Elasticsearch 聚合原理
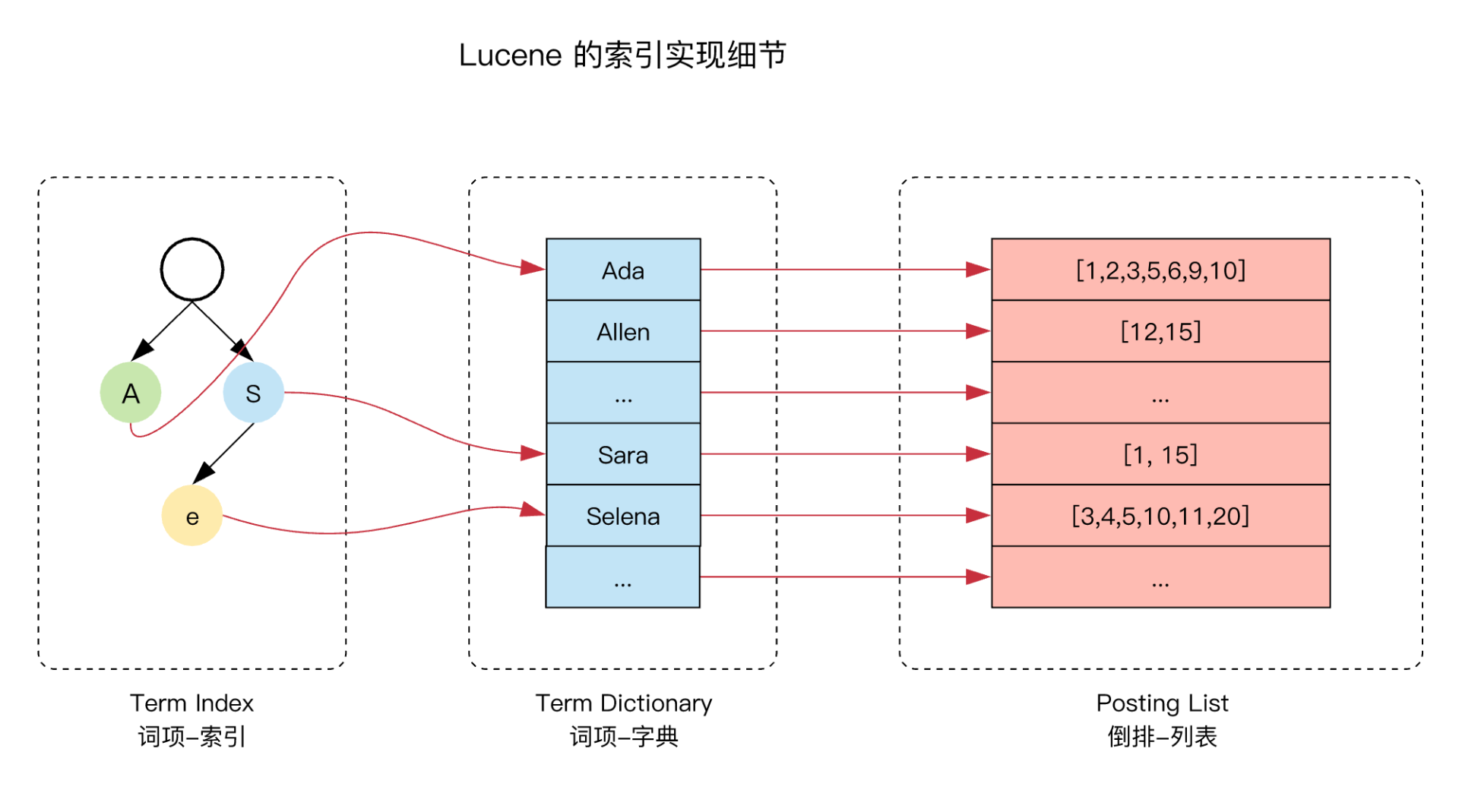
- 倒排索引(Inverted Index)
- term dictionary (有序, log(n))
- term index (FST Trie, O(m))
- 列式存储(doc_values)
- 顺序磁盘读写
- 序列化压缩
- analyzed strings 不支持(text)
- 顺排索引(fielddata)(原理:完整加载这个字段所有 Segment 中的倒排索引到内存中)
- jvm内存读取,查询性能更高
- 查询预热
- indices.fielddata.cache.size =20%(默认没有上限)
配置示例:
{"properties": {"tags": {"type": "keyword","doc_values": true // 默认开启},"content": {"type": "text","fielddata": true,"eager_global_ordinals": true // 预加载},"extra": {"keyword","index": false},"title": {"type": "text","fields": {"keyword": {"type": "keyword"}}}}}
Aggregations 分类及常用聚合
- Bucket
- Terms
- Composite
- Multi Terms
- Histogram
- Metrics
- Top-hits
- Stats
- Cardinality
Pipeline aggregations
关闭动态索引(避免无用字段和全文索引)
- 分词器调整
- 通过fields 设置专门的聚合字段
备注:新版本不支持动态查询boost, 可以使用function_score 查询
{mappings: {dynamic: false,properties: {id: {type: 'keyword',boost: 10},project: {type: 'text',analyzer: 'ik_max_word',search_analyzer: 'ik_smart',fields: {english: {type: 'text',analyzer: 'ik_english',search_analyzer: 'english'},pinyin: {type: 'text',analyzer: 'ik_pinyin_analyzer',search_analyzer: 'standard'}}},approvalId: {type: 'long'},reporter: {type: 'object',dynamic: true},subject: {type: 'text',analyzer: 'ik_max_word',search_analyzer: 'ik_smart',boost: 5,fields: {english: {type: 'text',analyzer: 'ik-english',search_analyzer: 'english'},pinyin: {type: 'text',analyzer: 'ik_pinyin_analyzer',search_analyzer: 'standard'}}},content: {type: 'text',analyzer: 'ik_strip_html',boost: 1.5,search_analyzer: 'ik_smart',fields: {english: {type: 'text',analyzer: 'ik_english',search_analyzer: 'english'},pinyin: {type: 'text',analyzer: 'ik_pinyin_analyzer',search_analyzer: 'standard'}}},envDescription: {type: 'flattened'},tags: {type: 'keyword',fields: {query: {type: 'keyword',normalizer: 'lowercase' // search: case_insensitive: true 7.10}}},chatGroups: {type: 'flattened'},deletedAt: {type: 'date'},createdAt: {type: 'date'},updatedAt: {type: 'date'}}},settings: {number_of_shards: 5,number_of_replicas: 2,analysis: {analyzer: {ik_pinyin_analyzer: {type: 'custom',tokenizer: 'ik_max_word',filter: 'pinyin_filter'},ik_strip_html: {type: 'custom',tokenizer: 'ik_smart',char_filter: ['html_strip']},ik_english: {type: 'custom',tokenizer: 'ik_max_word',filter: ['stemmer'],stopwords: '_english_'}},filter: {pinyin_filter: {type: 'pinyin',keep_first_letter: false,keep_separate_first_letter: false,limit_first_letter_length: 16,keep_full_pinyin: true,keep_joined_full_pinyin: true,keep_none_chinese: false,keep_none_chinese_together: false,keep_none_chinese_in_first_letter: false,keep_none_chinese_in_joined_full_pinyin: false,none_chinese_pinyin_tokenize: false,keep_original: false,lowercase: true,trim_whitespace: true,remove_duplicated_term: false}}}}}
2.2 搜索查询优化
2.2.1 Tags 聚合优化
{size: 0,query: {bool: {filter: [{prefix: {'tags.query': {value: inputweight:10}}},{script: {script: {source: `return doc.tags.size() != 0 && doc.deletedAt.size() == 0 && doc.status.value != '${StatusEnum.DRAFT}'`}}}]}},aggs: {genres: {terms: {field: 'tags'}}}}
2.2.2 工单搜索优化
Es评分机制
- TF:TF(Term Frequency),即词频,表示词条在文本中出现的频率。
- IDF:IDF(Inverse Document Frequency),即逆文档频率。
- 字段长度归一值:( norm )是字段中词数平方根的倒数。越短越好
- 向量空间模型(vector space model): 多词匹配
自定义评分规则: function_score boost_mode
GET /_search{"query": {"dis_max": {"queries": [{ "term": { "subject": "Quick pets" } },{ "term": { "content": "Quick pets" } }],"tie_breaker": 0.2}}}
2.2.3 常见的查询分析命令
查看不同分词器分词
curl --location --request POST 'http://elastic:Tiger!23@172.28.49.74:9200/_analyze' \--data-raw '{"text": "特朗普","analyzer": "ik_max_word"}'
查看当前字段分词
curl --location -g --request GET '{{es}}/work-ticket_v7/_doc/2021080600001/_termvectors?fields=content.english'
查看当前搜索在文档中的评分情况
curl --location -g --request GET '{{es}}/work-ticket_v7/_doc/2021080600001/_termvectors?fields=content.english'
Explain 优化搜索结果相关性
GET /_validate/query?explain {"query": {"match" : {"tweet" : "really powerful"}}}
Profile 定位查询性能问题 ```bash curl XPOST http://localhost:9200/myindex/mytype/_search -d ‘{ “profile”: true, “query”: {
"match": {"brand": "Cotton Plus"}
} }’
2.3 关于搜索推荐实现
- 词条建议器(term suggester):对于给定文本的每个词条,该建议器从索引中抽取要建议的关键词,这对于短字段(如分类标签)很有效。
- 词组建议器(phrase suggester):我们可以认为它是词条建议器的扩展,为整个文本(而不是单个词条)提供了替代方案,它考虑了各词条彼此临近出现的频率,使得该建议器更适合较长的字段,比如商品的描述。
- 完成建议器(completion suggester):该建议器根据词条的前缀,提供自动完成的功能(智能提示,有点最左前缀查询的意思),为了实现这种实时的建议功能,它得到了优化,工作在内存中。所以,速度要比之前说的match_phrase_prefix快的多!
- 上下文建议器(context suggester):它是完成建议器的扩展,允许我们根据词条或分类亦或是地理位置对结果进行过滤。
其它实现方式:
- match_phrase_prefix
-
其它优化调整
项目启动自动更新索引、数据
- 暴露接口维护旧索引、刷新数据
配置动态词库(本地词库、tags、用户表用户名); (7.12以下版本IK分词注意关闭gzip)
总结
设置合理的mapping字段类型、分词
- 使用节点查询缓存(filter)
- 使用分片请求缓存(size = 0)
- 通过 msearch 拆解多个聚合为单个子语句
- 低版本设置 “collect_mode” : “breadth_first”
参考文档:
Terms aggregation | Elasticsearch Guide [7.14]| Elastic
Elastic 系列:Lucene 的索引结构和查询效率 | NingG 个人博客
ElasticSearch Aggregations GroupBy 实现源码分析
通过Function Score Query优化Elasticsearch搜索结果

若有收获,就点个赞吧
0 人点赞
