最近处理潘多拉系统问题,常常会出现一些接口超时问题。所以梳理了一下超时常见类型及对应处理思路。
超时分类
客户端超时
错误信息:timeout of 1000ms exceeded,ETIMEDOUT
客户端超时是http 客户端 设置了超时时间,主动关闭了接口连接;通常分两种 connectTimeout(建立tcp连接超时),readTimeout(读取服务器数据超时)。不过很多http客户端不支持设置 connectTimeout(例如axios). eggjs的 ctx.curl 和 apache httpclient是支持两个超时参数设置的.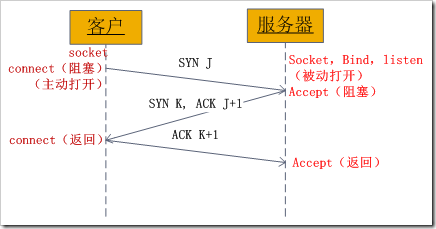
处理方法:根据业务合理配置客户端各类超时时间参数。由于服务端链路不可控,可以根据请求返回错误码,区分连接超时还是接收数据超时,针对不同错误类型触发接口重试(定时重试、重试次数)。
网关、代理超时
错误信息:
504 Gateway Timeout、
proxyconnect_timeout :后端服务器连接的超时时间发起握手等候响应超时时间
proxyread_timeout:连接成功后等候后端服务器响应时间其实已经进入后端的排队之中等候处理(也可以说是后端服务器处理请求的时间)
proxy_send_timeout :后端服务器数据回传时间就是在规定时间之内后端服务器必须传完所有的数据
处理方法:1根据业务调优化整网关或代理服务器超时时间,返回正确错误码,记录日志方便排查。
服务端超时
错误信息: 408 Request Timeout, Response timeout for 5000ms(不同语言框架返回信息不一样)
nodejs 服务端默认超时时间是2分钟,超时会返回客户端,重置连接(connect reset)。如果业务链路过长,或者业务有慢查询,流量高峰期等,会导致接口处理时间过长,造成超时。
处理方法:优化业务代码,sql,拆分非必要业务异步处理。对于突发流量,做好接口幂等设计(可以记录请求序列号),方便客户端重试。对于分布式系统,添加查询接口,保障事务一致性。
2. 处理方案
超时处理我目前的解决思路是:分析日志->定位超时链路点(client -nginx-gateway-server -server-db)->排查超时原因(客户端网络、服务器参数、接口代码)->优化代码逻辑或超时配置。最难排查的是偶发性的超时(请求数据正常,超时情况无法复现)。需要查看服务器有没有异常重启、带宽、内存等因素,目前还没有很好的思路。
上面就是本月的学习分享,大家周末愉快。
3. 总结
https://toutiao.io/posts/u97o5l/preview
http://reader.epubee.com/books/mobile/c6/c6164eab8503f0d3a037480a498e0df0/text00011.html

若有收获,就点个赞吧
0 人点赞
