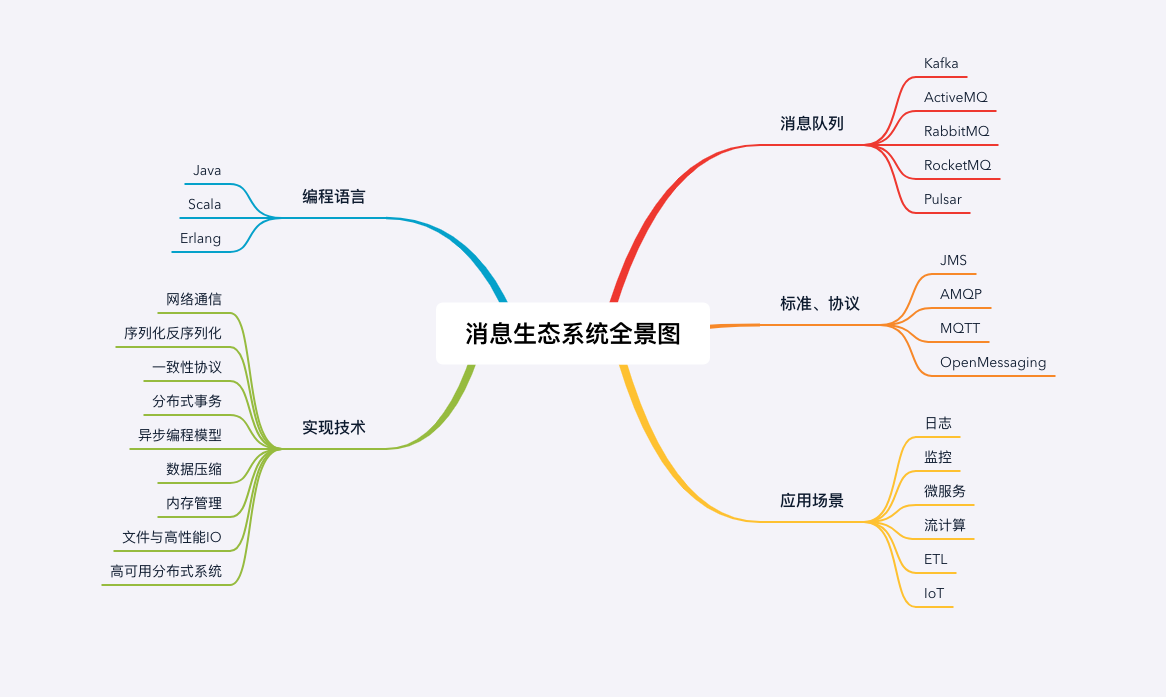

1. 消息队列应用场景
1.1异步处理
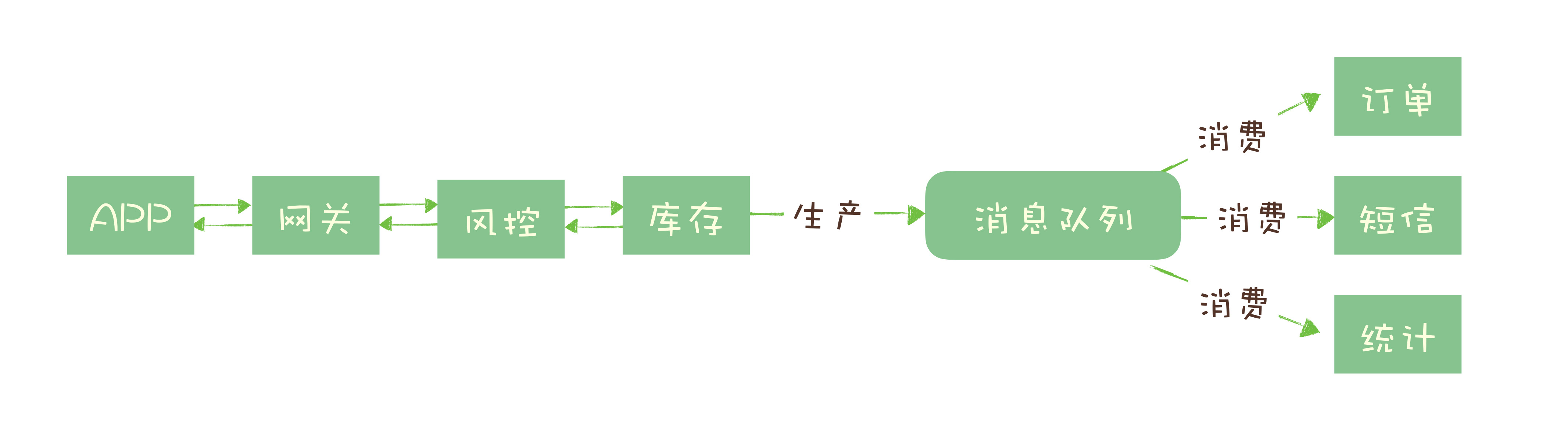
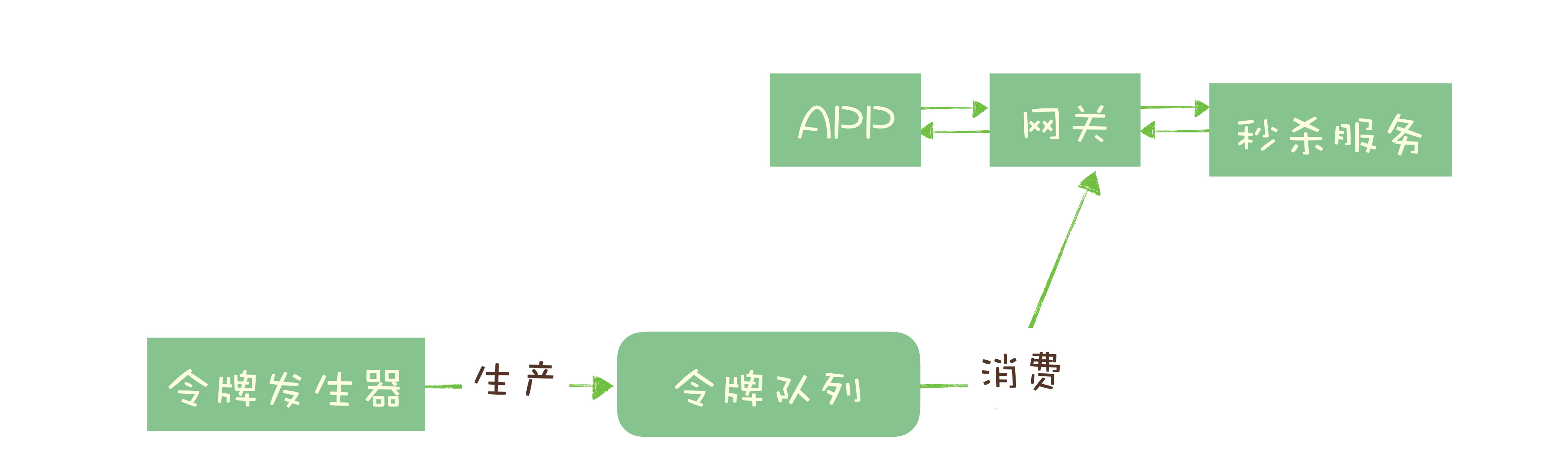
1.2流量削峰
1.3 服务解耦
我们知道订单是电商系统中比较核心的数据,当一个新订单创建时:
支付系统需要发起支付流程;
风控系统需要审核订单的合法性;
客服系统需要给用户发短信告知用户;
经营分析系统需要更新统计数据;
……
这些订单下游的系统都需要实时获得订单数据。随着业务不断发展,这些订单下游系统不断的增加,不断变化,并且每个系统可能只需要订单数据的一个子集,负责订单服务的开发团队不得不花费很大的精力,应对不断增加变化的下游系统,不停地修改调试订单系统与这些下游系统的接口。任何一个下游系统接口变更,都需要订单模块重新进行一次上线,对于一个电商的核心服务来说,这几乎是不可接受的。
所有的电商都选择用消息队列来解决类似的系统耦合过于紧密的问题。引入消息队列后,订单服务在订单变化时发送一条消息到消息队列的一个主题 Order 中,所有下游系统都订阅主题 Order,这样每个下游系统都可以获得一份实时完整的订单数据。
1.4 其它应用场景
- 作为发布 / 订阅系统实现一个微服务级系统间的观察者模式;
- 连接流计算任务和数据;
-
1.5 队列功能维度分类
• 优先级队列:
优先级队列不同于先进先出队列,优先级高的消息具备优先被消费的特权,这样可以为下游提供不同消息级别的保证。
应用:生产> 消费
• 延迟队列- 基于消息型:基于消息的延迟是指为每条消息设置不同的延迟时间,那么每当队列中有新消息进入的时候就会重新根据延迟时间排序(消耗性能);
- 基于列队(通用): 设置不同延迟级别的队列,比如5s、10s、30s、1min、5mins、10mins等,每个队列中消息的延迟时间都是相同的,这样免去了延迟排序所要承受的性能之苦,通过一定的扫描策略(比如定时)即可投递超时的消息。
• 死信队列
可以为每个队列设置一个回退队列,它和死信队列都是为异常的处理提供的一种机制保障。实际情况下,回退队列的角色可以由死信队列和重试队列来扮演。
• 重试队列
重试越多次重新投递的时间就越久,为此需要设置一个上限,超过投递次数就入死信队列。重试队列与延迟队列有相同的地方,都是需要设置延迟级别,它们彼此的区别是:延迟队列动作由内部触发,重试队列动作由外部消费端触发;延迟队列作用一次,而重试队列的作用范围会向后传递。
1.6 消费模式分类
消费模式分为推(push)模式和拉(pull)模式。
• 广播消费
• 消息一般有两种传递模式:点对点(P2P,Point-to-Point)模式和发布/订阅(Pub/Sub)模式
RabbitMQ是一种典型的点对点模式,而Kafka是一种典型的发布订阅模式。
RabbitMQ中可以通过设置交换器类型来实现发布订阅模式而达到广播消费的效果,Kafka中也能以点对点的形式消费,你完全可以把其消费组(consumer group)的概念看成是队列的概念。不过对比来说,Kafka中因为有了消息回溯功能的存在(基于offset),对于广播消费的力度支持比RabbitMQ的要强
• 消息回溯
• 消息堆积+持久化
消息堆积分内存式堆积和磁盘式堆积。RabbitMQ是典型的内存式堆积,但这并非绝对,在某些条件触发后会有换页动作来将内存中的消息换页到磁盘(换页动作会影响吞吐),或者直接使用惰性队列来将消息直接持久化至磁盘中。Kafka是一种典型的磁盘式堆积
2. 主流MQ介绍及对比
2.1 Rabbitmq
优点:轻量,迅捷,容易部署和使用,拥有灵活的路由配置 amqp协议,保证消息严格顺序性; 默认push模式
缺点:性能和吞吐量较差,消息堆积的支持不好,不易进行二次开发,消息不可回溯,队列模式,一对多消费支持不好;
**
2.2 Rocketmq
优点:性能好,稳定可靠,有活跃的中文社区,特点响应快,适合在线实时业务处理
缺点:兼容性较差,但随意影响力的扩大,该问题会有改善,队列有序,topic 无序;(解决方案:用一致性哈希算法,计算出队列ID,指定队列ID发送,这样可以保证相同的订单/用户的消息总被发送到同一个队列上,就可以确保严格顺序了。)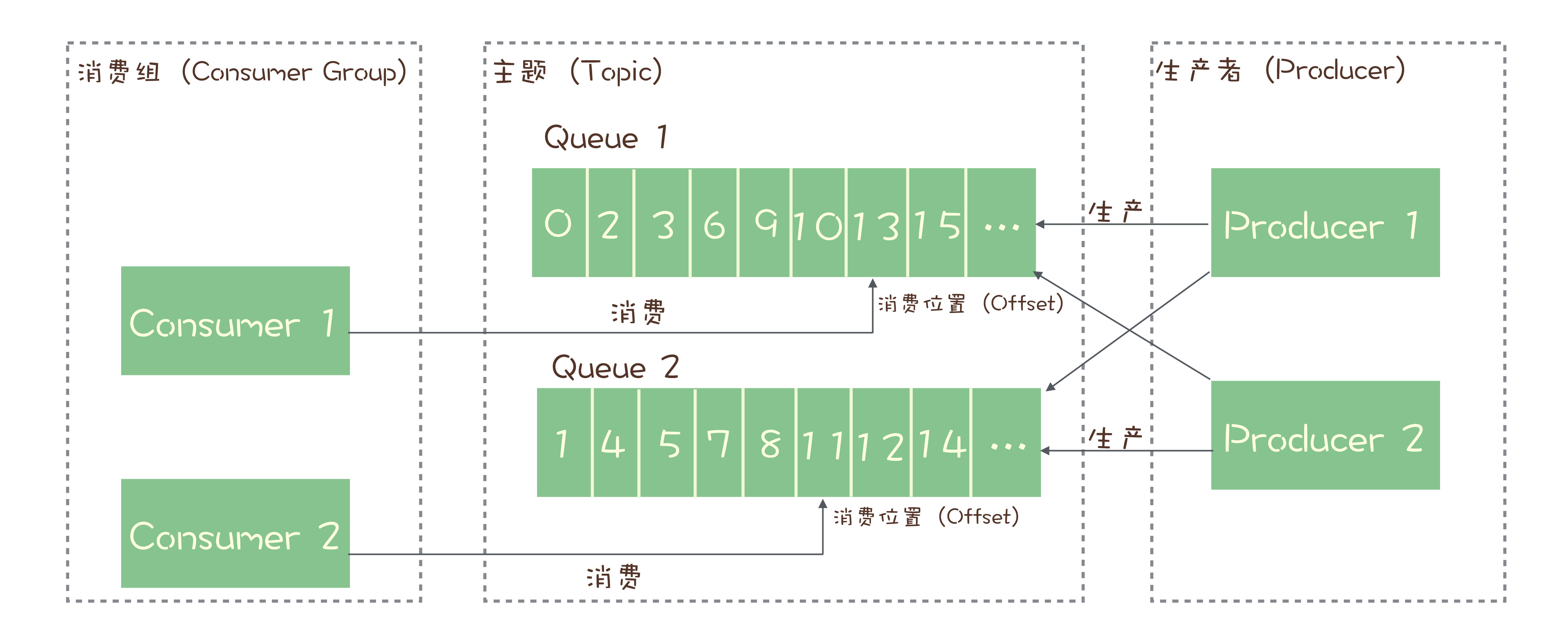
2.3 Kafka
优点:拥有强大的性能及吞吐量,兼容性很好,适合大数据、日志处理;(顺序读写,zero copy实现无内存交换, pagecahce 优化磁盘io); pull模式(基于长轮询);
缺点:由于“攒一波再处理”导致延迟比较高,可以通过配置修改批次数量;
2.4 Pulsar:
采用存储和计算分离的设计,是消息队里产品中黑马,值得持续关注
3. MQ 常见问题
3.1 消息队列事务一致性
3.2 如何确保消息不会丢失?
生产阶段注意错误捕获重试机制
存储阶段注意多节点,配置 Broker 参数保证消息存储到磁盘(单节点)
消费节点注意业务逻辑处理完成后 ack
3.3 如何处理消费过程中的重复消息?
3.4 消息积压了该如何处理?
增加消费能力。在扩容 Consumer 的实例数量的同时,必须同步扩容主题中的分区(也叫队列)数量,确保 Consumer 的实例数和分区数量是相等的

若有收获,就点个赞吧
0 人点赞
