AWK 列转行(行列转置)
小矩阵,可以使用以下AWK命令,大的矩阵文件未曾测试过
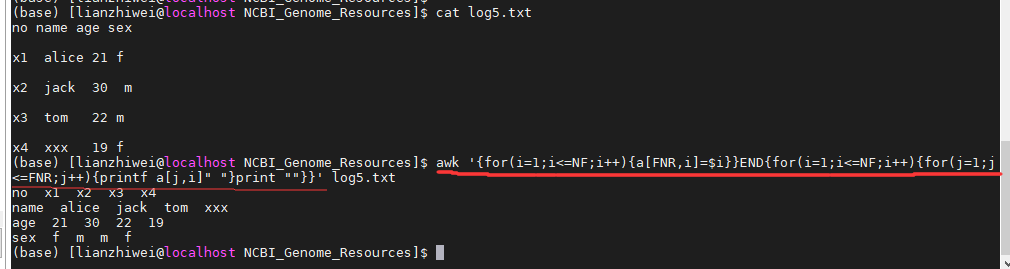
- 生成示例文件:log5.txt,文件内容为
no name age sex
x1 alice 21 f
x2 jack 30 m
x3 tom 22 m
x4 xxx 19 f
- 运行以下命令
awk '{for(i=1;i<=NF;i++){a[FNR,i]=$i}}END{for(i=1;i<=NF;i++){for(j=1;j<=FNR;j++){printf a[j,i]" "}print ""}}' filename
参考:https://blog.csdn.net/bigwood99/article/details/105276240
AWK筛选行(行筛选)
假设有一个文件,其文件内容前几行如下,我们需要根据每一行的NA值的个数对行进行筛选,比如NA值超过一半列数,我们就从文件中剔除这一行。
chr1 65419 71585 ENSG00000186092.7_1 6167.0 + 75.000000 100.000000 93.371212 87.857143 91.666668 91.666666chr1 134901 139379 ENSG00000237683.5 4479.0 - nan nan nan nan nan nan nan nan nan nan nan nanchr1 621059 622053 ENSG00000284662.1_1 995.0 - nan nan nan nan nan nan nan nan nan 33.333332 nan
实现上述目的的AWK命令如下:
# 1. NF代表文件字段(列)的个数,如果NA值大于"NF/2",zcat matrix.tab.gz | awk '{for(i=1;i<=NF;i++){if($i=="nan") a++} {if(a<=NF/2) print};a=0}' >rm0.3NA_mat.tab# 2. 从文件的每一行的第七列开始,将非NA的值统一减去50zcat matrix.tab.gz | awk -F "\t" -v OFS="\t" '{for(i=7;i<=NF;i++){if($i!="nan") $i=$i-50}print}' | gzip >matrix_sub50.tab.gz# 合并1和2的功能,筛选行的同时,从文件的每一行的第七列开始,将非NA的值统一减去50zcat matrix.tab.gz | awk -F "\t" -v OFS="\t" '{for(i=7;i<=NF;i++){if($i=="nan") a++; else $i=$i-50}{if(a<=NF/3) print};a=0}' >filteredNA_sub50_mat.tab
踩坑记录:以下两条命令都是错的
cat head.tab | awk '{for(i=1;i<=NF;i++){if($i=="nan") a++}}END{print a}' | wc -l #已经遍历所有行cat head.tab | awk '{for(i=1;i<=NF;i++){if($i=="nan") a++} print a}' | wc -l #遍历每一行,但记录NA的变量没有在每行遍历前重置为零

若有收获,就点个赞吧
0 人点赞
