日志分类
1.1 日志来源分类
诊断日志:APP、Web、服务端 、Nginx 日志错误排查
统计日志:运营数据埋点统计、IP访问量
审计日志:对日志规范化、过滤、归并和告警分析等处理后,以统一格式的日志形式进行集中存储和管理
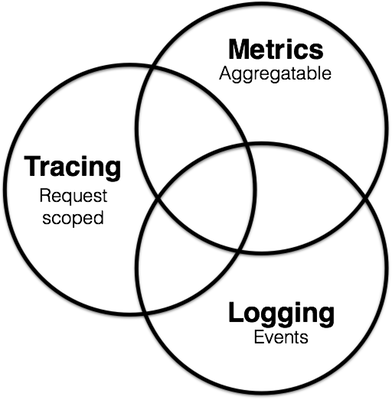
1.2 日志统计维度
- Logging: 提供系统/进程最精细化的信息,例如某个关键变量、事件、访问记录等。
- Tracing: 提供了一个请求从接收到处理完毕整个生命周期的跟踪路径,通常请求都是在分布式的系统中处理,所以也叫做分布式链路追踪。
- Metrics: 提供量化的系统内/外部各个维度的指标,一般包括Counter、Gauge、Histogram等。
产品功能对比
| 产品名称 | Graylog | 阿里云SLS | Splunk | Elk |
|---|---|---|---|---|
| 技术架构 | Graylog Server es(日志数据) mongodb(Streams, alerts, users, settings) |
Rest api(日志采集、查询) Loghub TSDB |
time-series indexer(时序索引) | Logstash es kibana(grafana) |
| 日志结构 | 按时间日期切割的Es索引 | succinct tree (只有 FST 结构的 40~70%) | LSM(日志结构合并树(Log-Structured Merge-Tree)) | FST tree(Finite State Transducer) |
| 功能 | 查询、报表、报警 | 查询、实时分析、报警,投递消费 | 查询、实时分析、报警 | 查询,报表 |
| 优点 | 部署方便 可视化规则配置 权限控制 |
| 功能全面(采集、日志类型、统计)
运维成本低
扩展性好、
高性能、高可用
上下文、tail查询
云平台支持 | 动态分析(抽取新的字段)
权限控制
储存体积小(数据压缩)
SPL(非结构化语句)
上下文查询 | 灵活扩展 |
| 缺点 | 使用体验不友好~ | | 付费 | 自定义logstash规则(性能)、日志分割
配置复杂
不支持多行采集 |
日志平台使用
3.1 Graylog 平台使用
3.1.1 查询语法
- 模糊查询:直接输入字符串 JOBTICKET_TIMEOUT_CHECK 或者JOB_TICKET_TIMEOUT(、?号不可以在首位). * 有区别.
- 精确查询:加引号 “JOB_TICKET_TIMEOUT_CHECK”
- 字段查询:message:JOB*
- 多字段查询:message:(JOB_SEND_USER_WEEK_SUMMARY JOB_CREATE_TICKET_USER_TREND)
- 多条件查询:JOB_SEND_USER_WEEK_SUMMARY OR (JOB_CREATE_TICKET_USER_TREND AND source:”BJ-VM-28-49-37”)
- 正则匹配查询:/.*_USER_WEEK_SUMMARY/
- 关键字: AND、OR、NOT (需要大写)、 exists
- 范围查找http_response_code:[0 TO 64}http_response_code:>400createdAt:[“2020-07-29T12:00:00.000-05:00” TO “2020-07-30T15:13:00.000-05:00”]
字符串转译:& | : \ / + - ! ( ) { } [ ] ^ “ ~ * ? . 示例: path:\/posts\/1234
3.1.2 stream 配置
功能:主要用来过滤结果、聚合相同系统、类型数据
一个 Stream 唯一属于一个 Index Set,但是多个 Streams 可以共享同一个 Index Set,同名字段类型必须一致3.1.3 告警配置
告警支持 http 和 email 方式 (FATAL级别错误);
3.2 阿里云 sls 使用
3.2.1 查询语法
全文查询: PUT and cn-shanghai
- 字段查询: request_time>60 and request_method:Ge*
- 精确查询: 使用完整的词进行查询
- 模糊查询: 星号(*)或问号(?)不能用在词的开头
- 运算符:and or not in () : >= , 关键字需要 “” 包裹;
-
3.2.2 分析语法:
查询语句和分析语句以竖线(|)分割:
示例: | SELECT status, count() AS PV GROUP BY status SQL函数: 、AVG、. method: PostLogstoreLogs | SELECT avg(latency) AS avg_latency, Project GROUP BY Project HAVING avg_latency > 1000
- SQL语法:INSERT、GROUP、HAVEING、LIMIT、JOIN 子查询. *| insert into target_logstore(k1,k2,v) select k1,k2,count(1) from source_logstore group by k1,k2
-
3.2.3 Trace 链路服务
基于 OpenTelemetry只提供数据的格式定义、产生、收集、发送,但并不提供分析、可视化、告警等功能。
3.2.4 数据加工
数据规整:针对混乱格式的日志进行字段提取、格式转换,获取结构化数据以支持后续的流处理、数据仓库计算。
- 数据富化:对日志(例如订单日志)和维表(例如用户信息表)进行字段连接(JOIN),为日志添加更多维度的信息,用于数据分析。
- 数据流转:通过跨地域加速功能将海外地域的日志传输到中心地域,实现全球日志集中化管理。
- 数据脱敏:对数据中包含的密码、手机号、地址等敏感信息进行脱敏。
- 数据过滤:过滤出关键服务的日志,用于重点分析。
日志平台架构参考
4.1 GrayLog

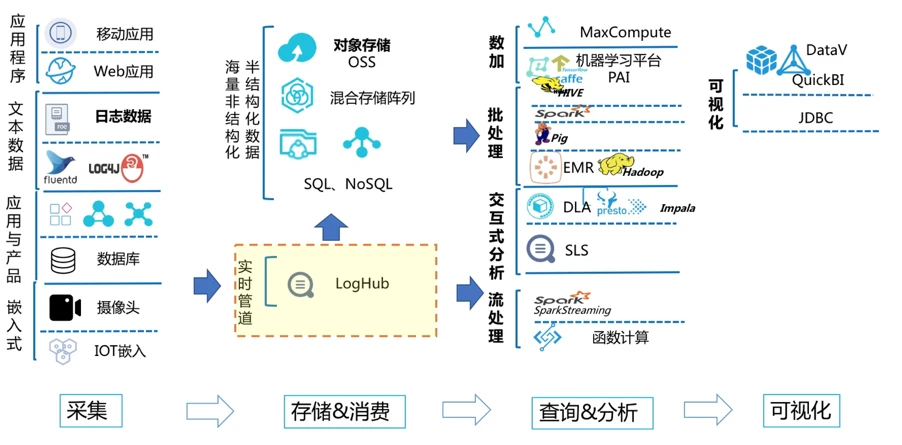
4.2 阿里云SLS

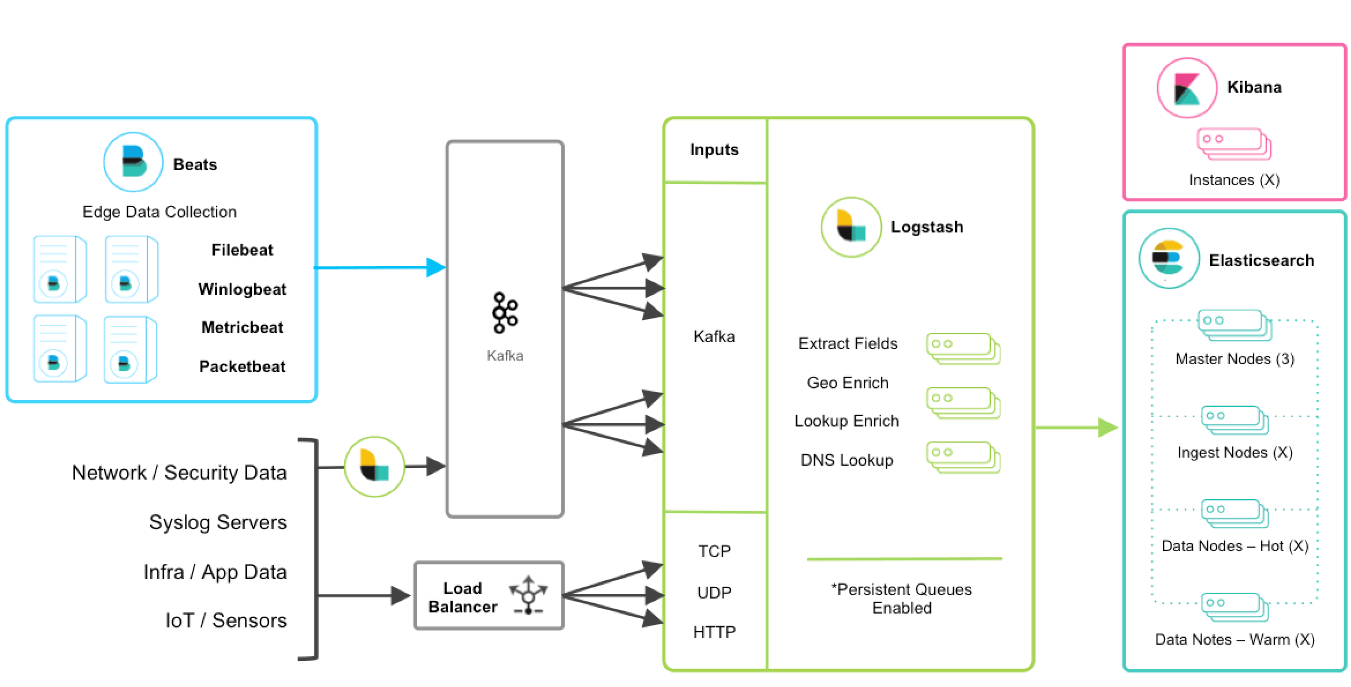
4.3 ELK
问题与思考
Q:graylog 按日期切割,日志存在冗余
A:
Q:graylog 日志结果无法选中、高亮
A:
Q:日志结构输入&采集规范化
A: 日志用途(统计、排查)
记录关键信息
日志文本分隔
预定义字段、分级
配置告警参考文档:
Graylog 查询官方文档
阿里云日志官方文档
时序数据库原理

若有收获,就点个赞吧
0 人点赞
