tags: [解析构建Dom树过程]
categories: 重学前端系列笔记
浏览器在请求放在服务器端的代码之后,如果解析又如何渲染成dom树,展示在页面中呢?
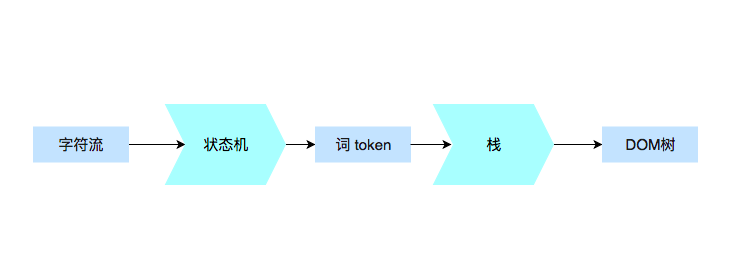
解析代码
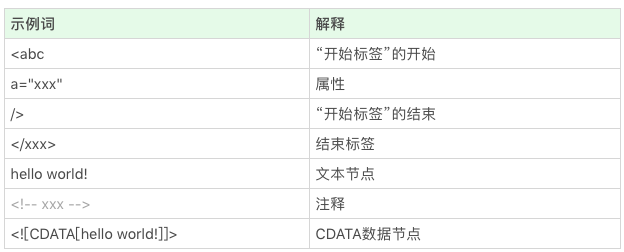
词(token)拆分
<p class="a">text text text</p>
如果把整个标签当做一个词来解析。那么就会很大,因为内部可以进行嵌套,所以:
- <p :“标签开始”的开始;
- class=”a” : 属性;
- > :“标签开始”的结束;
- text text text : 文本;
- :标签结束。
当我们通过http协议,获得一串字符流时,从接受的第一个字符开始解析,当遇到
<的时候。判断出这是标签文本,然后再读一个xx,就可以判断这不是个注释节点,然后再读取xx ="xxx",就可以将其解析为该标签的属性。当碰到/>就可以判断出,这个标签解析结束。可以将其展现。
状态机
上面解析每解析一个字符,都要做一次决策。而每一次决策就要涉及到状态机,这就引来了另一个问题,状态机是什么?
状态机是什么?
其实,绝大多数的语言的词法部分是使用状态机实现的,下面是一个词解析过程,画成状态机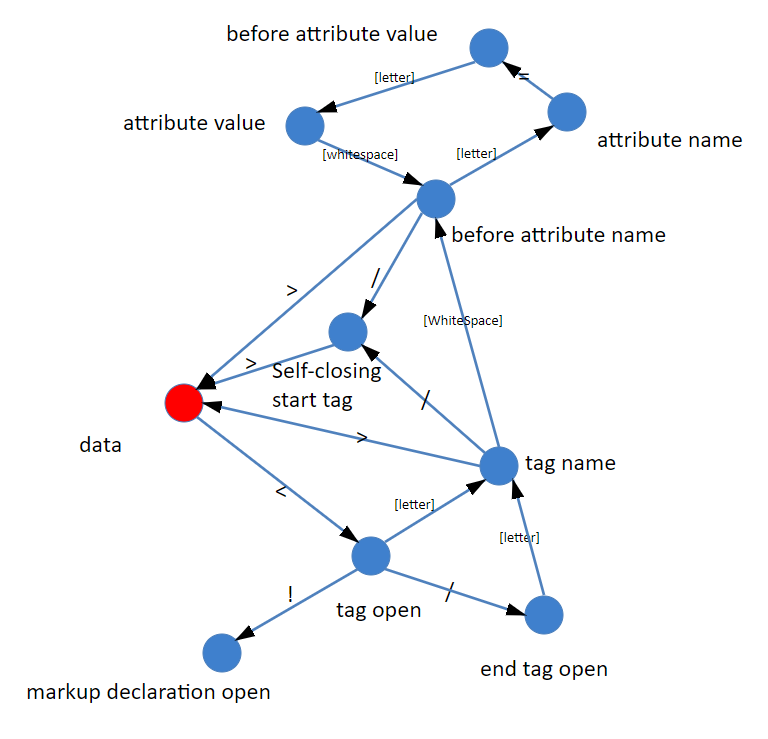
完整的状态机可以参照 HTML官方词法状态机解析
状态机解析过程:
初始部分:
- 只区分
<和非>,如果是<可以进入标签状态,如果是非<就进入文本状态
进入标签状态之后:
- 如果下一个字符是 “!”,那么就进入到了注释节点状态或者 CDATA节点
- 如果下一个字符是 “/ “,那么就进入标签结束状态
- 如果下一个字符是一个字母。那么进入标签解析开始的状态
- 如果我们要完整处理各种 HTML 标准中定义的东西,那么还要考虑“ ? ”“% ”等内容。
其实用状态机做词法解析,只是将各种特征字符拆分成单独状态,然后通过判断单独的状态,最终连成图结构输出。我们把每个函数当做一个状态,参数是接受的字符,返回值是下一个状态函数。
var data = function(c){
if(c==="&") {
return characterReferenceInData;
}
if(c==="<") {
return tagOpen;
}
else if(c==="\0") {
error();
emitToken(c);
return data;
}
else if(c===EOF) {
emitToken(EOF);
return data;
}
else {
emitToken(c);
return data;
}
};
var tagOpenState = function tagOpenState(c){
if(c==="/") {
return endTagOpenState;
}
if(c.match(/[A-Z]/)) {
token = new StartTagToken();
token.name = c.toLowerCase();
return tagNameState;
}
if(c.match(/[a-z]/)) {
token = new StartTagToken();
token.name = c;
return tagNameState;
}
if(c==="?") {
return bogusCommentState;
}
else {
error();
return dataState;
}
};
//……
这里通过 if....else 来区分解析的字符来进行状态迁移。状态迁移其实就是当前状态的函数通过判断返回下一个字符的状态函数。
var state = data;
var char
while(char = getInput())
state = state(char);
这段代码的关键一句是“ state = state(char) ”,不论我们用何种方式来读取字符串流,我们都可以通过 state 来处理输入的字符流,这里用循环是一个示例,真实场景中,可能是来自 TCP 的输出流。
function HTMLLexicalParser(){
// 状态函数们……
function data() {
// ……
}
function tagOpen() {
// ……
}
// ……
var state = data;
this.receiveInput = function(char) {
state = state(char);
}
}
构建 DOM 树
通过上面的词拆分进行解析。简单的词到后来的 DOM 树。整个过程是通过栈实现的。任何语言都有栈这个东西。
- 栈顶元素就是当前节点;
- 遇到属性,就添加到当前节点;
- 遇到文本节点,如果当前节点是文本节点,则跟文本节点合并,否则入栈成为当前节点的子节点;
- 遇到注释节点,作为当前节点的子节点;
- 遇到 tag start 就入栈一个节点,当前节点就是这个节点的父节点;
- 遇到 tag end 就出栈一个节点(还可以检查是否匹配)。
<html maaa=a >
<head>
<title>cool</title>
</head>
<body>
<img src="a" />
</body>
</html>


若有收获,就点个赞吧
0 人点赞
