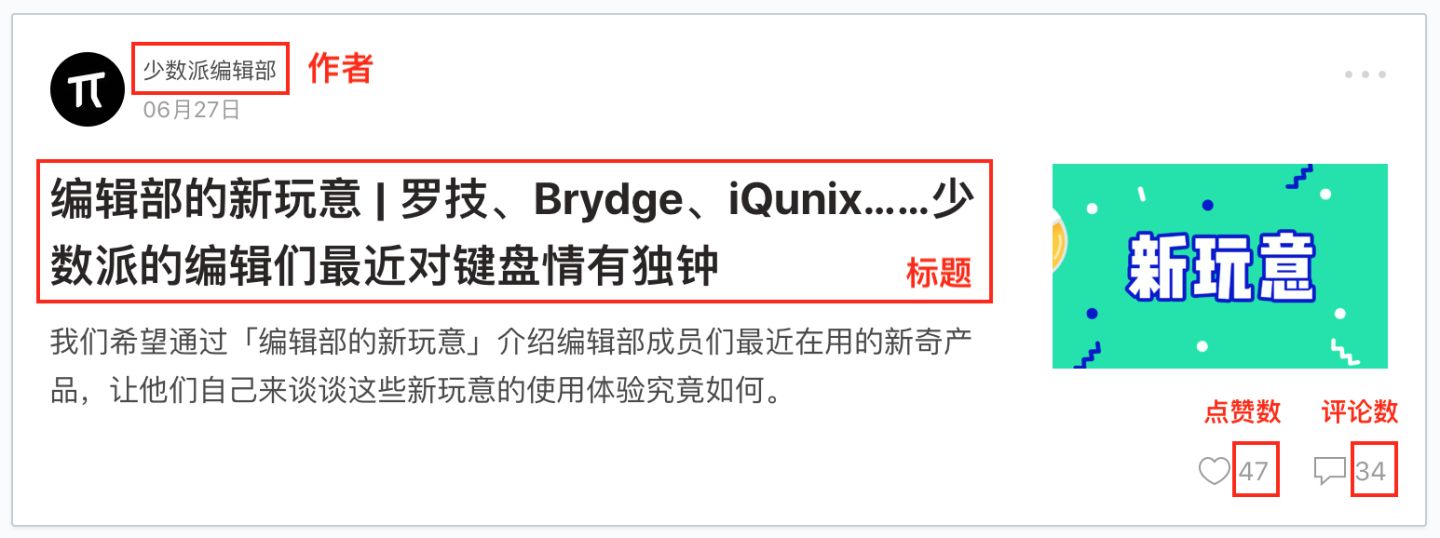
下面开始我们的数据采集之路。
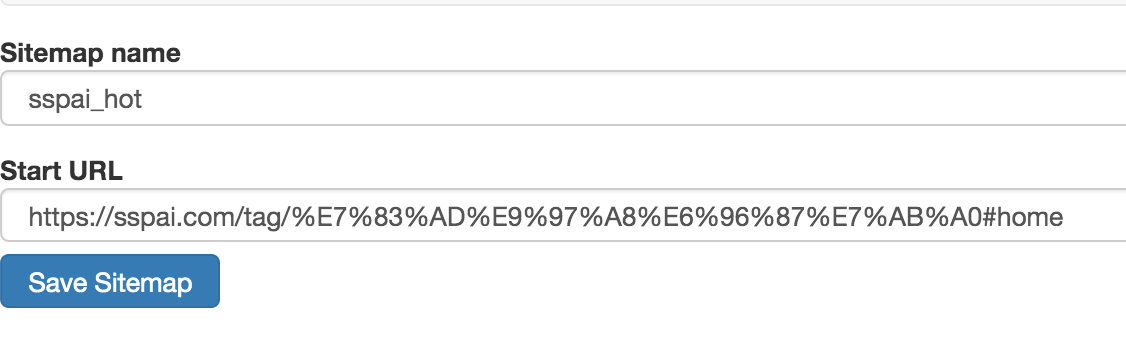
1.创建 sitmap
老规矩,第一步我们先创建一个少数派的 sitmap,取名为 sspai_hot,起始链接为 https://sspai.com/tag/%E7%83%AD%E9%97%A8%E6%96%87%E7%AB%A0#home。
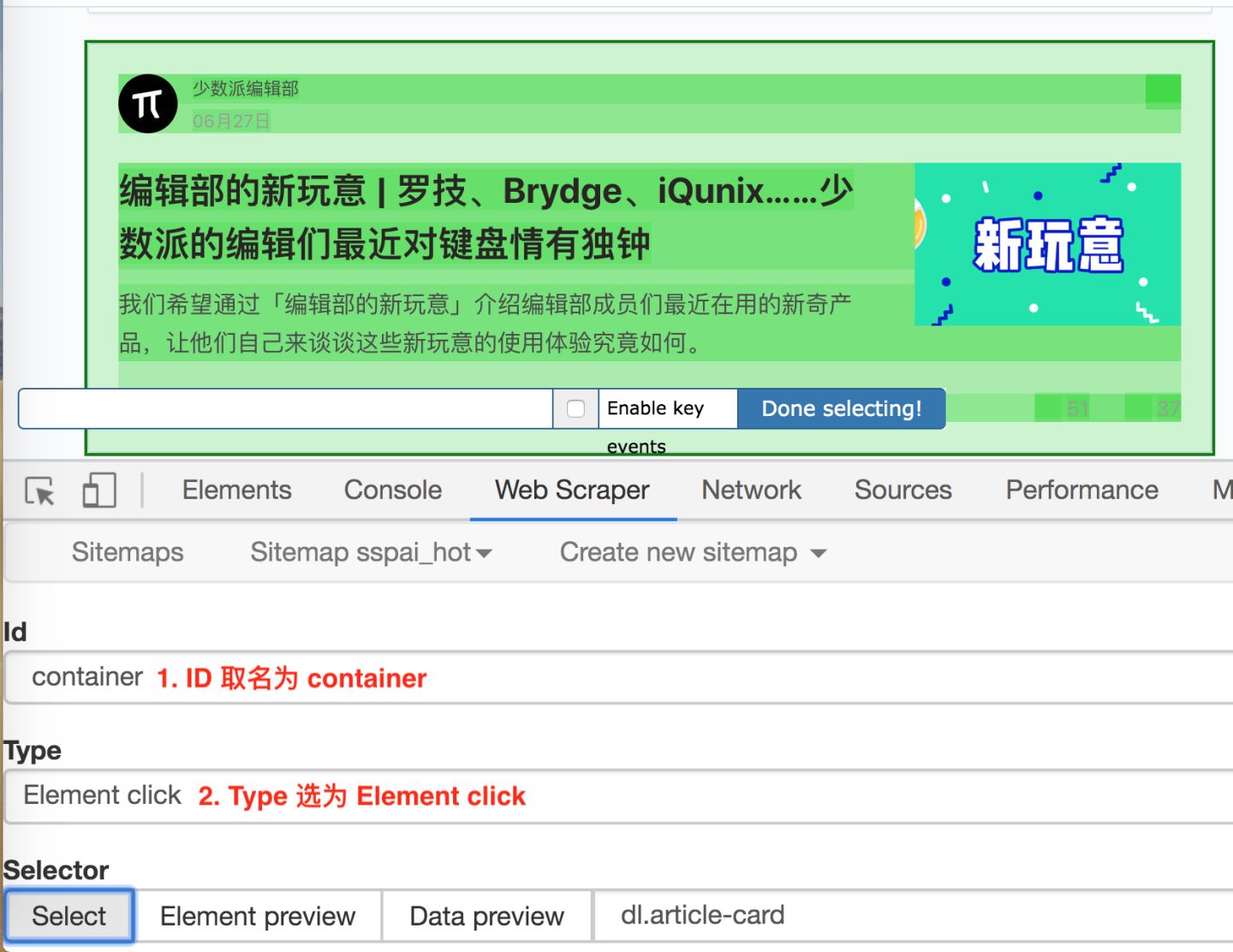
2.创建容器的 selector
通过上一节的内容,我们知道想在 web scraper 里想抓取多种类型的数据,必须先创建一个容器(container),这个容器包含多种类型的数据,所以我们第二步就是要创建容器的 selector。
要注意的是,这个 selector 的 Type 类型选为 Element click,翻译成中文就是模拟点击元素,意如其名,我们可以利用这种类型模拟点击「加载更多」按钮。
这种类型的 selector,会多出几个选项,第一个就是 Click selector,这个就是选择「加载更多」按钮的,具体操作可见下图的动图。
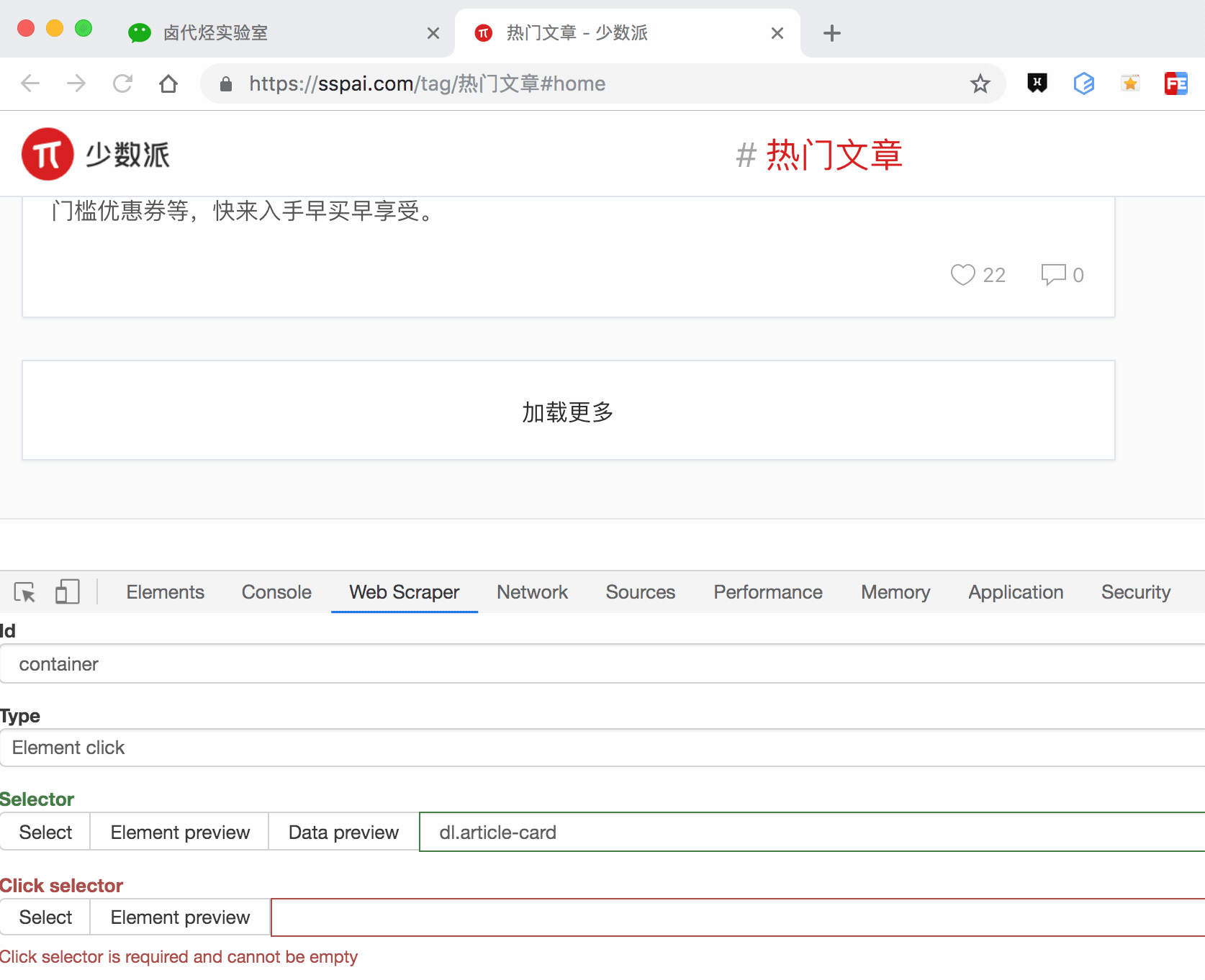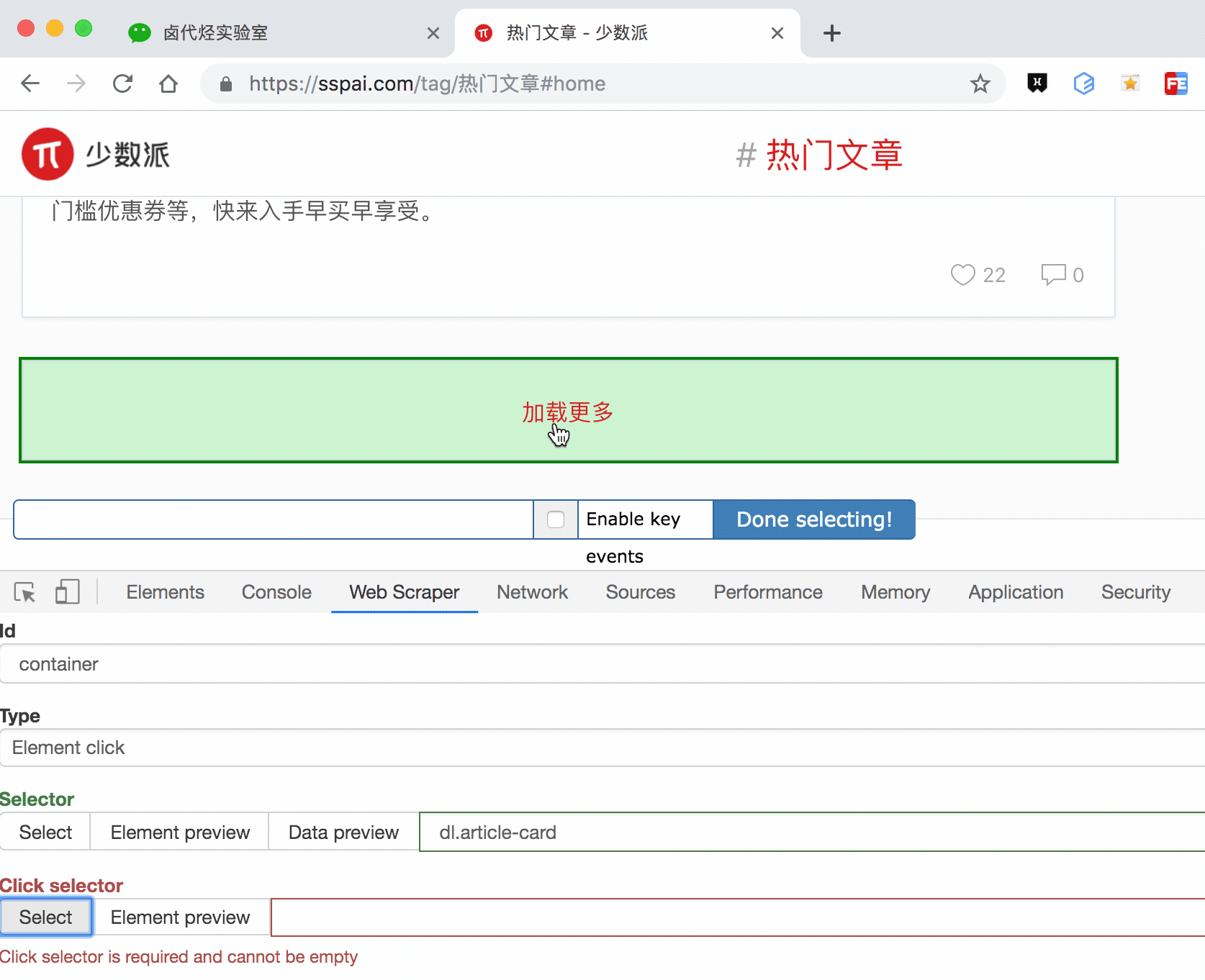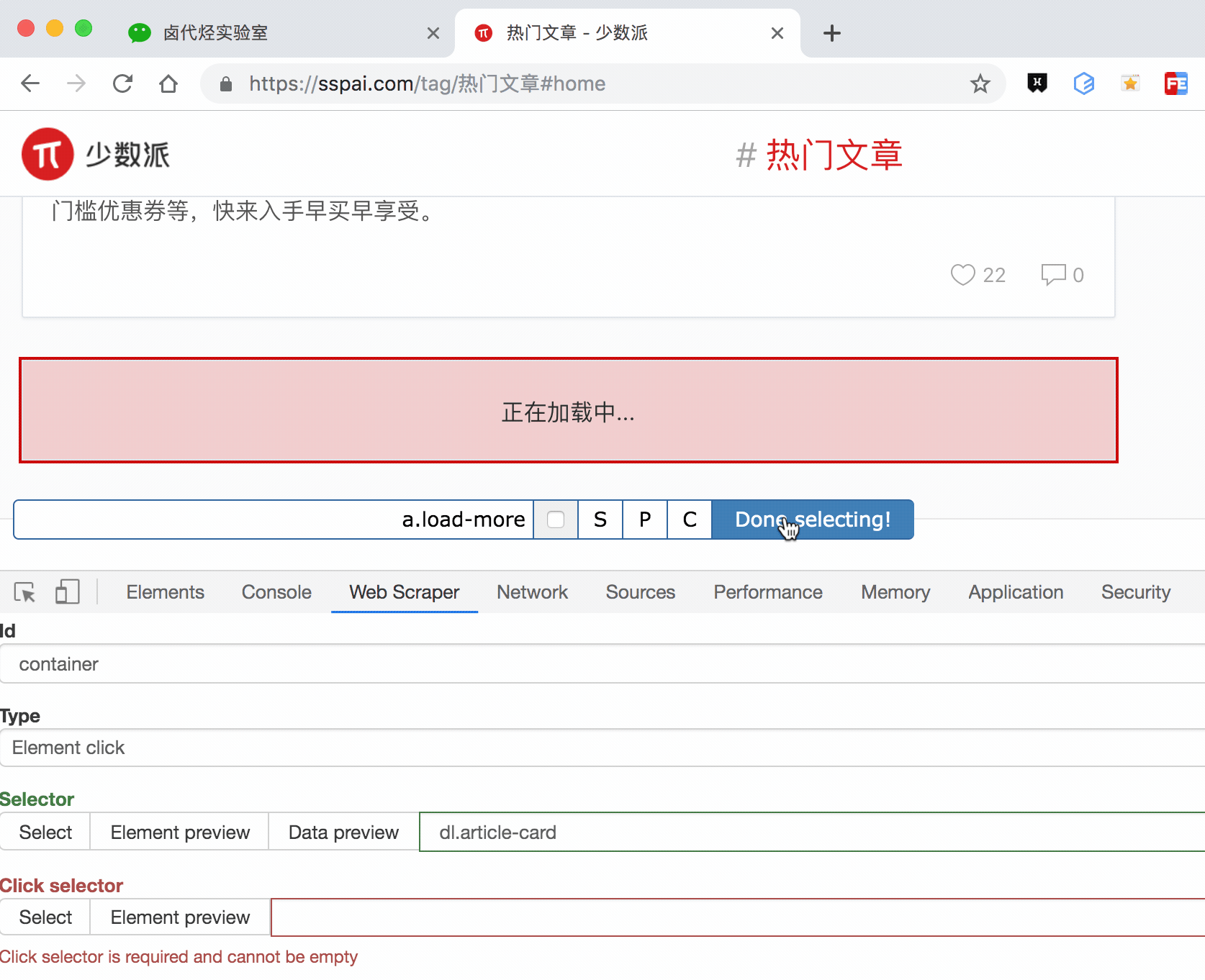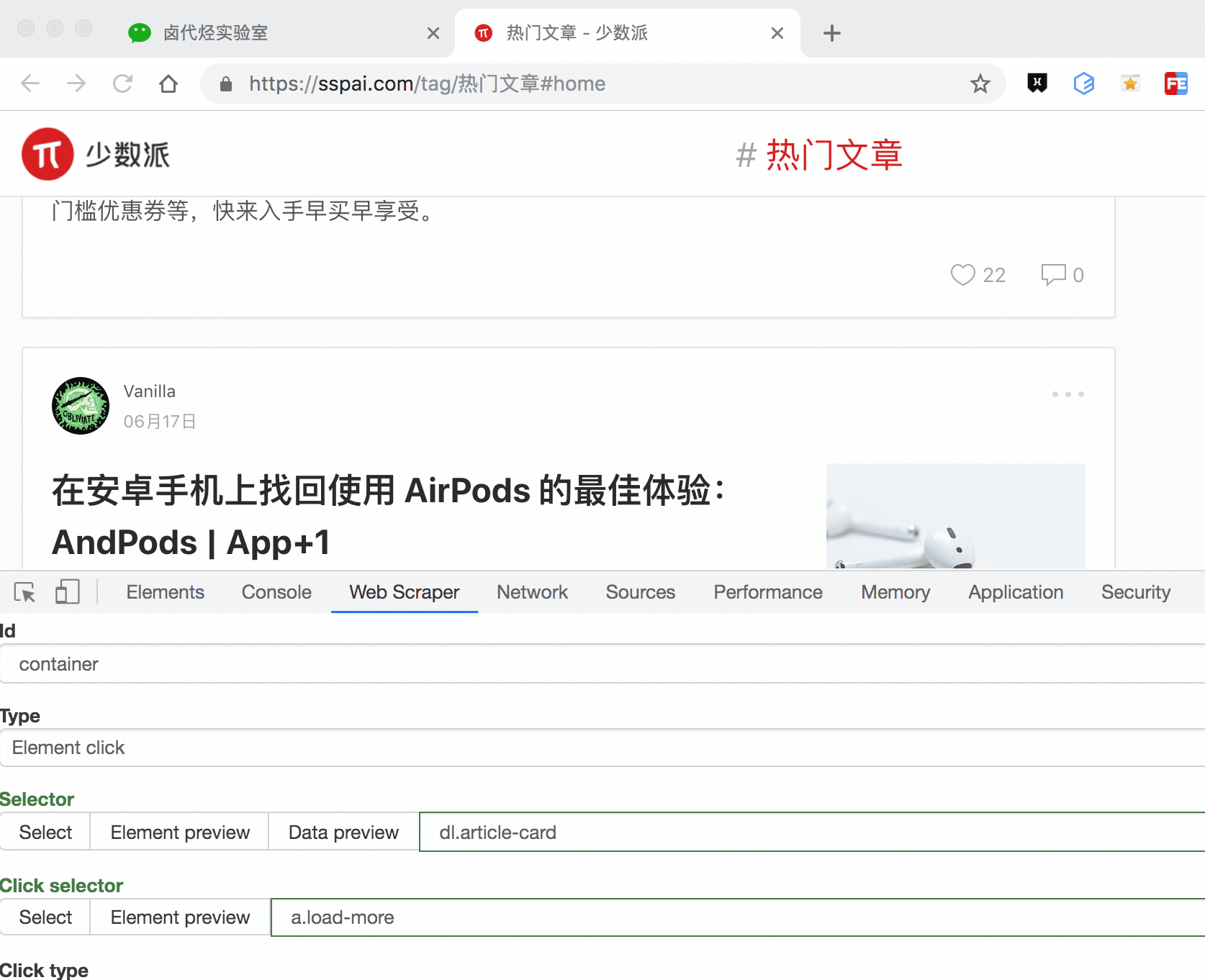
还有几个多出来的选项,我们一一解释一下:
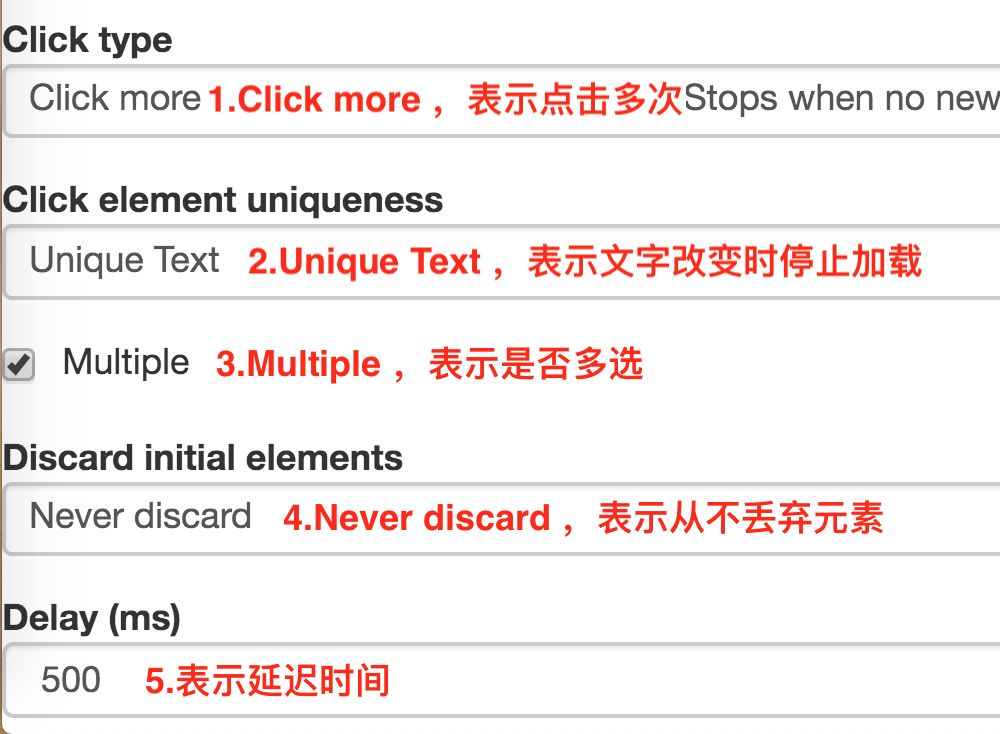
1.Click type
点击类型,click more 表示点击多次,因为我们要抓取批量数据,这里就选择 click more,还有一个 click once 选项,点击一次
2.Click element uniqueness
这个选项是控制 Web Scraper 什么时候停止抓取数据的。比如说 Unique Text,表示文字改变时停止抓取数据。
我们都知道,一个网站的数据不可能是无穷无尽的,总有加载完的时候,这时候「加载更多」按钮文字可能就变成「没有更多」、「没有更多数据」、「加载完了」等文字,当文字变动时,Web scraper 就会知道没有更多数据了,会自动停止抓取数据。
3.Multiple
这个我们的老朋友了,表示是否多选,这里我们要抓取多条数据,当然要打勾。
4.Discard initial elements
是否丢弃初始元素,这个主要是去除一些网站的重复数据用的,不是很重要,我们这里也用不到,直接选择 Never discard,从不丢弃数据。
5.Delay
延迟时间,因为点击加载更多后,数据加载需要一段时间,delay 就是等待数据加载的时间。一般我们设置要大于等于 2000,因为延迟 2s 是一个比较合理的数据,如果网络不好,我们可以设置更大的数字。
3.创建子选择器
接下来我们创建几个子选择器,分别抓取作者、标题、点赞数和评论数四种类型的数据,详细操作我在上一篇教程中已经说明了,这里我就不详细说明了。整个爬虫的结构如下,大家可以参考一下:
4.抓取数据
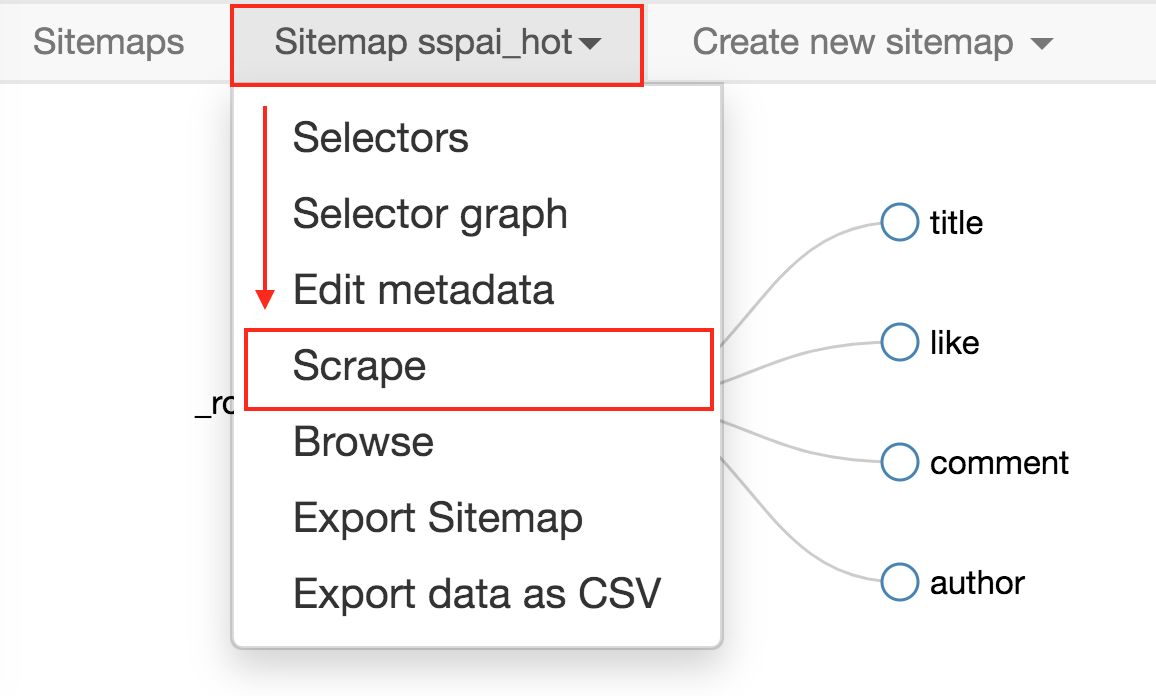
按照 Sitemap spay_hot -> Scrape 的操作路径就可以抓取数据了。
今天我们学习了通过 Web Scraper 抓取点击加载更多类型的网页。实践过程中,你会发现这种类型的网页无法控制爬取数目,不像豆瓣 TOP250,明明白白就是 250 条数据,不多也不少。下一篇我们就聊聊,如何利用 Web Scraper,自动控制抓取的数目。
Web Scraper自动控制抓取数量 & Web Scraper父子选择器
我们把单选按钮选择后,会出现 S ,P, C 三个字符,意思分别如下:
S:Select,按下键盘的 S 键,选择选中的元素
P:Parent,按下键盘的 P 键,选择选中元素的父节点
C:Child,按下键盘的 C 键,选择选中元素的子节点
我们分别演示一下,首先是通过 S 键选择标题节点:
我们对比上个动图,会发现节点选中变红的同时,并没有打开新的网页。
如何抓取选中元素的父节点 or 子节点?
通过 P 键和 C 键选择父节点和子节点:
按压 P 键后,我们可以明显看到我们选择的区域大了一圈,再按 C 键后,选择区域又小了一圈,这个就是父子选择器的功能。
这期介绍了 Web Scraper 的两个使用小技巧,下期我们说说 Web Scraper 如何抓取无限滚动的网页。
Web Scraper 翻页——抓取「滚动加载」类型
我们在刷朋友圈刷微博的时候,总会强调一个『刷』字,因为看动态的时候,当把内容拉到屏幕末尾的时候,APP 就会自动加载下一页的数据,从体验上来看,数据会源源不断的加载出来,永远没有尽头。

我们今天就是要讲讲,如何利用 Web Scraper 抓取滚动到底翻页的网页。
今天我们的练手网站是知乎数据分析模块的精华帖,网址为:
https://www.zhihu.com/topic/19559424/top-answers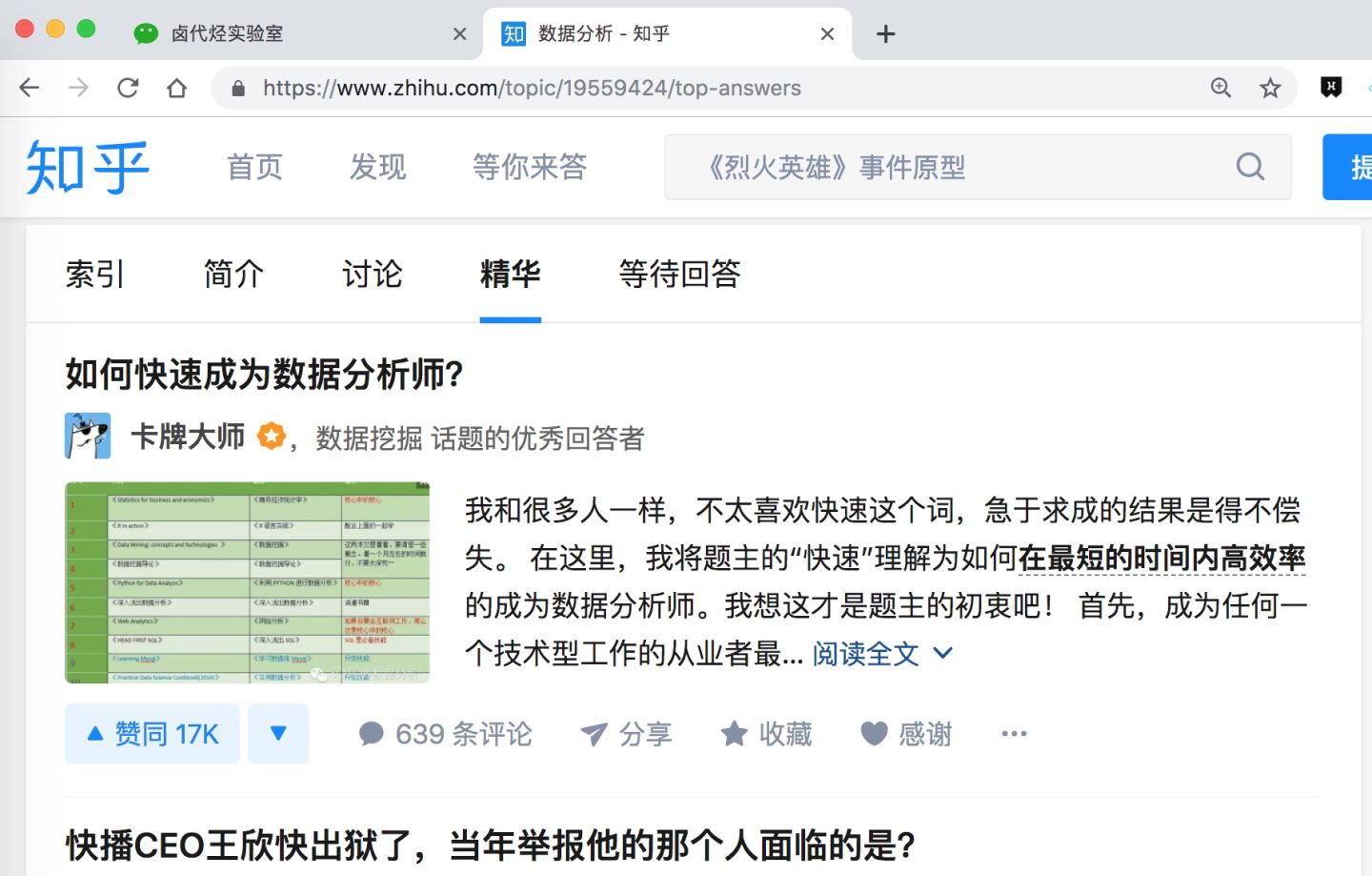
这次要抓取的内容是精华帖的标题、答题人和赞同数。下面是今天的教程。
1.制作 Sitemap
刚开始我们要先创建一个 container,包含要抓取的三类数据,为了实现滚动到底加载数据的功能,我们把 container 的 Type 选为 Element scroll down,就是滚动到网页底部加载数据的意思。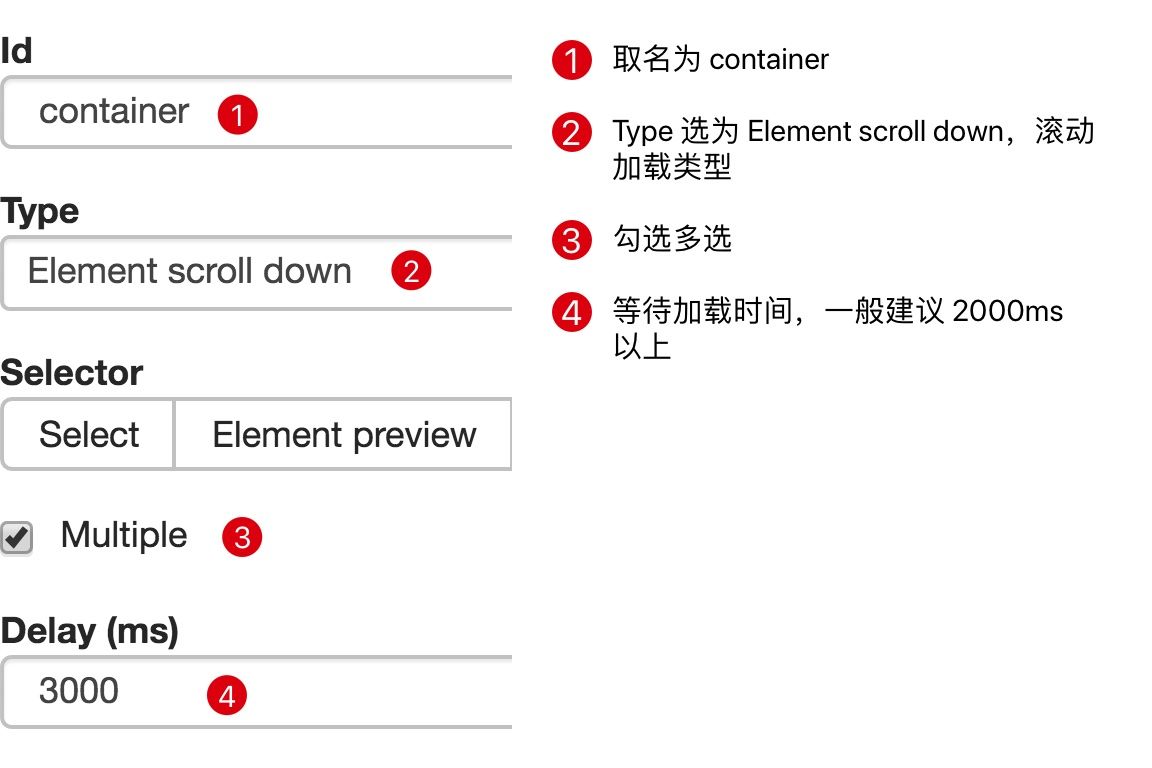
在这个案例里,选择的元素名字为 div.List-item。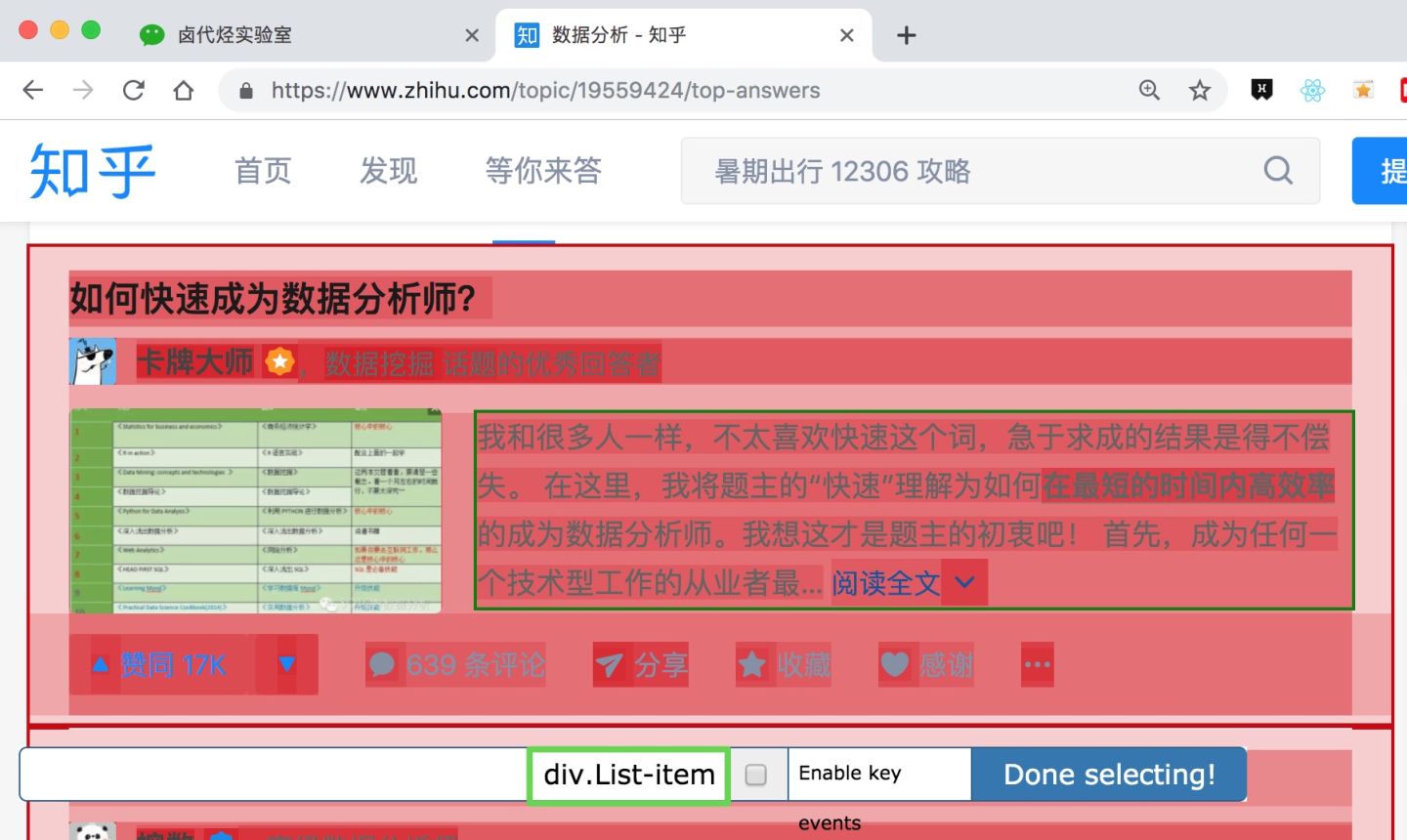
为了复习上一节通过数据编号控制条数的方法,我们在元素名后加个 nth-of-type(-n+100),暂时只抓取前 100 条数据。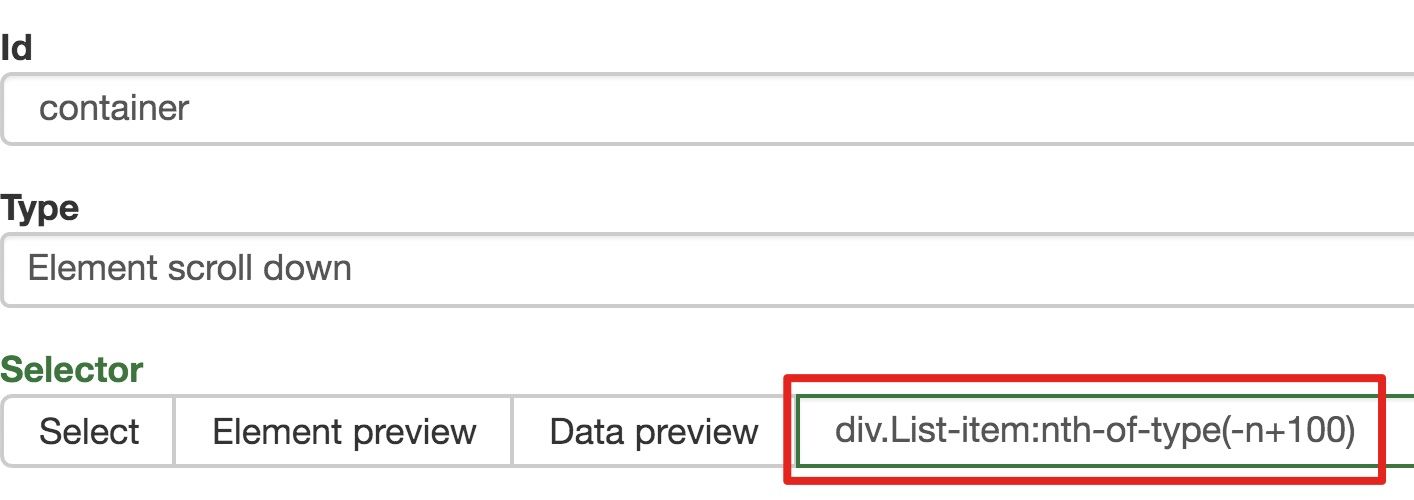
然后我们保存 container 这个节点,并在这个节点下选择要抓取的三个数据类型。
首先是标题,我们取名为 title,选择的元素名为 [itemprop='zhihu:question'] a:
然后是答题人名字 name 与 赞同数 like,选择的元素名分别为 #Popover10-toggle a 和 button.VoteButton--up:

2.爬取数据,发现问题
元素都选择好了,我们按 Sitemap zhihu_top_answers -> Scrape -> Start craping 的路径进行数据抓取,等待十几秒结果出来后,内容却让我们傻了眼: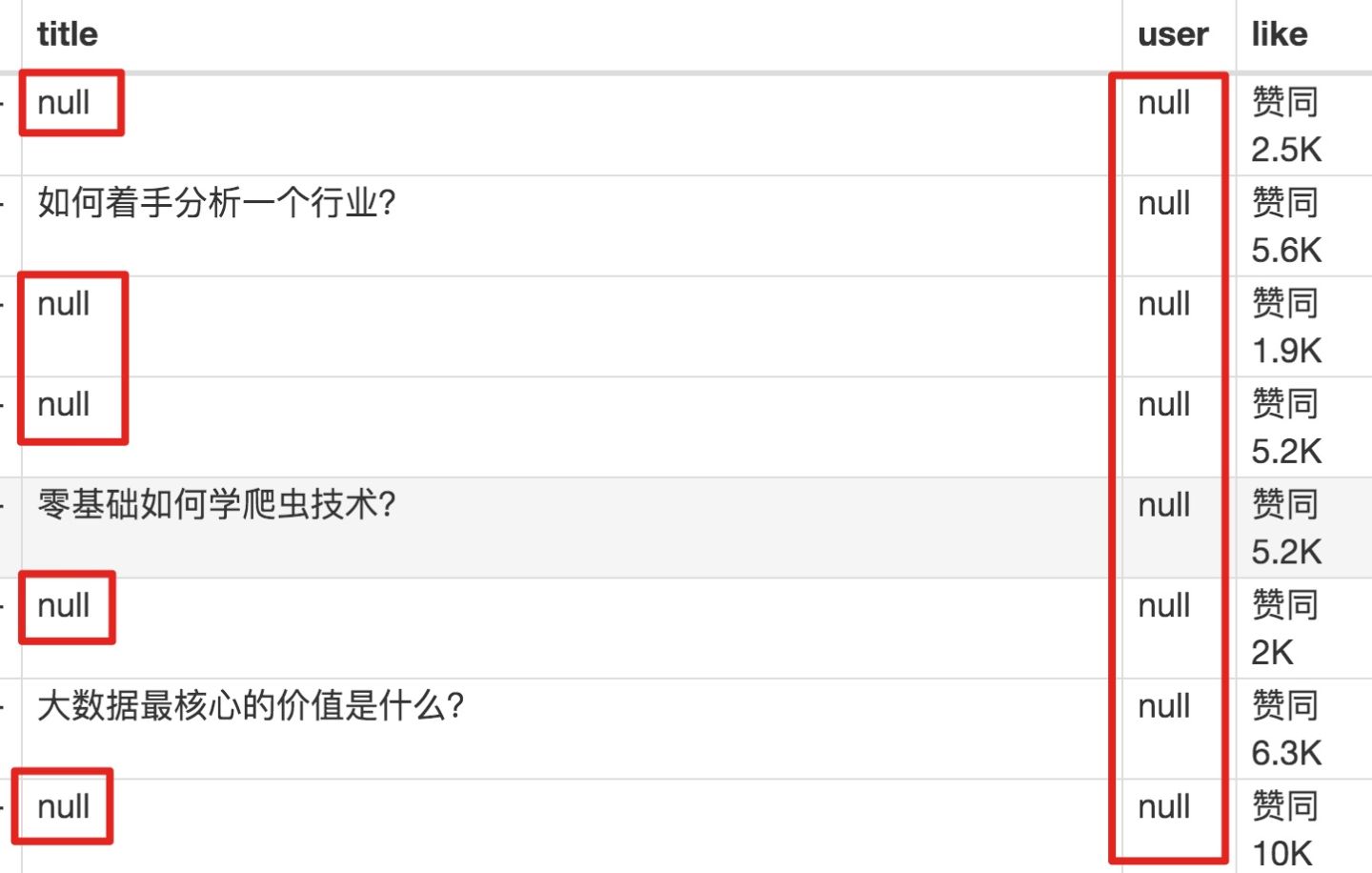
数据呢?我要抓的数据呢?怎么全变成了 null?
在计算机领域里,null 一般表示空值,表示啥都没有,放在 Web Scraper 里,就表示没有抓取到数据。
我们可以回想一下,网页上的的确确存在数据,我们在整个的操作过程中,唯一的变数就是选择元素这个操作上。所以,肯定是我们选择元素时出错了,导致内容匹配上出了问题,无法正常抓取数据。要解决这个问题,我们就要查看一下网页的构成。
3.分析问题
查看一下网页的构成,就要用浏览器的另一个功能了,那就是选择查看元素。
1.我们点击控制面板左上角的箭头,这时候箭头颜色会变蓝。
2.然后我们把鼠标移动到标题上,标题会被一个蓝色的半透明遮罩盖住。
3.我们再点击一下标题,会发现我们会跳转到 Elements 这个子面板,内容是一些花花绿绿看不大懂的代码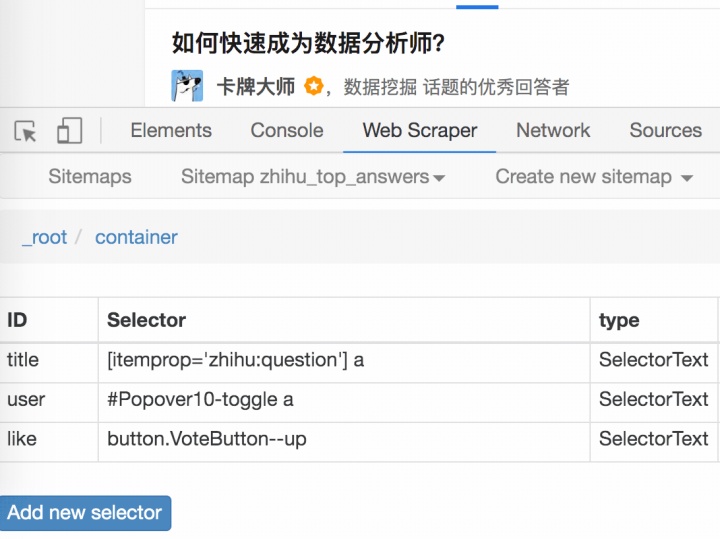
做到这里心里别发怵,这些 HTML 代码不涉及什么逻辑,在网页里就是个骨架,提供一些排版的作用。如果你平常用 markdown 写作,就可以把 HTML 理解为功能更复杂的 markdown。
结合 HTML 代码,我们先看看 [itemprop='zhihu:question'] a 这个匹配规则是怎么回事。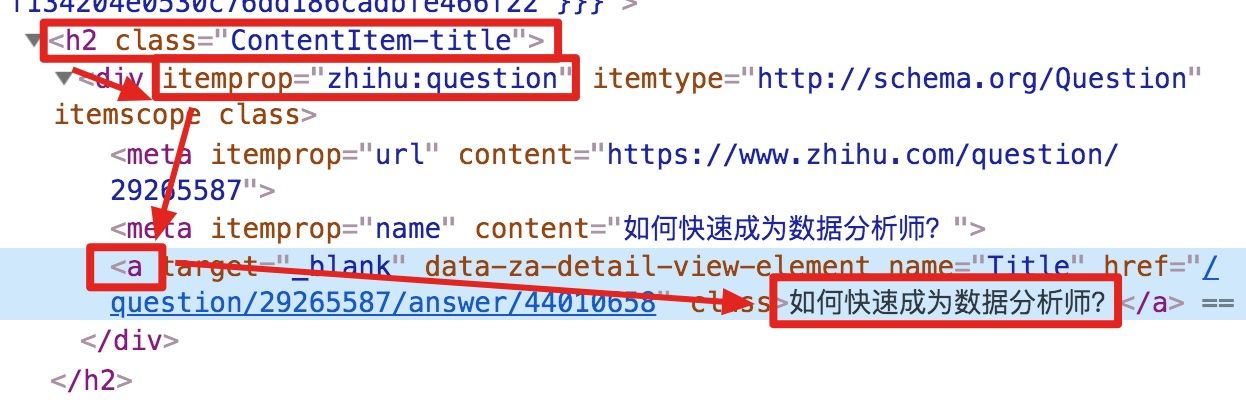
首先这是个树形的结构:
- 先是一个名字为 h2 的标签
<h2>...</h2>,它有个class='ContentItem-title'的属性; - 里面又有个名为 div 的标签
<div>...</div>,它有个itemprop='zhihu:question'的属性; - div 标签里又有一个 名字为 a 的标签
<a>...</a>; - a 标签里有一行字,就是我们要抓取的标题:
如何快速成为数据分析师?
上句话从可视化的角度分析,其实就是一个嵌套的结构,我把关键内容抽离出来,内容结构是不是清晰了很多?
<h2 class='ContentItem-title'/><div itemprop='zhihu:question'/><a>如何快速成为数据分析师?</a></div></h2>我们再分析一个抓取标题为 null 的标题 HTML 代码。
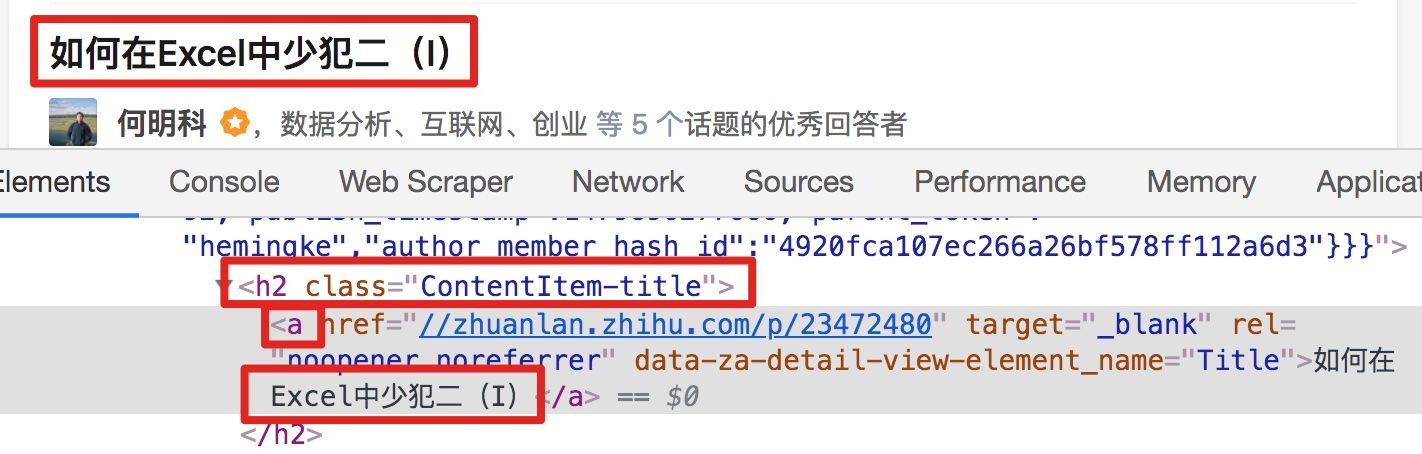
我们可以很清楚的观察到,在这个标题的代码里,少了名为 div 属性为 itemprop='zhihu:question' 的标签!这样导致我们的匹配规则匹配时找不到对应标签,Web Scraper 就会放弃匹配,认为找不到对应内容,所以就变成 null 了。
找到原因后我们就好解决问题了。
4.解决问题
我们发现,选择标题时,无论标题的嵌套关系怎么变,总有一个标签不变,那就是包裹在最外层的,属性名为 class='ContentItem-title' 的 h2 标签。我们如果能直接选择 h2 标签,不就可以完美匹配标题内容了吗?
逻辑上理清了关系,我们如何用 Web Scraper 操作?这时我们就可以用上一篇文章介绍的内容,利用键盘 P 键选择元素的父节点:
放在今天的课程里,我们点击两次 P 键,就可以匹配到标题的父标签 h2 (或 h2.ContentItem-title):
以此类推,因为答题人名字也出现了 null,我们分析了 HTML 结构后选择名字的父标签 span.AuthorInfo-name,具体的分析操作和上面差不多,大家可以尝试一下。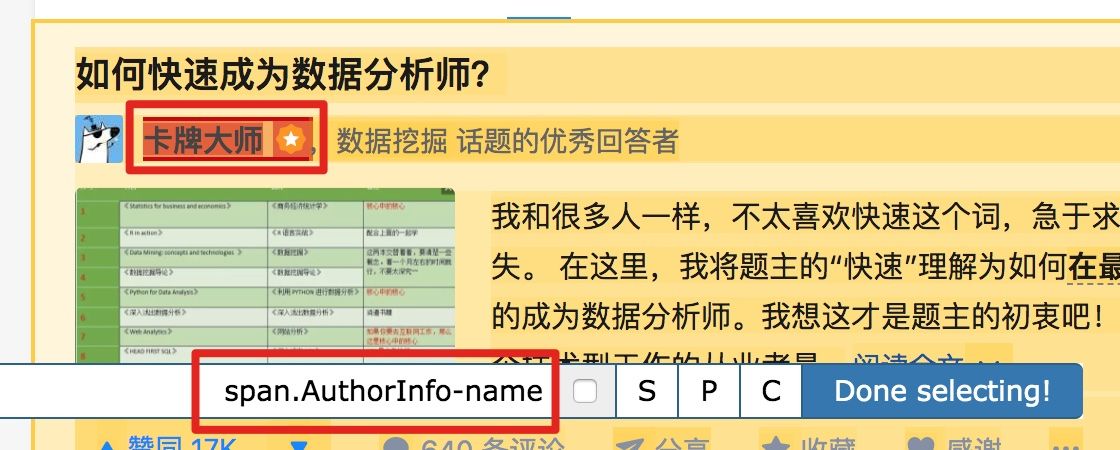
我的三个子内容的选择器如下,可以作为一个参考:
最后我们点击 Scrape 爬取数据,检查一下结果,没有出现 null,完美!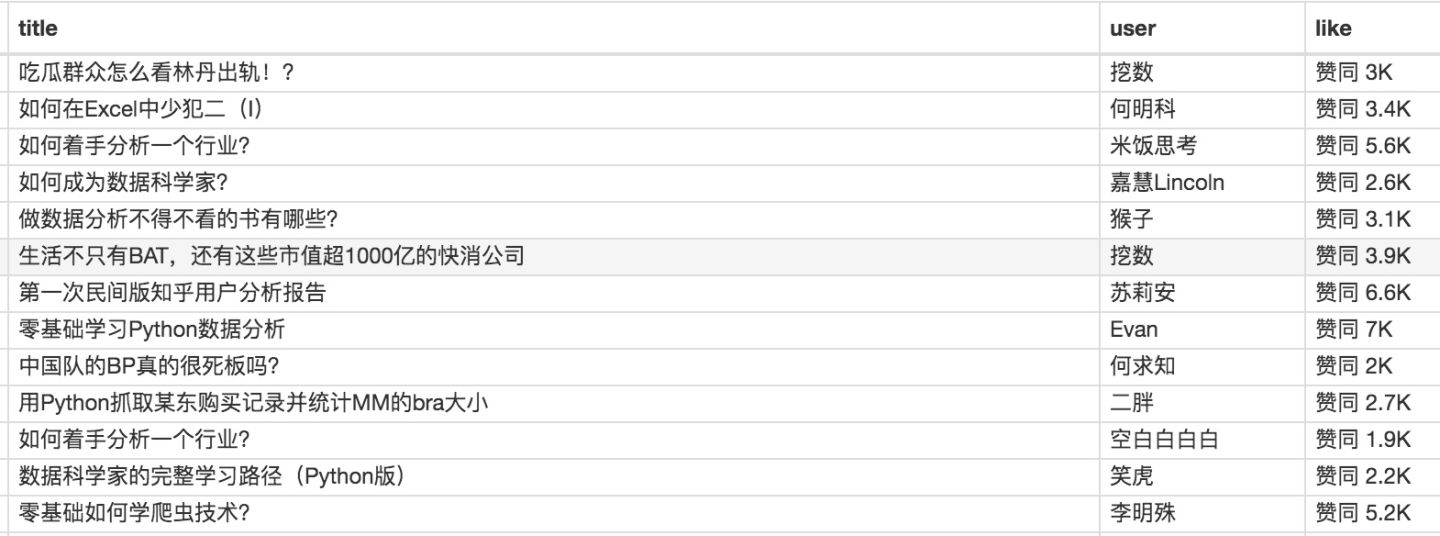
5.吐槽时间
爬取知乎数据时,我们会发现滚动加载数据那一块儿很快就做完了,在元素匹配那里却花了很多时间。
这间接的说明,知乎这个网站从代码角度上分析,写的还是比较烂的。
如果你爬取的网站多了,就会发现大部分的网页结构都是比较「随心所欲」的。所以在正式抓取数据前,经常要先做小规模的尝试,比如说先抓取 20 条,看看数据有没有问题。没问题后再加大规模正式抓取,这样做一定程度上可以减少返工时间。
Web Scraper 抓取表格数据
首先我们分析一下,网页里的经典表格是怎么构成的。
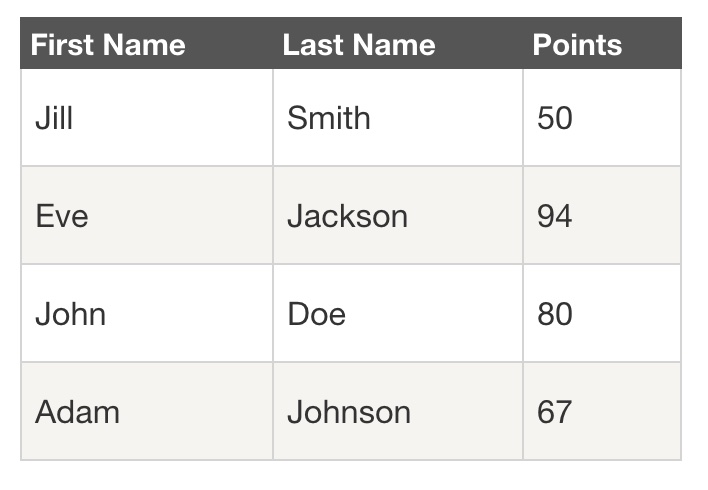
First Name所在的行比较特殊,是一个表格的表头,表示信息分类- 2-5 行是表格的主体,展示分类内容
经典表格就这些知识点,没了。下面我们写个简单的表格 Web Scraper 爬虫。
1.制作 Sitemap
我们今天的练手网站是
http://www.huochepiao.com/search/chaxun/result.asp?txtChuFa=%C9%CF%BA%A3&txtDaoDa=%B1%B1%BE%A9
爬虫的内容是抓取上海到北京的所有列车时刻表。
我们先创建一个包含整个表格的 container,Type 类型选为 Table,表示我们要抓取表格。

具体的参数如上图所示,因为比较简单,就不多说了。
在这个面板下向下翻,会发现多了一个不一样的面板。观察一下你就会发现,这些数据其实就是表格数据类型的分类,在这个案例里,他把车次、出发站、开车时间等分类都列了出来。

在 Table columns 这个分类里,每一行的内容旁边的选择按钮默认都是打勾的,也就是说默认都会抓取这些列的内容。如果你不想抓取某类内容,去掉对应的勾选就可以了。
在你点击 Save selector 的按钮时,会发现 Result key 的一些选项报错,说什么 invalid format 格式无效:

解决这个报错很简单,一般来说是 Result key 名字的长度不够,你给加个空格加个标点符号就行。如果还报错,就试试换成英文名字:

解决报错保存成功后,我们就可以按照 Web Scraper 的爬取套路抓取数据了。
2.为什么我不建议你用 Web Scraper 的 Table Selector?
如果你按照刚刚的教程做下里,就会感觉很顺利,但是查看数据时就会傻眼了。
刚开始抓取时,我们先用 Data preview 预览一下数据,会发现数据很完美:
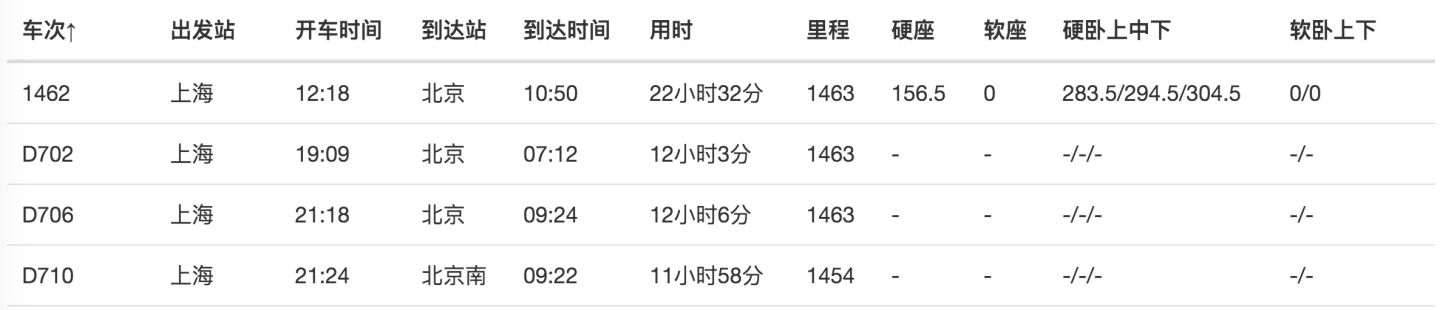
抓取数据后,在浏览器的预览面板预览,会发现车次这一列数据为 null,意味着没有抓取到相关内容:
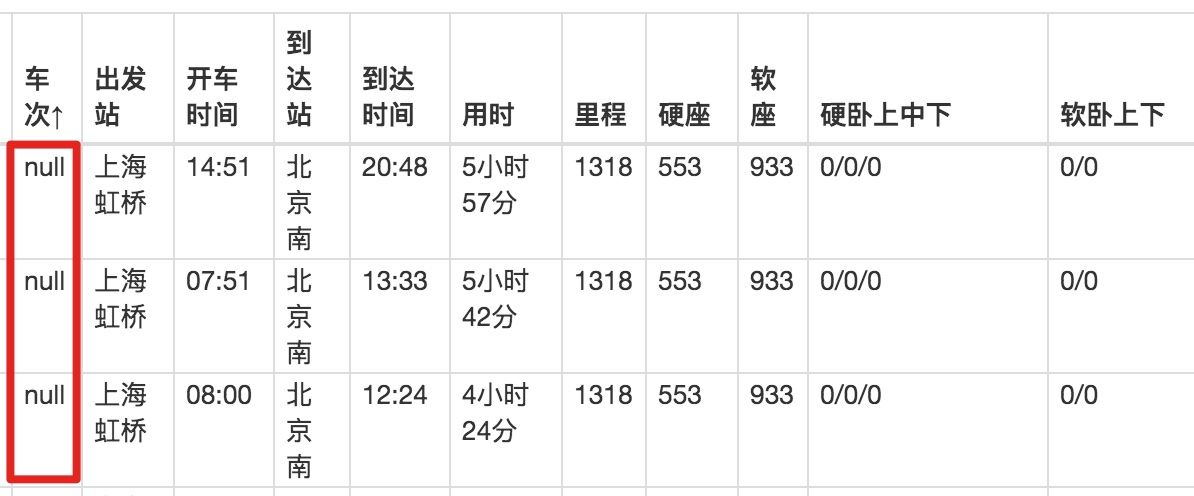
我们下载抓取的 CSV 文件后,在预览器里打开,会发现车次的数据出现了,但出发站的数据又为 null 了!

这不是坑爹呢!
关于这个问题我调查了半天,应该是 Web Scraper 对中文关键字索引的支持不太友好,所以会抛出一些诡异的 bug,因此我并不建议大家用它的 Table 功能。
如果真的想抓取表格数据,我们可以用之前的方案,先创建一个类型为 Element 的 container,然后在 container 里再手动创建子选择器,这样就可以规避这个问题。
上面只是一个原因,还有一个原因是,在现代网站,很少有人用 HTML 原始表格了。
HTML 提供了表格的基础标签,比如说 <table>、 <thead>、 <tbody> 等标签,这些标签上提供了默认的样式。好处是在互联网刚刚发展起来时,可以提供开箱即用的表格;缺点是样式太单一,不太好定制,后来很多网站用其它标签模拟表格,就像 PPT里用各种大小方块组合出一个表格一样,方便定制:
出于这个原因,当你在用 Table Selector 匹配一个表格时,可能会死活匹配不上,因为从 Web Scraper 的角度考虑,你看到的那个表格就是个高仿,根本不是原装正品,自然是不认的。
3.总结
我们并不建议直接使用 Web Scraper 的 Table Selector,因为对中文支持不太友好,也不太好匹配现代网页。如果有抓取表格的需求,可以用之前的创建父子选择器的方法来做。
Web Scraper 翻页——抓取分页器翻页的网页
本来想解释一下啥叫分页器,翻了一堆定义觉得很繁琐,大家也不是第一年上网了,看张图就知道了。我找了个功能最全的例子,支持数字页码调整,上一页下一页和指定页数跳转。

今天我们就学学,Web Scraper 怎么对付这种类型的网页翻页。
其实我们在本教程的第一个例子,抓取豆瓣电影 TOP 排行榜中,豆瓣的这个电影榜单就是用分页器分割数据的:

但当时我们是找网页链接规律抓取的,没有利用分页器去抓取。因为当一个网页的链接变化规律时,控制链接参数抓取是实现成本最低的;如果这个网页进可以翻页,但是链接的变化不是规律的,就得去会一会这个分页器了。
说这些理论有些枯燥,我们举个翻页链接不规律的例子。
8 月 2 日是蔡徐坤的生日,为了表达庆祝,在微博上粉丝们给坤坤刷了 300W 的转发量,微博的转发数据正好是用分页器分割的,我们就分析一下微博的转发信息页面,看看这类数据怎么用 Web Scraper 抓取。

这条微博的直达链接是:
https://weibo.com/1776448504/I0gyT8aeQ?type=repost
看了他那么多的视频,为了表达感激,我们可以点进去出为坤坤加一份阅读量。
首先我们看看第 1 页转发的链接,长这个样子:
第 2 页长这个样子,注意到多了个 #_rnd1568563840036 参数:
https://weibo.com/1776448504/I0gyT8aeQ?type=repost#_rnd1568563840036
第 3 页参数为 #_rnd1568563861839
https://weibo.com/1776448504/I0gyT8aeQ?type=repost#_rnd1568563861839
第 4 页参数为 #_rnd1568563882276:
https://weibo.com/1776448504/I0gyT8aeQ?type=repost#_rnd1568563882276
多看几个链接你就可以发现,这个转发网页的网址毫无规律可言,所以只能通过分页器去翻页加载数据。下面就开始我们的实战教学环节。
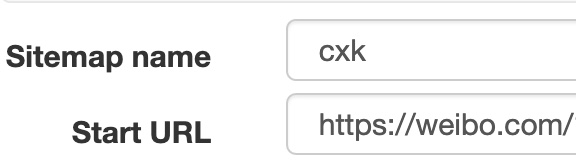
1.创建 SiteMap
我们首先创建一个 SiteMap,这次取名为 cxk,起始链接为 https://weibo.com/1776448504/I0gyT8aeQ?type=repost。
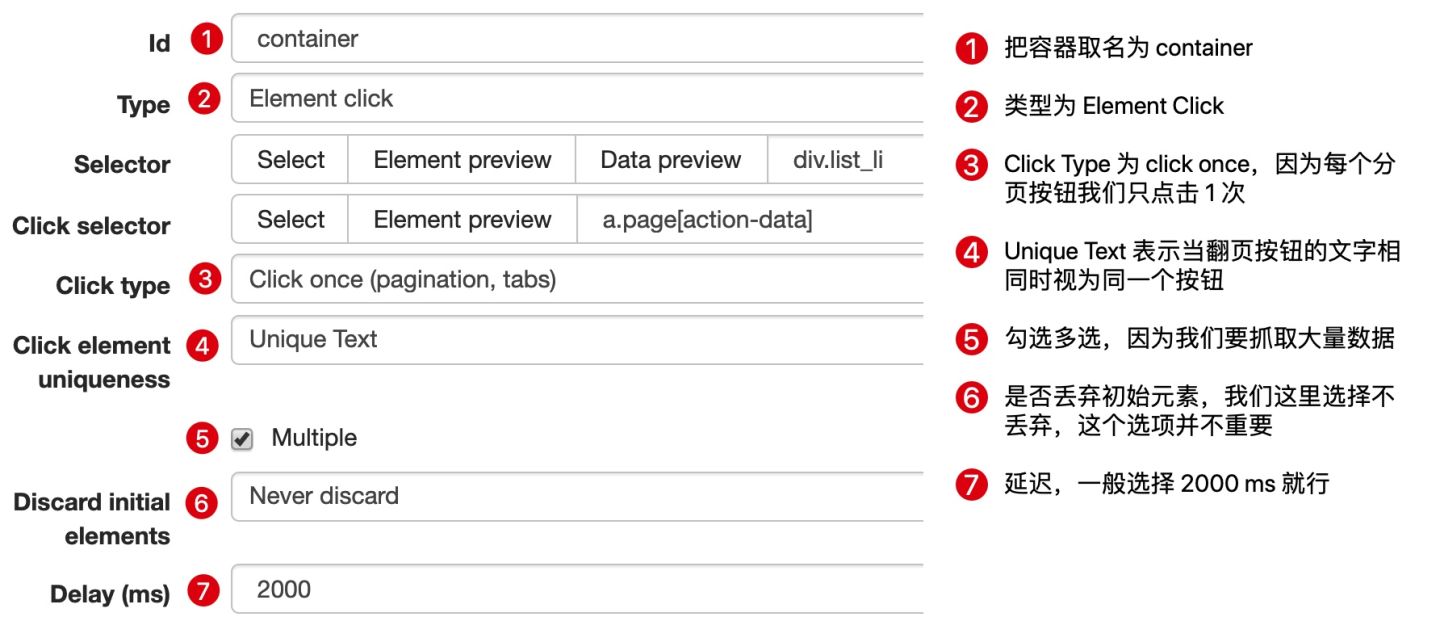
2.创建容器的 selector
因为我们要点击分页器,外面的容器的类型我们选为 Element Click,具体的参数解释可以看下图,我们之前在简易数据分析 08详细解释过一次,这里就不多言了。
container 的预览是下图的样子:

分页器选择的过程可以参看下图:

3.创建子选择器
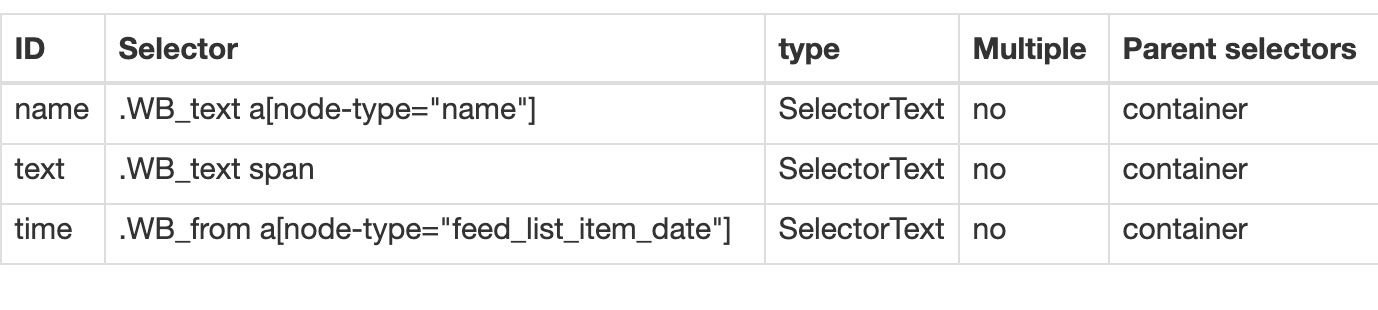
这几个子选择器都比较简单,类型都是文字选择器,我们选择了评论用户名,评论内容和评论时间三种类型的内容。
4.抓取数据
按照 Sitemap cxk -> Scrape 的操作路径就可以抓取数据了。
5.一些问题
如果你看了我上面的教程立马去爬数据,可能遇到的第一个问题就是,300w 的数据,难道我全部爬下来吗?
听上去也不太现实,毕竟 Web Scraper 针对的数据量都是相对比较小的,几万数据都算多的了,数据再大你就得考虑爬取时间是否太长,数据如何存储,如何应对网址的反爬虫系统(比如说冷不丁的跳出一个验证码,这个 Web Scraper 是无能为力的)。
考虑到这个问题,前面的自动控制抓取数量的教程你又看过的话,可能想着用 :nth-of-type(-n+N) 控制抓取 N 条数据。如果你尝试了,就会发现这个方法根本没用。
失效的原因其实涉及到一点点网页的知识了,感兴趣的话可以看看下面的解释,不感兴趣可以直接看最后的结论。
像我前面介绍的点击更多加载型网页和下拉加载型网页,他们新加载的数据,是在当前页面追加的,你一直下拉,数据一直加载,同时网页的滚动条会越来越短,这意味着所有的数据都在同一个页面。
当我们用 :nth-of-type(-n+N) 控制加载数量时,其实相当于在这个网页设立一个计数器,当数据一直累加到我们想要的数量时,就会停止抓取。
但是对于使用翻页器的网页,每次的翻页相当于刷新当前网页,这样每次都会设立一个计数器。
比如说你想抓取 1000 条数据,但是第 1 页网页只有 20 条数据,抓到最后一条了,还差 980 条;然后一翻页,又设立一个新的计数器,抓完第 2 页的最后一条数据,还差 980,一翻页计数器就重置,又变成 1000 了……所以这个控制数量的方法就失效了。
所以结论就是,如果翻页器类型的网页想提前结束抓取,只有断网的这种方法。当然,如果你有更好的方案,可以在评论里回复我,我们可以互相讨论一下。
6.总结
分页器是一种很常见的网页分页方法,我们可以通过 Web Scraper 中的 Element click 处理这种类型的网页,并通过断网的方法结束抓取。
Web Scraper 高级用法——抓取二级页面
在前面的课程里,我们抓取的数据都是在同一个层级下的内容,探讨的问题主要是如何应对市面上的各种分页类型,但对于详情页内容数据如何抓取,却一直没有介绍。
比如说我们想抓取 b 站的动画区 TOP 排行榜的数据:
https://www.bilibili.com/ranking/all/1/0/3www.bilibili.com
按之前的抓取逻辑,我们是把这个榜单上和作品有关的数据抓取一遍,比如说下图里的排名、作品名字、播放量、弹幕数和作者名。
经常逛 B 站的小伙伴也知道,UP 主经常暗示观看视频小伙伴三连操作(点赞+投币+收藏),由此可见,这 3 个数据对视频的排名有一定的影响力,所以这些数据对我们来说也有一定的参考价值。
但遗憾的是,在这个排名列表里,并没有相关数据。这几个数据在视频详情页里,需要我们点击链接进去才能看到: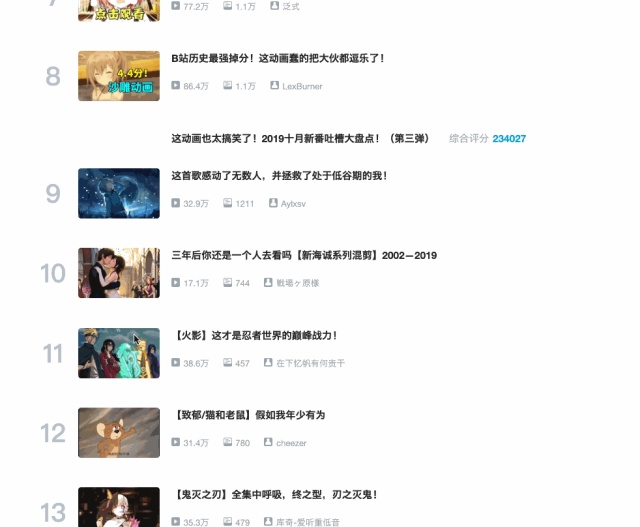
今天的教程内容,就是教你如何利用 Web Scraper,在抓取一级页面(列表页)的同时,抓取二级页面(详情页)的内容。
1.创建 SiteMap
首先我们找到要抓取的数据的位置,关键路径我都在下图的红框里标出来了,大家可以对照一下: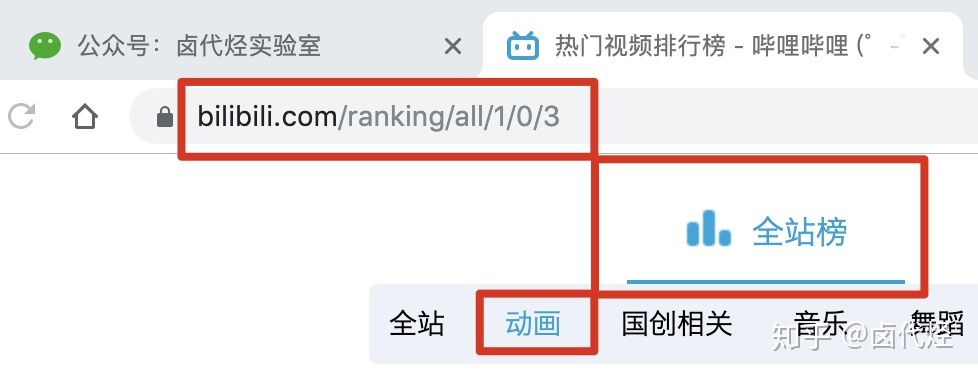
然后创建一个相关的 SiteMap,这里我取了个 bilibili_rank 的名字: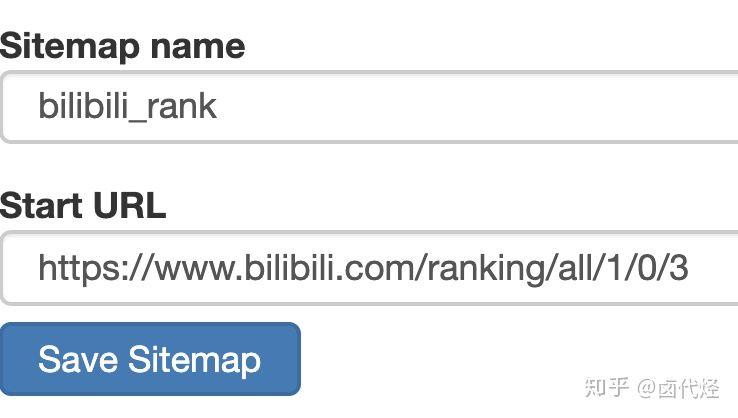
2.创建容器的 selector
设置之前我们先观察一下,发现这个网页的排行榜数据是 100 条数据一次性加载完的,没有分页的必要,所以这里的 Type 类型选为 Element 就行。
其他的参数都比较简单,就不细说了(不太懂的可以看我之前的基础教程)这里截个图大家可以做个参考: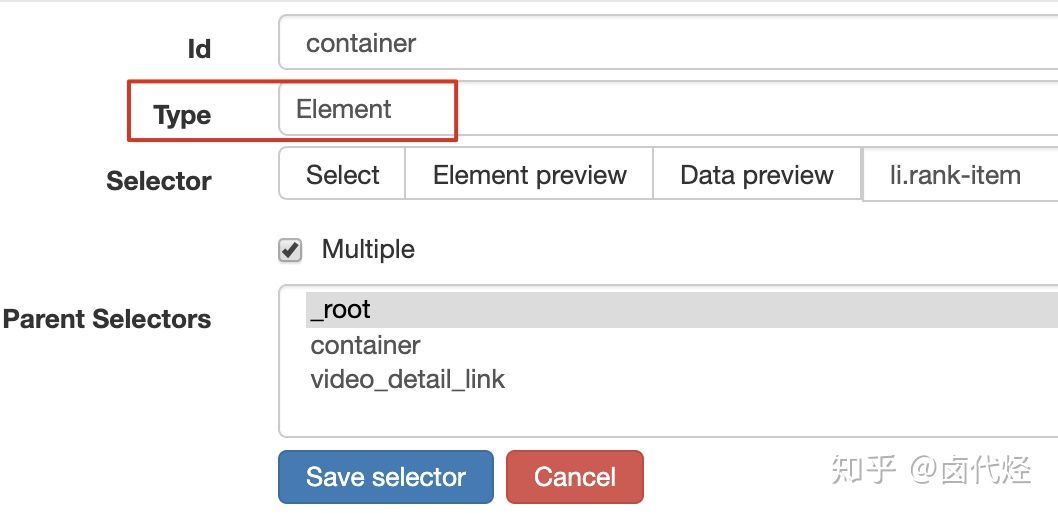
3.创建列表页子选择器
这次子选择器要抓取的内容如下,也都比较简单,截个图大家可以参考一下:
- 排名(num)
- 作品标题(title)
- 播放量(play_amount)
- 弹幕量(danmu_count)
- 作者:(author)


如果做到这一步,其实已经可以抓到所有已知的列表数据了,但本文的重点是:如何抓取二级页面(详情页)的三连数据?
跟着做了这么多爬虫,可能你已经发现了,Web Scraper 本质是模拟人类的操作以达到抓取数据的目的。
那么我们正常查看二级页面(详情页)是怎么操作的呢?其实就是点击标题链接跳转:
Web Scraper 为我们提供了点击链接跳转的功能,那就是 Type 为 Link 的选择器。
感觉有些抽象?我们对照例子来理解一下。
首先在这个案例里,我们获取了标题的文字,这时的选择器类型为 Text:
当我们要抓取链接时,就要再创建一个选择器,选的元素是一样的,但是 Type 类型为 Link:
创建成功后,我们点击这个 Link 类型的选择器,进入他的内部,再创建相关的选择器,下面我录了个动图,注意看我鼠标强调的导航路由部分,可以很清晰的看出这几个选择器的层级关系: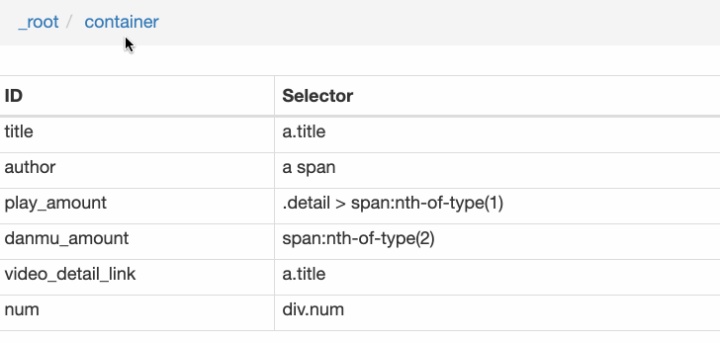
4.创建详情页子选择器
当你点击链接后就会发现,浏览器会在一个新的 Tab 页打开详情页,但是 Web Scraper 的选择窗口开在列表页,无法跨页面选择想要的数据。
处理这个问题也很简单,你可以复制详情页的链接,拷贝到列表页所在的 Tab 页里,然后回车重新加载,这样就可以在当前页面选择了。
我们在类型为 Link 的选择器内部多创建几个选择器,这里我选择了点赞数、硬币数、收藏数和分享数 4 个数据,这个操作也很简单,这里我就不详细说了。
所有选择器的结构图如下: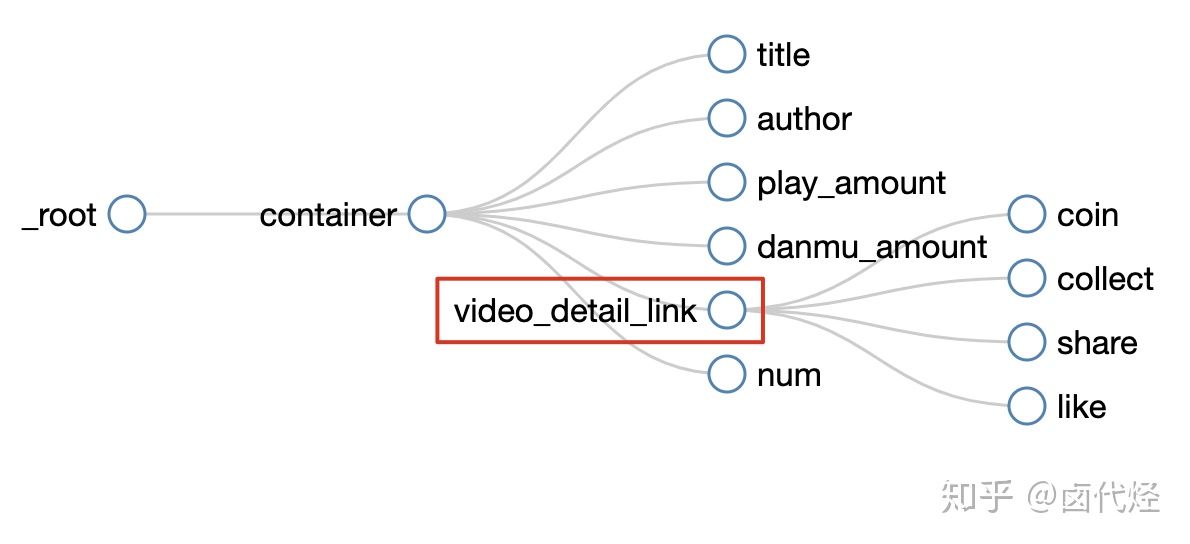
我们可以看到 video_detail_link 这个节点包含 4 个二级页面(详情页)的数据,到此为止,我们的子选择器已经全部建立好了。
5.抓取数据
终于到了激动人心的环节了,我们要开始抓取数据了。但是抓取前我们要把等待时间调整得大一些,默认时间是 2000 ms,我这里改成了 5000 ms。
为什么这么做?看了下图你就明白了: 首先,每次打开二级页面,都是一个全新的页面,这时候浏览器加载网页需要花费时间;>
首先,每次打开二级页面,都是一个全新的页面,这时候浏览器加载网页需要花费时间;>
其次,我们可以观察一下要抓取的点赞量等数据,页面刚刚加载的时候,它的值是 「—」,等待一会儿后才会变成数字。>
所以,我们直接等待 5000 ms,> 等页面和数据加载完成后,再统一抓取。
配置好参数后,我们就可以正式抓取并下载了。下图是我抓取数据的一部分,特此证明此方法有用: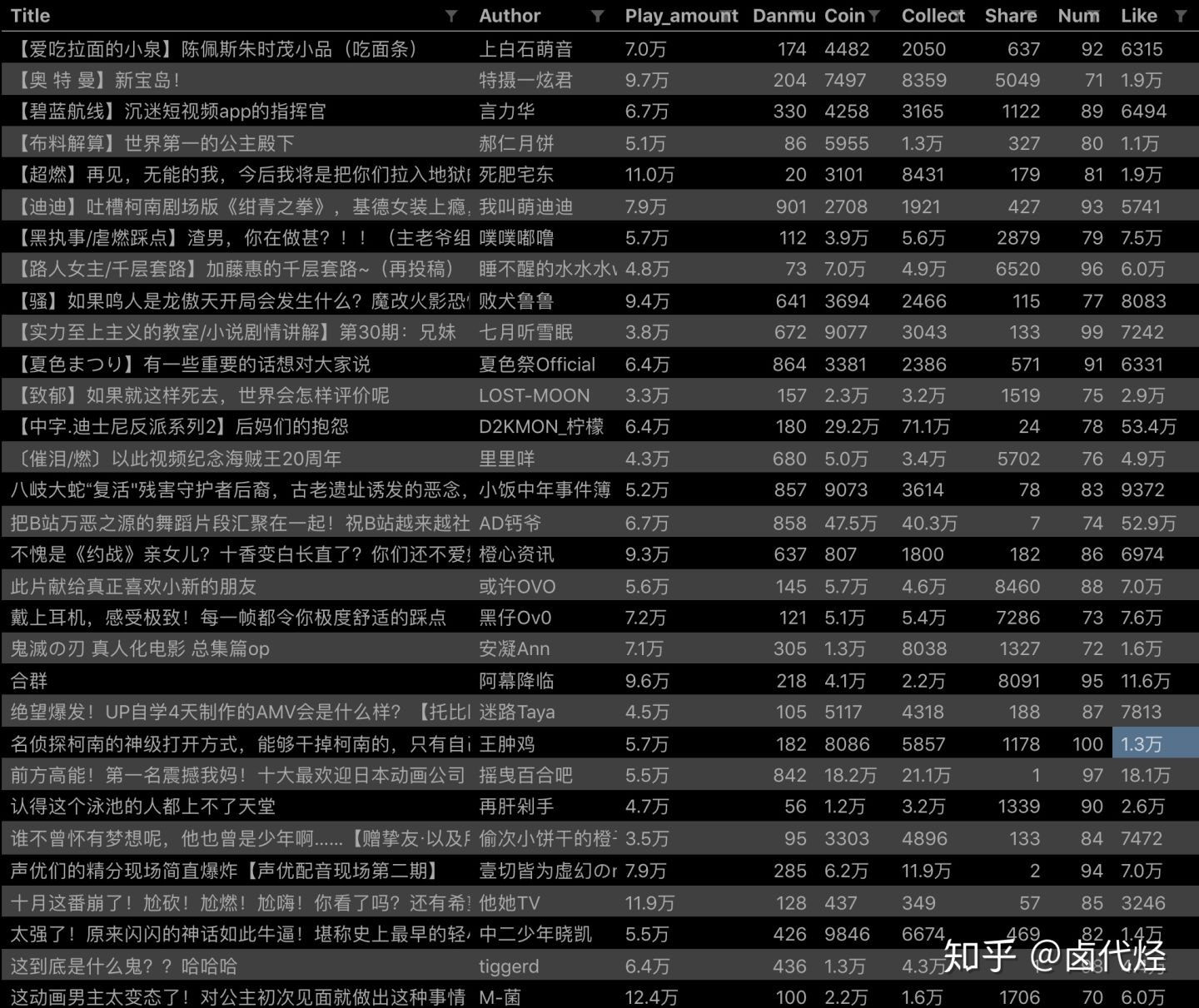
6.总结
这次的教程可能有些难度,我把我的 SiteMap 分享出来,制作的时候如果遇到难题,可以参考一下我的配置,SiteMap 导入的功能我在第 6 篇教程里详细说明了,大家可以配合食用:
{"_id":"bilibili_rank","startUrl":["https://www.bilibili.com/ranking/all/1/0/3"],"selectors":[{"id":"container","type":"SelectorElement","parentSelectors":["_root"],"selector":"li.rank-item","multiple":true,"delay":0},{"id":"title","type":"SelectorText","parentSelectors":["container"],"selector":"a.title","multiple":false,"regex":"","delay":0},{"id":"author","type":"SelectorText","parentSelectors":["container"],"selector":"a span","multiple":false,"regex":"","delay":0},{"id":"play_amount","type":"SelectorText","parentSelectors":["container"],"selector":".detail > span:nth-of-type(1)","multiple":false,"regex":"","delay":0},{"id":"danmu_amount","type":"SelectorText","parentSelectors":["container"],"selector":"span:nth-of-type(2)","multiple":false,"regex":"","delay":0},{"id":"video_detail_link","type":"SelectorLink","parentSelectors":["container"],"selector":"a.title","multiple":false,"delay":0},{"id":"coin","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.coin","multiple":false,"regex":"","delay":0},{"id":"collect","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.collect","multiple":false,"regex":"","delay":0},{"id":"share","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":"span.share","multiple":false,"regex":"[0-9]+","delay":0},{"id":"num","type":"SelectorText","parentSelectors":["container"],"selector":"div.num","multiple":false,"regex":"","delay":0},{"id":"like","type":"SelectorText","parentSelectors":["video_detail_link"],"selector":".ops span.like","multiple":false,"regex":"","delay":0}]}
当你掌握了二级页面的抓取方式后,三级页面、四级页面也不在话下。因为套路都是一样的:都是在 Link 选择器指向的下一个页面抓取数据,因为原理是一样的,我就不演示了。
Web Scraper 翻页——利用 Link 选择器翻页
这次的更新是受一位读者启发的,他当时想用 Web scraper 爬取一个分页器分页的网页,却发现我之前介绍的分页器翻页方法不管用。我研究了一下才发现我漏讲了一种很常见的翻页场景。
在 web scraper 翻页——分页器翻页的文章里,我们讲了如何利用 Element Click 选择器模拟鼠标点击分页器进行翻页,但是把同样的方法放在豆瓣 TOP 250 上,翻页到第二页时抓取窗口就会自动退出,一条数据都抓不到。
其实主要原因是我没有讲清楚这种方法的适用边界。
通过 Element Click 点击分页器翻页,只适用于网页没有刷新的情况,我在分页器那篇文章里举了蔡徐坤微博评论的例子,翻页时网页是没有刷新的:
仔细看下图,链接发生了变化,但是刷新按钮并没有变化,说明网页并没有刷新,只是内容变了

而在 豆瓣 TOP 250 的网页里,每次翻页都会重新加载网页:
仔细看下图,链接发生变化的同时网页刷新了,有很明显的 loading 转圈动画

其实这个原理从技术规范上很好解释:当一个 URL 链接是 # 字符后数据变化时,网页不会刷新;当链接其他部分变化时,网页会刷新。当然这个只是随口提一下,感兴趣的同学可以去这个链接研究一下,不感兴趣可以直接跳过。
1.创建 Sitemap
本篇文章就来讲解一下,如何利用 Web Scraper 抓取翻页时会刷新网页的分页器网站。
这次的网页我们选用最开始练手 Web Scraper 的网站——豆瓣电影 TOP250,换个姿势练习 Web Scraper 翻页技巧。
像这种类型的网站,我们要借助 Link 选择器来辅助我们翻页。Link 标签我们在上一节介绍过了,我们可以利用这个标签跳转网页,抓取另一个网页的数据。这里我们利用 Link 标签跳转到分页网站的下一页。
首先我们用 Link 选择器选择下一页按钮,具体的配置可以见下图: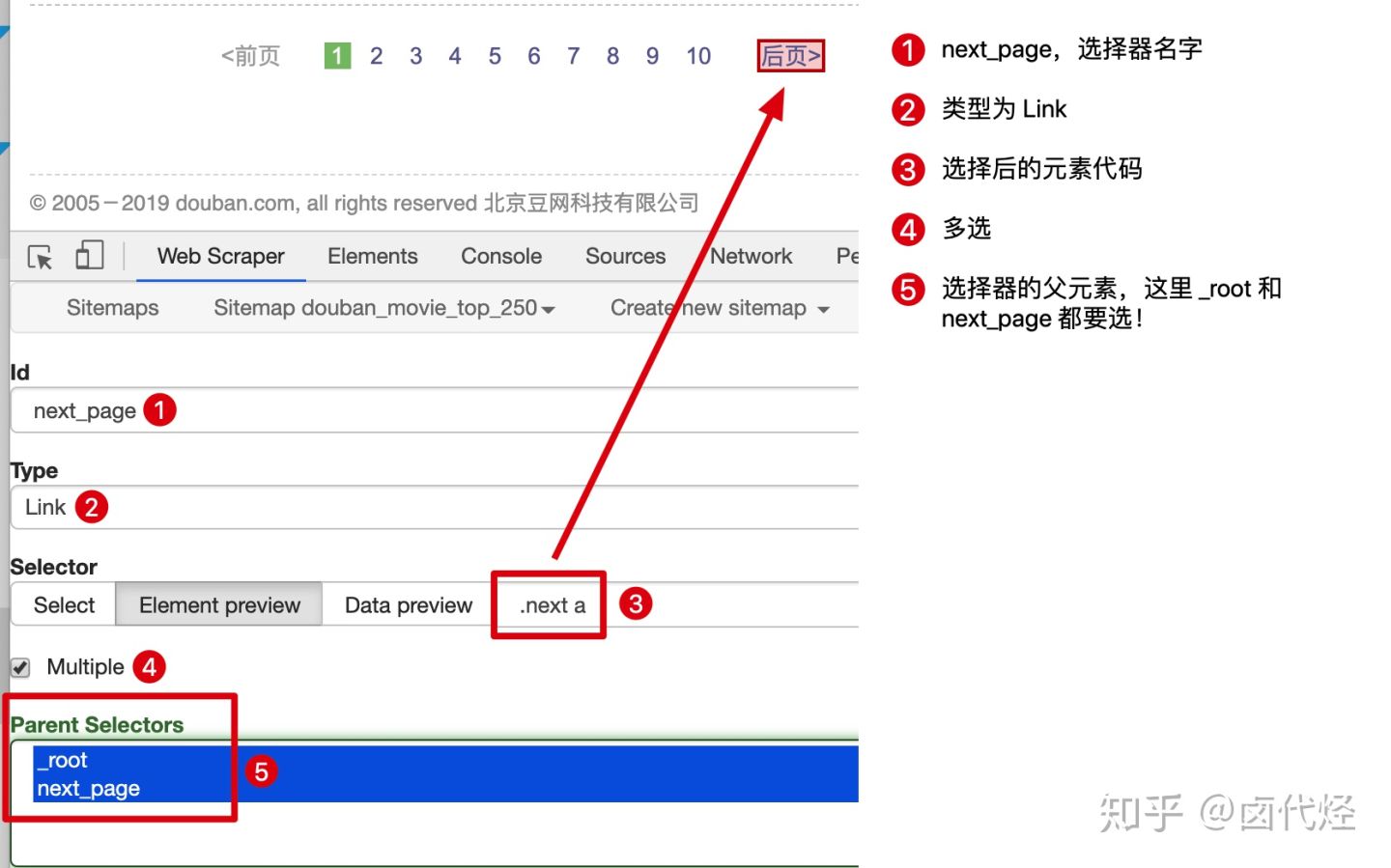
这里有一个比较特殊的地方:Parent Selectors ——父选择器。
之前我们都没有碰过这个选择框的内容,next_page 这次要有两个父节点——_root 和 next_page,键盘按 shift 再鼠标点选就可以多选了,先按我说的做,后面我会解释这样做的理由。
保存 next_page 选择器后,在它的同级下再创建 container 节点,用来抓取电影数据: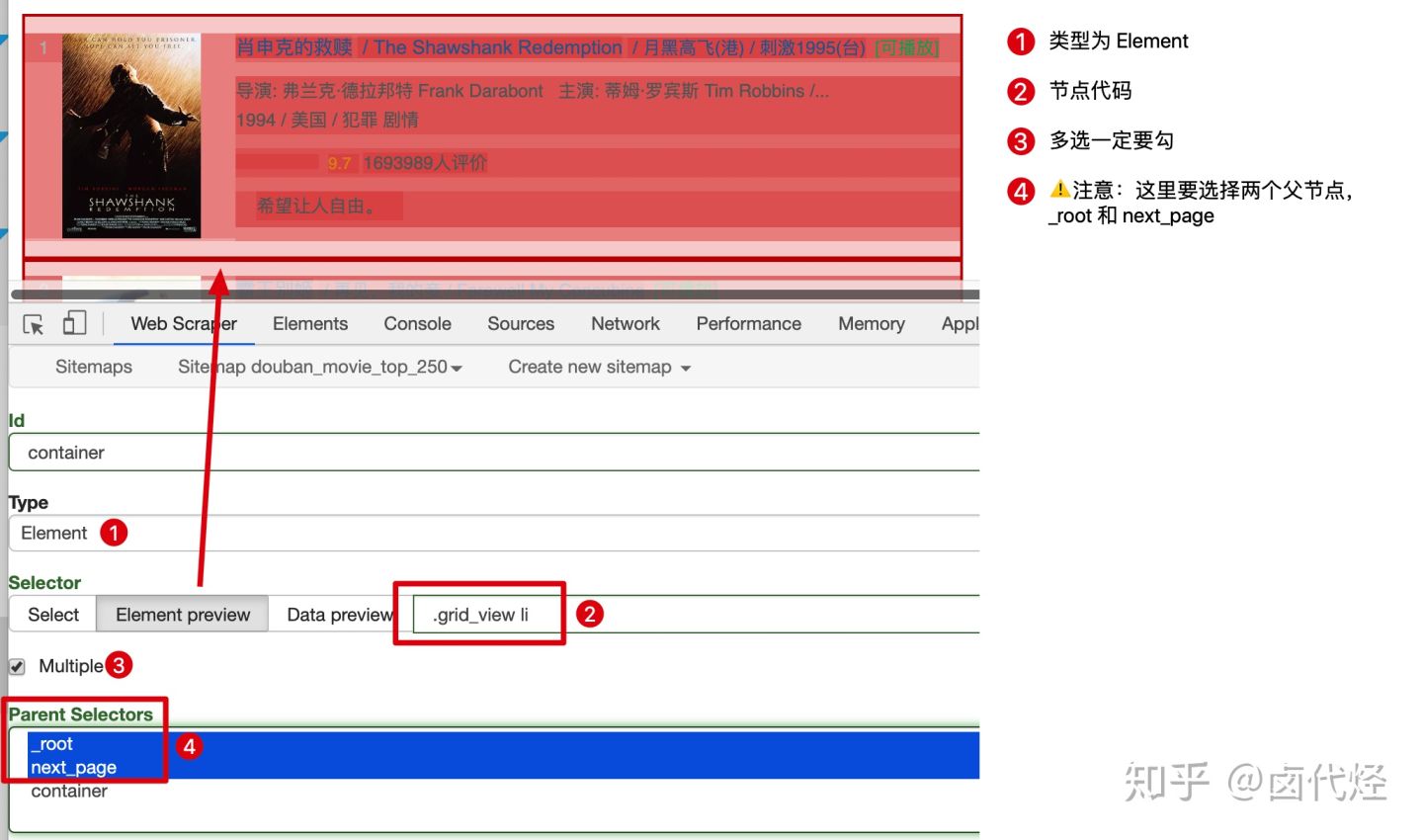
这里要注意:翻页选择器节点 next_page 和数据选择器节点 container 是同一级,两个节点的父节点都是两个:_root 和 next_page:
因为重点是 web scraper 翻页技巧,抓取的数据上我只简单的抓取标题和排名:
然后我们点击 Selector graph 查看我们编写的爬虫结构:
可以很清晰的看到这个爬虫的结构,可以无限的嵌套下去: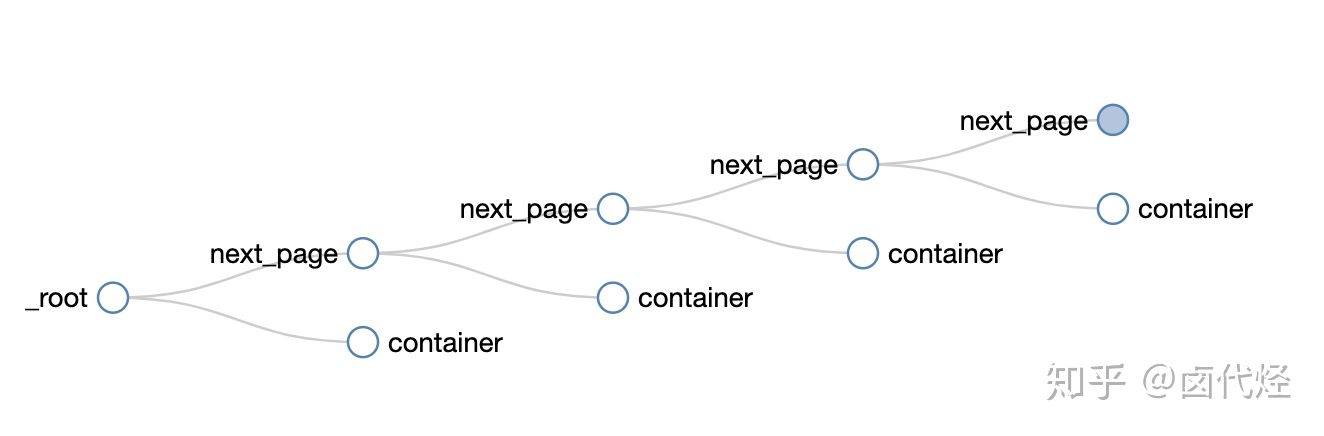
点击 Scrape,爬取一下试试,你会发现所有的数据都爬取下来了: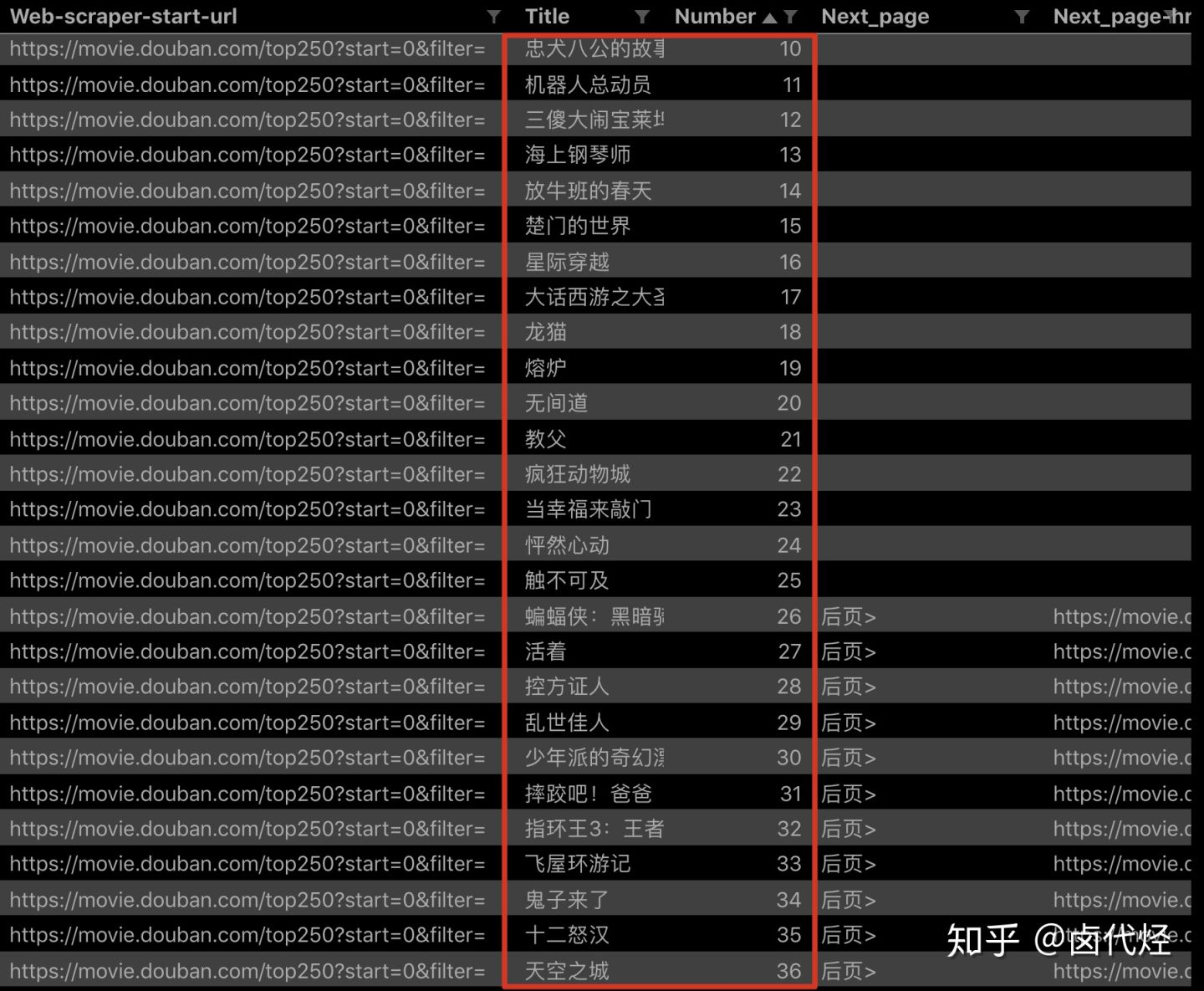
2.分析原理
按照上面的流程下来,你可能还会比较困扰,数据是抓下来了,但是为什么这样操作就可以呢,为什么 next_page 和 container 要同级,为什么他们要同时选择两个父节点:_root 和 next_page?
产生困扰的原因是因为我们是倒叙的讲法,从结果倒推步骤;下面我们从正向的思维分步讲解。
首先我们要知道,我们抓取的数据是一个树状结构,_root 表示根节点,就是我们的抓取的第一个网页,我们在这个网页要选择什么东西呢?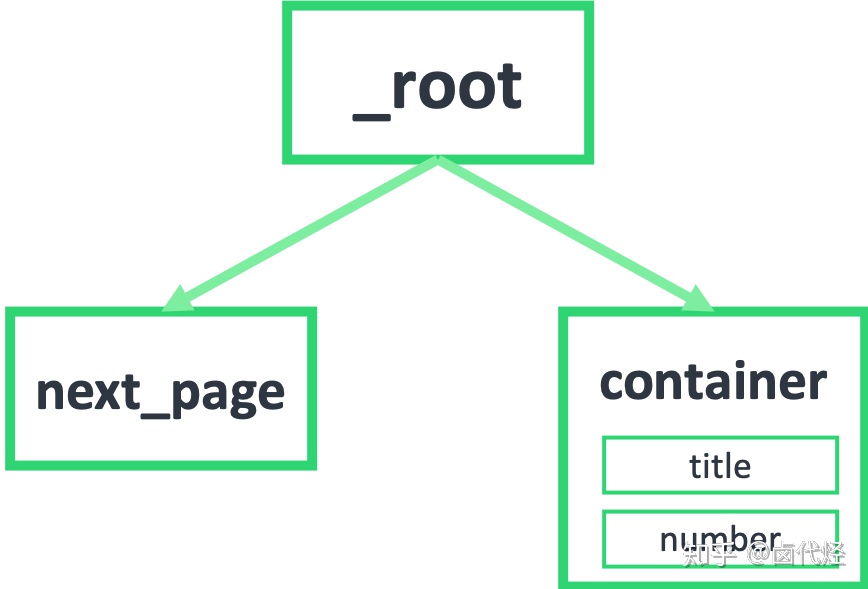
1.一个是下一页的节点,在这个例子里就是用 Link 选择器选择的 next_page
2.一个是数据节点,在这个例子里就是用 Element 选择器选择的 container
因为 next_page 节点是会跳转的,会跳到第二页。第二页除了数据不一样,结构和第一页还是一样的,为了持续跳转,我们还要选择下一页,为了抓取数据,还得选择数据节点: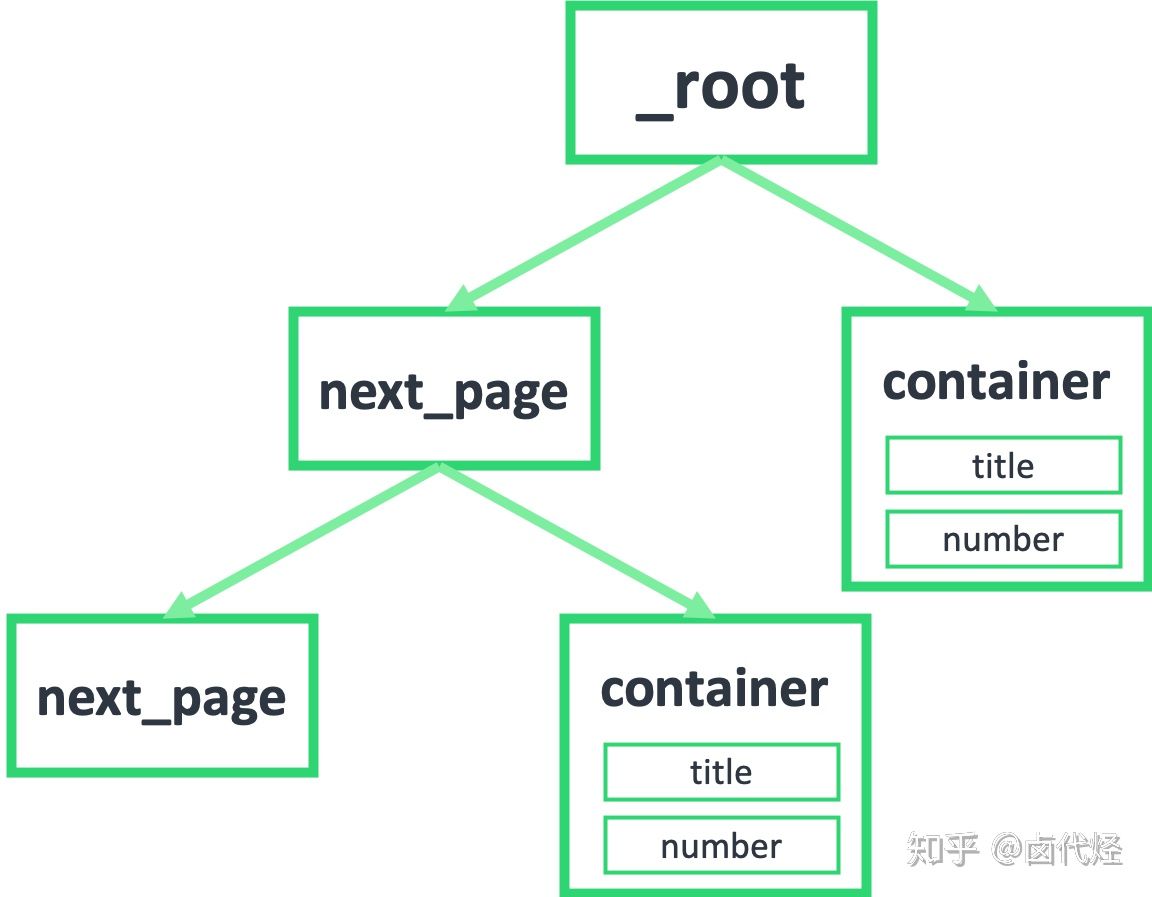
如果我们把箭头反转一下,就会发现真相就在眼前,next_page 的父节点,不正好就是 _root 和 next_page 吗?container 的父节点,也是 _root 和 next_page!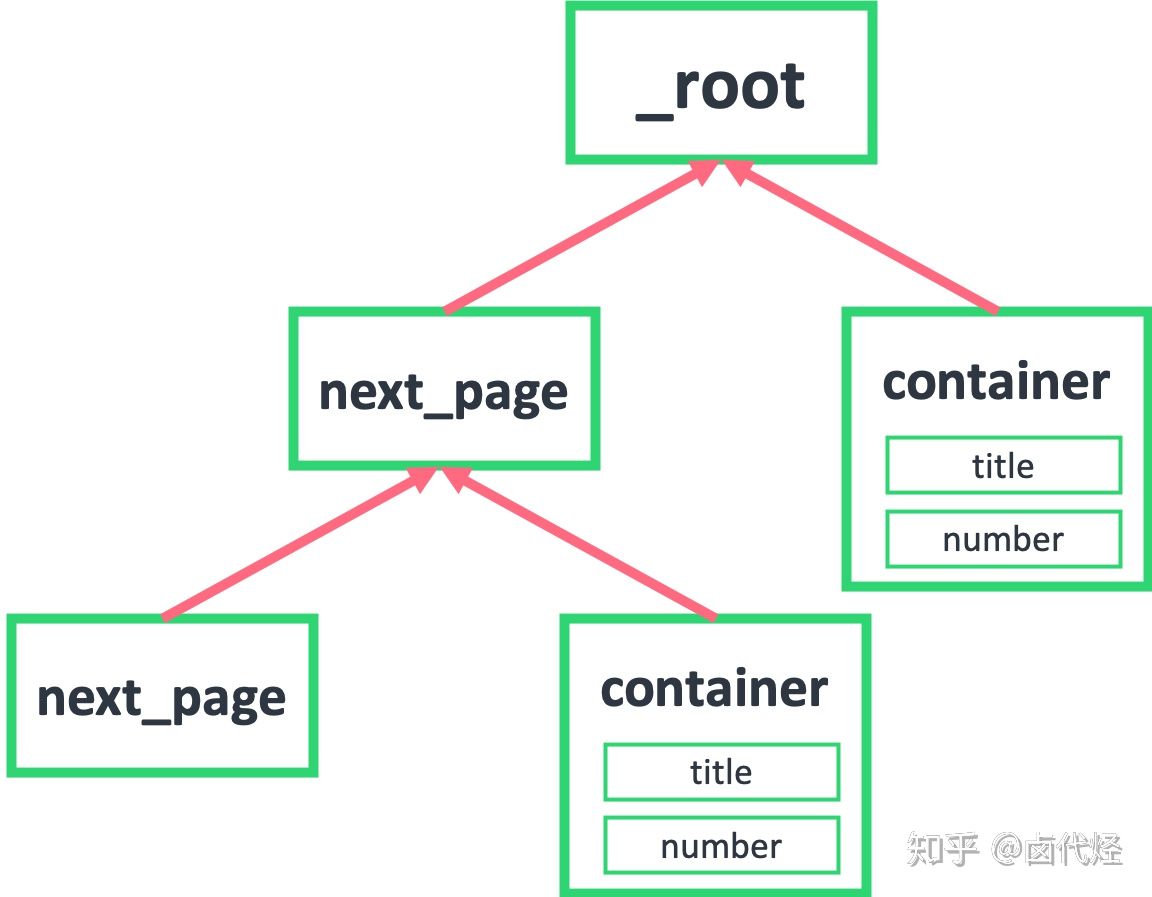
到这里基本就真相大白了,不理解的同学可以再多看几遍。像 next_page 这种我调用我自己的形式,在编程里有个术语——递归,在计算机领域里也算一种比较抽象的概念,感兴趣的同学可以自行搜索了解一下。
3.sitemap 分享
下面是这次实战的 Sitemap,同学们可以导入到自己的 web scraper 中进行研究:
{"_id":"douban_movie_top_250","startUrl":["https://movie.douban.com/top250?start=0&filter="],"selectors":[{"id":"next_page","type":"SelectorLink","parentSelectors":["_root","next_page"],"selector":".next a","multiple":true,"delay":0},{"id":"container","type":"SelectorElement","parentSelectors":["_root","next_page"],"selector":".grid_view li","multiple":true,"delay":0}]}

若有收获,就点个赞吧
0 人点赞
