动机
Infographics(信息图)是”information” and “graphics”的组合单词,是对信息进行图形化的表达.信息图可以清楚地表达复杂且大量的信息,应用也非常广泛,但是制作一个信息图并不容易,这是一个很耗时的过程,并且还需要用户懂一定的设计。
要制作信息图有多个选择,可以使用专业的设计软件,也可以借助现有的一些图形化的工具,但是对于没有设计基础、且不懂软件操作的人来说,这是非常困难的。
因此本文提出了一个可以将比例相关的自然语言自动转化成信息图的方法,目标是不需要任何提前了解的技术,每个人都可以轻松的创建信息图。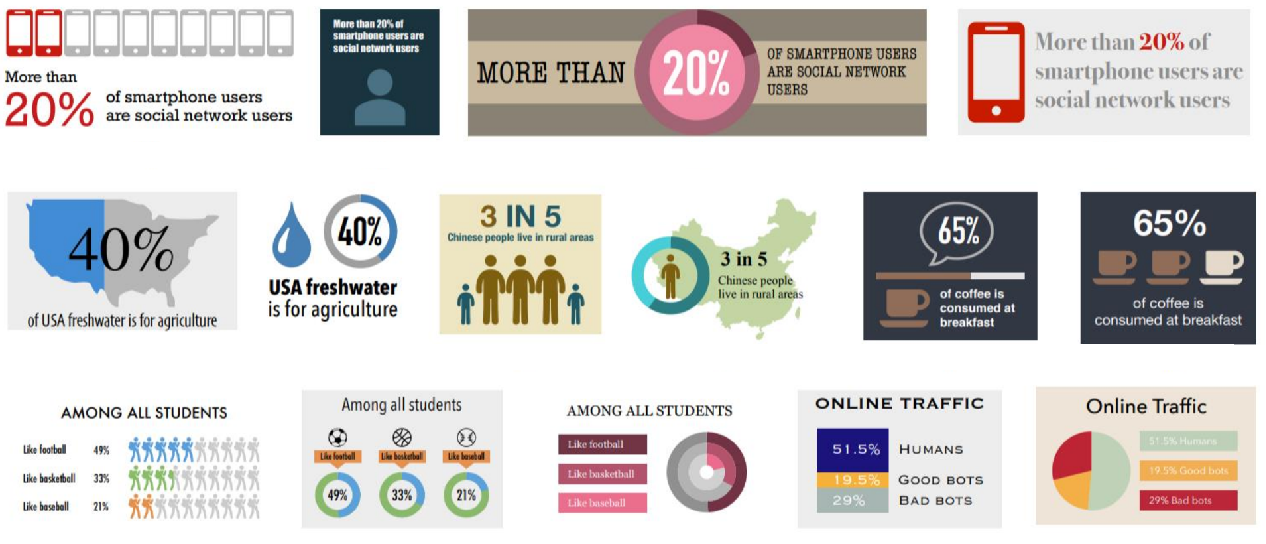
挑战
- 文本
- 如何理解输入的文本
- 如何提取出需要可视化的信息
- 可视化
- 如何把文本转化为可视化元素(图标、图表、颜色、描述…)
- 如何处理多个可视化元素的布局(空间、配色)Preliminary Survey
为了更好地理解和学习infographics在现实生活中的使用,并且要为本文的系统找到一种特定的文本类型,作者做了初步的survey。具体做法是使用“Infographic”作为搜索关键词,用谷歌图片搜索下载了200个不同的结果,并按以下三点标准将其分为983个独立的信息图单元。
- 至少传达一种信息
- 至少包含一个图形元素
- 视觉上和语义上一致且完整
基于统计结果发现,统计数据相关的占主要部分,其中,基于比例的最多,达到了45.7%。于是最终选择了基于比例的文本来作为本文系统自动可视化的输入: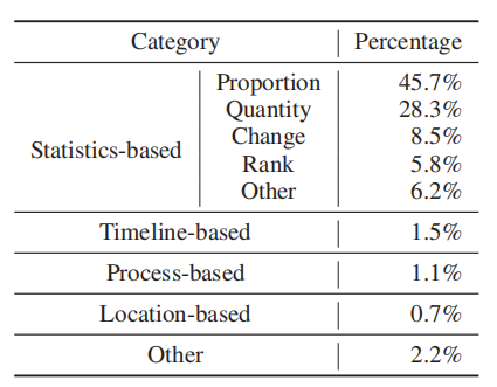
Text-to-Viz流程

文本解析
- 训练集
- 理解人们如何用日常的语言来表达比例相关的信息
- 收集了约10万份ppt,使用正则表达式匹配n%, m in n, m out of n, half of等,提取了5562句文本描述,最终采样了800句作为训练集
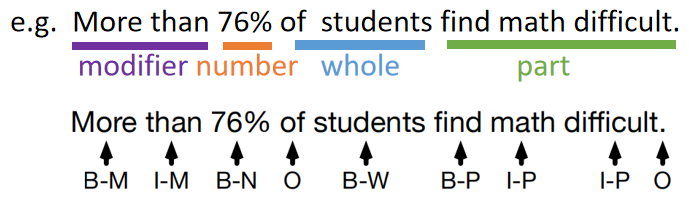
- 关键信息:Number, Whole, and Part

- 理解人们如何用日常的语言来表达比例相关的信息
- 具体步骤
- Tokenization 分词
- Featurization 特征提取
word embedding feature, syntactic feature, Brown clustering feature… -
可视化生成
为了更好的了解与比例相关的信息图,作者和两个专家进行了一个小时的讨论,这两名专家都是有四年以上设计经验。主要内容是作者展示一些信息图,然后讨论它们是如何从一个手稿或是想法生成的。最终总结出了四个维度的设计空间:

Step 1: 在每个设计维度生成一组候选
Step 2: 枚举候选的组合,获取有效的信息图
Step 3: 将上一步得到的结果进行评分排序,用户可以选择某一个信息图进行进一步的调整Layout Candidates
包含一组描述整体布局的模板
画布的长宽比例,以及区域的划分
- 每个区域所放置的元素类型
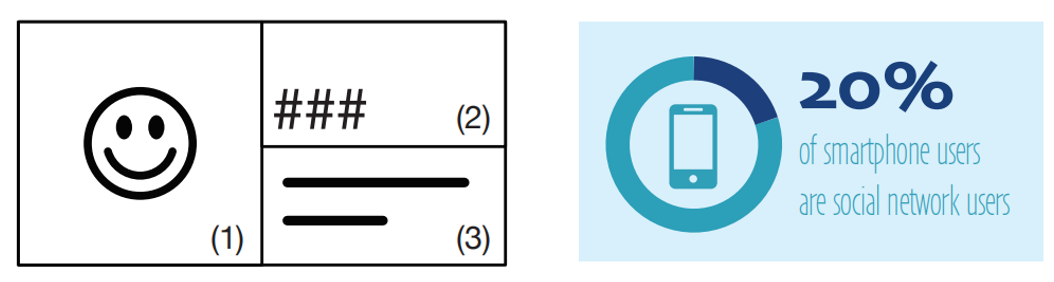
Description Candidates
从文本解析模块可以得到四个字段,为了生成更多候选的文本块,还使用了stanford Parser这个nlp工具,来提取出不同长度的描述,来满足不同的layout.
E.g. More than 20% of smartphone users are social network users.
Number: 20%, Whole: “of smartphone users”, “smartphone users”, Part: “are social network users”, Modifier: “more than”, After-number: “of smartphone users are social network users”, etc.
Graphic Candidates
- 七类高频使用的图形元素
- Pictograph, adornment, donut chart, pie chart, bar chart, filled icon, and scaled icon
图形库
视觉上和谐统一&与语义匹配
方法
对于所有的布局模板
- 找到满足布局内每个区域的要求的所有元素,生成有效的组合
- 对于每个有效的组合( layout + description + graphic + color)


- 语义分数是为了评估匹配到的图标和颜色主题的准确性,因为它们都是通过关键词匹配得到的,所以匹配结果越好,这个分数就越高。
- 信息分数是如果用户能够从信息图中轻松地看出原始信息的话,这个分数越高。在本文的系统中,由于空间的限制,可能有些内容会被省去,所以通过计算非停词在结果中出现的比例来得到信息分数:
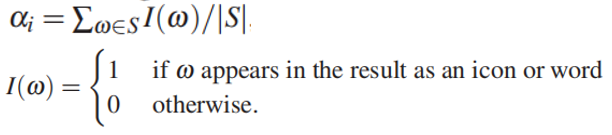
视觉分数是衡量各个元素在布局各个区域中fit得好不好,通过计算空间浪费的程度来得到:

总分数是以上三个分数的加权和 ,权重分别为0.25、0.25、0.5。
用户选择与修改
评估
失败的结果
对于稍微复杂点的输入,分词不够准确
- 有些icon的选择不太合适
- 歧义问题
- 30% of students are French, while 40% are American.
- 30% of students speak French, while 40% speak English.User Study
- Casual User Interview: 举办了两场公开的展会,总共80+用户参与,包括软件开发工程师、销售人员、项目管理员等,大多数人都没有设计经验
- 反馈都非常积极,他们很喜欢这种可以立即得到结果、不用自己设计的形式。问得最多的一个问题是可不可以支持其他类型的输入,以及比如是在一个现有的ppt模板上面使用,可不可以自动匹配一套对应的颜色方案。
- Expert Interview: 与三个有丰富设计经验的专家分别进行了1h的讨论
- 总体上都认为这个工具非常有前景。有个专家提到一点是,这个系统并不是要生成多完美的设计结果,受众是那些不懂设计的人,可能就是做些简单的展示,并不会追求最好,所以保持它的简介性最重要。总结
- 总体上都认为这个工具非常有前景。有个专家提到一点是,这个系统并不是要生成多完美的设计结果,受众是那些不懂设计的人,可能就是做些简单的展示,并不会追求最好,所以保持它的简介性最重要。总结
- 本文提出了一种把比例数据相关的文本自动转化为一组信息图的方法
- 未来工作
- 扩展到其他类型的文本
- 集成到Office这样的工具中,方便使用
- 尝试新的技术来提升生成结果的质量
原论文

若有收获,就点个赞吧
0 人点赞
